:::warning
如果你尝试解决用JMH优化公司里的公共组件性能问题, 你可能会要知道下面的内容
如果你只是为了 解决普通的业务问题, 这里就没必要看了, 纯属浪费时间, 还提升不了啥性能; 我的建议是不要看了 :::
这是一段官方示例 Sample_22_FalseSharing 中的说明文字
/** One of the unusual thing that can bite you back is false sharing.* If two threads access (and possibly modify) the adjacent values* in memory, chances are, they are modifying the values on the same* cache line. This can yield significant (artificial) slowdowns.** JMH helps you to alleviate this: @States are automatically padded.* This padding does not extend to the State internals though,* as we will see in this example. You have to take care of this on* your own.*/
翻译:
有一件非常容易背刺我们的事 —— 伪共享
如果两个线程 同时访问(修改) 内存地址上相近的值
有一定几率会导致两个线程修改的值是在同一个缓存行上的
好了现在引入了一个新的概念 “缓存行”
缓存行这个是CPU设计上的概念, 硬件上的实现;
先解释一下什么是缓存行
CPU和内存
要了解什么是缓存行, 得先知道CPU和内存之间的结构, 以及他们之间是如何交换数据并进行处理的
结构
- 其中L1 cache是单核独享的
- 内存或者L3 cache是所有核共享的
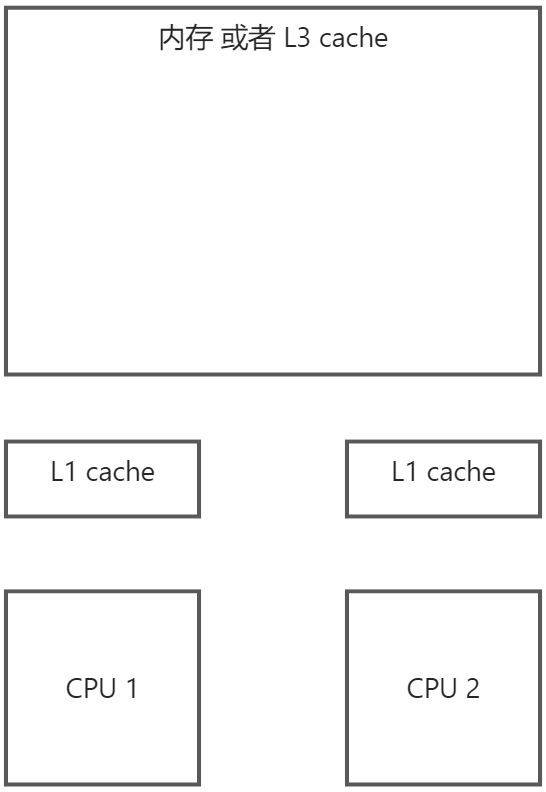
cpu读取内存数据
假设内存中有一个 32 字节的 int值, CPU是如何读取或者修改它的呢?
- 第一步: 确定要被读取的数据在内存中的位置, 由于CPU一次总是读取64个字节, 所以不可避免的读取到了其他数据
- 假设CPU一次总是读取 64 字节的数据
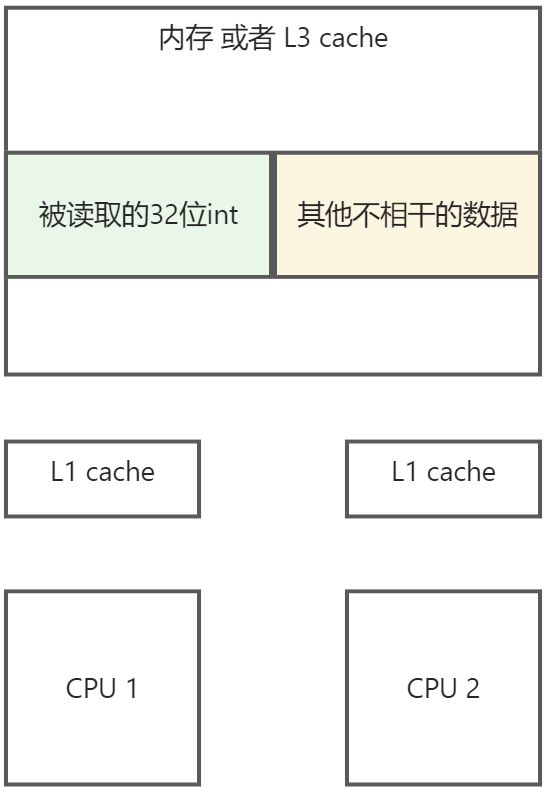
- 第二步 : 将内存中的数据, 复制到 L1 cahce中

- 第三步: CPU对L1 cache中的数据进行读取计算修改
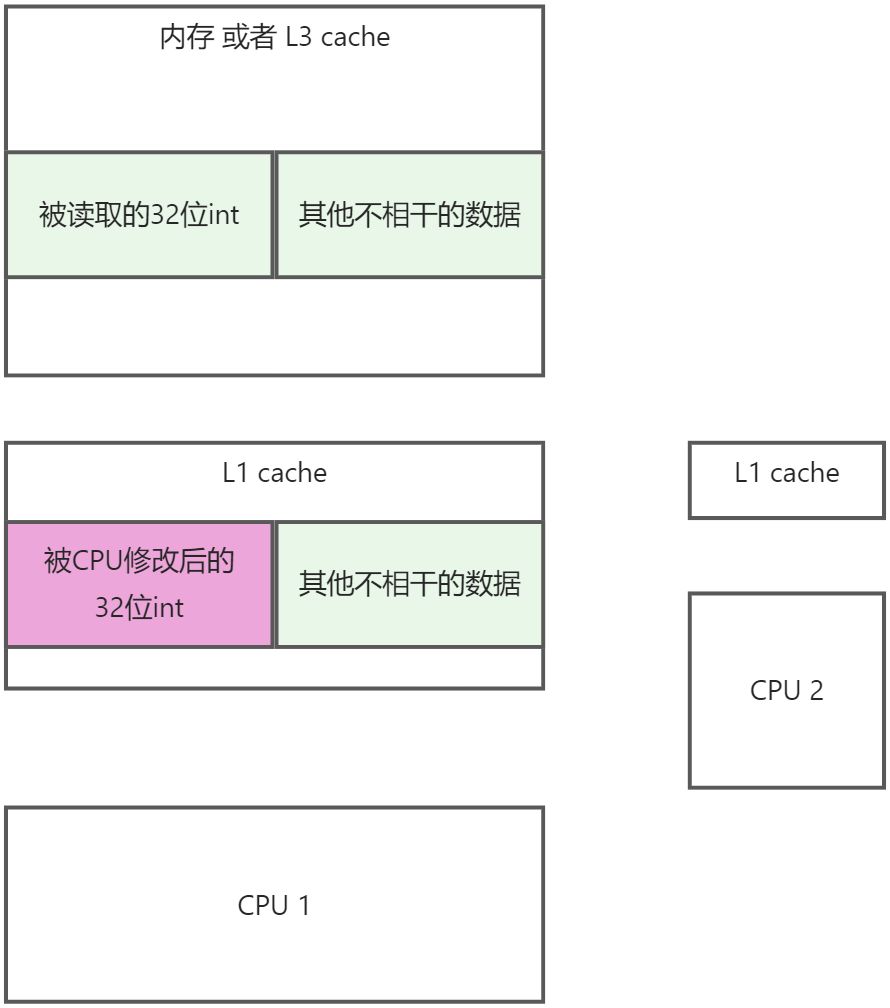
- 第四步: L1 cahce中的数据, 复制到原来内存中的位置
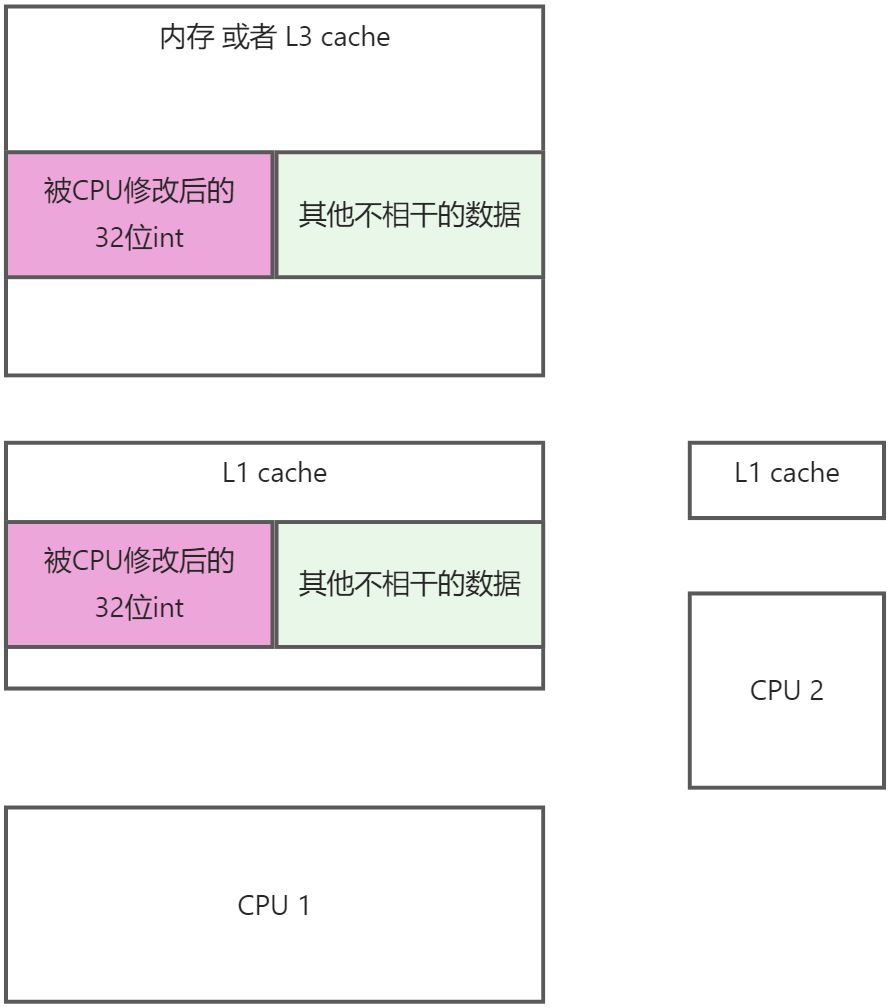
好了, 聪明的同学已经发现问题了, 为什么只修改32位的数据, 却要读取64位数据呢?
这个是硬件设计的事, 我们软件层面无法控制
两个线程CPU同时读取一段数据
我们软件编写的时候, 并不知道CPU同时操作了64位的数据
这样就会出现一个严重的问题
如果两个线程同时修改这64位的数据, 那岂不是就会发生数据的冲突了么?
最后这64位, 到底是哪一个线程为主?
我们来推演一下看看:
- 两个线程同时读取数据
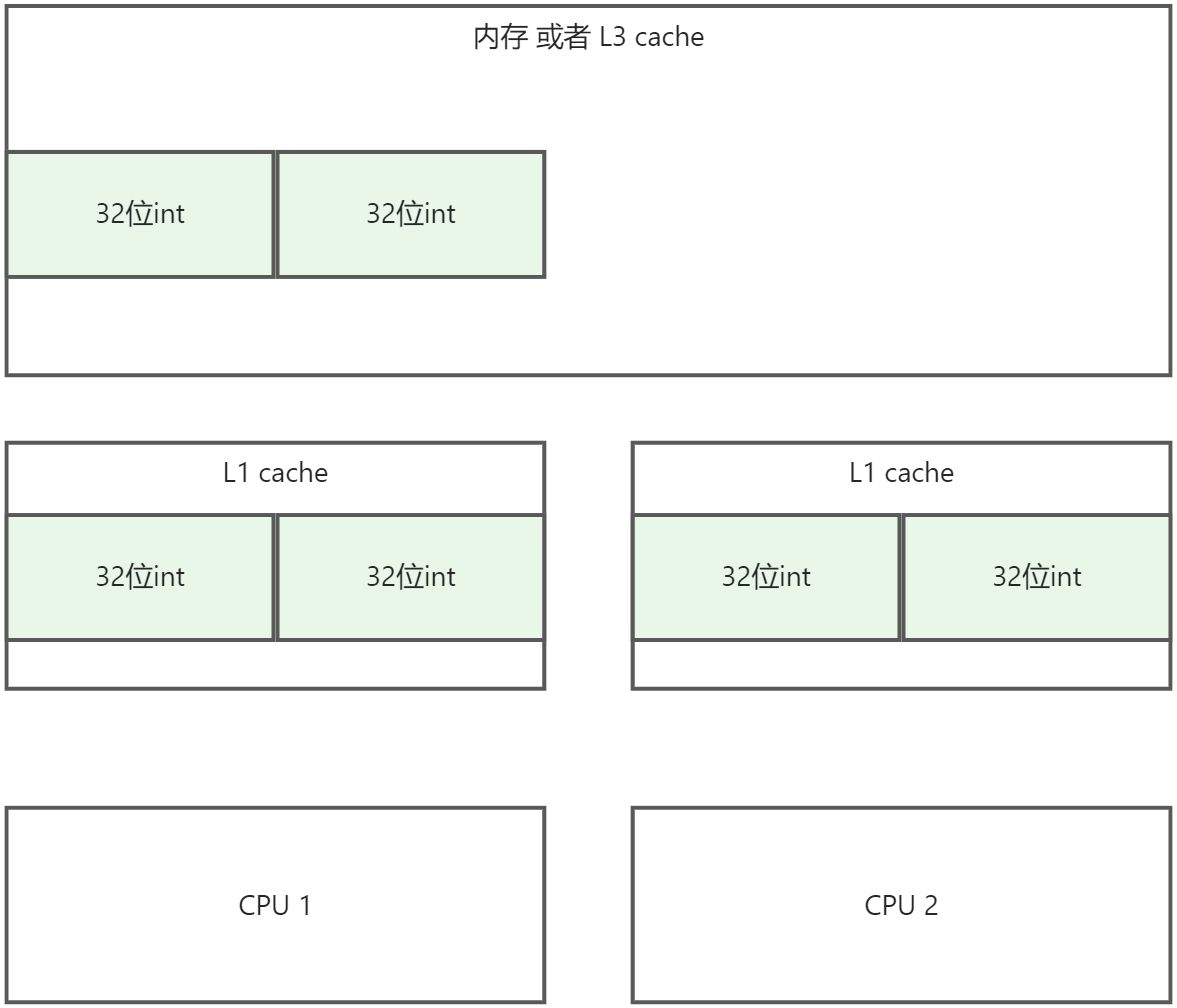
- cpu1修改前32位, CPU2修改后32位
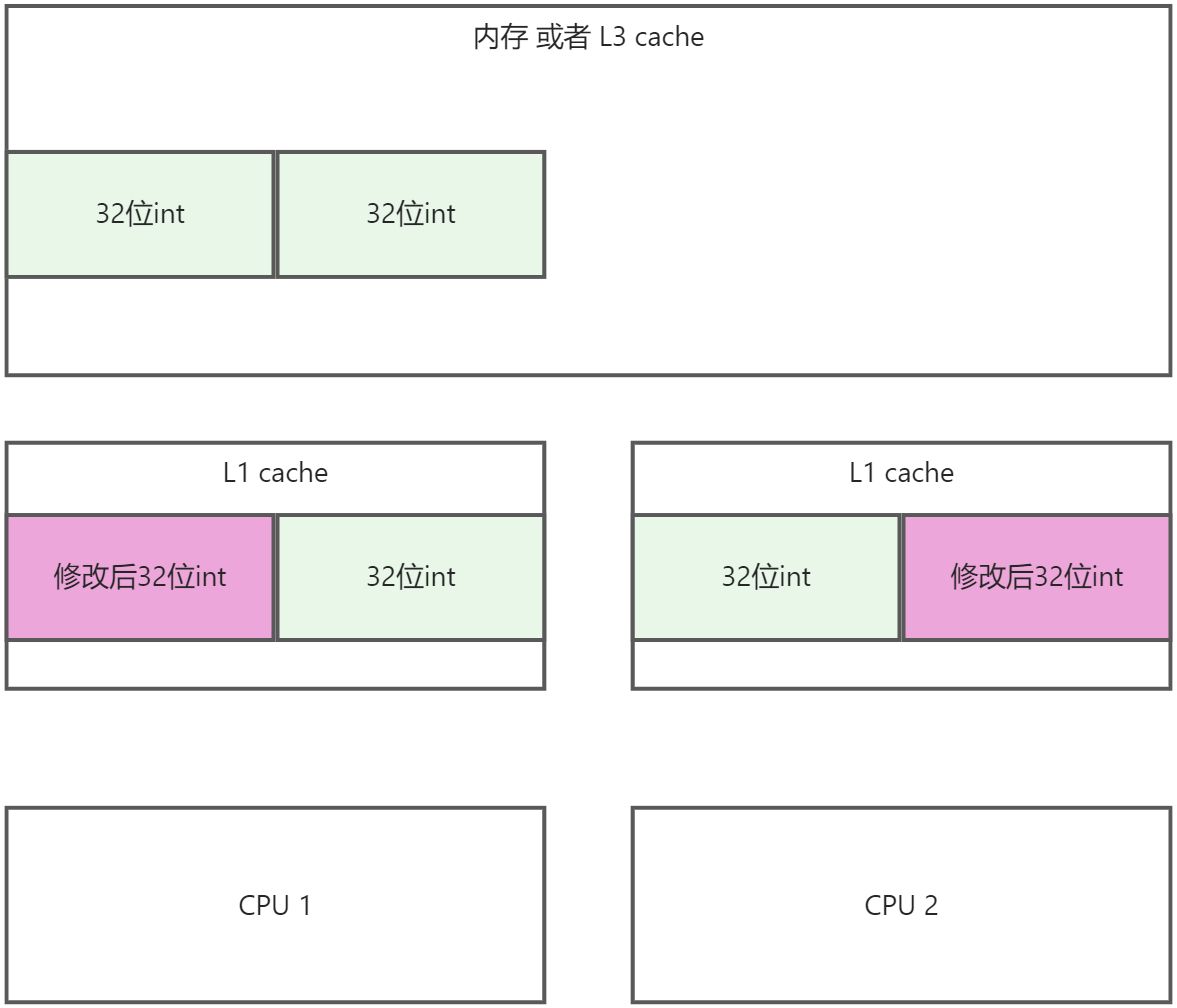
- 同时将数据回写到内存中
- 就是这一步出现了问题!
假如CPU1先写回去, CPU2再写, 那岂不是CPU1的操作直接就被覆盖了?
反之亦然
CPU是如何解决这个问题的呢?
上述情况会带来一个极大的问题, 就是我们的计算不能保证正确性!! 这样写的所有程序都没卵用了, 全都是不可靠
那CPU是怎么解决这个问题的呢?
CPU的处理很简单,也很有效:
- CPU只采用第一个修改缓存行的结果
- 其他核的修改直接抛弃, 重新计算
由于这个问题是CPU内部解决的, 所以我们在应用层完全感知不到, 唯一的感知就是运行速度不稳定了, 忽快忽慢
看看步骤:
- 将CPU1执行结果写回到内存中, 同时废弃掉CPU2的修改
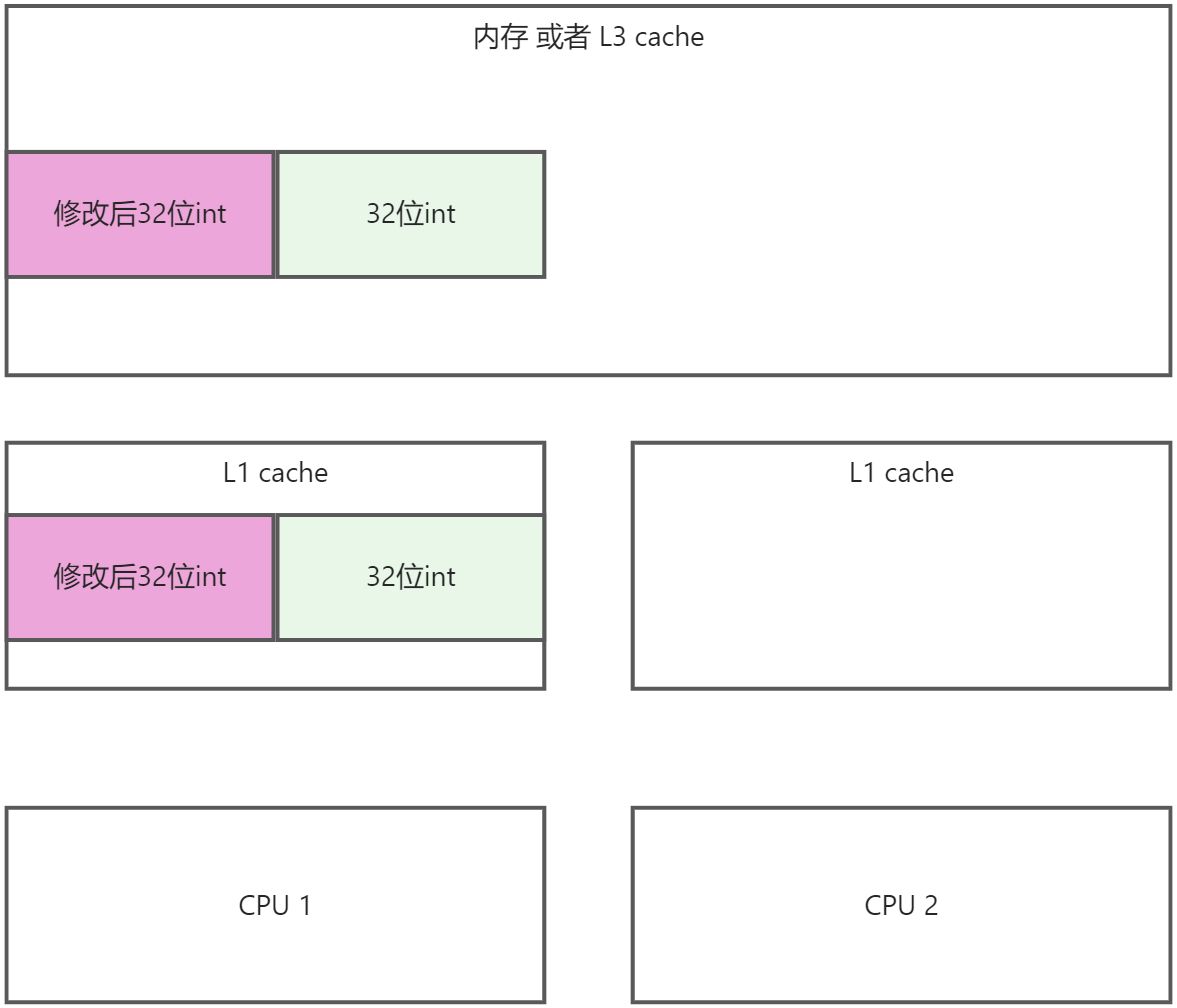
- CPU2重新读取内存
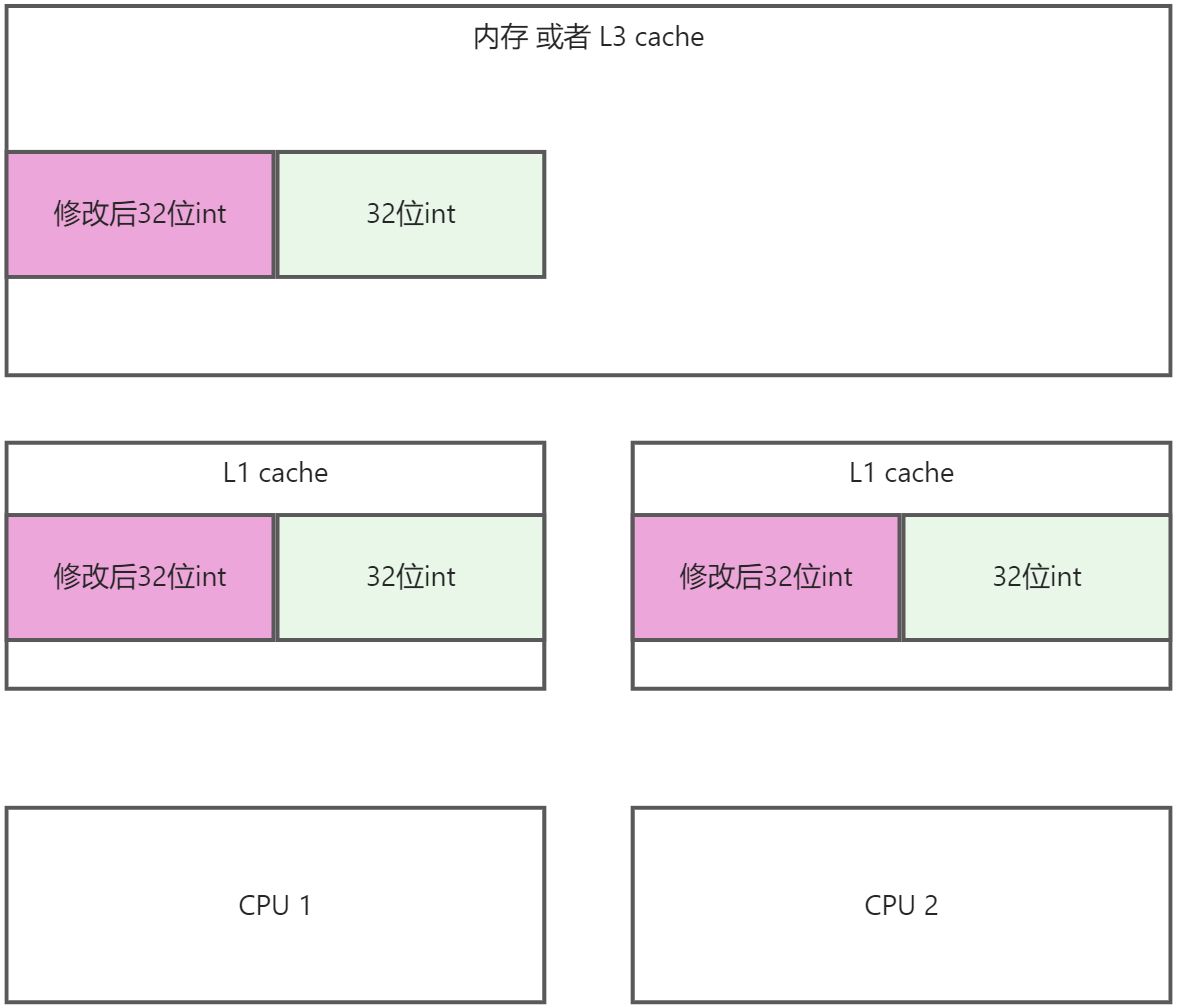
- CPU2执行修改操作
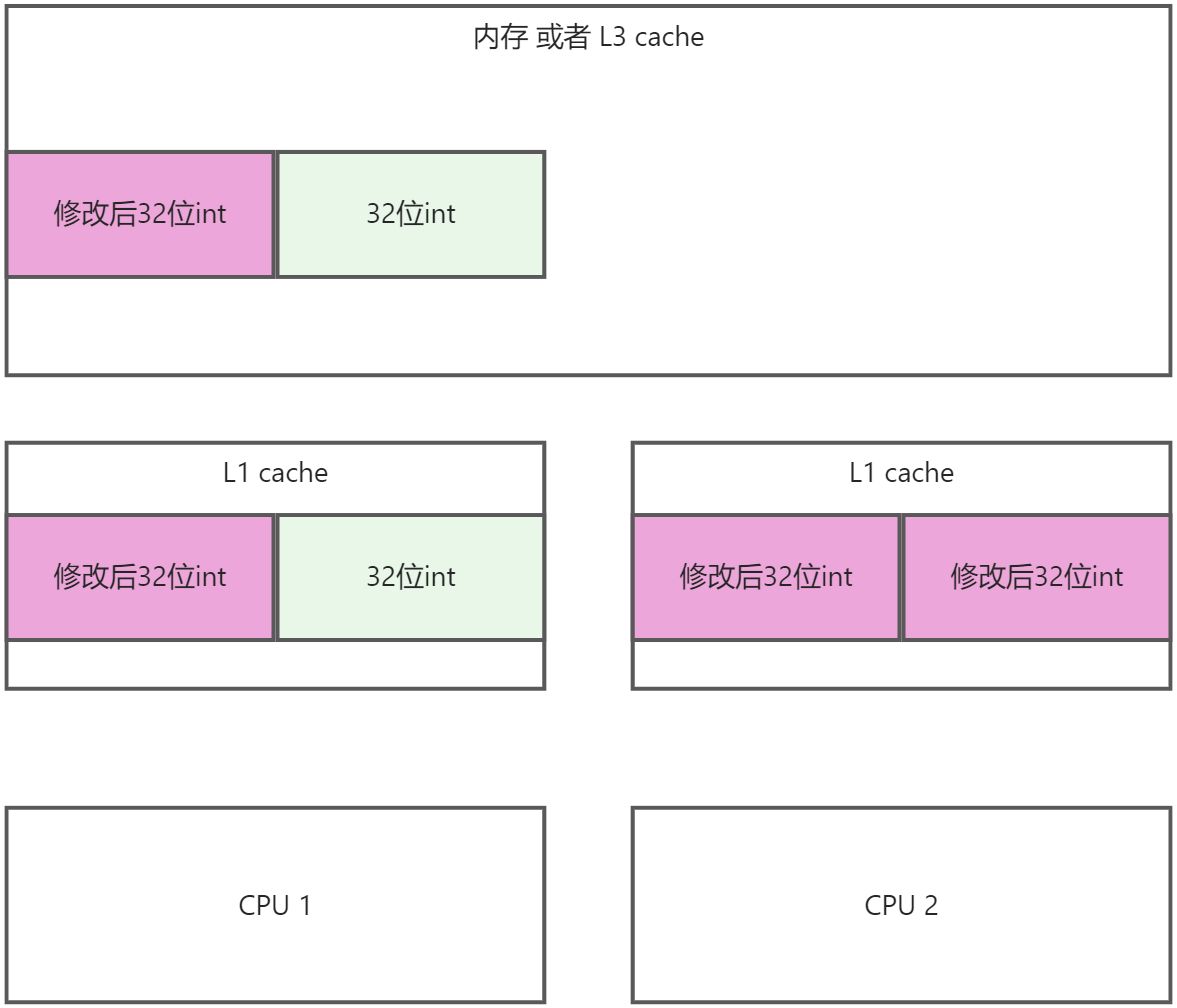
- CPU2的数据写回到内存中
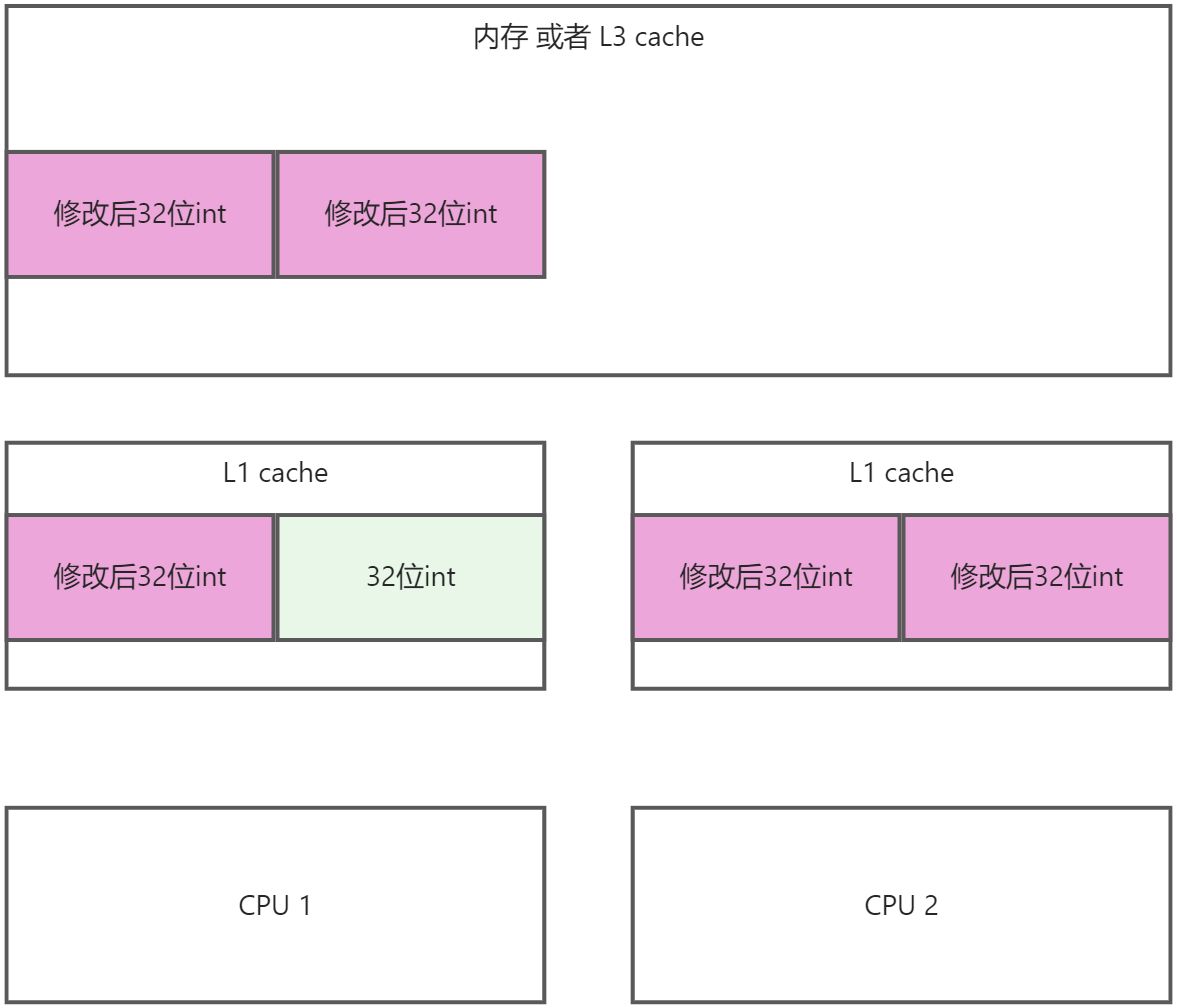
这样缓存行的问题就解决了
这跟JMH有什么关系呢?
- 缓存行的问题, 会导致某些多线程代码的执行效率大大下降
- 如果我们的JMH在执行这些有问题的代码, 就会导致性能不及预期
Java中有一个非常有名的项目:
一个有多线程缓存行问题的例子
@State(Scope.Group)public static class StateBaseline {//这两个32位的int内存分配的时候是靠在一起的, 很容易出现伪共享问题int readOnly;int writeOnly;}@Benchmark@Group("baseline")public int reader(StateBaseline s) {return s.readOnly;}@Benchmark@Group("baseline")public void writer(StateBaseline s) {s.writeOnly++;}
怎么解决缓存行问题?
尝试1: PADDING
@State(Scope.Group)public static class StatePadded {int readOnly;int p01, p02, p03, p04, p05, p06, p07, p08;int p11, p12, p13, p14, p15, p16, p17, p18;int writeOnly;int q01, q02, q03, q04, q05, q06, q07, q08;int q11, q12, q13, q14, q15, q16, q17, q18;}@Benchmark@Group("padded")public int reader(StatePadded s) {return s.readOnly;}@Benchmark@Group("padded")public void writer(StatePadded s) {s.writeOnly++;}
尝试2: CLASS HIERARCHY TRICK
public static class StateHierarchy_1 {int readOnly;}public static class StateHierarchy_2 extends StateHierarchy_1 {byte p01, p02, p03, p04, p05, p06, p07, p08;byte p11, p12, p13, p14, p15, p16, p17, p18;byte p21, p22, p23, p24, p25, p26, p27, p28;byte p31, p32, p33, p34, p35, p36, p37, p38;byte p41, p42, p43, p44, p45, p46, p47, p48;byte p51, p52, p53, p54, p55, p56, p57, p58;byte p61, p62, p63, p64, p65, p66, p67, p68;byte p71, p72, p73, p74, p75, p76, p77, p78;}public static class StateHierarchy_3 extends StateHierarchy_2 {int writeOnly;}public static class StateHierarchy_4 extends StateHierarchy_3 {byte q01, q02, q03, q04, q05, q06, q07, q08;byte q11, q12, q13, q14, q15, q16, q17, q18;byte q21, q22, q23, q24, q25, q26, q27, q28;byte q31, q32, q33, q34, q35, q36, q37, q38;byte q41, q42, q43, q44, q45, q46, q47, q48;byte q51, q52, q53, q54, q55, q56, q57, q58;byte q61, q62, q63, q64, q65, q66, q67, q68;byte q71, q72, q73, q74, q75, q76, q77, q78;}@State(Scope.Group)public static class StateHierarchy extends StateHierarchy_4 {}@Benchmark@Group("hierarchy")public int reader(StateHierarchy s) {return s.readOnly;}@Benchmark@Group("hierarchy")public void writer(StateHierarchy s) {s.writeOnly++;}
尝试3 : 直接使用大数组
@State(Scope.Group)public static class StateArray {int[] arr = new int[128];}@Benchmark@Group("sparse")public int reader(StateArray s) {return s.arr[0];}@Benchmark@Group("sparse")public void writer(StateArray s) {s.arr[64]++;}
尝试4: 使用注解告诉JVM分配内存的时候将不同变量放入不同缓存行中; (示例中说JDK8有用, 但是我试了没用, 甚至直接不能编译)
@State(Scope.Group)public static class StateContended {int readOnly;//仅在JDK8有这个注解//但即使切换到JDK8我本地还是无法编译运行....// @sun.misc.Contendedint writeOnly;}@Benchmark@Group("contended")public int reader(StateContended s) {return s.readOnly;}@Benchmark@Group("contended")public void writer(StateContended s) {s.writeOnly++;}

若有收获,就点个赞吧
0 人点赞
