https://www.cnblogs.com/hellogiser/p/big-endian-vs-little-endian.html https://www.bilibili.com/video/BV1pX4y1N7T4?p=14 https://blog.csdn.net/a1219532602/article/details/103442437
简介
字节序是指 : 多字节数据的存储顺序
比如 int 是4个字节,
内存分配了4个字节存储一个int型的数字 0x12345678
那么这4个字节中 第一个字节存的是 0x12 还是 0x78 ??
这是个问题
分类
- 小端格式: 将低位字节数据存储在低地址
- 大端格式: 将高位字节数据存储在低地址 (较符合人类的习惯, 先读取的是高位的数字)
不同的CPU使用的字节序是不同的
- IBM, Motorola(Power PC), Sun的机器一般采用Big-endian方式存储数据
- x86系列则采用Little-endian方式存储数据。
小端字节序的意义
小端字节序对于逻辑电路更有效率。逻辑电路先处理低位字节更有效率,因为计算都是从低位开始的,计算机中的内部处理逻辑都是使用小端字节序。
但是,大多数的网络协议和文件格式都是大端字节序,这样对用户更加友好。
既然有区分,在使用时肯定要使用一定的解析规则,下面进行简要介绍。
[
](https://blog.csdn.net/a1219532602/article/details/103442437)
判断字节序的C代码
#include <stdio.h>//a, b 公用一块存储空间union un{int a; //占4字节char b;//占1字节};int main(int argc, char const *argv[]){union un myun;//a占4字节myun.a=0x12345678;printf("a = %#x\n", myun.a);printf("b = %#x\n", myun.b);if (myun.b == 0x78){printf("小端存储\n");}else{printf("大端存储\n");}return 0;}/*big-endian: return 1little-endian: return 0*/int checkEndianByInt(){int i = 0x12345678;char *c = (char *)&i;return(*c == 0x12);}/*big-endian: return 1little-endian: return 0*/int checkEndianByUnion(){union{int a;// 4 byteschar b// 1 byte} u;u.a = 1;if (u.b == 1) return 0;else return 1;}
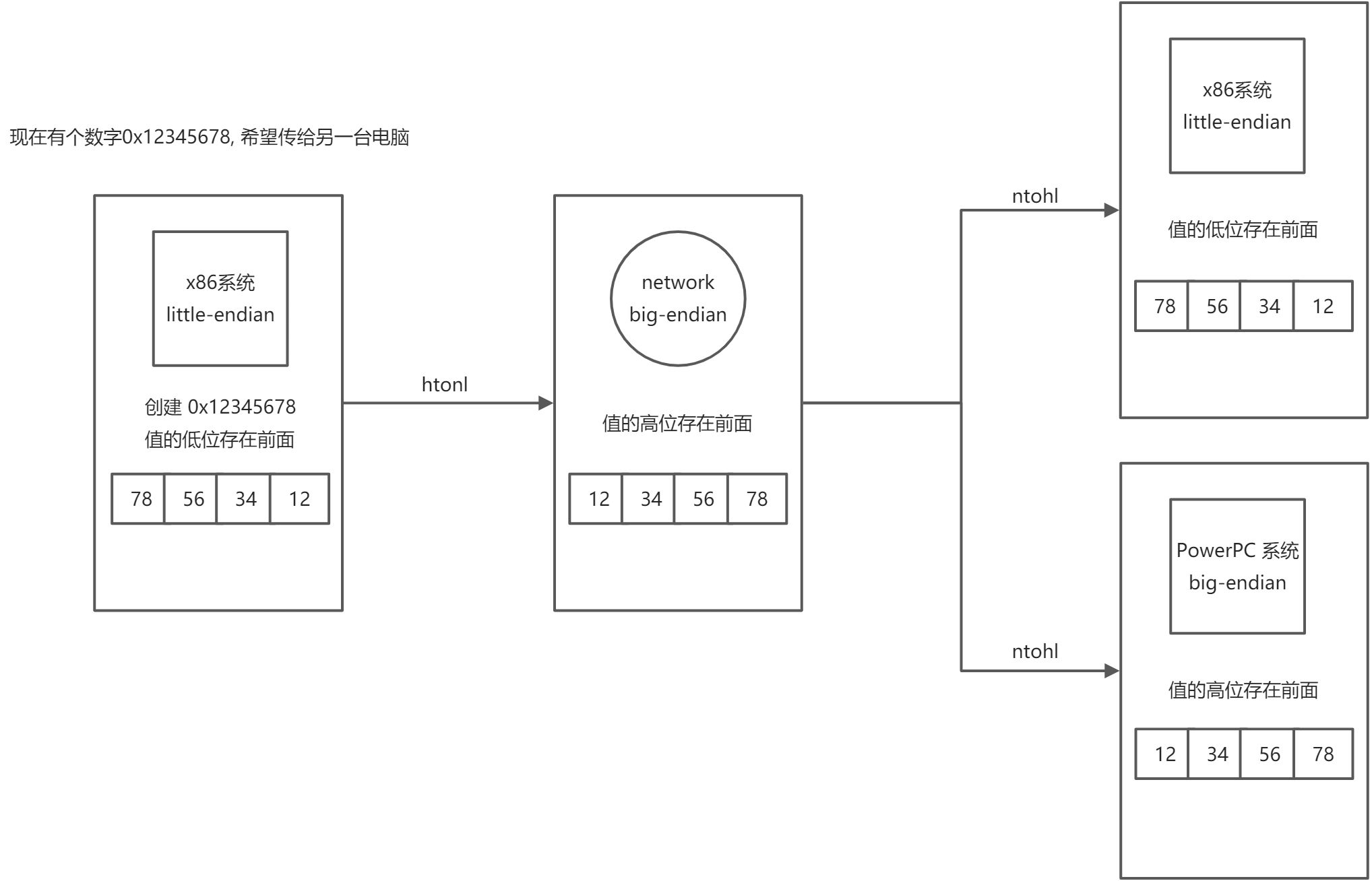
网络传输的字节序
https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E5%AD%97%E8%8A%82%E5%BA%8F/12610557
- 网络协议指定了通讯协议使用 大端存储Big-endian
字节序转换函数
- htonl : host to network 32位
- htons : host to network 16位
- ntohl : network to host 32位
- ntohs : network to host 16位
// #include <arpa/inet.h> //unix的实现#include <winsock2.h> //windows的实现#include <stdio.h>int main(int argc, char const *argv[]){unsigned int a = htonl(0x12345678);printf("a = %d\n", a);unsigned int b = ntohl(0x12345678);printf("b = %d\n", b);return 0;}
例

若有收获,就点个赞吧
0 人点赞
