Eureka Server 存在三个变量(registry、 readWriteCacheMap、readOnlyCacheMap)保存服务注册信息,默认情况下定时任务每30s将readWriteCacheMap同步至readOnlyCacheMap,每60s清理超过90s未续约的节点。Eureka Client每30s 从readOnlyCacheMap更新服务注册信息,而UI则从registry更新服务注册信息。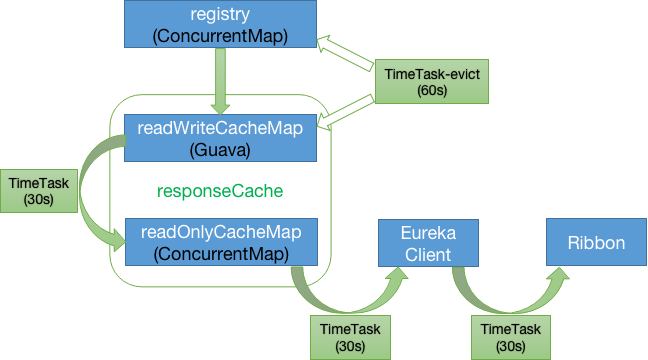
三级缓存
我们知道 Eureka Server 在运行期间就是一个普通的 Java 项目,并没有使用数据库之类的存储软件,那么在运行期间是如何存储数据的呢?
Eureka Server的数据存储分为了两层: 数据存储层和缓存层。 数据存储层记录注册到Eureka Server上的服务信息,缓存层是经过包装后的数据,可以直接在Eureka Client调用时返回。我们先来看看数据存储层的数据结构。
Eureka Server的数据存储分为了两层: 数据存储层和缓存层。 数据存储层记录注册到Eureka Server上的服务信息,缓存层是经过包装后的数据,可以直接在Eureka Client调用时返回。我们先来看看数据存储层的数据结构。
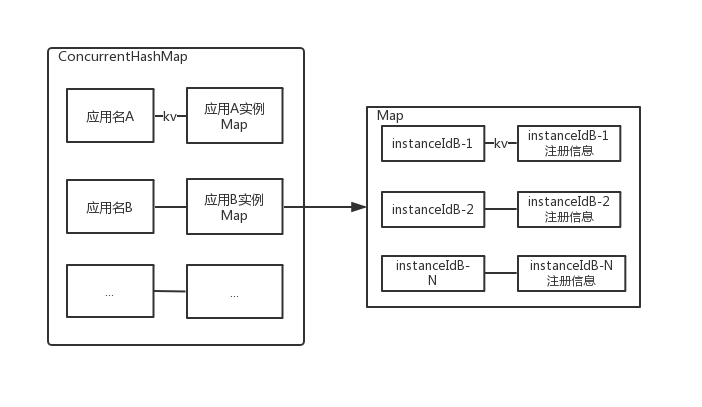
private final ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry= new ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>();
第一层的 ConcurrentHashMap 的 key=spring.application.name 也就是客户端实例注册的应用名;value 为嵌套的 ConcurrentHashMap。
第二层嵌套的 ConcurrentHashMap 的 key=instanceId 也就是服务的唯一实例 ID,value 为 Lease 对象,Lease 对象存储着这个实例的所有注册信息,包括 ip 、端口、属性等。
根据这个存储结构我们可以发现,Eureka Server第一层都是存储着所有的服务名,以及服务名对应的实例信息,也就是说第一层都是按照服务应用名这个维度来切分存储的。
应用名1:应用1实例 Map应该名2:应用2实例 Map...
第二层是根据实例的唯一ID来存储的,那么按照这个结构最终的存储数据格式为:
: 应用1实例A:实例A的注册信息应用名1:应用1实例: 应用1实例B:实例B的注册信息: 应用1实例C:实例C的注册信息: ....-----------------: 应用2实例F:实例F的注册信息应该名2:应用2实例: 应用2实例G:实例G的注册信息: ......
当如服务的状态发生变更时,会同步Eureka Server中的registry数据信息,比如服务注册,剔除服务时。
Eureka Server缓存机制
Eureka Server为了提供响应效率,提供了两层的缓存结构,将Eureka Client所需要的注册信息,直接缓存在缓存结构中。
第一层缓存: readOnlyCacheMap,本质上是ConcurrentHashMap ,依赖定时从readWriteCacheMap同步数据,默认时间为30s。
readOnlyCacheMap :是一个CureentHashMap只读缓存,这个主要是为了供客户端获取注册信息时使用,其缓存更新,依赖于定时器的更新,通过和readWriteCacheMap的值做对比,如果数据不一致,则以readWriteCacheMap的数据为准。
第二层缓存: readWriteCacheMap, 本质上是Guava缓存
readWriteCacheMap:readWriteCacheMap的数据主要同步于存储层。当获取缓存时判断缓存中是否没有数据,如果不存在此数据,则通过CacheLoader的load方法去加载,加载成功之后将数据放入缓存,同时返回数据。
readWriteCacheMap 缓存过期时间,默认为180秒,当服务下线、过期、注册、状态变更,都会来清除此缓存中的数据。
Eureka Client 获取全量或者增量的数据时,会先从一级缓存中获取;如果一级缓存中不存在,再从二级缓存中获取;如果二级缓存也不存在,这时候先将存储层的数据同步到缓存中,再从缓存中获取。
通过Eureka Server的二层缓存机制,可以非常有效地提升Eureka Server的响应时间,通过数据存储层和缓存层的数据切割,根据使用场景来提供不同的数据支持

若有收获,就点个赞吧
0 人点赞
