提供了三大核心能力:
面向接口与的远程方法调用
智能容错和负载均衡
服务自动注册和发现
服务熔断服务降级
dubbo有什么用:
在分布式系统中,服务与服务之间怎么通信是一个问题,目前主流的方式就是通过RPC或HTTP协议进行通信。像Spring Cloud就是通过http协议进行服务之间的通信,而dubbo是一个RPC框架,它实现了RPC调用。这两种方式对比起来的话,HTTP协议稍微简单点,但是由于它需要3次握手和4次挥手,性能较差,而dubbo实现的RPC,底层是用netty这种非阻塞I/O,速度会快很多。
架构设计:
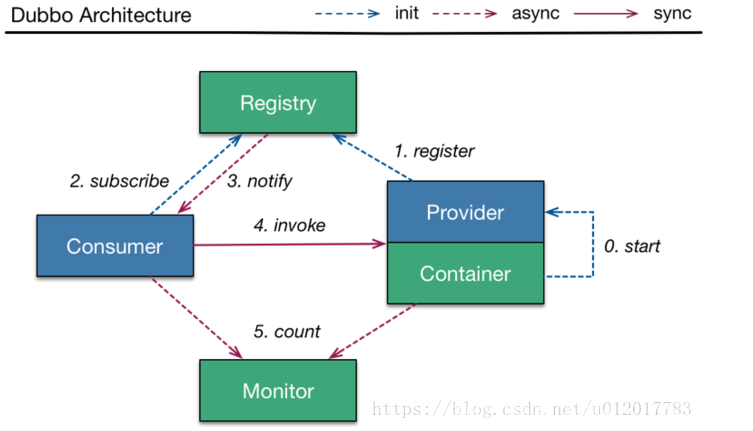
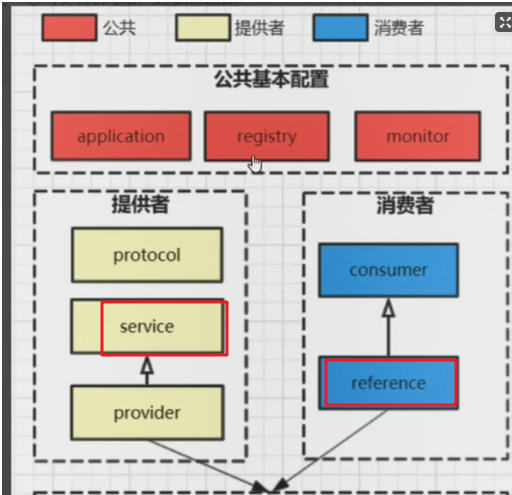
服务提供者(Provider):暴露服务的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务。
服务消费者(Consumer): 调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
注册中心(Registry):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
监控中心(Monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Container: 为dubbo的容器,
首先,写一个服务,将服务注册到注册中心,然后再写一个消费者,消费者再从注册中心获取这些提供的这些服务,然后测试消费者去调用服务者提供的这些服务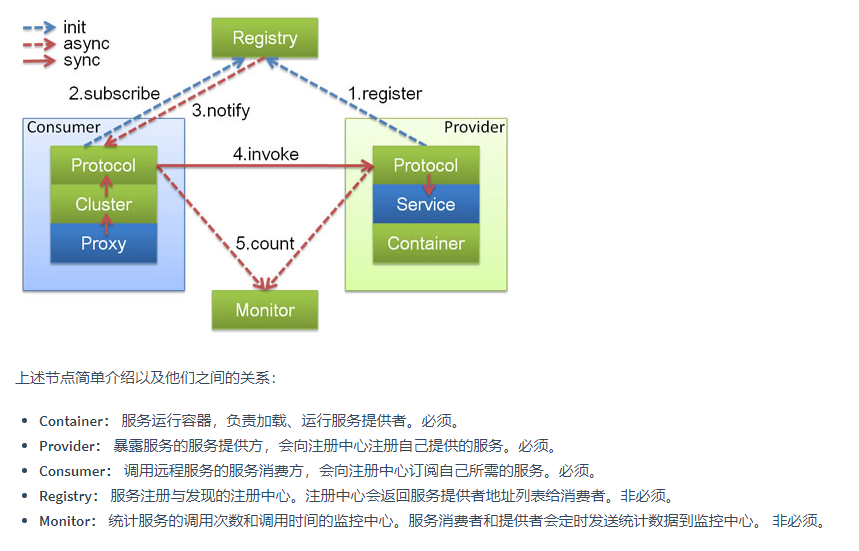
远程调用过程: 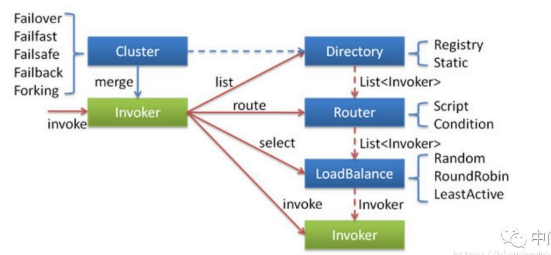
Directory服务的动态发现,基于 注册中心服务的服务注册和发现,
router: 路由,根据发现的所有服务提供者列表中进行路由选择,根据 一定的路由规则选择合适的服务提供者
LoadBalance : 进行负载均衡 随机,轮询,hash,最小活跃数
cluster集群容错:就是当从服务提供者列表中按照负载均衡算法选择一个服务提供者,进行RPC服务调用后,发送了异常后的策略,例如failover(重试)、failfast(快速失败)等
前提:
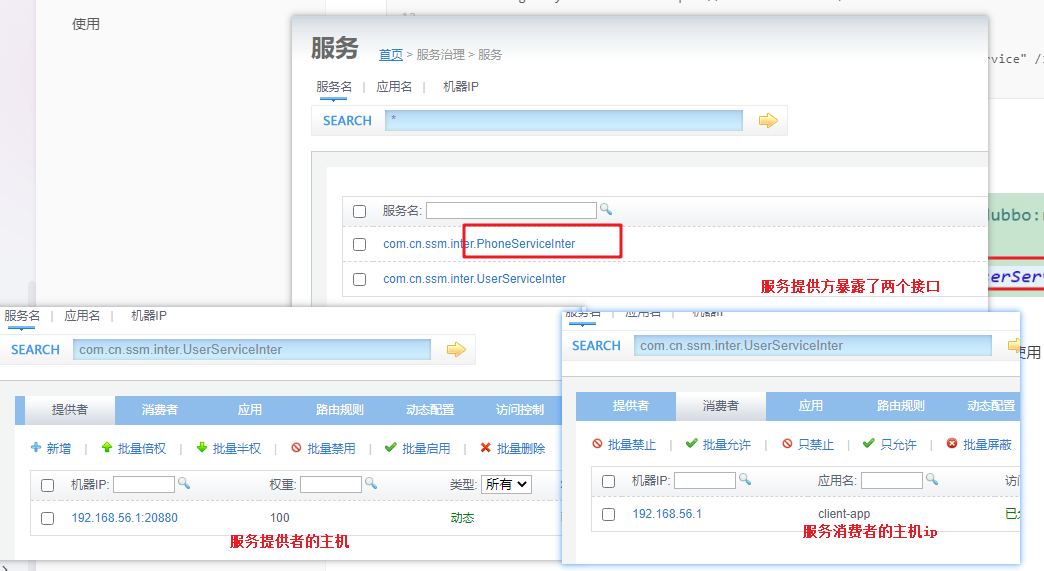
本地安装了dubbo-admin监控
在服务器上安装了zk,将dubbo-admin 监控 zk 也就是在 dubbo-admin 中配置zk的服务地址,可以实时监控zk上面所注册的消费者和提供者
将服务提供者注册到注册中心(暴露服务)
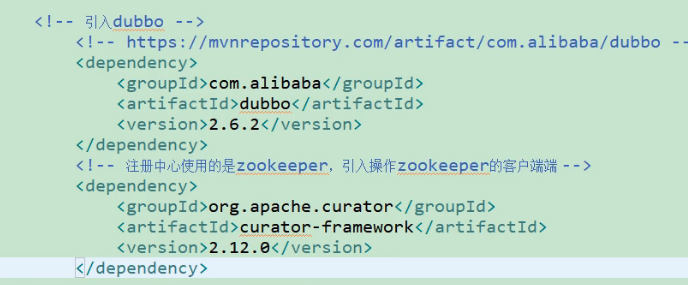
导入dubbo依赖
由于我们使用的是zookeeper做的注册中心,需要引入zookeeper的客户端
配置服务提供者:
<?xml version=”1.0” encoding=”UTF-8”?>
xmlns:dubbo=”http://dubbo.apache.org/schema/dubbo“
xsi:schemaLocation=”http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd”>
消费者:
<?xml version=”1.0” encoding=”UTF-8”?>
xmlns:dubbo=”http://dubbo.apache.org/schema/dubbo“
xsi:schemaLocation=”http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd”>
消费者如何使用:
@Service
public class CustomerService {
@Autowired<br /> UserServiceInter userServiceInter;<br /> public void usrService(){<br /> System.out.println(userServiceInter.getUsername());<br /> }<br />}
这样服务消费者在自己里面直接使用@autowired 服务提供者的服务类就可以正常使用了
当消费者访问UserService的时候Dubbo会去注册中心找到提供这个接口服务的真正位置
暴露方式二: 
上面的暴露服务使用的是Service 在消费者使用的时候使用 也需 reference 来使用
配置:
用dubbo中的@Service来暴露 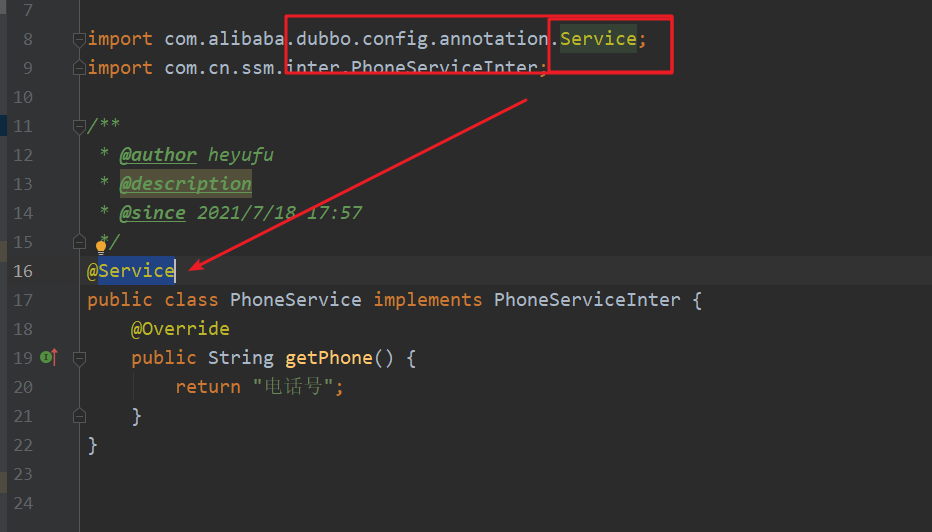
如果提供者使用这种方式来暴露接口,消费者也需要修改配置: 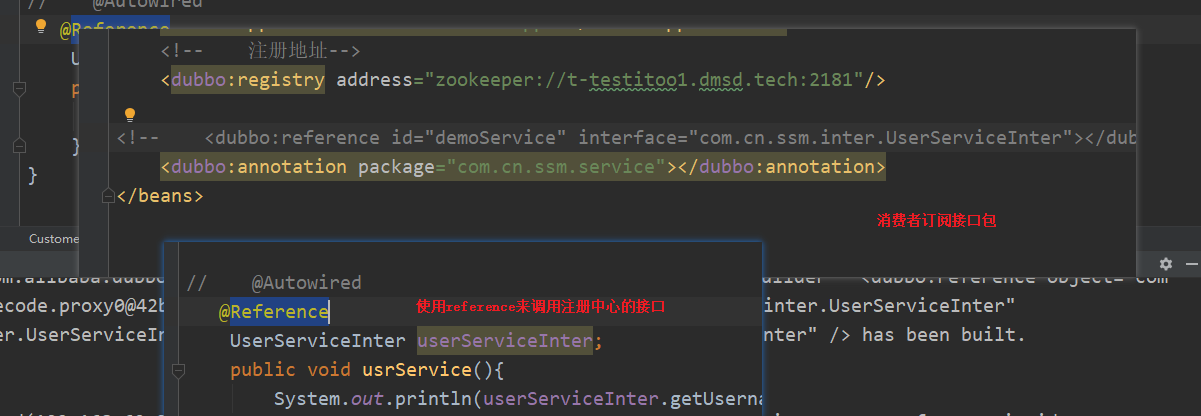
下面我们安装一下另外一个监控中心:
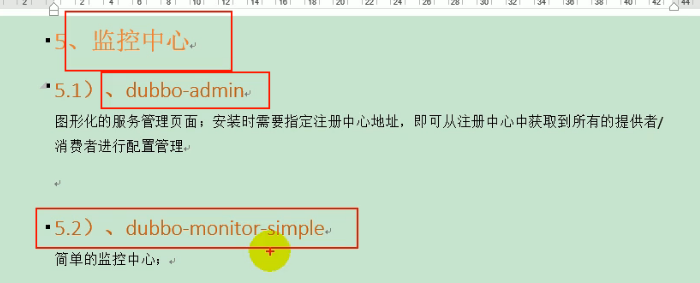
安装duboo-monitor-simple:

标签介绍:
重写优先级:
dubbo支持JVM参数,xml文件,properties文件来指定配置
spring boot中yml和properties的顺序是: 如果在相同优先级位置下先加载properties 然后加载 yml文件,他们还可以放在其他位置:
- 外置,在相对于应用程序运行目录的/congfig子目录里。
- 外置,在应用程序运行的目录里
- 内置,在config包内
- 内置,在Classpath根目录
src/main/resources/config下application.properties覆盖src/main/resources下application.properties中相同的属性
启动时检测:
当启动服务消费者的时候,如果服务提供者宕机了,那么消费者是启动不了的,我们可以设置消费者启动的时候不检查

我们在上面都是用的reference来配置调用的接口,规则需要 配置在每个reference上就很麻烦,可以 使用 
超时设置: timeout 默认是秒
当我们的服务消费者 调用提供者如果提供者的接口运行比较慢 超过了1s就会报错,我们可以自定义超时时间
我们不光可以给接口整体设置超时属性,还可以具体到某一个方法:
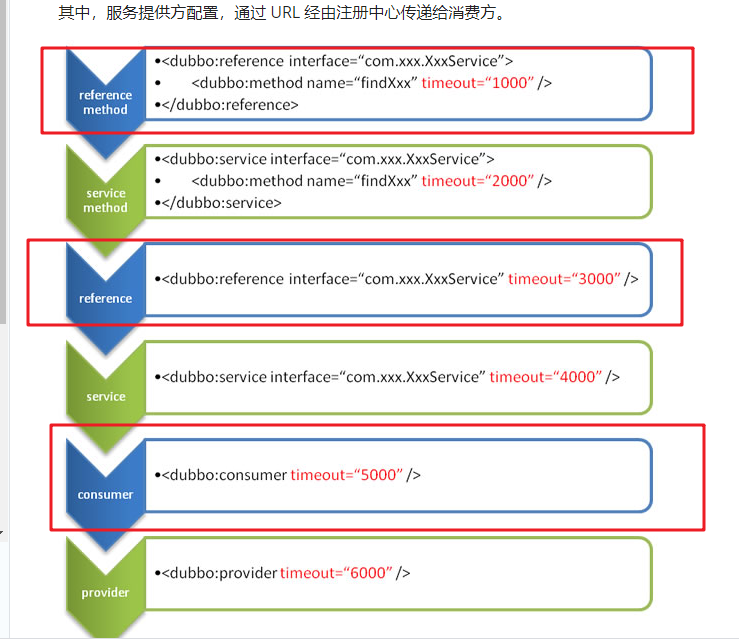
属性配置的 优先级:
- 方法级优先,接口级次之,全局配置再次之。
- 如果级别一样,则消费方优先,提供方次之。(服务提供者也可以设置超时时间,如果消费者和提供者同样都设置了,以消费者的为准)
重试次数: retries 一般和超时时间配合使用,不包含第一次调用,默认是2次
假如这个时候我们有三台 服务器都部署了服务提供方,那么假如第一次失败了,不会在一棵树上吊死,而是会去利用剩余的重试次数去调用其他服务器的提供者服务
我们规定重试次数只有在幂等的请求上才设置,在非幂等不设置重试次数
幂等: 查询,删除,修改, 每次的效果都是一样的
非幂等: 新增
多版本:(实现灰度发布)
灰度发布(又名金丝雀发布)是指在黑与白之间,能够平滑过渡的一种发布方式。在其上可以进行A/B testing,即让一部分用户继续用产品特性A,一部分用户开始用产品特性B,如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面来。灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度。灰度发布开始到结束期间的这一段时间,称为灰度期。
当一个接口实现,出现不兼容升级时,可以用版本号过渡,版本号不同的服务相互间不引用。
可以按照以下的步骤进行版本迁移:
- 在低压力时间段,先升级一半提供者为新版本
- 再将所有消费者升级为新版本
- 然后将剩下的一半提供者升级为新版本
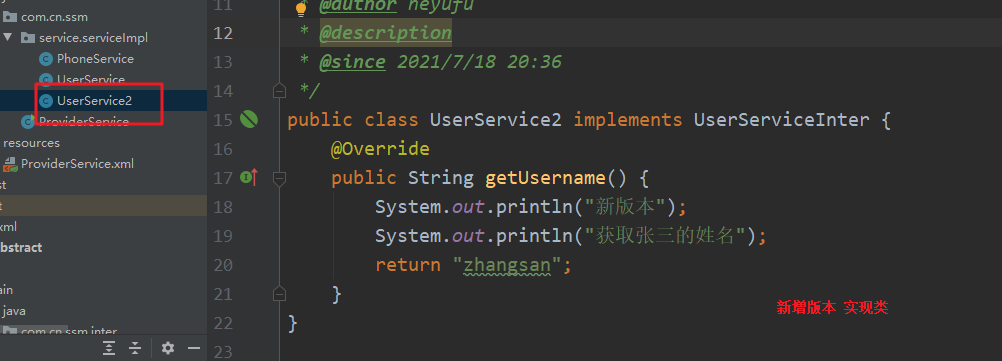
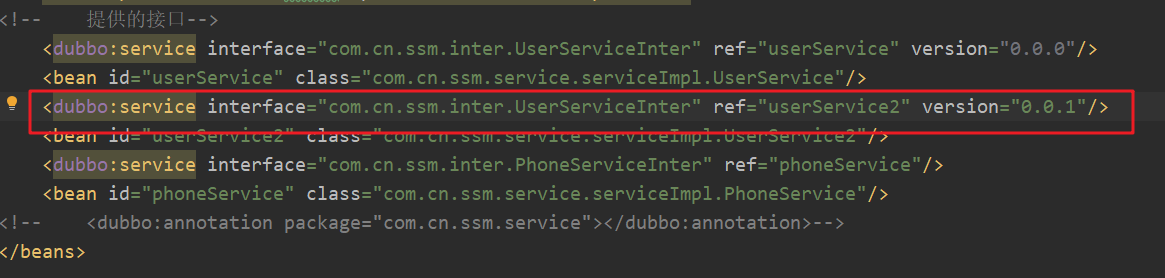
通过给客户端指定版本来区分是新版本还是老版本:
也可以用平滑的方式: 将 version设置为* 也就是 新老都可以调用
将当前服务的接口class路径做key value 为实际
可以根据方法的参数来实现路由
https://blog.csdn.net/xx123698/article/details/106006160?utm_term=dubbo%E5%A6%82%E4%BD%95%E5%AE%9E%E7%8E%B0%E7%81%B0%E5%BA%A6%E5%8F%91%E5%B8%83&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~sobaiduweb~default-2-106006160&spm=3001.4430
路由规则:
- 条件路由: 官网:https://dubbo.apache.org/zh/docs/v2.7/user/examples/routing-rule/
- 标签路由:
- 脚本路由: 可以通过脚本路由的方式来实现灰度发布
动态路由配置两种方式:
- 可以通过api来设置:
RegistryFactory registryFactory = ExtensionLoader.getExtensionLoader(RegistryFactory.class).getAdaptiveExtension();
Registry registry = registryFactory.getRegistry(URL.valueOf(“zookeeper://10.20.153.10:2181”));
registry.register(URL.valueOf(“condition://0.0.0.0/com.foo.BarService?category=routers&dynamic=false&rule=”+ URL.encode(“http://10.20.160.198/wiki/display/dubbo/host = 10.20.153.10 => host = 10.20.153.11”) + “));
以上代码的规则,概括就是:对于所有调用com.foo.BarService接口的消费者,如果消费者的ip是”10.20.153.10“,那么这个消费者将调用ip为”10.20.153.11“的提供者,这样,通过动态配置注册中心的路由规则,就实现了动态指定某个提供者的需求。
本地存根:
相当于AOP中的环绕通知:
- 消费者发起调用
- 如果消费者中存在本地存根,就会先执行本地存根
- 然后调用服务提供者
原理:
远程服务后,客户端通常只剩下接口,而实现全在服务器端,但提供方有些时候想在客户端也执行部分逻辑,那么就在服务消费者这一端提供了一个Stub类,然后当消费者调用provider方提供的dubbo服务时,客户端生成 Proxy 实例,这个Proxy实例就是我们正常调用dubbo远程服务要生成的代理实例,然后消费者这方会把 Proxy 通过构造函数传给 消费者方的Stub ,然后把 Stub 暴露给用户,Stub 可以决定要不要去调 Proxy。会通过代理类去完成这个调用,这样在Stub类中,就可以做一些额外的事,来对服务的调用过程进行优化或者容错的处理。


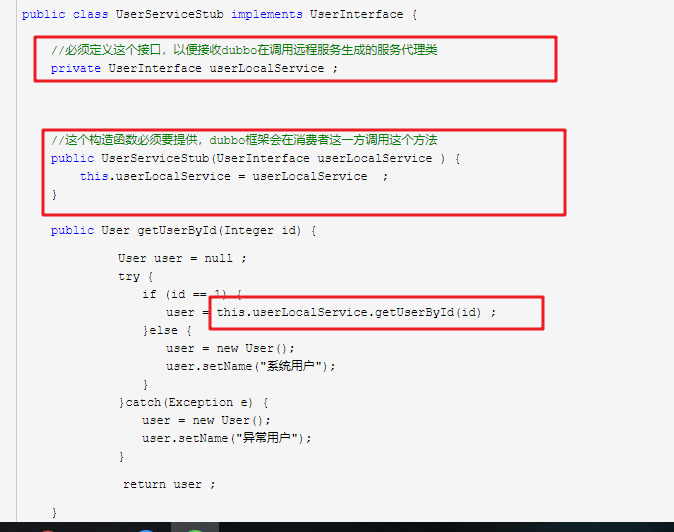
dubbo和springboot的使用:
dubbo与springboot整合的三种方式
1、将服务提供者注册到注册中心(如何暴露服务)
1.1导入Dubbo的依赖 和 zookeeper 客户端
2、让服务消费者去注册中心订阅服务提供者的服务地址
Springboot与Dubbo整合的三种方式
2.1导入dubbo-starter。在application.properties配置属性,使用@Service【暴露服务】,使用@Reference【引用服务】
2.2保留Dubbo 相关的xml配置文件
导入dubbo-starter,使用@ImportResource导入Dubbo的xml配置文件
3、使用 注解API的方式
将每一个组件手动配置到容器中,让dubbo来扫描其他的组件
Dubbo的RPC隐式参数调用
由于ThreadLocal是本地线程隔离级别的,所以对于服务调用是无法传递参数的
https://www.yuque.com/docs/share/de82d42a-54ea-4c5c-b772-f207347186c2?# 《RPC调用,session传递解决方案一:(Dubbo+Spring Redis Session)》
利用RpcContext是ThreadLocal的临时状态记录器,
分别在消费端和服务端中定义过滤器当接收到 RPC 请求,或发起 RPC 请求时,RpcContext 的状态都会变化。比如:A 调 B,B 再调 C,则 B 机器上,在 B 调 C 之前,RpcContext 记录的是 A 调 B 的信息,在 B 调 C 之后,RpcContext 记录的是 B 调 C 的信息。
提供者: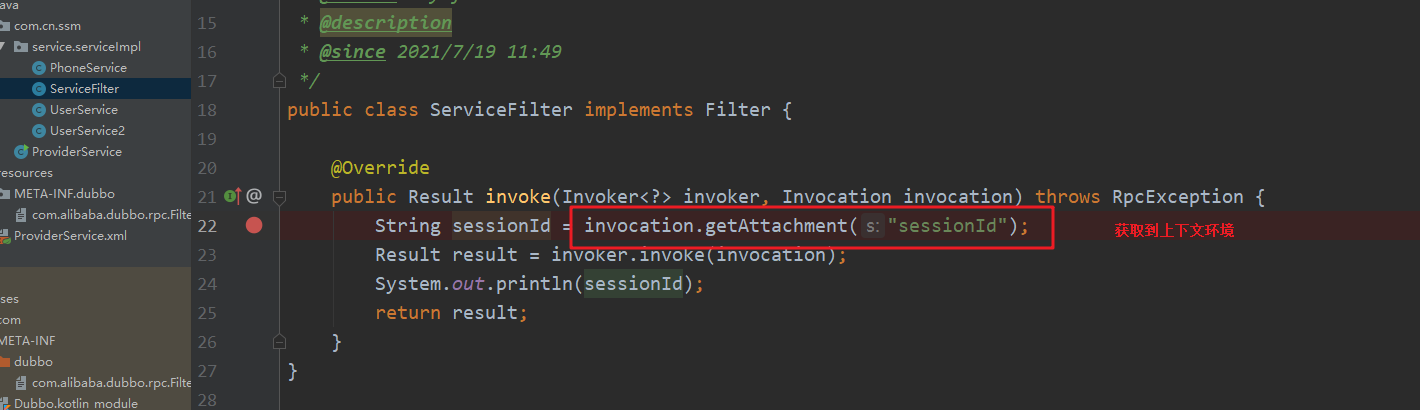
消费者: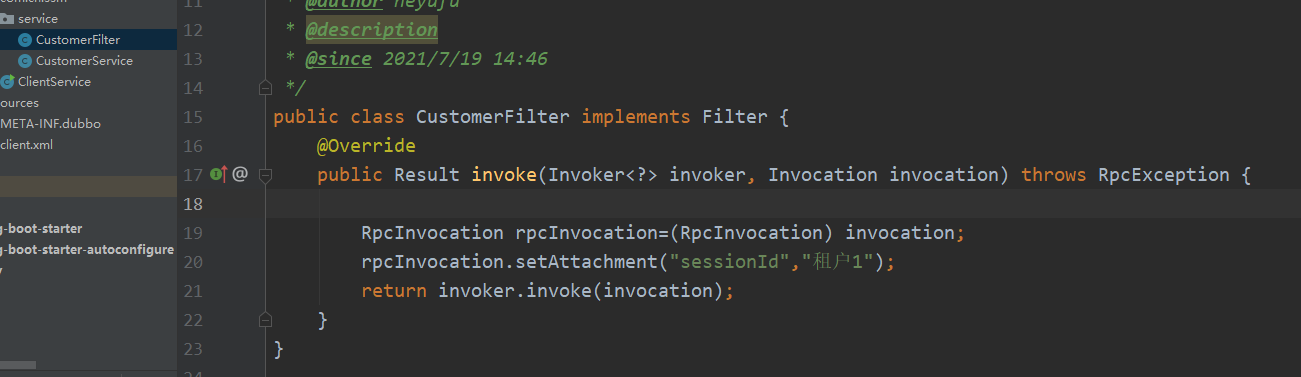

我们一般用dubbo的过滤器来做统一的入口
//服务提供方使用,获取参数
RpcContext.getContext().getAttachments()
//服务器消费方使用,设置参数
RpcContext.getContext().setAttachment()
//调接口时,必须是A直接到B,如果A没有直接到B,而是先到C,再由C到B,那么在B里getAttachment()获取不到值
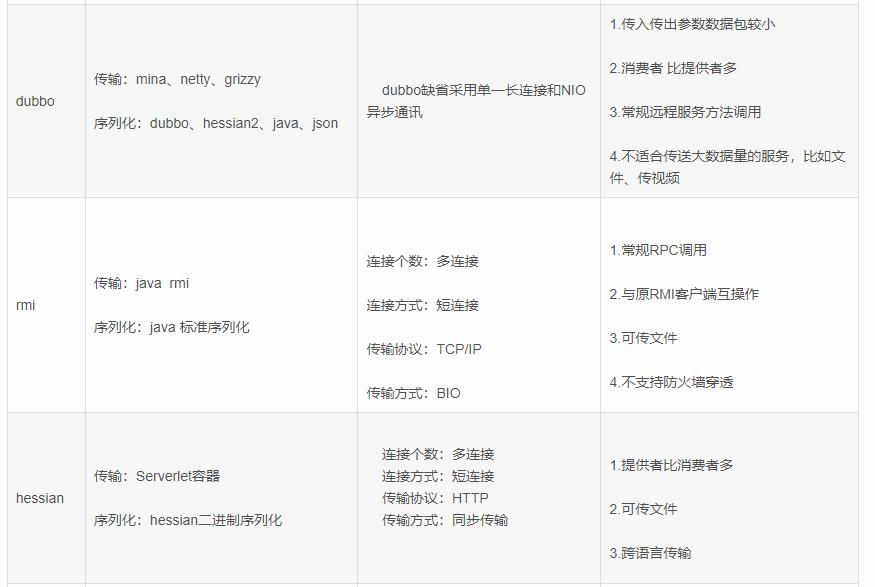
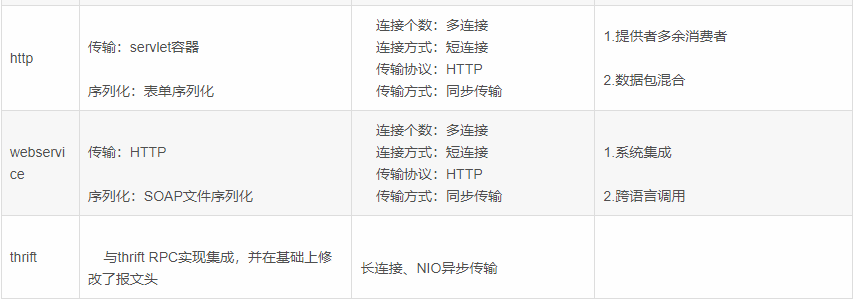
传输协议:

高可用:
1.zookeeper宕机:

1、【提供者】在 【启动】 时,向注册中心zk 【注册】 自己提供的服务。
2、【消费者】在【启动】时,向注册中心zk 【订阅】自己所需的服务。
如果zk做注册中心,注册中心全部宕机了发布者和订阅者之间还能继续通信吗?
可以的,消费者在启动时,消费者会从zk拉取注册的生产者的地址接口等数据,缓存在本地。
每次调用时,按照本地存储的地址进行调用
消费者本地有一个生产者的列表,他会按照列表继续工作,倒是无法从注册中心去同步最新的服务列表,短期的注册中心挂掉是不要紧的,但一定要尽快修复
挂掉是不要紧的,但前提是你没有增加新的服务,如果你要调用新的服务,则是不能办到的
2. 集群下Dubbo负载均衡配置:
- 基于权重的随机负载均衡机制: 默认
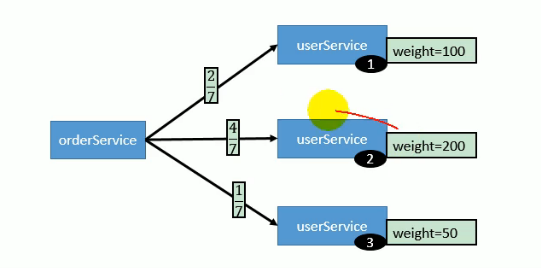
先统计所有服务器上该接口方法的权重总和,然后对这个总和随机nextInt一下,看生成的随机数落到哪个段内,就调哪个服务器上的该服务。
https://blog.csdn.net/qq_23864915/article/details/90524467
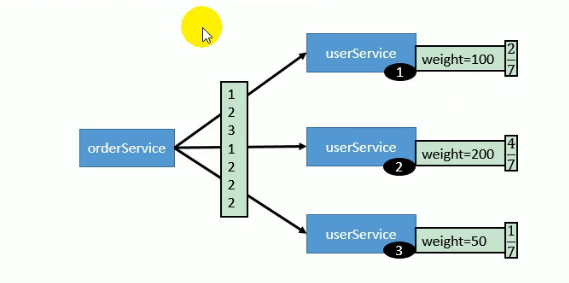
- 基于权重的轮询负载均衡机制:
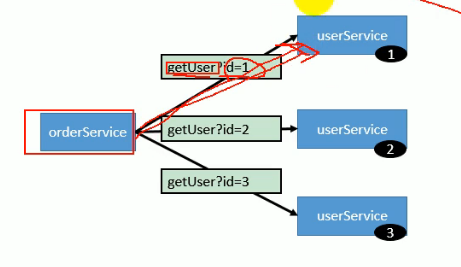
- 一致性hash负载均衡机制:
- 最小活跃数负载均衡:
我这么说吧!初始状态下所有服务提供者的活跃数均为 0(每个服务提供者的中特定方法都对应一个活跃数,我在后面的源码中会提到),每收到一个请求后,对应的服务提供者的活跃数 +1,当这个请求处理完之后,活跃数 -1。
因此,Dubbo 就认为谁的活跃数越少,谁的处理速度就越快,性能也越好,这样的话,我就优先把请求给活跃数少的服务提供者处理。
假如活跃数相同,就走随机
因为我们如果采用默认的方式,是可以在dubbo中调节权重的
https://www.cnblogs.com/wyq178/p/9822731.html
Dubbo服务降级
当服务器压力剧增的情况下,根据实际业务情况和流量,对一些服务和页面有策略的不处理或换种简单的处理方式,
假设现在服务器上有三个服务,服务A服务B服务C, 现在想牺牲服务C为AB提供高可用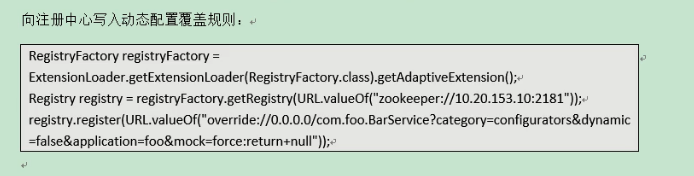
- mock=force:return+null 表示消费者对该服务的调用直接返回null,不发起远程调用,用来屏蔽不重要的服务
- mock=fail:return:null 表示消费方对该服务调用失败之后再返回null
我们可以直接在dubbo监控页面进行设置:
屏蔽调用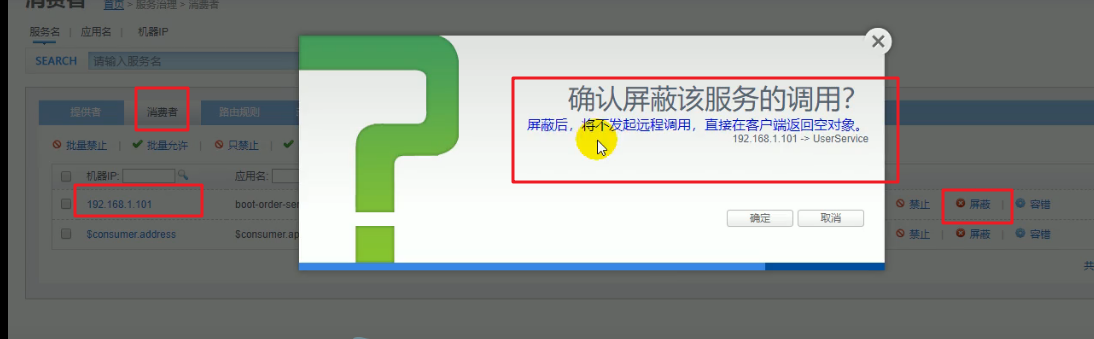
容错: 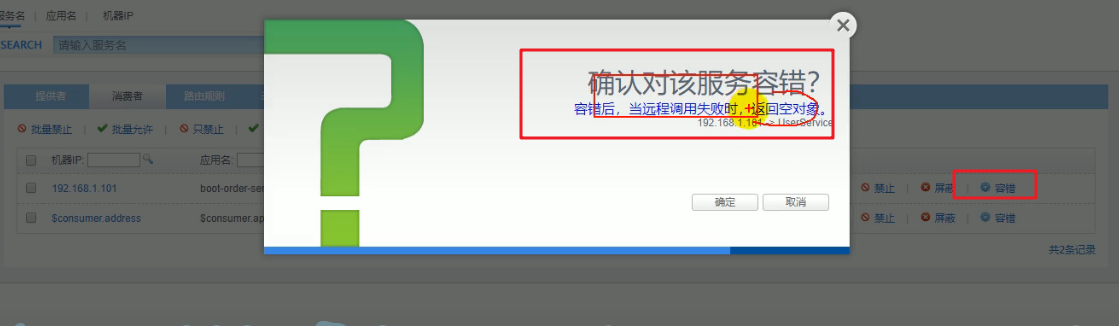
什么是容错: 当我们消费者访问提供者一个接口的时候,如果提供者时间超过1s会出现错误页面,添加容错就会
故障降级: 比如调用的远程服务挂了,网络故障、或者RPC服务返回异常。 那么可以直接降级,降级的方案比如设置默认值、采用兜底数据
限流降级: 在秒杀这种流量比较集中并且流量特别大的情况下,因为突发访问量特别大可能会导致系统支撑不了。这个时候可以采用限流来限制访问量。当达到阀值时,后续的请求被降级
dubbo提供了mock配置主要有两种配置方式:
- 在远程调用异常时,服务端直接返回一个固定的字符串(也就是写死的字符串)

- 消费者增加Mock类实现要被降级的类,要对那个服务做降级,就实现哪个接口:
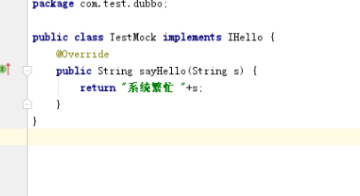
通过超时异常来模拟服务异常超时的场景。设置timeout 为1 访问服务肯定会超时 ,超时后将执行TestMock中的实现 来降级。当服务端故障解除以后(timeout设置为1000),调用过程将恢复正常

集群容错
通过整合Hystrix来容错:
在消费者和提供者都引入hystrix-start
在提供服务的方法上添加@HystrixCommand
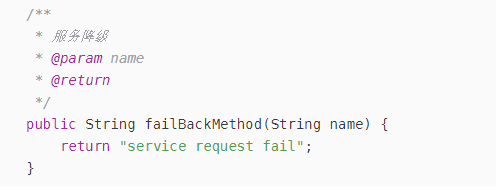
在消费者中添加兜底方法
@HystrixCommand(fallbackMethod = “failBackMethod”)
public String sayHello(@RequestParam String name) {
return demoService.defaultMethod(name);
}
学习博客:
https://blog.csdn.net/qq_41157588/article/details/106737191
https://www.cnblogs.com/syp172654682/p/8964068.html

若有收获,就点个赞吧
0 人点赞
