Hadoop
Hadoop框架中最核心的设计是为海量数据提供存储的HDFS和对数据进行计算的MapReduce
MapReduce的作业主要包括:(1)从磁盘或从网络读取数据,即IO密集工作;(2)计算数据,即CPU密集工作
Hadoop集群的整体性能取决于CPU、内存、网络以及存储之间的性能平衡。因此运营团队在选择机器配置时要针对不同的工作节点选择合适硬件类型
一个基本的Hadoop集群中的节点主要有
•NameNode:负责协调集群中的数据存储
•DataNode:存储被拆分的数据块
•JobTracker:协调数据计算任务
•TaskTracker:负责执行由JobTracker指派的任务
•SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
在集群中,大部分的机器设备是作为Datanode和TaskTracker工作的
HDFS
分布式文件系统在物理结构上是由计算机集群中的多个节点构成的,这些节点分为两类,一类叫“主节点”(Master Node)或者也被称为“名称结点”(NameNode),另一类叫“从节点”(Slave Node)或者也被称为“数据节点”(DataNode)
读文件代码
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set(“fs.defaultFS”,”hdfs://localhost:9000”);
conf.set(“fs.hdfs.impl”,”org.apache.hadoop.hdfs.DistributedFileSystem”);
FileSystem fs = FileSystem.get(conf);
Path file = new Path(“test”);
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content = d.readLine(); //读取文件一行
System.out.println(content);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
写文件代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set(“fs.defaultFS”,”hdfs://localhost:9000”);
conf.set(“fs.hdfs.impl”,”org.apache.hadoop.hdfs.DistributedFileSystem”);
FileSystem fs = FileSystem.get(conf);
byte[] buff = “Hello world”.getBytes(); // 要写入的内容
String filename = “test”; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
System.out.println(“Create:”+ filename);
os.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Hbase
HBase与传统的关系数据库的区别主要体现在以下几个方面:
(1)数据类型:关系数据库采用关系模型,具有丰富的数据类型和存储方式,HBase则采用了更加简单的数据模型,它把数据存储为未经解释的字符串
(2)数据操作:关系数据库中包含了丰富的操作,其中会涉及复杂的多表连接。HBase操作则不存在复杂的表与表之间的关系,只有简单的插入、查询、删除、清空等,因为HBase在设计上就避免了复杂的表和表之间的关系
(3)存储模式:关系数据库是基于行模式存储的。HBase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的
HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧有的版本仍然保留(这是和HDFS只允许追加不允许修改的特性相关的)
•表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
•行:每个HBase表都由若干行组成,每个行由行键(row key)来标识。
•列族:一个HBase表被分组成许多“列族”(Column Family)的集合,它是基本的访问控制单元
•列限定符:列族里的数据通过列限定符(或列)来定位
•单元格:在HBase表中,通过行、列族和列限定符确定一个“单元格”(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
•时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
•HBase中需要根据行键、列族、列限定符和时间戳来确定一个单元格,因此,可以视为一个“四维坐标”,
即[行键, 列族, 列限定符, 时间戳]
表中的每个行区间构成一个Region,同一个Region不会被分拆到多个Region服务器
每个Region服务器存储10-1000个Region
元数据表,又名.META.表,存储了Region和Region服务器的映射关系
当HBase表很大时, .META.表也会被分裂成多个Region
根数据表,又名-ROOT-表,记录所有元数据的具体位置
-ROOT-表只有唯一一个Region,名字是在程序中被写死的
Zookeeper文件记录了-ROOT-表的位置(客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息,大多数客户端甚至从来不和Master通信)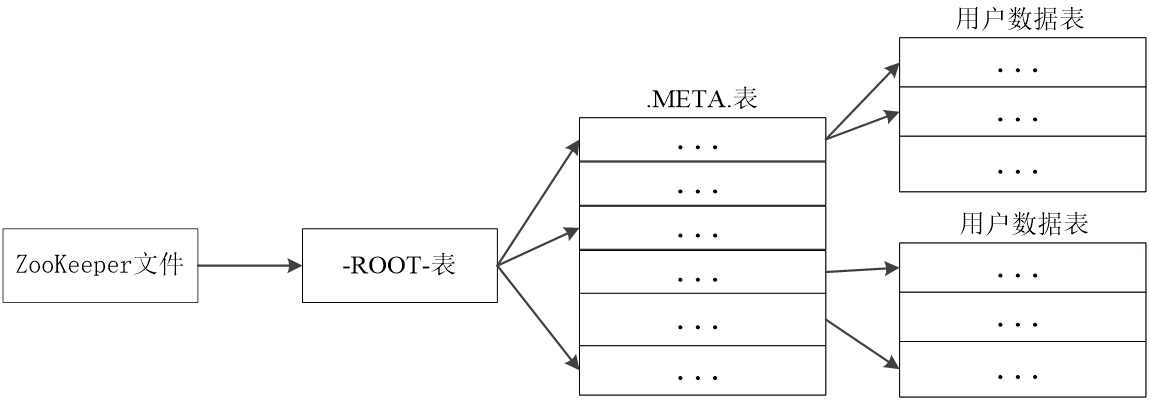

计算: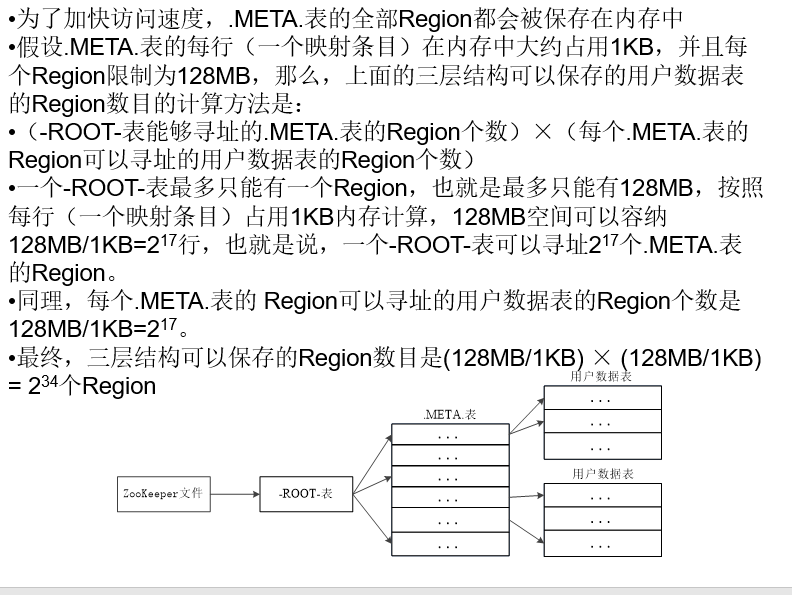
shell命令:
例子1:创建一个表,该表名称为tempTable,包含3个列族f1,f2和f3
例子2:继续向表tempTable中的第r1行、第“f1:c1”列,添加数据值为“hello,dblab”
例子3:
(1)从tempTable中,获取第r1行、第“f1:c1”列的值
(2)从tempTable中,获取第r1行、第“f1:c3”列的值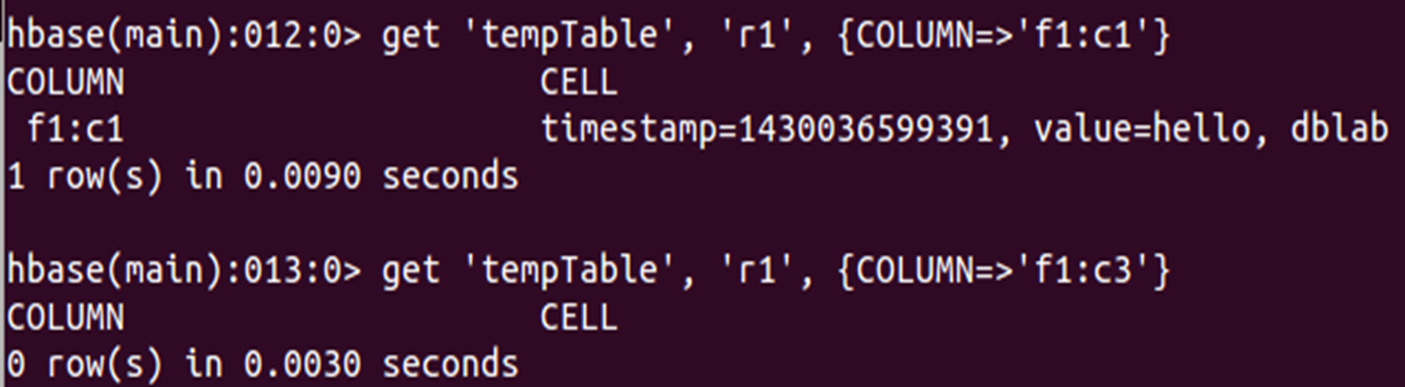
例子4:使表tempTable无效、删除该表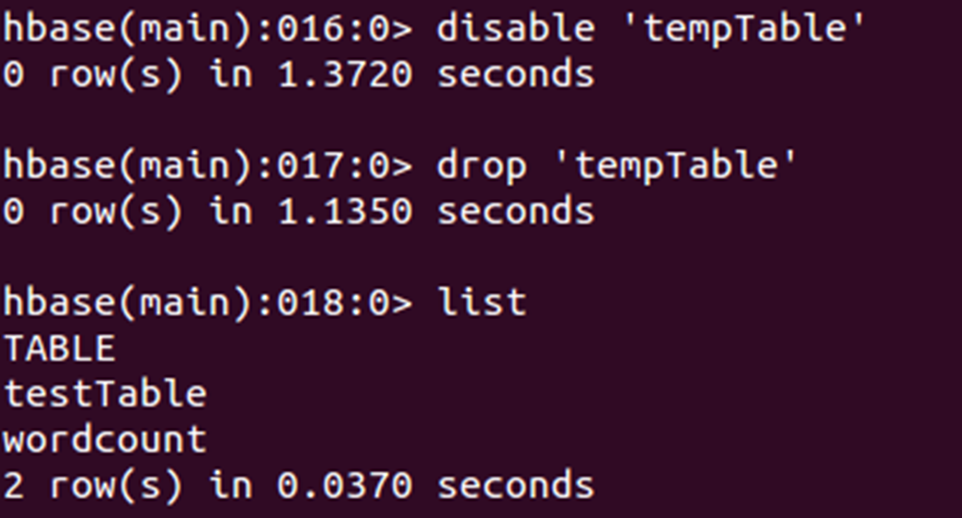
NoSQL
特点
NoSQL数据库具有以下几个特点:
(1)灵活的可扩展性
(2)灵活的数据模型
(3)与云计算紧密融合
优势:可以支持超大规模数据存储,灵活的数据模型可以很好地支持Web2.0应用,具有强大的横向扩展能力等
劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现事务强一致性,很难实现数据完整性,技术尚不成熟,缺乏专业团队的技术支持,维护较困难等
•Hadoop就是针对数据分析
•MongoDB(文档数据库)、Redis(键值数据库)等是针对在线业务,两者都抛弃了关系模型
三大基石
CAP

一个分布式系统不可能同时满足一致性、可用性和分区容忍性这三个需求,最多只能同时满足其中两个
BASE
说起BASE(Basically Availble, Soft-state, Eventual consistency),不得不谈到ACID。
| ACID | BASE |
|---|---|
| 原子性(Atomicity) | 基本可用(Basically Available) |
| 一致性(Consistency) | 软状态/柔性事务(Soft state) |
| 隔离性(Isolation) | 最终一致性 (Eventual consistency) |
| 持久性 (Durable) |
一个数据库事务具有ACID四性:
- A(Atomicity):原子性,是指事务必须是原子工作单元,对于其数据修改,要么全都执行,要么全都不执行
- C(Consistency):一致性,是指事务在完成时,必须使所有的数据都保持一致状态
- I(Isolation):隔离性,是指由并发事务所做的修改必须与任何其它并发事务所做的修改隔离
- D(Durability):持久性,是指事务完成之后,它对于系统的影响是永久性的,该修改即使出现致命的系统故障也将一直保持
BASE的基本含义是基本可用(Basically Availble)、软状态(Soft-state)和最终一致性(Eventual consistency):
- 基本可用,是指一个分布式系统的一部分发生问题变得不可用时,其他部分仍然可以正常使用,也就是允许分区失败的情形出现
- “软状态(soft-state)”是与“硬状态(hard-state)”相对应的一种提法。数据库保存的数据是“硬状态”时,可以保证数据一致性,即保证数据一直是正确的。“软状态”是指状态可以有一段时间不同步,具有一定的滞后性
最终一致性,允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,必须最终读到更新后的数据。 最常见的实现最终一致性的系统是DNS(域名系统)。
最终一致性
最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,又可以区分为:
会话一致性:它把访问存储系统的进程放到会话(session)的上下文中,只要会话还存在,系统就保证“读己之所写”一致性。如果由于某些失败情形令会话终止,就要建立新的会话,而且系统保证不会延续到新的会话
单调写一致性:系统保证来自同一个进程的写操作顺序执行。系统必须保证这种程度的一致性,否则就非常难以编程了
MapReduce
摩尔定律:CPU性能大约每隔18个月翻一番
但是最近开始失效了,所以开始借助于分布式并行编程来提高程序性能。
MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
MapReduce采用“分而治之”策略,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理
MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”
Hadoop框架是用Java实现的,但是,MapReduce应用程序则不一定要用Java来写工作流程

不同的Map任务之间不会进行通信
- 不同的Reduce任务之间也不会发生任何信息交换
- 用户不能显式地从一台机器向另一台机器发送消息
- 所有的数据交换都是通过MapReduce框架自身去实现的


Split
等量划分本节点上的资源量(CPU、内存等)
HDFS 以固定大小的block 为基本单位存储数据,而对于MapReduce 而言,其处理单位是split。split 是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。
Map任务数量
Hadoop为每个split创建一个Map任务,split 的多少决定了Map任务的数目。大多数情况下,理想的分片大小是一个HDFS块
Reduce任务的数量
最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目
通常设置比reduce任务槽数目稍微小一些的Reduce任务个数(这样可以预留一些系统资源处理可能发生的错误)
适用的情况:
•关系代数运算(选择、投影、并、交、差、连接)
•分组与聚合运算
•矩阵-向量乘法
•矩阵乘法
编程









Hive
Hive是一个构建于Hadoop顶层的数据仓库工具
某种程度上可以看作是用户编程接口,本身不存储和处理数据
依赖分布式文件系统HDFS存储数据
依赖分布式并行计算模型MapReduce处理数据
Spark
特点
- 运行速度快
- 容易使用
- 通用性
-
和Hadop的对比
Hadoop最主要的缺陷是Map Reduce计算模型延迟过高,无法胜任实时、快速计算的需求,只适用于离线批处理
Hadoop存在以下缺陷: 表达能力有限 (计算都必须转化成Map和Reduce两个操作,但不适用于所有情况)
- 磁盘IO开销大 (每次执行都需要从磁盘读取数据,中间结果也要写入磁盘)
- 延迟高
相比之下,spark的优点:
- Spark的计算模式也属于MapReduce,但不局限于~,还提供了多种数据集操作类型,更灵活
- Spark提供了内存计算,中间结果直接存放在内存
- 基于DAG的任务调度执行机制,优于Map Reduce的迭代执行机制
但是,Spark并不能完全替代Hadoop,主要用于替代Hadoop中的Map Reduce计算模型,实际上,Spark已经很好的融入了Hadoop生态系统。
Spark生态系统
能同时支持批处理(Map reduce)、交互式查询(Impala)、流数据处理(Storm框架)
Spark运行架构
包括:

若有收获,就点个赞吧
0 人点赞
