Redis集群
redis在业务场景现在使用越来越广泛,作为运维人员在生产环境一定要确保业务系统的稳定、高效运行,这样就不得不提及根据需求随之出现的集群相关技术。它的出现一是避免单点故障,二是提高业务系统性能。
一. Redis集群方案介绍
在互联网发展的今天,网站的稳定性和高可用性不言而喻,随着技术的发展,集群方案层出不穷,目前Redis集群实现一般有客户端分片、代理分片和服务器端分片三种解决方案。
1.1 客户端分片(集群方案)
这种方案将分片工作放在业务程序端,程序代码根据预先设置的路由规则,直接对多个redis实例进行分布式访问。这样的好处是,不依赖于第三方分布式中间件,实现方法和代码都自己掌控,可随时调整,不用担心踩到坑。这实际上是一种静态分片技术。redis实例的增减,都得手工调整分片程序。基于此分片机制的开源产品,现在仍不多见。这种分片机制的性能比代理式更好(少了一个中间分发环节)。但缺点是升级麻烦,对研发人员的个人依赖性强,需要有较强的程序开发能力做后盾。如果主力程序员离职,可能新的负责人会选 择重写一遍。所以,这种方式下可运维性较差。出现故障,定位和解决都得研发和运维配合解决,故障时间变长。因此这种方案,难以进行标准化运维,不太适合中小公司。
1.2 代理分片(集群方案)
这种方案,将分片工作交给专门的代理程序来做。代理程序接收到来自业务程序的数据请求,根据路由规则,将这些请求分发给正确的redis实例并返回给业务程序。这种机制下,一般会选用第三方代理程序(而不是自己研发),因为后端有多个Redis实例,所以这类程序又称为分布式中间件。这样的好处是,业务程序不用关心后端Redis实例,运维起来也方便。虽然会因此带来些性能损耗,但对于redis这种内存读写型应用,相对而言是能容忍的。 这是我们推荐的集群实现方案。像基于该机制的开源产品Twemproxy,Codis 便是其中代表,应用非常广泛。
Twemproxy是一种代理分片机制,由Twitter开源。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis服务器,再原路返回。这个方案顺理成章地解决了单个redis实例承载能力的问题。当然,Twemproxy本身也是单点,需要用keepalived做高可用方案。这么些年来,Twemproxy是应用范围最广、稳定性最高、最久经考验的分布式中间件。
只是它还有诸多不方便之处。Twemproxy最大的痛点在于,无法平滑地扩容/缩容。这样增加了运维难度:业务量突增,需增加Redis服务器;业务量萎缩,需要减少redis服务器。但对Twemproxy而言,基本上都很难操作。或者说,Twemproxy更加像服务器端静态sharding。有时为了规避业务量突增导致的扩容需求,甚至被迫新开一个基于Twemproxy的redis集群。Twemproxy另一个痛点是,运维操作不友好,甚至没有控制面板。当然,由于使用了中间件代理,相比客户端直接连服务器方式,性能上有所损耗,实测结果降低了20%左右。
Codis由豌豆荚于2014年11月开源,基于Go和C开发,是近期涌现的、国人开发的优秀开源软件之一。现已广泛用于豌豆荚的各种Redis业务场景,从各种压力测试来看,稳定性符合高效运维的要求。性能更是改善很多,最初比Twemproxy慢20%;现在比Twemproxy快近100%(条件:多实例,一般Value长度)。Codis具有可视化运维管理界面。Codis无疑是为解决Twemproxy缺点而出的新解决方案。因此综合方面会优于Twemproxy很多。目前也越来越多公司选择Codis。Codis引入了Group的概念,每个Group包括1个redis master及至少1个redis slave,这是和Twemproxy的区别之一。这样做的好处是,如果当前Master 有问题,则运维人员可通过Dashboard“自助式”切换到Slave,而不需要小心翼翼地修改程序配置文件。为支持数据热迁移(Auto Rebalance),出品方修改了redis Server源码,并称之为Codis Server。Codis采用预先分片(Pre-Sharding)机制,事先规定好了,分成1024个slots(也就是说,最多能支持后端1024个Codis Server),这些路由信息保存在zookeeper中。不足之处有对redis源码进行了修改,以及代理实现本身会有的问题。
1.3 服务器端分片(集群方案)
随着redis版本的发展,服务器端分片技术成熟,建立在基于无中心分布式架构之上(没有代理节点性能瓶颈问题)。redis-cluster即为官方基于该架构的解决方案。rediscluster将所有Key映射到16384个slot中,集群中每个Redis实例负责一部分,业务程序通过集成的redis cluster客户端进行操作。客户端可以向任一实例发出请求,如果所需数据不在该实例中,则该实例引导客户端自动去对应实例读写数据。redis cluster 的成员管理(节点名称、IP、端口、状态、角色)等,都通过节点之间两两通讯,定期交换并更新。
reids-cluster在redis 3.0中推出,支持redis分布式集群部署模式,采用无中心分布式架构。所有的 redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。节点的fail是通过集群中超过半数的节点检测失效时才生效,客户端与redis节点直连,不需要中间proxy层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可,减少了代理层,大大提高了性能。redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster负责维护node<->slot<->key之间的关系。目前Jedis(Redis官方推荐的Java连接开发工具)已经支持redis-cluster,从计算架构或者性能方面无疑redis-cluster是最佳的选择方案。
Redis Cluster设计要点
1. Redis集群的数据分片
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
那么redis是如何合理分配这些节点和数据的呢?Redis Cluster没有使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽(hash slot)的方式来分配的。redis cluster默认分配了16384个slot,当我们set一个key时,会采用CRC16算法来取模得到所属的slot,然后将这个key分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。注意的是:必须要3个以上的主节点,否则创建集群时会失败。
我们假设现在有3个节点已经部署成redis cluster,分别是:A,B,C三个节点,他们可以是一台机器上的三个端口,也可以是三台不同的服务器,那么采用哈希槽(hash slot)的方式来分配16384个slot,它们三个节点分别承担的slot区间是:
- 节点A覆盖0-5500
- 节点B覆盖5501-11000
- 节点C覆盖11001-16383
那么,现在我想设置1个key ,比如叫my_name: set my_name linux 按照redis cluster的哈希槽算法:CRC16(‘my_name’)%16384 = 2412。 那么就会把这个key的存储分配到A节点上。
同样,当我连接(A,B,C)任何一个节点想获取my_name这个key时,也会这样的算法,然后内部跳转到A节点上获取数据。
这种结构很容易添加或者删除节点. 比如如果想新添加个节点D, 需要从节点 A, B, C中得部分槽到D上;如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可;
由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
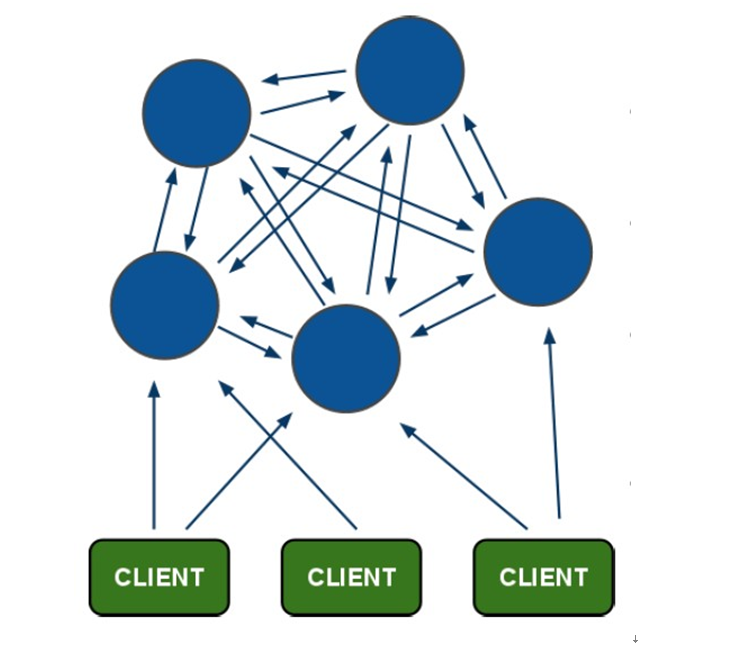
2. Redis集群的主从复制模型
为了使在部分节点失败或者大部分节点无法通信的情况下集群仍然可用,所以集群使用了主从复制模型,每个节点都会有N-1个复制品。
在具有A,B,C三个节点的集群,在没有复制模型的情况下,如果节点B失败了,那么整个集群就会以为缺少5501-11000这个范围的槽而不可用;
然而如果在集群创建的时候(或者过一段时间)我们为每个节点添加一个从节点A1,B1,C1,那么整个集群便有三个master节点和三个slave节点组成,这样在节点B失败后,集群便会选举B1为新的主节点继续服务,整个集群便不会因为槽找不到而不可用了。
不过当B和B1都失败后,集群是不可用的。
3. Redis一致性保证
Redis 并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
第一个原因是因为集群是用了异步复制。写操作过程:
- 客户端向主节点B写入一条命令
- 主节点B向客户端回复命令状态
- 主节点将写操作复制给他得从节点B1,B2和B3。
主节点对命令的复制工作发生在返回命令回复之后,因为如果每次处理命令请求都需要等待复制操作完成的话,那么主节点处理命令请求的速度将极大地降低,我们必须在性能和一致性之间做出权衡。注意:Redis集群可能会在将来提供同步写的方法。
Redis集群另外一种可能会丢失命令的情况是集群出现了网络分区,并且一个客户端与至少包括一个主节点在内的少数实例被孤立。
举个例子,假设集群包含A、B、C、A1、B1、C1六个节点,其中A 、B 、C为主节点,A1、B1、C1为A,B,C的从节点,还有一个客户端Z1。假设集群中发生网络分区,那么集群可能会分为两方,大部分的一方包含节点A、C、A1、B1和C1,小部分的一方则包含节点B和客户端Z1。
Z1仍然能够向主节点B中写入,如果网络分区发生时间较短,那么集群将会继续正常运作,如果分区的时间足够让大部分的一方将B1选举为新的master,那么Z1写入B中得数据便丢失了。
注意,在网络分裂出现期间,客户端Z1可以向主节点B发送写命令的最大时间是有限制的,这一时间限制称为节点超时时间(node timeout),是Redis集群的一个重要的配置选项。
二. 部署Redis集群
为了实验环境简单、方便部署只使用一台服务器,然后启动六个redis实例组成集群,集群包括三组,每组都是一主一从的关系。但是生产环境考虑到高可用最少需要三台服务器。
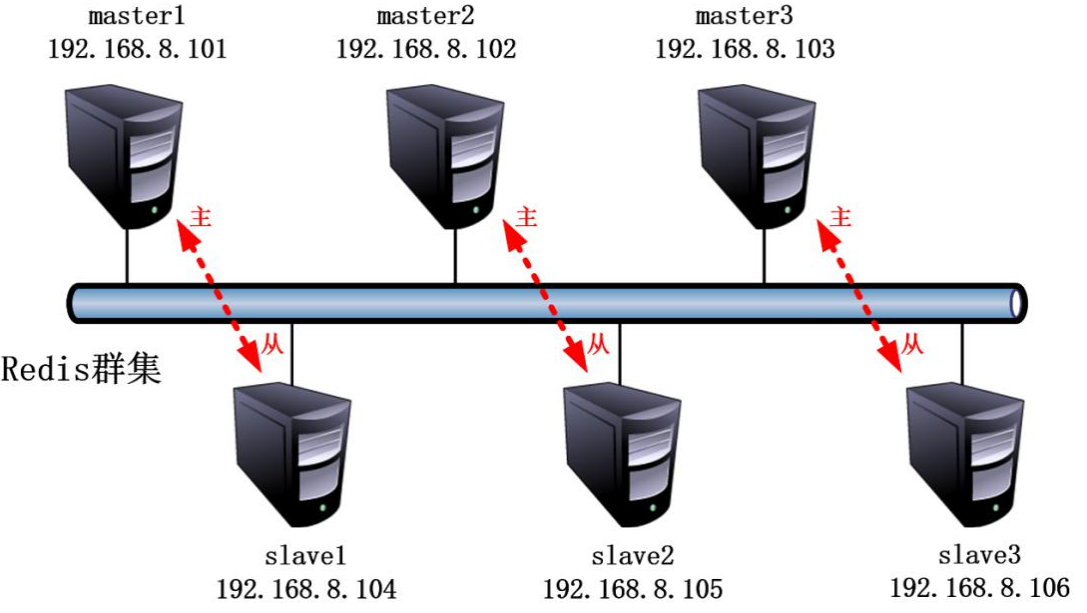
案例环境及相关软件版本:
| 软件 | 相关信息 |
|---|---|
| 系统 | CentOS 7.7 最小化安装 |
| redis版本 | 5.0.7 |
| 服务器主机名 | master1-3,slave1-3 |
| 服务器IP地址 | 192.168.8.101/24–192.168.8.106/24 |
| firewalld | 开启 |
| Selinux | 关闭 |
| redis实例端口 | 6379 |
案例需求:
使用六个Redis实例搭建一个Redis集群,要求任意宕机一组实例,集群写入或读取数据不受任何影响。要求理解Redis的性能管理。
案例实现思路:
- 下载安装Redis
- 配置启动六个Redis实例
- 将六个Redis实例组成集群
- 集群结构微调
- 破坏性测试
2.1 下载并安装redis
这里进行Redis 5.0.7版本的编译安装。
[root@redis-cluster ~]# wget -c http://download.redis.io/releases/redis-5.0.7.tar.gz[root@redis-cluster ~]# tar zxvf redis-5.0.7.tar.gz -C /usr/src/[root@redis-cluster ~]# cd /usr/src/redis-5.0.7/[root@redis-cluster redis-5.0.7]# make[root@redis-cluster redis-5.0.7]# make PREFIX=/usr/local/redis install[root@redis-cluster redis-5.0.7]# ln -s /usr/local/redis/bin/* /usr/local/bin/
2.2 创建6个实例所用配置文件
##创建实例配置文件目录[root@redis-cluster redis-5.0.7]# mkdir /etc/redis-cluster/7000 -p[root@redis-cluster redis-5.0.7]# mkdir /etc/redis-cluster/7001 -p[root@redis-cluster redis-5.0.7]# mkdir /etc/redis-cluster/7002 -p[root@redis-cluster redis-5.0.7]# mkdir /etc/redis-cluster/7003 -p[root@redis-cluster redis-5.0.7]# mkdir /etc/redis-cluster/7004 -p[root@redis-cluster redis-5.0.7]# mkdir /etc/redis-cluster/7005 -p##复制配置并修改[root@redis-cluster redis-5.0.7]# cp redis.conf /etc/redis-cluster/7000/[root@redis-cluster redis-5.0.7]# vim /etc/redis-cluster/7000/redis.conf##主要修改以下配置bind 127.0.0.1 192.168.154.101protected-mode noport 7000 #不同的实例,端口要不同daemonize yespidfile /var/run/redis_7000.pid #不同的实例,名字要不同logfile "/var/log/redis-cluster/7000.log" #不同的实例,名字不同dir /etc/redis-cluster/7000/ #不同的实例,目录名不同appendonly yescluster-enabled yescluster-config-file nodes-7000.conf #不同的实例,名字不同cluster-node-timeout 15000##注:其余的实例按照上面的样式进行修改即可##需要创建日志目录[root@redis-cluster redis-5.0.7]# mkdir /var/log/redis-cluster/
2.3 启动6个Redis实例
##启动Redis实例[root@redis-cluster ~]# redis-server /etc/redis-cluster/7000/redis.conf[root@redis-cluster ~]# redis-server /etc/redis-cluster/7001/redis.conf[root@redis-cluster ~]# redis-server /etc/redis-cluster/7002/redis.conf[root@redis-cluster ~]# redis-server /etc/redis-cluster/7003/redis.conf[root@redis-cluster ~]# redis-server /etc/redis-cluster/7004/redis.conf[root@redis-cluster ~]# redis-server /etc/redis-cluster/7005/redis.conf##查看Redis实例的开启状态[root@redis-cluster ~]# netstat -antp | grep redis-servertcp 0 0 192.168.154.101:7000 0.0.0.0:* LISTEN 6345/redis-server 1tcp 0 0 127.0.0.1:7000 0.0.0.0:* LISTEN 6345/redis-server 1tcp 0 0 192.168.154.101:7001 0.0.0.0:* LISTEN 6535/redis-server 1tcp 0 0 127.0.0.1:7001 0.0.0.0:* LISTEN 6535/redis-server 1tcp 0 0 192.168.154.101:7002 0.0.0.0:* LISTEN 6616/redis-server 1tcp 0 0 127.0.0.1:7002 0.0.0.0:* LISTEN 6616/redis-server 1tcp 0 0 192.168.154.101:7003 0.0.0.0:* LISTEN 6621/redis-server 1tcp 0 0 127.0.0.1:7003 0.0.0.0:* LISTEN 6621/redis-server 1tcp 0 0 192.168.154.101:7004 0.0.0.0:* LISTEN 6626/redis-server 1tcp 0 0 127.0.0.1:7004 0.0.0.0:* LISTEN 6626/redis-server 1tcp 0 0 192.168.154.101:7005 0.0.0.0:* LISTEN 6631/redis-server 1tcp 0 0 127.0.0.1:7005 0.0.0.0:* LISTEN 6631/redis-server 1tcp 0 0 192.168.154.101:17000 0.0.0.0:* LISTEN 6345/redis-server 1tcp 0 0 127.0.0.1:17000 0.0.0.0:* LISTEN 6345/redis-server 1tcp 0 0 192.168.154.101:17001 0.0.0.0:* LISTEN 6535/redis-server 1tcp 0 0 127.0.0.1:17001 0.0.0.0:* LISTEN 6535/redis-server 1tcp 0 0 192.168.154.101:17002 0.0.0.0:* LISTEN 6616/redis-server 1tcp 0 0 127.0.0.1:17002 0.0.0.0:* LISTEN 6616/redis-server 1tcp 0 0 192.168.154.101:17003 0.0.0.0:* LISTEN 6621/redis-server 1tcp 0 0 127.0.0.1:17003 0.0.0.0:* LISTEN 6621/redis-server 1tcp 0 0 192.168.154.101:17004 0.0.0.0:* LISTEN 6626/redis-server 1tcp 0 0 127.0.0.1:17004 0.0.0.0:* LISTEN 6626/redis-server 1tcp 0 0 192.168.154.101:17005 0.0.0.0:* LISTEN 6631/redis-server 1tcp 0 0 127.0.0.1:17005 0.0.0.0:* LISTEN 6631/redis-server 1##防火墙放行端口[root@redis-cluster ~]# firewall-cmd --add-port=7000-7005/tcp --permanent[root@redis-cluster ~]# firewall-cmd --add-port=17000-17005/tcp --permanent[root@redis-cluster ~]# firewall-cmd --reloadsuccess
从每个实例的日志中可以看到,因此每个节点都会为其分配一个新的ID。
6345:M 10 Feb 2020 20:49:11.563 * No cluster configuration found, I'm 76a03da129ae0a753cd489ad70b8f5b6e5c747c3
此ID将由该特定实例永久使用,以使该实例在群集的上下文中具有唯一的名称。每个节点都使用此ID而不是IP或端口记住其他每个节点。IP地址和端口可能会更改,但是唯一的节点标识符在节点的整个生命周期中都不会改变。我们将此标识符简称为Node ID。
2.4 创建集群
- 如果是redis 5.0版本,使用redis-cli命令即可
- 如果是redis 4.0或者3.0,需要使用redis-trib.rb命令,在源码包的src目录中存在。
[root@redis-cluster ~]# redis-cli --cluster create 192.168.154.101:7000 \> 192.168.154.101:7001 192.168.154.101:7002 192.168.154.101:7003 \> 192.168.154.101:7004 192.168.154.101:7005 \> --cluster-replicas 1## 下面是集群创建时的信息,输入yes接受即可创建>>> Performing hash slots allocation on 6 nodes...Master[0] -> Slots 0 - 5460Master[1] -> Slots 5461 - 10922Master[2] -> Slots 10923 - 16383 #分配的slots情况Adding replica 192.168.154.101:7004 to 192.168.154.101:7000Adding replica 192.168.154.101:7005 to 192.168.154.101:7001Adding replica 192.168.154.101:7003 to 192.168.154.101:7002 #主从情况>>> Trying to optimize slaves allocation for anti-affinity[WARNING] Some slaves are in the same host as their masterM: 76a03da129ae0a753cd489ad70b8f5b6e5c747c3 192.168.154.101:7000slots:[0-5460] (5461 slots) masterM: 5a3c4ce2d2328522310231debdf92d4622bda446 192.168.154.101:7001slots:[5461-10922] (5462 slots) masterM: d4b9b07f5264443905e49a66e3680e6658c2f9af 192.168.154.101:7002slots:[10923-16383] (5461 slots) masterS: a2a6387d2e5e6146605cb719879ae128e557e07c 192.168.154.101:7003replicates d4b9b07f5264443905e49a66e3680e6658c2f9afS: 8d77ad5872ad3fa9519ad5d3a9bd878e69b507d1 192.168.154.101:7004replicates 76a03da129ae0a753cd489ad70b8f5b6e5c747c3S: d2a2c64c733b062aeca2eb34c3ea1a2b5ee2a4e1 192.168.154.101:7005replicates 5a3c4ce2d2328522310231debdf92d4622bda446Can I set the above configuration? (type 'yes' to accept): yes>>> Nodes configuration updated>>> Assign a different config epoch to each node>>> Sending CLUSTER MEET messages to join the clusterWaiting for the cluster to join.....>>> Performing Cluster Check (using node 192.168.154.101:7000)M: 76a03da129ae0a753cd489ad70b8f5b6e5c747c3 192.168.154.101:7000slots:[0-5460] (5461 slots) master1 additional replica(s)M: d4b9b07f5264443905e49a66e3680e6658c2f9af 127.0.0.1:7002slots:[10923-16383] (5461 slots) master1 additional replica(s)M: 5a3c4ce2d2328522310231debdf92d4622bda446 127.0.0.1:7001slots:[5461-10922] (5462 slots) master1 additional replica(s)S: d2a2c64c733b062aeca2eb34c3ea1a2b5ee2a4e1 127.0.0.1:7005slots: (0 slots) slavereplicates 5a3c4ce2d2328522310231debdf92d4622bda446S: 8d77ad5872ad3fa9519ad5d3a9bd878e69b507d1 127.0.0.1:7004slots: (0 slots) slavereplicates 76a03da129ae0a753cd489ad70b8f5b6e5c747c3S: a2a6387d2e5e6146605cb719879ae128e557e07c 127.0.0.1:7003slots: (0 slots) slavereplicates d4b9b07f5264443905e49a66e3680e6658c2f9af[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered. #看到这个信息,代表集群创建成功
2.5 使用Redis集群
测试redis集群是否可以写入数据,这里随便挑选一个Redis实例都可以;使用-c选项表示使用集群模式。
[root@redis-cluster ~]# redis-cli -c -p 7000 -h 192.168.154.101192.168.154.101:7000> pingPONG192.168.154.101:7000> set username mary-> Redirected to slot [14315] located at 127.0.0.1:7002OK127.0.0.1:7002> set password 123456-> Redirected to slot [9540] located at 127.0.0.1:7001OK127.0.0.1:7001> set userid 001-> Redirected to slot [15270] located at 127.0.0.1:7002OK127.0.0.1:7002> set address beijing-> Redirected to slot [3680] located at 127.0.0.1:7000OK127.0.0.1:7000> set city baoding-> Redirected to slot [11479] located at 127.0.0.1:7002OK127.0.0.1:7002> quit##写入数据的时候发生了重定向写入
2.6 集群操作
2.6.1 查看集群成员
[root@redis-cluster ~]# redis-cli -p 7000 -h 192.168.154.101 cluster nodesd4b9b07f5264443905e49a66e3680e6658c2f9af 127.0.0.1:7002@17002 master - 0 1581343964000 3 connected 10923-163835a3c4ce2d2328522310231debdf92d4622bda446 127.0.0.1:7001@17001 master - 0 1581343964791 2 connected 5461-10922d2a2c64c733b062aeca2eb34c3ea1a2b5ee2a4e1 127.0.0.1:7005@17005 slave 5a3c4ce2d2328522310231debdf92d4622bda446 0 1581343963000 6 connected76a03da129ae0a753cd489ad70b8f5b6e5c747c3 192.168.154.101:7000@17000 myself,master - 0 1581343964000 1 connected 0-54608d77ad5872ad3fa9519ad5d3a9bd878e69b507d1 127.0.0.1:7004@17004 slave 76a03da129ae0a753cd489ad70b8f5b6e5c747c3 0 1581343965798 5 connecteda2a6387d2e5e6146605cb719879ae128e557e07c 127.0.0.1:7003@17003 slave d4b9b07f5264443905e49a66e3680e6658c2f9af 0 1581343964000 4 connected
- Node ID
- ip:port
- 标志: master, slave, myself, fail, …
- 如果是slave, 其master的Node ID
- 集群最近一次向节点发送 PING 命令之后,过去了多长时间还没接到回复
- 节点最近一次返回 PONG 回复的时间
- 此节点的配置纪元(请参阅群集规范)
- 本节点的网络连接情况:例如 connected
- 节点目前包含的槽
2.6.2 测试集群故障转移
这里我们关闭一个主节点
## 关闭7002实例[root@redis-cluster redis-cluster]# redis-cli -p 7002 debug segfault##查看集群节点,发现7003变成了主节点[root@redis-cluster redis-cluster]# redis-cli -p 7000 cluster nodesd2a2c64c733b062aeca2eb34c3ea1a2b5ee2a4e1 127.0.0.1:7005@17005 slave 5a3c4ce2d2328522310231debdf92d4622bda446 0 1581347213196 6 connected76a03da129ae0a753cd489ad70b8f5b6e5c747c3 192.168.154.101:7000@17000 myself,master - 0 1581347214000 1 connected 0-5460a2a6387d2e5e6146605cb719879ae128e557e07c 127.0.0.1:7003@17003 master - 0 1581347215211 7 connected 10923-163835a3c4ce2d2328522310231debdf92d4622bda446 127.0.0.1:7001@17001 master - 0 1581347215000 2 connected 5461-109228d77ad5872ad3fa9519ad5d3a9bd878e69b507d1 127.0.0.1:7004@17004 slave 76a03da129ae0a753cd489ad70b8f5b6e5c747c3 0 1581347216222 5 connectedd4b9b07f5264443905e49a66e3680e6658c2f9af 127.0.0.1:7002@17002 master,fail - 1581347184162 1581347182000 3 disconnected
重启7002实例,其变成了7003实例的从节点
[root@redis-cluster redis-cluster]# redis-server 7002/redis.conf[root@redis-cluster redis-cluster]# redis-cli -p 7000 cluster nodesd2a2c64c733b062aeca2eb34c3ea1a2b5ee2a4e1 127.0.0.1:7005@17005 slave 5a3c4ce2d2328522310231debdf92d4622bda446 0 1581347497820 6 connected76a03da129ae0a753cd489ad70b8f5b6e5c747c3 192.168.154.101:7000@17000 myself,master - 0 1581347495000 1 connected 0-5460a2a6387d2e5e6146605cb719879ae128e557e07c 127.0.0.1:7003@17003 master - 0 1581347494792 7 connected 10923-163835a3c4ce2d2328522310231debdf92d4622bda446 127.0.0.1:7001@17001 master - 0 1581347496000 2 connected 5461-109228d77ad5872ad3fa9519ad5d3a9bd878e69b507d1 127.0.0.1:7004@17004 slave 76a03da129ae0a753cd489ad70b8f5b6e5c747c3 0 1581347494000 5 connectedd4b9b07f5264443905e49a66e3680e6658c2f9af 127.0.0.1:7002@17002 slave a2a6387d2e5e6146605cb719879ae128e557e07c 0 1581347497000 7 connected
2.6.3 添加一个新节点
再另外创建一个新的实例7006,然后启动
[root@redis-cluster redis-cluster]# redis-server /etc/redis-cluster/7006/redis.conf
将其加入到集群中
[root@redis-cluster redis-cluster]# redis-cli --cluster add-node 192.168.154.101:7006 192.168.154.101:7000>>> Adding node 192.168.154.101:7006 to cluster 192.168.154.101:7000>>> Performing Cluster Check (using node 192.168.154.101:7000)M: 76a03da129ae0a753cd489ad70b8f5b6e5c747c3 192.168.154.101:7000slots:[0-5460] (5461 slots) master1 additional replica(s)S: d2a2c64c733b062aeca2eb34c3ea1a2b5ee2a4e1 127.0.0.1:7005slots: (0 slots) slavereplicates 5a3c4ce2d2328522310231debdf92d4622bda446M: a2a6387d2e5e6146605cb719879ae128e557e07c 127.0.0.1:7003slots:[10923-16383] (5461 slots) master1 additional replica(s)M: 5a3c4ce2d2328522310231debdf92d4622bda446 127.0.0.1:7001slots:[5461-10922] (5462 slots) master1 additional replica(s)S: 8d77ad5872ad3fa9519ad5d3a9bd878e69b507d1 127.0.0.1:7004slots: (0 slots) slavereplicates 76a03da129ae0a753cd489ad70b8f5b6e5c747c3S: d4b9b07f5264443905e49a66e3680e6658c2f9af 127.0.0.1:7002slots: (0 slots) slavereplicates a2a6387d2e5e6146605cb719879ae128e557e07c[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.>>> Send CLUSTER MEET to node 192.168.154.101:7006 to make it join the cluster.[OK] New node added correctly.
检查一下集群节点
[root@redis-cluster redis-cluster]# redis-cli --cluster check 192.168.154.101:7000192.168.154.101:7000 (76a03da1...) -> 1 keys | 5461 slots | 1 slaves.127.0.0.1:7006 (eb6c6e2d...) -> 0 keys | 0 slots | 0 slaves.127.0.0.1:7003 (a2a6387d...) -> 3 keys | 5461 slots | 1 slaves.127.0.0.1:7001 (5a3c4ce2...) -> 1 keys | 5462 slots | 1 slaves.[OK] 5 keys in 4 masters.0.00 keys per slot on average.>>> Performing Cluster Check (using node 192.168.154.101:7000)M: 76a03da129ae0a753cd489ad70b8f5b6e5c747c3 192.168.154.101:7000slots:[0-5460] (5461 slots) master1 additional replica(s)S: d2a2c64c733b062aeca2eb34c3ea1a2b5ee2a4e1 127.0.0.1:7005slots: (0 slots) slavereplicates 5a3c4ce2d2328522310231debdf92d4622bda446M: eb6c6e2de18d512e0864aaa3809717a130b58369 127.0.0.1:7006slots: (0 slots) masterM: a2a6387d2e5e6146605cb719879ae128e557e07c 127.0.0.1:7003slots:[10923-16383] (5461 slots) master1 additional replica(s)M: 5a3c4ce2d2328522310231debdf92d4622bda446 127.0.0.1:7001slots:[5461-10922] (5462 slots) master1 additional replica(s)S: 8d77ad5872ad3fa9519ad5d3a9bd878e69b507d1 127.0.0.1:7004slots: (0 slots) slavereplicates 76a03da129ae0a753cd489ad70b8f5b6e5c747c3S: d4b9b07f5264443905e49a66e3680e6658c2f9af 127.0.0.1:7002slots: (0 slots) slavereplicates a2a6387d2e5e6146605cb719879ae128e557e07c[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.
可以看到Redis实例7006成为了一个主节点,但是并没有为其分配slots,也就是其并不负责数据存取。需要我们手动对集群进行重新分片迁移。
2.6.4 对集群进行重新分片
[root@redis-cluster redis-cluster]# redis-cli --cluster reshard 192.168.154.101:7000## 这个命令是会进入交互模式## 192.168.154.101:7000代表集群
第一个问题是:问你需要移动多少个slots,这里为了均匀,可以填写16384/4=4096,填写4096个即可
How many slots do you want to move (from 1 to 16384)?
第二个问题:问你要将slots移动到哪个节点,添加7006实例的Node ID
What is the receiving node ID?
第三个问题:问你要从哪些节点移出slots,all代表从其它所有master节点移出,即每个节点移出一部分;
Please enter all the source node IDs.Type 'all' to use all the nodes as source nodes for the hash slots.Type 'done' once you entered all the source nodes IDs.Source node #1:
重新分片后,可以进行集群检查,会发现已经完成分片
[root@redis-cluster redis-cluster]# redis-cli --cluster check 192.168.154.101:7000192.168.154.101:7000 (76a03da1...) -> 1 keys | 4096 slots | 1 slaves.127.0.0.1:7006 (eb6c6e2d...) -> 1 keys | 4096 slots | 0 slaves.127.0.0.1:7003 (a2a6387d...) -> 2 keys | 4096 slots | 1 slaves.127.0.0.1:7001 (5a3c4ce2...) -> 1 keys | 4096 slots | 1 slaves.[OK] 5 keys in 4 masters.0.00 keys per slot on average.>>> Performing Cluster Check (using node 192.168.154.101:7000)M: 76a03da129ae0a753cd489ad70b8f5b6e5c747c3 192.168.154.101:7000slots:[1365-5460] (4096 slots) master1 additional replica(s)S: d2a2c64c733b062aeca2eb34c3ea1a2b5ee2a4e1 127.0.0.1:7005slots: (0 slots) slavereplicates 5a3c4ce2d2328522310231debdf92d4622bda446M: eb6c6e2de18d512e0864aaa3809717a130b58369 127.0.0.1:7006slots:[0-1364],[5461-6826],[10923-12287] (4096 slots) masterM: a2a6387d2e5e6146605cb719879ae128e557e07c 127.0.0.1:7003slots:[12288-16383] (4096 slots) master1 additional replica(s)M: 5a3c4ce2d2328522310231debdf92d4622bda446 127.0.0.1:7001slots:[6827-10922] (4096 slots) master1 additional replica(s)S: 8d77ad5872ad3fa9519ad5d3a9bd878e69b507d1 127.0.0.1:7004slots: (0 slots) slavereplicates 76a03da129ae0a753cd489ad70b8f5b6e5c747c3S: d4b9b07f5264443905e49a66e3680e6658c2f9af 127.0.0.1:7002slots: (0 slots) slavereplicates a2a6387d2e5e6146605cb719879ae128e557e07c[OK] All nodes agree about slots configuration.>>> Check for open slots...>>> Check slots coverage...[OK] All 16384 slots covered.
重新分片可以自动执行,而无需以交互方式手动输入参数。可以使用如下命令行来实现:
redis-cli reshard <host>:<port> --cluster-from <node-id> --cluster-to <node-id> --cluster-slots <number of slots> --cluster-yes
2.6.5 添加一个从节点
这里我们可以再创建并启动一个Redis实例:7007
[root@redis-cluster redis-cluster]# redis-server 7007/redis.conf
添加从节点
[root@redis-cluster ~]# redis-cli --cluster add-node 192.168.154.101:7007 192.168.154.101:7000 --cluster-slave##由于没有指定主节点是谁,所以是将新节点添加为副本较少的主节点的从节点
也可以指定主节点是谁
redis-cli --cluster add-node 192.168.154.101:7007 192.168.154.101:7000 --cluster-slave --cluster-master-id eb6c6e2de18d512e0864aaa3809717a130b58369## 这里指定主节点为7006实例的Node ID
2.6.6 删除节点
要删除一个从节点,只需使用del-node命令:
redis-cli --cluster del-node 127.0.0.1:7000 `<node-id>`##第一个参数只是集群中的一个随机节点,第二个参数是您要删除的节点的ID
您也可以用相同的方法删除主节点,但是要删除主节点,它必须为空。如果主节点不为空,则需要先将数据从其重新分片到所有其他主节点。

若有收获,就点个赞吧
0 人点赞
