存储过程
如果需要在MySQL中执行一系列语句,可以将所有语句封装在单个程序中,并在需要的时候调用这个程序,而不是每次发送所有SQL语句。存储过程处理的是一组SQL语句,且没有返回值。
除了SQL语句,还可以使用变量来存储结果并在存储过程中执行程序化的内容。例如可以使用IF,CASE子句、逻辑操作和WHILE循环。
- 存储的函数(funcation)和过程(procedure)都称为存储例程(routine)
- 要创建存储过程,应该具有CREATE ROUTINE权限
- 存储函数具有返回值
- 存储过程没有返回值
- 所有代码写在BEGIN和END之间
- 存储函数可以直接在SELECT语句中调用
- 可以使用CALL语句调用存储过程
- 由于存储过程中的语句应以分隔符(;)结尾,因此必须要更改MySQL的分隔符,以便MySQL不会用正常语句解释存储例程中的SQL语句。创建过程结束后,可以将分隔符更改回默认值。
如何操作
假设想要添加新员工,你需要更新3个表,分别是employees表、salaries表和titles表。可以开发一个存储过程并调用它来创建新的employee,而不是执行三条语句。
mysql> desc employees;+------------+---------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+------------+---------------+------+-----+---------+-------+| emp_no | int(11) | NO | PRI | NULL | || birth_date | date | NO | | NULL | || first_name | varchar(14) | NO | MUL | NULL | || last_name | varchar(16) | NO | | NULL | || gender | enum('M','F') | NO | | NULL | || hire_date | date | NO | | NULL | |+------------+---------------+------+-----+---------+-------+6 rows in set (0.00 sec)mysql> desc titles;+-----------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-----------+-------------+------+-----+---------+-------+| emp_no | int(11) | NO | PRI | NULL | || title | varchar(50) | NO | PRI | NULL | || from_date | date | NO | PRI | NULL | || to_date | date | YES | | NULL | |+-----------+-------------+------+-----+---------+-------+4 rows in set (0.00 sec)mysql> desc salaries;+-----------+---------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-----------+---------+------+-----+---------+-------+| emp_no | int(11) | NO | PRI | NULL | || salary | int(11) | NO | | NULL | || from_date | date | NO | PRI | NULL | || to_date | date | NO | | NULL | |+-----------+---------+------+-----+---------+-------+4 rows in set (0.00 sec)
必须传递的信息包括员工的first_name、last_name、gender和birth_date以及员工加入部门department。可以使用输入变量来传递这些变量,并且应该将员工编号作为输出。存储过程不返回值,但它可以更新一个变量并使用它。
实例:实现的是创建新的employee并更新salaries表和departments表:
/* 在创建之前,如果存在任何相同名字的存储过程,则删除已经存在的存储过程*/DROP PROCEDURE IF EXISTS create_employee;/* 修改分隔符为$$ */DELIMITER $$/* IN 指定作为参数的变量,OUT指定输出的变量 */CREATE PROCEDURE create_employee (OUT new_emp_no INT, IN first_name varchar(20), IN last_name varchar(20),IN gender enum('M','F'),IN birth_date date,IN emp_dept_name varchar(40),IN title varchar(50))BEGIN/* 为emp_dept_no和salary声明变量 */DECLARE emp_dept_no char(4);DECLARE salary int DEFAULT 60000;/* 查询employees表的emp_no的最大值,赋值给变量new_emp_no */SELECT max(emp_no) INTO new_emp_no FROM employees;/* 增加new_emp_no */SET new_emp_no = new_emp_no + 1;/* 插入数据到employees表中 *//* CURDATE()函数给出当前日期 */INSERT INTO employees VALUES(new_emp_no,birth_date,first_name,last_name,gender,CURDATE());/* 找到dept_name对应的dept_no */SELECT emp_dept_name;SELECT dept_no INTO emp_dept_no FROM departments WHERE dept_name=emp_dept_name;SELECT emp_dept_no;/* 插入dept_emp */INSERT INTO dept_emp VALUES(new_emp_no,emp_dept_no,CURDATE(),'9999-01-01');/* 插入titles */INSERT INTO titles VALUES(new_emp_no,title,CURDATE(),'9999-01-01');/* 以title为条件查询的薪水 */IF title = 'Staff'THEN SET salary = 100000;ELSEIF title = 'Senior Staff'THEN SET salary = 120000;END IF;/* 插入salaries */INSERT INTO salaries VALUES(new_emp_no,salary,CURDATE(),'9999-01-01');END$$/* 把分隔符改回;*/DELIMITER ;
要创建存储过程,可以有以下方法:
- 将上述代码粘贴到命令行客户端中
- 将以上代码保存成文件,并使用mysql -u -p employees < stored_procedure.sql将其导入到MySQL中
- 使用SOURCE从文件加载:source ./stored_procedure.sql
mysql> source stored_procedure.sql;Query OK, 0 rows affected (0.00 sec)Query OK, 0 rows affected (0.00 sec)
查询新建立的存储过程是否存在:
mysql> show procedure status like '%emp%'\G;*************************** 1. row ***************************Db: employeesName: create_employeeType: PROCEDUREDefiner: root@localhostModified: 2019-08-16 11:43:04Created: 2019-08-16 11:43:04Security_type: DEFINERComment:character_set_client: utf8mb4collation_connection: utf8mb4_0900_ai_ciDatabase Collation: utf8mb4_0900_ai_ci1 row in set (0.00 sec)
把你要传递的输出值存储在@new_emp_no中,并传递所需的输入值
mysql> CALL create_employee(@new_emp_no,'John','Smith','M','1984-06-19','Research','Staff');+---------------+| emp_dept_name |+---------------+| Research |+---------------+1 row in set (0.01 sec)+-------------+| emp_dept_no |+-------------+| d008 |+-------------+1 row in set (0.01 sec)Query OK, 1 row affected (0.02 sec)
查询存储在@new_emp_no变量中的emp_no的值:
mysql> select @new_emp_no;+-------------+| @new_emp_no |+-------------+| 500000 |+-------------+1 row in set (0.00 sec)
检查是否在employees表、salaries表和titles表中创建了行:
mysql> select * from employees where emp_no=500000;+--------+------------+------------+-----------+--------+------------+| emp_no | birth_date | first_name | last_name | gender | hire_date |+--------+------------+------------+-----------+--------+------------+| 500000 | 1984-06-19 | John | Smith | M | 2019-08-16 |+--------+------------+------------+-----------+--------+------------+1 row in set (0.00 sec)mysql> select * from salaries where emp_no=500000;+--------+--------+------------+------------+| emp_no | salary | from_date | to_date |+--------+--------+------------+------------+| 500000 | 100000 | 2019-08-16 | 9999-01-01 |+--------+--------+------------+------------+1 row in set (0.00 sec)mysql> select * from titles where emp_no=500000;+--------+-------+------------+------------+| emp_no | title | from_date | to_date |+--------+-------+------------+------------+| 500000 | Staff | 2019-08-16 | 9999-01-01 |+--------+-------+------------+------------+1 row in set (0.00 sec)
可以通过 show create procedure create_employee \G;命令查看存储过程定义的语句。
存储过程安全性
用户需要拥有针对存储过程的EXECUTE权限才能执行它。
mysql> GRANT EXECUTE ON employees.* TO 'emp_read_only'@'%';
即使emp_read_only对表没有写访问权限,也可以通过调用存储过程来写入。
根据存储例程的定义:
- DEFINER子句指定存储例程的创建者。如果没有指定,则获取当前用户。
- SQL SECURITY子句指定存储例程的执行上下文。它可以是DEFINER或者INVOKER。
- DEFINER:即使只有EXECUTE权限的用户也可以调用并获取存储例程的输出,而不管该用户是否具有对基础表的操作权限。如果DEFINER具有权限,那就足够了;
- INVOKER:安全上下文被切换到调用存储例程的用户。在这种情况下,调用者应该可以访问基础表。
函数
如同存储过程一样,我们可以创建存储函数。二者主要区别是,函数应该有一个返回值,并且可以在SELECT中调用函数。通常,创建存储函数是为了简化复杂的计算。
如何操作
实例:假设银行工作人员想根据客户的收入水平给出信用卡额度,同时不暴露客户的实际工资,那么可以利用下面的函数查询收入水平:
编写函数文件function.sql
DROP FUNCTION IF EXISTS get_sal_level;DELIMITER $$CREATE FUNCTION get_sal_level(emp int) RETURNS VARCHAR(10) DETERMINISTICBEGINDECLARE sal_level varchar(10);DECLARE avg_sal FLOAT;SELECT AVG(salary) INTO avg_sal FROM salaries WHERE emp_no=emp;IF avg_sal < 50000 THENSET sal_level = 'BRONZE';ELSEIF (avg_sal >= 50000 AND avg_sal < 70000) THENSET sal_level = 'SILVER';ELSEIF (avg_sal >= 70000 AND avg_sal < 90000) THENSET sal_level = 'GOLD';ELSEIF (avg_sal >= 90000) THENSET sal_level = 'PLATINUM';ELSESET sal_level = 'NOT FOUND';END IF;RETURN (sal_level);END$$DELIMITER ;
创建该函数:
mysql> source /root/mysql/funcation.sqlQuery OK, 0 rows affected, 1 warning (0.00 sec)Query OK, 0 rows affected (0.00 sec)
查询创建的函数:
mysql> show function status like '%sal%'\G;*************************** 1. row ***************************Db: employeesName: get_sal_levelType: FUNCTIONDefiner: root@localhostModified: 2019-08-16 15:46:14Created: 2019-08-16 15:46:14Security_type: DEFINERComment:character_set_client: utf8mb4collation_connection: utf8mb4_0900_ai_ciDatabase Collation: utf8mb4_0900_ai_ci1 row in set (0.00 sec)
查询存储函数的定义:
mysql> show create function get_sal_level \G;*************************** 1. row ***************************Function: get_sal_levelsql_mode: ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONCreate Function: CREATE DEFINER=`root`@`localhost` FUNCTION `get_sal_level`(emp int) RETURNS varchar(10) CHARSET utf8mb4DETERMINISTICBEGINDECLARE sal_level varchar(10);DECLARE avg_sal FLOAT;SELECT AVG(salary) INTO avg_sal FROM salaries WHERE emp_no=emp;IF avg_sal < 50000 THENSET sal_level = 'BRONZE';ELSEIF (avg_sal >= 50000 AND avg_sal < 70000) THENSET sal_level = 'SILVER';ELSEIF (avg_sal >= 70000 AND avg_sal < 90000) THENSET sal_level = 'GOLD';ELSEIF (avg_sal >= 90000) THENSET sal_level = 'PLATINUM';ELSESET sal_level = 'NOT FOUND';END IF;RETURN (sal_level);ENDcharacter_set_client: utf8mb4collation_connection: utf8mb4_0900_ai_ciDatabase Collation: utf8mb4_0900_ai_ci1 row in set (0.00 sec)
使用创建的存储函数:
mysql> SELECT get_sal_level(10002);+----------------------+| get_sal_level(10002) |+----------------------+| SILVER |+----------------------+1 row in set (0.00 sec)mysql> SELECT get_sal_level(10001);+----------------------+| get_sal_level(10001) |+----------------------+| GOLD |+----------------------+1 row in set (0.00 sec)mysql> SELECT get_sal_level(1);+------------------+| get_sal_level(1) |+------------------+| NOT FOUND |+------------------+1 row in set (0.00 sec)
内置函数
MySQL提供了许多内置函数。前面使用的CURDATE()函数获取了当前日期。也可以在WHERE子句中使用CURDATE()函数:
mysql> SELECT * FROM employees WHERE hire_date = CURDATE();+--------+------------+------------+-----------+--------+------------+| emp_no | birth_date | first_name | last_name | gender | hire_date |+--------+------------+------------+-----------+--------+------------+| 500000 | 1984-06-19 | John | Smith | M | 2019-08-16 |+--------+------------+------------+-----------+--------+------------+1 row in set (0.13 sec)
- 下面的函数给出了一周前的日期:
mysql> SELECT DATE_ADD(CURDATE(), INTERVAL -7 DAY) AS '7 Days Ago';+------------+| 7 Days Ago |+------------+| 2019-08-09 |+------------+1 row in set (0.00 sec)
- 将两个字符串相加:
mysql> SELECT CONCAT(first_name,' ', last_name) AS 'Name' FROM employees LIMIT 1;+-------------+| Name |+-------------+| Aamer Anger |+-------------+1 row in set (0.00 sec)
触发器
触发器用于在触发器事件之前或之后激活某些内容。例如,可以在插入表中的每行之前或更新的每行之后激活触发器。
触发器非常有用,可以在无停机时间的情况下更改表或用于审计目的。假设想查找某一行的前一个值,可以编写一个触发器,在更新之前将这些行保存在另一个表中。另一个表保存了以前的记录,充当审计表。
触发器动作时间可以是BEFORE或AFTER,表示触发器是在每行要修改之前或之后被激活。
触发事件可以是INSERT、DELETE或UPDATE。
- INSERT: 无论何时通过INSERT、REPLACE或LOAD DATA语句插入新行,都会激活INSERT触发事件
- UPDATE:通过UPDATE语句激活UPDATE触发事件
- DELETE:通过DELETE或REPLACE语句激活DELETE触发事件
从MySQL5.7开始,一个表可以同时具有多个触发器。例如,一个表可以有两个BEFORE INSERT触发器。必须使用FOLLOWS或PRECEDES指定先行的触发器。
如何操作
例如,假设希望在将薪水插入salaries表之前对其进行四舍五入。NEW指的是正在插入的新值:
编写触发器文件:
[root@www mysql]# vim before_insert_trigger.sqlDROP TRIGGER IF EXISTS salary_round;DELIMITER $$CREATE TRIGGER salary_round BEFORE INSERT ON salariesFOR EACH ROWBEGINSET NEW.salary=ROUND(NEW.salary);END$$DELIMITER ;
通过导入文件创建触发器:
mysql> source /root/mysql/before_insert_trigger.sql;Query OK, 0 rows affected, 1 warning (0.00 sec)Query OK, 0 rows affected (0.02 sec)
通过在薪水中插入浮点数来测试触发器:
mysql> INSERT INTO salaries VALUES(10002,100000.79,CURDATE(),'9999-01-01');Query OK, 1 row affected (0.00 sec)
可以看到薪水被四舍五入:
mysql> SELECT * FROM salaries WHERE emp_no=10002 AND from_date=CURDATE();+--------+--------+------------+------------+| emp_no | salary | from_date | to_date |+--------+--------+------------+------------+| 10002 | 100001 | 2019-08-16 | 9999-01-01 |+--------+--------+------------+------------+1 row in set (0.00 sec)
同理,可以再创建一个BEFORE UPDATE触发器来完成薪水的四舍五入操作。
DROP TRIGGER IF EXISTS salary_update_round;DELIMITER $$CREATE TRIGGER salary_update_round BEFORE UPDATE ON salariesFOR EACH ROWBEGINSET NEW.salary=ROUND(NEW.salary);END$$DELIMITER ;
案例:假设你要记录salaries表中新增的薪水记录,首先创建一个审计表:
mysql> CREATE TABLE salary_audit (emp_no int,user varchar(50),date_modified date);Query OK, 0 rows affected (0.01 sec)
请注意,以下触发器由PRECEDES salary_round指定在salary_round触发器之前执行:
DELIMITER $$CREATE TRIGGER salary_auditBEFORE INSERT ON salariesFOR EACH ROW PRECEDES salary_roundBEGININSERT INTO salary_audit VALUES(NEW.emp_no,USER(),CURDATE());END$$DELIMITER ;
导入触发器后插入数据进行测试:
mysql> INSERT INTO salaries VALUES(10003,100000.79, CURDATE(),'9999-01-01');Query OK, 1 row affected (0.00 sec)
查看数据插入情况以及查询salary_audit表来找出谁插入了薪水:
mysql> SELECT * FROM salaries WHERE emp_no=10003 AND from_date=CURDATE();+--------+--------+------------+------------+| emp_no | salary | from_date | to_date |+--------+--------+------------+------------+| 10003 | 100001 | 2019-08-18 | 9999-01-01 |+--------+--------+------------+------------+1 row in set (0.01 sec)mysql> SELECT * FROM salary_audit WHERE emp_no=10003;+--------+----------------+---------------+| emp_no | user | date_modified |+--------+----------------+---------------+| 10003 | root@localhost | 2019-08-18 |+--------+----------------+---------------+1 row in set (0.00 sec)
如果salary_audit表被删除或不可用,则salaries表上的所有插入都将被阻止。如果不想执行审计,则应先删除触发器,然后再删除表。
由于上述复杂性,触发器产生的开销会影响写入速度。
要检查所有触发器,可以指定SHOW TRIGGERS\G命令;要检查现有触发器的定义,可以指定SHOW CREATE TRIGGER
视图
视图是一个基于SQL语句的结果集的虚拟表。视图就像一个真正的表一样,也具有行和列,但是有一些限制。视图隐藏了SQL的复杂性,更重要的是,它提供了额外的安全性。
如何操作
假设只想提供对salaries表的emp_no列和salary列,且from_date在2002-01-01之后的数据的访问权限。可以通过对提供所需结果的SQL语句创建视图。
mysql> CREATE ALGORITHM=UNDEFINED DEFINER='root'@'localhost' \-> SQL SECURITY DEFINER VIEW salary_view AS \-> SELECT emp_no,salary FROM salaries WHERE from_date > '2002-01-01';Query OK, 0 rows affected (0.01 sec)
现在,salary_view视图已经创建,可以像查询其他表一样查询它:
mysql> select * from salary_view limit 5;+--------+--------+| emp_no | salary |+--------+--------+| 10001 | 88958 || 10002 | 150001 || 10003 | 100001 || 10007 | 88070 || 10009 | 94409 |+--------+--------+5 rows in set (0.00 sec)mysql> SELECT emp_no,AVG(salary) as avg_salary FROM salary_view \-> GROUP BY emp_no ORDER BY avg_salary DESC LIMIT 5;+--------+-------------+| emp_no | avg_salary |+--------+-------------+| 43624 | 158220.0000 || 47978 | 155709.0000 || 253939 | 155513.0000 || 109334 | 155190.0000 || 80823 | 154459.0000 |+--------+-------------+5 rows in set (2.54 sec)
可以看到该视图可以访问特定行(即from_date > ‘2002-01-01’)而不是所有行;可以通过使用视图来限制用户对特定行的访问。
要列出所有视图,执行:
mysql> SHOW FULL TABLES WHERE TABLE_TYPE LIKE 'VIEW';+----------------------+------------+| Tables_in_employees | Table_type |+----------------------+------------+| current_dept_emp | VIEW || dept_emp_latest_date | VIEW || salary_view | VIEW |+----------------------+------------+3 rows in set (0.00 sec)
要检查视图的定义,请执行:
mysql> SHOW CREATE VIEW salary_view \G;*************************** 1. row ***************************View: salary_viewCreate View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `salary_view` AS select `salaries`.`emp_no` AS `emp_no`,`salaries`.`salary` AS `salary` from `salaries` where (`salaries`.`from_date` > '2002-01-01')character_set_client: utf8mb4collation_connection: utf8mb4_0900_ai_ci1 row in set (0.00 sec)
可以更新没有子查询、JOINS、GROUP BY子句、union等的简单视图。如果基础表有默认值,那么salary_view就是一个可以被更新或插入的简单视图:
mysql> UPDATE salary_view SET salary=100000 WHERE emp_no=10001;Query OK, 1 row affected (0.01 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> INSERT INTO salary_view VALUES(10001,100001);ERROR 1423 (HY000): Field of view 'employees.salary_view' underlying table doesn't have a default value
如果该表有一个默认值,即使它不符合视图中的过滤器条件,也可以向其中插入一行。为了避免这种情况,为了只允许插入符合视图条件的行,必须在定义里面提供WITH CHECK OPTION。
VIEW算法:
- MERGE: MySQL将输入查询和视图定义合并到一个查询中,然后执行组合查询。仅允许在简单视图上使用MEGRE算法。
- TEMPTABLE: MySQL将结果存储在临时表中,然后对这个临时表执行输入查询。
- UNDEFINED(默认):MySQL自动选择MEGRE或TEMPTABLE算法。MySQL把MERGE算法作为首选的TEMPTABLE算法,因为MERGE算法效率更高。
事件
如同Linux服务器上的cron一样,MySQL的EVENTS是用来处理计划任务的。MySQL使用称为事件调度线程的特殊线程来执行所有预定事件。默认情况下,事件调度线程是未启用(版本低于8.0.3)的状态,如要启用它,可以执行以下命令:
mysql> SET GLOBAL event_scheduler = ON ;Query OK, 0 rows affected (0.00 sec)mysql> show variables like '%event_scheduler%';+-----------------+-------+| Variable_name | Value |+-----------------+-------+| event_scheduler | ON |+-----------------+-------+1 row in set (0.00 sec)
如何操作
假设不再需要保留一个月之前的薪水审计记录,则可以设定一个每日运行的事件,用它从salary_audit表中删除一个月之前的记录。
[root@www mysql]# vim purge_event.sqlDROP EVENT IF EXISTS purge_salary_audit;DELIMITER $$CREATE EVENT IF NOT EXISTS purge_salary_audit ON SCHEDULEEVERY 1 DAYSTARTS CURRENT_DATEDO BEGINDELETE FROM salary_audit WHERE date_modified < DATE_ADD(CURDATE(),INTERVAL -30 day);END $$DELIMITER ;
查看事件:
mysql> SHOW EVENTS\G;*************************** 1. row ***************************Db: employeesName: purge_salary_auditDefiner: root@localhostTime zone: SYSTEMType: RECURRINGExecute at: NULLInterval value: 1Interval field: DAYStarts: 2019-08-19 00:00:00Ends: NULLStatus: ENABLEDOriginator: 1character_set_client: utf8mb4collation_connection: utf8mb4_0900_ai_ciDatabase Collation: utf8mb4_0900_ai_ci1 row in set (0.00 sec)
要检查事件的定义,可以执行:
mysql> SHOW CREATE EVENT purge_salary_audit \G
要禁用/启用该事件,可以执行以下操作:
mysql> ALTER EVENT purge_salary_audit DISABLE;mysql> ALTER EVENT purge_salary_audit ENABLE;
访问控制
所有存储的程序(过程、函数、触发器和事件)和视图都有一个DEFINER。如果未指定DEFINER,则创建该对象的用户将被选为DEFINER。
存储例程(包括过程和函数)和视图具有值为DEFINER或INVOKER的SQL SECURITY特性,来指定对象是在definer还是在invoker上下文中执行。触发器和事件没有SQL SECURITY特性,并且始终在definer上下文中执行。服务器根据需要自动调用这些对象,因此不存在调用用户。
获取有关数据库和表的信息
在数据库列表中有一个information_schema数据库。information_schema数控库是由所有数据库对象的元数据组成的视图集合。可以连接到information_schema库并浏览所有表。
INFORMATION_SCHEMA查询作为数据字典表的视图来实现。INFORMATION_SCHEMA表中有下面两种类型的元数据。
- 静态表元数据:TABLE_SCHEMA、TABLE_NAME、TABLE_TYPE和ENGINE。这些统计信息将直接从数据字典中读取。
- 动态表元数据:AUTO_INCREMENT、AVG_ROW_LENGTH和DATA_FREE。动态元数据会频繁更改(例如,AUTO_INCREMENT值将在每次INSERT后增长)。在很多情况下,动态元数据在一些需要精确计算的情况下也会产生一些开销,并且准确性可能对常规查询不会有好处。考虑到DATA_FREE统计量的情况(该统计量显示表中的空闲字节数),缓存值通常足够了。
在MySQL8.0中,动态表元数据将默认被缓存。这可以通过information_schema_stats设置(默认缓存)进行配置,并且可以更改为SET @@ GLOBAL.information_schema_stats = ‘LATEST’,以便始终直接从存储引擎中检索动态信息(代价是略长的查询执行时间)。
mysql> show variables like '%information_schema%';+---------------------------------+-------+| Variable_name | Value |+---------------------------------+-------+| information_schema_stats_expiry | 86400 |+---------------------------------+-------+1 row in set (0.00 sec)mysql> SET @@GLOBAL.information_schema_stats_expiry = 0;Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.information_schema_stats_expiry = 0;Query OK, 0 rows affected (0.00 sec)mysql> show variables like '%information_schema%';+---------------------------------+-------+| Variable_name | Value |+---------------------------------+-------+| information_schema_stats_expiry | 0 |+---------------------------------+-------+1 row in set (0.00 sec)
如果想永远改变,修改配置文件
[root@www ~]# vim /etc/my.cnfinformation_schema_stats_expiry=0
information_schema库中的大多数表具有引用数据库名称的TABLE_SCHEMA列和引用表名称的TABLE_NAME列。
如何操作
检查所有表的列表:
mysql> USE information_schema;mysql> SHOW tables;
TABLES
TABLES表包含有关表的所有信息,例如属于哪个数据库TABLE_SCHEMA,以及行数(TABLE_ROWS)、ENGINE、DATA_LENGTH、INDEX_LENGTH和DATA_FREE:
mysql> desc tables;+-----------------+--------------------------------------------------------------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+-----------------+--------------------------------------------------------------------+------+-----+---------+-------+| TABLE_CATALOG | varchar(64) | NO | | NULL | || TABLE_SCHEMA | varchar(64) | NO | | NULL | || TABLE_NAME | varchar(64) | NO | | NULL | || TABLE_TYPE | enum('BASE TABLE','VIEW','SYSTEM VIEW') | NO | | NULL | || ENGINE | varchar(64) | YES | | NULL | || VERSION | int(2) | YES | | NULL | || ROW_FORMAT | enum('Fixed','Dynamic','Compressed','Redundant','Compact','Paged') | YES | | NULL | || TABLE_ROWS | bigint(21) unsigned | YES | | NULL | || AVG_ROW_LENGTH | bigint(21) unsigned | YES | | NULL | || DATA_LENGTH | bigint(21) unsigned | YES | | NULL | || MAX_DATA_LENGTH | bigint(21) unsigned | YES | | NULL | || INDEX_LENGTH | bigint(21) unsigned | YES | | NULL | || DATA_FREE | bigint(21) unsigned | YES | | NULL | || AUTO_INCREMENT | bigint(21) unsigned | YES | | NULL | || CREATE_TIME | timestamp | NO | | NULL | || UPDATE_TIME | datetime | YES | | NULL | || CHECK_TIME | datetime | YES | | NULL | || TABLE_COLLATION | varchar(64) | YES | | NULL | || CHECKSUM | bigint(21) | YES | | NULL | || CREATE_OPTIONS | varchar(256) | YES | | NULL | || TABLE_COMMENT | text | YES | | NULL | |+-----------------+--------------------------------------------------------------------+------+-----+---------+-------+21 rows in set (0.00 sec)
例如:假设想知道employees数据库中的DATA_LENGTH、INDEX_LENGTH和DATA_FREE,代码如下;
mysql> SELECT SUM(DATA_LENGTH)/1024/1024 AS DATA_SIZE_MB,\-> SUM(INDEX_LENGTH)/1024/1024 AS INDEX_SIZE_MB,\-> SUM(DATA_FREE)/1024/1024 AS DATA_FREE_MB \-> FROM information_schema.tables WHERE TABLE_SCHEMA='employees';+--------------+---------------+--------------+| DATA_SIZE_MB | INDEX_SIZE_MB | DATA_FREE_MB |+--------------+---------------+--------------+| 143.85937500 | 5.54687500 | 0.00000000 |+--------------+---------------+--------------+1 row in set (0.00 sec)
COLUMNS
该表列出了每个表的所有列及其定义:
mysql> SELECT * FROM COLUMNS WHERE TABLE_NAME='employees'\G
FILES
MySQL将InnoDB数据存储在字典中的目录(与数据库名称相同)内的.ibd文件中。要获取有关这些文件的更多信息,可以查看FILES表:
mysql> SELECT * FROM FILES WHERE FILE_NAME LIKE './employees/employees.ibd'\G
应该关注DATA_FREE,它表示未分配的数据段,以及由于碎片而在数据段内部空闲的数据段。重建表时,可以释放DATA_FREE中显示的字节。
INNODB_TABLESPACES
INNODB_TABLESPACES表也提供了该文件的大小:
mysql> SELECT * FROM INNODB_TABLESPACES WHERE NAME='employees/employees'\G*************************** 1. row ***************************SPACE: 2NAME: employees/employeesFLAG: 16417ROW_FORMAT: DynamicPAGE_SIZE: 16384ZIP_PAGE_SIZE: 0SPACE_TYPE: SingleFS_BLOCK_SIZE: 4096FILE_SIZE: 32505856ALLOCATED_SIZE: 32505856SERVER_VERSION: 8.0.16SPACE_VERSION: 1ENCRYPTION: NSTATE: normal1 row in set (0.00 sec)
可以在文件系统中验证相同的内容:
[root@www ~]# ls -ltr /var/lib/mysql/employees/employees.ibd-rw-r----- 1 mysql mysql 32505856 Aug 16 11:43 /var/lib/mysql/employees/employees.ibd
INNODB_TABLESTATS
INNODB_TABLESTATS表提供了索引大小和近似行数:
mysql> SELECT * FROM INNODB_TABLESTATS WHERE NAME='employees/employees'\G
PROCESSLIST
最常用的视图之一是PROCESSLIST,它列出了服务器上运行的所有查询:
mysql> SELECT * FROM PROCESSLIST \G*************************** 1. row ***************************ID: 8USER: rootHOST: localhostDB: information_schemaCOMMAND: QueryTIME: 0STATE: executingINFO: SELECT * FROM PROCESSLIST*************************** 2. row ***************************ID: 4USER: event_schedulerHOST: localhostDB: NULLCOMMAND: DaemonTIME: 4193STATE: Waiting for next activationINFO: NULL2 rows in set (0.00 sec)
也可以执行show processlist来获取相同的输出结果。
mysql> show processlist;+----+-----------------+-----------+-----------+---------+------+-----------------------------+------------------+| Id | User | Host | db | Command | Time | State | Info |+----+-----------------+-----------+-----------+---------+------+-----------------------------+------------------+| 4 | event_scheduler | localhost | NULL | Daemon | 4320 | Waiting for next activation | NULL || 8 | root | localhost | employees | Query | 0 | starting | show processlist |+----+-----------------+-----------+-----------+---------+------+-----------------------------+------------------+2 rows in set (0.00 sec)
ROUTINES
包含函数和存储例程的定义
TRIGGERS
包含触发器的定义
VIEWS
包含视图的定义
事务
- 执行事务
- 使用保存点
- 隔离级别
- 锁
引言
事务就是一组应该一起成功或一起失败的SQL语句。
事务应该具备原子性、一致性、隔离性和持久性(Atomicity、Consistency、Isolation、Durability,简称ACID)的属性。举一个非常基本的例子,从账户A到账户B转账,假设账户A有600美元,账户B有400美元,希望从账户A转100美元到账户B上。
银行将从账户A中扣除100美元,并使用以下SQL代码(用于说明)向账户B添加100美元:
mysql> SELECT balance INTO @a.bal FROM account WHERE account_number='A';
以编程方式检查@a.bal是否大于或等于100:
mysql> UPDATE account SET balance=@a.bal-100 WHERE account_number='A';mysql> SELECT balance INTO @b.bal FROM account WHERE account_number='B';
以编程方式检查@b.bal是否为非空值:
mysql> UPDATE account SET balance=@b.bal+100 WHERE account_number='B';
这4条SQL语句应该是单个事务的一部分,并且满足以下ACID属性。
- 原子性:所有的SQL语句要么全部成功,要么全部失败,不会存在部分更新。如果数据库在运行两个SQL语句之后没有服从这个属性,那么账户A就会凭空损失100美元。(undo log保证)
- 一致性:事务只能以允许的方式改变受其影响的数据。在这个例子中,如果account_number与账户B不存在,则整个事务应该被回滚。
- 隔离性:同时发生的事务(并发事务)不应该导致数据库处于不一致的状态中。系统中每个事务都应该像唯一事务一样执行。任何事务都不应影响其他事务的存在。假设A向B转账的同时,A完全转移所有600美元,两个事务应该独立进行,在进行转账前确认好余额。
- 持久性:无论数据库或系统是否发生故障,数据都会永久保存在磁盘上,并且不会丢失。(redo log保证)
InnoDB是MySQL中默认的存储引擎,其支持事务处理,而MyISAM不支持事务处理。
执行事务
通过创建dummy表和示例数据来了解本节内容:
mysql> CREATE DATABASE bank;Query OK, 1 row affected (0.01 sec)mysql> USE bank;Database changedmysql> CREATE TABLE account(account_number varchar(10) PRIMARY KEY,balance int);Query OK, 0 rows affected (0.08 sec)mysql> INSERT INTO account VALUES('A',600),('B',400);Query OK, 2 rows affected (0.08 sec)Records: 2 Duplicates: 0 Warnings: 0
如何操作
要启动一个事务(一组SQL),可以执行START TRANSACTION或BEGIN语句:
mysql> START TRANSACTION;或mysql> BEGIN;
然后执行你希望在事务中包含的所有语句,例如从账户A转100美元到账户B:
mysql> SELECT balance INTO @a.bal FROM account WHERE account_number='A';Query OK, 1 row affected (0.00 sec)mysql> UPDATE account SET balance=@a.bal-100 WHERE account_number='A';Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> SELECT balance INTO @b.bal FROM account WHERE account_number='B';Query OK, 1 row affected (0.00 sec)mysql> UPDATE account SET balance=@b.bal+100 WHERE account_number='B';Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0
确保所有SQL语句成功执行后,执行COMMIT语句,该语句将完成事务并提交数据;
mysql> COMMIT;Query OK, 0 rows affected (0.00 sec)
如果遇到错误并希望中止事务,可以发送ROLLBACK语句而非COMMIT语句。
例如,如果账户A想要给一个并不存在的账户转账,则应取消交易并将金额退还给账户A:
mysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT balance INTO @a.bal FROM account WHERE account_number='A';Query OK, 1 row affected (0.00 sec)mysql> UPDATE account SET balance=@a.bal-100 WHERE account_number='A';Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> SELECT balance INTO @b.bal FROM account WHERE account_number='C';Query OK, 0 rows affected, 1 warning (0.00 sec)mysql> SHOW WARNINGS;+---------+------+-----------------------------------------------------+| Level | Code | Message |+---------+------+-----------------------------------------------------+| Warning | 1329 | No data - zero rows fetched, selected, or processed |+---------+------+-----------------------------------------------------+1 row in set (0.00 sec)mysql> SELECT @b.bal;+--------+| @b.nal |+--------+| NULL |+--------+1 row in set (0.00 sec)mysql> ROLLBACK;Query OK, 0 rows affected (0.00 sec)
检查数据并没有发生变化:
mysql> SELECT * FROM account;+----------------+---------+| account_number | balance |+----------------+---------+| A | 500 || B | 500 |+----------------+---------+2 rows in set (0.00 sec)
autocommit
默认情况下,autocommit的状态是ON,这意味着所有单独的语句一旦被执行就会被提交,除非该语句在BEGIN…COMMIT块中。如果autocommit的状态为OFF,则需要明确发出COMMIT语句来提交事务。要禁用autocommit,请执行:
mysql> SET autocommit=0;Query OK, 0 rows affected (0.00 sec)mysql> show variables like '%autocommit%';+---------------+-------+| Variable_name | Value |+---------------+-------+| autocommit | OFF |+---------------+-------+1 row in set (0.00 sec)
DDL语句,如数据库的CREATE或DROP语句,以及表或存储例程的CREATE、DROP或ALTER语句,都是无法回滚的。
使用保存点
使用保存点可以回滚到事务中的某些点,而且无需中止事务。
- 使用SAVEPOINT标识符为事务设置名称;
- 使用ROLLBACK TO标识语句将事务回滚到指定的保存点而不中止事务。
如何操作
假设账户A想向多个账户转账,即使向其中一个账户转账的操作失败,向其他账户的转账操作也不应该回滚:
mysql> USE bank;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedmysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT balance INTO @a.bal FROM account WHERE account_number='A';Query OK, 1 row affected (0.00 sec)mysql> UPDATE account SET balance=@a.bal-100 WHERE account_number='A';Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> UPDATE account SET balance=balance+100 WHERE account_number='B';Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> SAVEPOINT transfer_to_b;Query OK, 0 rows affected (0.00 sec)mysql> SELECT balance INTO @a.bal FROM account WHERE account_number='A';Query OK, 1 row affected (0.00 sec)mysql> UPDATE account SET balance=@a.bal-100 WHERE account_number='A';Query OK, 1 row affected (0.00 sec)Rows matched: 1 Changed: 1 Warnings: 0mysql> UPDATE account SET balance=balance+100 WHERE account_number='C';Query OK, 0 rows affected (0.00 sec)Rows matched: 0 Changed: 0 Warnings: 0
由于没有行被更新,意味着没有账户‘C’,所以可以将事务回滚到保存点(transfer_to_b),然后‘A’将得到从C扣除的100美元。
mysql> ROLLBACK TO transfer_to_b;Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;Query OK, 0 rows affected (0.01 sec)mysql> SELECT balance FROM account WHERE account_number='A';+---------+| balance |+---------+| 400 |+---------+1 row in set (0.00 sec)mysql> SELECT balance FROM account WHERE account_number='B';+---------+| balance |+---------+| 600 |+---------+1 row in set (0.00 sec)
隔离级别
当两个或多个事务同时发生时,隔离级别定义了一个事务与其他事务在资源或者数据修改方面的隔离程度。有4种类型的隔离级别,要更改隔离级别,需要设置transaction_isolation变量,该变量是动态的并具有会话级别的作用范围。
mysql> show variables like '%isolation%';+-----------------------+-----------------+| Variable_name | Value |+-----------------------+-----------------+| transaction_isolation | REPEATABLE-READ |+-----------------------+-----------------+1 row in set (0.02 sec)
如何操作
要更改隔离级别,请执行
mysql> SET @@transaction_isolation='READ-COMMITTED';
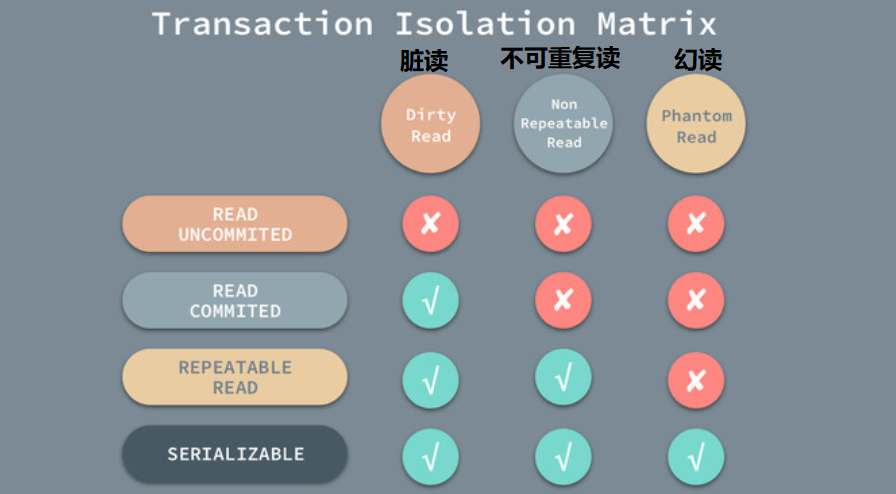
读取未提交(read uncommitted)
当前事务可以读取由另一个未提交的事务写入的数据,也称为脏读(dirty read)。
例如,想要在账户A中增加一些金额,并将其转到账户B。假设两个交易同时发生,流程将会是下面这样的:
账户A最初有400美元,我们想为账户A添加500美元,然后从账户A向账户B转账500美元,详细流程见下表。
| #事务1(增加存款) | #事务2(转账) |
|---|---|
| BEGIN; | BEGIN; |
| UPDATE account SET balance=balance+500 WHERE account_number=‘A’; | – |
| – | SELECT balance INTO @a.bal FROM account WHERE account_number=‘A’; #账户A中的金额变为900美元 |
| ROLLBACK; #假设由于某种原因事务回滚 | – |
| #由于在先前的SELECT中账户A中有900美元, 所以将账户A中的900美元转到账户B UPDATE account SET balance=balance-900 WHERE account_number=‘A’; | |
| – | #账户B收到款 UPDATE account SET balance=balance+900 WHERE account_number=‘B’; |
| – | #事务2成功完成 COMMIT; |
可以注意到,事务2已经读取了未提交或从事务1回滚的数据,导致账户A中的值在此事务之后成为负的,这显然不是所期望的。
读提交(read committed)
当前事务只能读取另一个事务提交的数据,这也称为不可重复读取(non-repeatable)。
再来看上面的例子,假设账户A有400美元,账户B有600美元。下表展示了读提交的过程。
| #事务1(增加存款) | #事务2(转账) |
|---|---|
| BEGIN; | BEGIN; |
| UPDATE account SET balance=balance+500 WHERE account_number=‘A’; | – |
| – | SELECT balance INTO @a.bal FROM account WHERE account_number=‘A’; #账户A中有美元,因为事务1还没有 提交数据 |
| COMMIT; | – |
| – | SELECT balance INTO @a.bal FROM account WHERE account_number=‘A’; #账户A中的金额变为900美元, 因为事务1已结提交了数据 |
可以注意到,在同一个事务中,相同的SELECT语句获取了不同的结果。
可重复读取(repeatable read)
一个事务通过第一条语句只能看到相同的数据,即使另一个事务已提交数据。在同一个事务中,读取通过第一次读取建立快照是一致的。一个例外是,一个事务可以读取在同一事务中更改的数据。
当事务开始并执行第一次读取数据时,将创建读取视图并保持打开状态,直到事务结束。为了在事务结束之前提供相同的结果集,InnoDB使用行版本控制和UNDO信息。假设事务1选择了几行,另一个事务删除了这些行并提交了数据。如果事务1处于打开状态,它应该能够看到自己在开始时选择的行。已被删除的行保留在UNDO日志空间中以履行事务1。一旦事务1操作完成,那些行便被标记为从UNDO日志中删除。这称为多版本并发控制(MVCC)。
再来看刚才的例子,假设账户A中有400美元,账户B中有600美元,下表展示了整个过程。
| #事务1(增加存款) | #事务2(转账) |
|---|---|
| BEGIN; | BEGIN; |
| – | SELECT balance INTO @a.bal FROM account WHERE account_number=‘A’; #账户A里有400美元 |
| UPDATE account SET balance=balance+500 WHERE account_number=‘A’; | – |
| – | SELECT balance INTO @a.bal FROM account WHERE account_number=‘A’; #尽管事务1已结提交,账户A中仍然是400美元 |
| COMMIT; | – |
| – | COMMIT; |
| – | SELECT balance INTO @a.bal FROM account WHERE account_number=‘A’; #账户A中的金额变为900美元,因为这是 一个全新的事务 |
注意:这仅适用于SELECT语句,不一定适用于DML语句。如果插入或修改某些行并提交该事务,那么从另一个并发REPEATABLE READ事务发出的DELETE或UPDATE语句,可能会影响那些刚刚提交的行,即使会话无法查询这些语句。如果事务更新或删除由不同事务提交的行,则这些更改对当前事务变为可见。具体实例如下:
| #事务1 | #事务2 |
|---|---|
| SELECT * FROM account; #2行被返回 | – |
| – | INSERT INTO account VALUES(‘C’,1000); #新account被创建 |
| – | COMMIT; |
| SELECT * FROM account WHERE account_number=‘C’; #由于MVCC ,没有行被返回 | – |
| DELECT FROM account WHERE account_number=‘C’; #令人惊讶的是,account C被删除了 | – |
| – | SELECT * FROM account; #因为事务1尚未提交,所以返回3行 |
| COMMIT; | – |
| – | SELECT * FROM account; #因为事务1已被提交,所以返回2行 |
下表是另一个例子:
| #事务1 | #事务2 |
|---|---|
| BEGIN; | BEGIN; |
| SELECT * FROM account; #2行被返回 | – |
| – | INSERT INTO account VALUES(‘D’,1000); |
| – | COMMIT; |
| SELECT * FROM account; #由于MVCC,返回了3行 | – |
| UPDATE account SET balance=1000 WHERE account_number=‘D’; #令人惊讶的是,account D得到更新 | – |
| SELECT * FROM account; #令人惊讶的是,返回了4行 | – |
序列化(serializable)
通过把选定的所有行锁起来,序列化可以提供最高级别的隔离。此级别与REPEATABLE READ类似,但如果禁用autocommit,则InnoDB会将所有普通SELECT语句隐式转换为SELECT…LOCK IN SHARE MODE;如果启用autocommit,则SELECT就是他自己的事务,如下表所示。
| #事务1 | #事务2 |
|---|---|
| BEGIN; | BEGIN; |
| SELECT * FROM account WHERE account_number=‘A’; | – |
| – | UPDATE account SET balance=1000 WHERE account_number=‘A’; #将一直等待,直到事务1在A行上的锁被释放 |
| COMMIT; | – |
| – | #UPDATE现在会成功 |
另一个例子参见下表:
| #事务1 | #事务2 |
|---|---|
| SELECT * FROM account WHERE account_number=‘A’; #选择A的值 | – |
| – | INSERT INTO account VALUES(‘D’,2000); #插入D账户 |
| SELECT * FROM account WHERE account_number=‘D’; #等待,直到事务2操作完成 | – |
| – | COMMIT; |
| #现在前面的select语句返回D的值 | – |
所以,序列化会等待被锁的行,并且总是读取最新提交的数据。
锁
有以下两种类型的锁:
- 内部锁:MySQL在自身服务器内部执行内部锁,以管理多个会话对表内容的争用;
- 外部锁:MySQL为客户会话提供选项来显式地获取表锁,以阻止其他会话访问表。
内部锁又可以分为下面两种类型。
- 行级锁:行级锁是细粒度的。只有被访问的行会被锁定。这允许通过多个会话同时进行写访问,使其适用于多用户、高度并发和OLTP(on-line transaction processing联机事务处理)的应用程序。只有InnoDB支持行级锁。
- 表级锁:MySQL对MyISAM、MEMORY和MERGE表使用表级锁,一次只允许一个会话更新这些表。这种锁定级别使得这些存储引擎更适用于只读的或以读取操作为主的或单用户的应用程序。
外部锁:可以使用LOCK TABLES和UNLOCK TABLES语句来控制锁定。
READ和WRITE的表锁定解释如下:
- READ:当一个表被锁定为READ时,多个会话可以从表中读取数据而不需要获取锁。此外,多个会话可以在同一个表上获得锁,这就是为什么READ锁也被称为共享锁。当READ锁被保持时,没有会话可以将数据写入表格中(包括持有该锁的会话)。如果有任何写入尝试,该操作将处于等待状态,直到READ锁被释放。
- WRITE:当一个表被锁定为WRITE时,除持有该锁的会话之外,其他任何会话都不能读取或向表中写入数据。除非现有锁被释放,否则其他任何会话都不能获得任何锁,所以WRITE锁也被称为排他锁。如果有任何读取/写入尝试,该操作将处于等待状态,直到WRITE锁被释放。
当执行UNLOCK TABLES语句时或当会话终止时,所有锁都将会被释放。
如何操作
语法:
锁定表:mysql> LOCK TABLES table_name [READ | WRITE]解锁表:mysql> UNLOCK TABLES;
要锁定所有数据库中的所有表,可以执行以下语句。在获取数据库的一致快照时需要使用该语句,它会冻结对数据库的所有写入操作:
mysql> FLUSH TABLES WITH READ LOCK;
锁队列
除共享锁(一个表可以有多个共享锁)之外,没有两个锁可以一起加在一个表上。如果一个表已经有一个共享锁,此时有一个排他锁要进来,那么它将被保留在队列中,直到共享锁被释放。当排他锁在队列中时,所有后续的共享锁也会被阻塞并保留在队列中。
当InnoDB从表中读取/写入数据时会获取元数据锁。如果第二个事务请求WRITE LOCK,该事务将被保留在队列中,直到第一个事务完成。如果第三个事务想要读取数据,就必须等到第二个事务完成。
事务1:
mysql> BEGIN;Query OK, 0 rows affected (0.00 sec)mysql> SELECT * FROM employees LIMIT 10;+--------+------------+------------+-----------+--------+------------+| emp_no | birth_date | first_name | last_name | gender | hire_date |+--------+------------+------------+-----------+--------+------------+| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 || 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 || 10003 | 1959-12-03 | Parto | Bamford | M | 1986-08-28 || 10004 | 1954-05-01 | Chirstian | Koblick | M | 1986-12-01 || 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 || 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 || 10007 | 1957-05-23 | Tzvetan | Zielinski | F | 1989-02-10 || 10008 | 1958-02-19 | Saniya | Kalloufi | M | 1994-09-15 || 10009 | 1952-04-19 | Sumant | Peac | F | 1985-02-18 || 10010 | 1963-06-01 | Duangkaew | Piveteau | F | 1989-08-24 |+--------+------------+------------+-----------+--------+------------+10 rows in set (0.01 sec)
注意COMMIT未执行,该事务仍保持开放状态。
事务2:
mysql> LOCK TABLE employees WRITE;
该语句必须等到事务1完成才会被执行。
事务3:
mysql> SELECT * FROM employees LIMIT 10;
事务3不会给出任何结果,因为队列中有排他锁(正在等待事务2完成操作),而且它阻塞了该表上的所有操作。
查看
另起一个会话,进行SHOW PROCESSLIST查看
mysql> show processlist;+----+-----------------+-----------+-----------+---------+------+---------------------------------+----------------------------------+| Id | User | Host | db | Command | Time | State | Info |+----+-----------------+-----------+-----------+---------+------+---------------------------------+----------------------------------+| 4 | event_scheduler | localhost | NULL | Daemon | 1798 | Waiting for next activation | NULL || 8 | root | localhost | employees | Sleep | 371 | | NULL || 9 | root | localhost | employees | Query | 218 | Waiting for table metadata lock | LOCK TABLE employees WRITE || 10 | root | localhost | employees | Query | 80 | Waiting for table metadata lock | SELECT * FROM employees LIMIT 10 || 11 | root | localhost | NULL | Query | 0 | starting | show processlist |+----+-----------------+-----------+-----------+---------+------+---------------------------------+----------------------------------+5 rows in set (0.01 sec)
可以注意到事务2和事务3都在等待事务1的完成。

若有收获,就点个赞吧
0 人点赞
