NoSQL数据存储模式
NoSQL 概念出现于1998年,发力于2009年,而这一年恰好是Hadoop技术在互联网上成功应用于大数据处理的爆发年。
NoSQL 技术主要解决以互联网业务应用为主的大数据应用问题,重点要突出处理速度的响应和海量数据的存储问题。
- 解决传统关系型数据库无法解决的数据存储及访问问题;
- 要解决大数据应用问题;
- 要解决互联网上应用问题;
最新的NoSQL官网( https://nosql-database.org )对NoSQL的定义:主体符合非关系型、分布式、开放源码和具有水平扩展能力的下一代数据库管理系统。
数据库分类
现有流行的数据库可以分为TRDB、NoSQL、NewSQL 三大类
1、TRDB数据库
传统关系型数据库技术(Traditional Relational Database),在全球范围内已经流行了40多年,从第一款关系型数据库产品Oracal,到Access、Foxpro、SQL Server、DB2、Sybase、MySQL等,主要特点如下:
- 使用强存储模式技术。这里特指数据库表、行、字段的建立,都需要预先严格定义,并进行相关属性约束;
- 采用SQL技术标准来定义和操作数据库;
- 采用强事务保证可用性及安全性;
- 主要采用单机集中式处理(CP,Centralized Processing)方式;
上述技术特点,在保证数据安全、准确运行的同时,也进一步降低了运行速度,在大数据环境下直接使用,存在速度、存储、数据多样性等方面的技术瓶颈。
2、NoSQL数据库
由于大数据问题的出现,催生了NoSQL技术,并在短短的十余年内得到了迅猛发展。该技术的出现,弥补了传统关系型数据库的技术缺陷——尤其在速度、存储量及多样化结构数据的处理问题上,NoSQL技术产品在225种以上。从数据存储结构原理的角度,一般将NoSQL数据库分为键值存储、文档存储、列族存储、图存储、其他存储5种模式。
NoSQL数据库的主要技术特点有以下几种:
- 使用弱存储模式技术。简化了约束要求,提高处理速度
- 没有采用SQL技术标准来定义和操作数据库
- 采用弱事务保证数据可用性及安全性或根本没有事务处理机制
- 主要采用多机分布式处理(DP,Distributed Processing)方式
3、NewSQL数据库
NeqSQL是最近几年才出现的一种新的数据库技术。其出现目的是为了结合传统关系型数据库与NoSQL数据库技术的特点,实现在大数据环境下的数据存储及处理。希望既要实现NoSQL技术快速、有效的大数据处理能力,又要实现传统关系数据库的SQL、事务处理等优势。
最新热门的NewSQL数据库产品包括了 PostgreSQL、SequoiaDB(国产)、MariaDB、VoltDB、Clustrix等。
NoSQL 数据存储模式
传统关系数据库在使用之前,必须先进行表结构定义,并对字段属性进行各种约束,而NoSQL在这方面的要求会很宽松,很多NoSQL数据库产品竟然不需要预先定义数据存储结构。
因此,需要进一步了解NoSQL的数据存储模式(Data Storage Scheme),发现它们的优点,避开它们的缺点。
NoSQL数据存储模式主要涉及数据库建立的存放数据的逻辑结构,基本的数据读、写、改、删等操作,数据处理对象,及在分布式状态下的一些处理方式。
一、键值数据存储模式
键值数据库(Key Value / Tuple Store)是一类轻量级结合内存处理为主的NoSQL数据库。说它轻量级,指的是它的存储数据结构特别简单,数据库系统本身规模也比较小;说它以内存(也出现了以SSD为主的新型键值数据库)为主的运行处理,设计的目的是为了更快地实现对大数据的处理。
真正的键值数据库中的约束很少,约束越少意味着执行速度越快,所能接受数据类型越多,视频、照片、音频、地图、表格、文件等都可以存储:
| 键(Key) | 值(Value) |
|---|---|
| D:\path\bag | Binary:picture |
| Http://https ://hao.360.cn |
Binary: |
| Fish:2008 | Binary:30 |
| 中国:上海:浦东 | Binary:浦东国际机场 |
- 键(key)起唯一索引值的作用,确保一个键值结构里数据记录的唯一性,同时也起信息记录的作用。
- 值(Value)是对应键相关的数据,通过键来获取,可以存放任何类型的数据。
- 键和值的组合就形成了键值对,它们之间的关系是一对一影射的关系。
- 命名空间是由键值对所构成的集合。通常由一类键值对数据构成一个集合。
- 基本数据操作方式:
- put命令:用于写或更新键值存储里指定地址的值;
- get命令:用于读键值存储里指定地址的值;
- delete命令:用于删除键值存储里指定地址的键和值
优点:
- 简单。存储结构只有键和值,并成对出现。如热门网页排行记录。当一个综合电子商务网站,想了解哪些网页受关注度高,那么应该记录用户访问的网页地址和对应点击量;
- 快速。内存为主的设计思路,使其具有快速处理数据的优势
- 高效计算。数据结构简单化,基于内存的数据集计算,为大量用户访问情况下,提供高速计算并响应的应用提供了技术支持。如电子商务网站需要根据用户历史访问记录,实时提供用户喜欢商品的推荐信息,提高用户的购买量。键值数据库就擅长解决类似问题
- 分布式处理。分布式处理能力使键值数据库具备了处理大数据的能力。它们可以把PB级的大数据放到几百台PC服务器的内存里一起计算,最后把计算结果汇总。
缺点:
- 对值进行多值查找功能很弱
- 缺少约束,意味着更容易出错
- 不容易建立复杂关系
应用案例
- Amazon的S3键值数据库产品
- Redis国内应用:医疗通、京东、阿里巴巴、腾讯(游戏)、新浪网(微博)、美团网、赶集网等
二、文档数据存储模式
文档数据库(Document Store)与传统文档数据库(word、Notes)不是一类数据库。其也是建立在对磁盘读写的基础上,但首先考虑的是读写性能,为此尽最大可能去掉传统关系型数据库的各种规范约束,甚至无须事先定义数据存储结构。
文档数据库里的文档:
{"Customer_id":"20001","Name":"张三","Addree":"中国天津和平区成都道100000号","First Shopping":"2017-02-08","Amount":20.8}{"Customer_id":"20002","Name":"李四","Addree":"中国北京东城区金宝街20000号","First Shopping":"2017-03-08","Amount":30.8}{"Customer_id":"20003","Name":"王五","Addree":"美国纽约市皇后大街30000号","First Shopping":"2017-04-08","Amount":40.8}
文档数据库借用了“键值对”的格式,实际存储时,代码的所有内容(数据和格式)都存储在一个大的字段里。这个带“{}”括号的含若干个键值对的一个大字段称之为一条文档(Document)
文档数据库存储结构基本要素
键值对(Key-Value Pair)
文档数据库数据存储结构的基本形式为键值对形式,具体由数据和格式组成。数据分为键和值两部分,格式根据数据种类的不同有所不同,如JSON(JavaScript Object Notation)、XML、BSON(Binary Serialized Document Format)等。
键一般用字符串来表示;
值可用各种数据类型表示,如数字、字符串、日期、逻辑值(True或False),也可以是更加复杂的结构,如数组、文档。
按照数据和格式的复杂程度,可以把键值对分为基本键值对、带结构键值对、多形结构键值对。
- 基本键值对:就是键和值都是基本数据类型,没有更加复杂的带结构的数据。
带结构键值对:把值带数组或嵌入文档的叫做带结构键值对。
{"Goods":[10001,20003,30008,40010] #采用数组}
{"Goods_id":"10001001","Name":"《Hadoop》权威指南","Price":67,"Publishing Information":{"Writer":(美)怀特,"ISDN":"9787302224242","Press":"清华大学出版社" #值嵌入文档}}
多形结构的键值对:就是不同结构的键值对可以放在一起,构成不同的文档,形成一个数据集。这在电子商务平台里经常会见到。这种多形结构的键值对,为基本属性差异很大的商品信息展示提供了方便,并相对传统关系型数据库来说,提高了操作速度。
文档(Document)
文档是由键值对所构成的有序集。
JSON格式的文档:
{{"Book_ID":"100002","Name":"《Python语言》","Price": 79}{"Book_ID":"100003","Name":"《C语言》","Price": 50}{"Book_ID":"100004","Name":"《Java语言》","Price": 80}}
上述代码每个“{}”里的内容代表一个文档,总共有3个文档。每个文档里的键值对必须唯一,如”Book_ID”:”100002”不能重复出现在同一个文档里。
同样的JSON内容,用XML格式文档表示如下:
<Books><Book_Record><Book_ID>100002</Book_ID><Name>"《Python语言》"</Name><Price>79</Price><Book_Record><Book_Record><Book_ID>100003</Book_ID><Name>"《C语言》"</Name><Price>50</Price><Book_Record><Book_Record><Book_ID>100004</Book_ID><Name>"《Java语言》"</Name><Price>80</Price><Book_Record></Books>
集合(Collection)
集合是由若干条文档构成的对象。一个集合对应的文档应该具有相关性。如所有的图书相关信息放在一个集合里,方便电子商务平台用户选择。

在文档数据库中为了便于操作,每个集合都有一个集合名称,如“Books”。
数据库(Database)
文档数据库中包含若干个集合,在进行数据操作之前,必须指定数据库名。
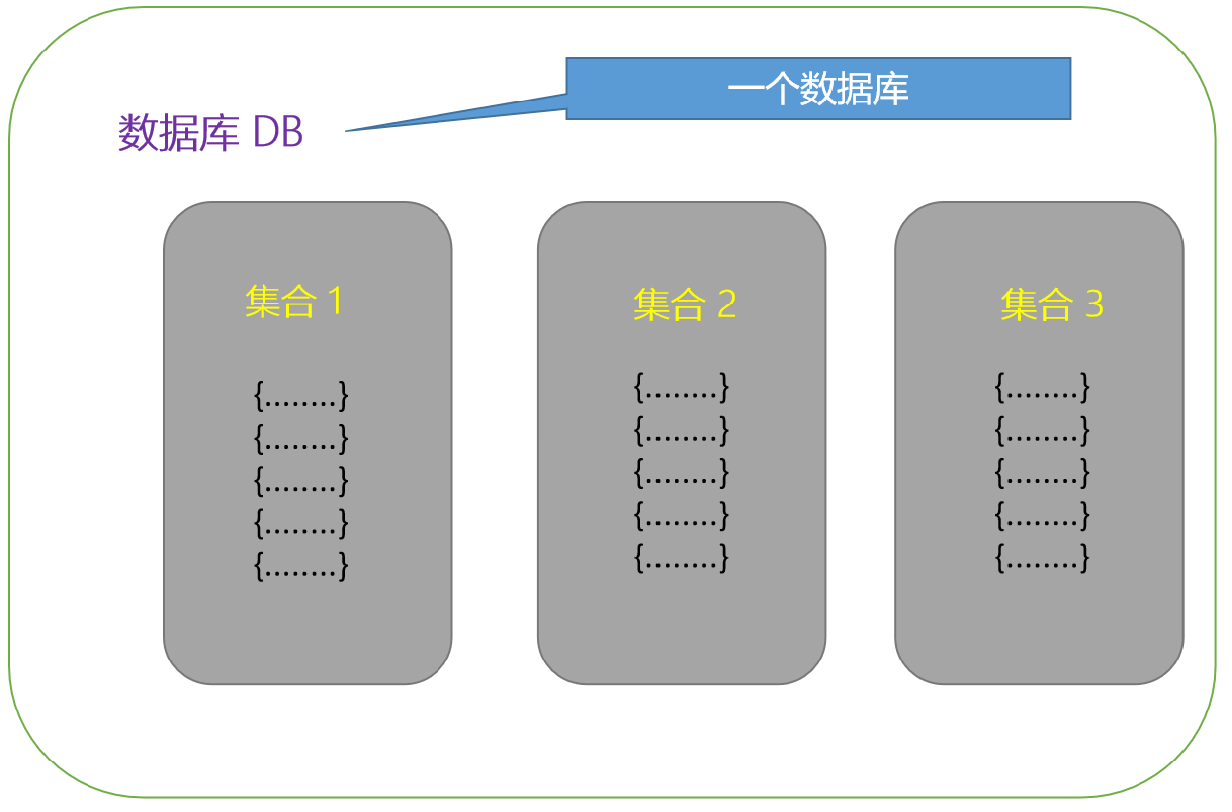
DB为文档数据库名称,一台服务器上允许多个数据库一起并存,如DB1、DB2、DB3。。。。
基本数据操作方式
对文档数据库进行操作的基本方式包括了读、写、改、删4种,以MongoDB文档数据库为例:
写(insert)命令
DB.Books.insert({"Book_ID":"100003","Name":"《C语言》","Price":50})
读(select)命令
DB.Books.find({Name":"《C语言》"})
改(update)命令
DB.Books.update({"Book_ID":"100003"},{$set{"Price":50}})
删(remove)命令
DB.Books.remove({"Book_ID":"100003"})
优点
- 简单:不考虑约束,数据存储结构简单,提高读写相应速度
- 相对高效:相对于传统关系型数据库而言。传统关系型数据库,最大并发支持操作在几千到几万条之间(一般企业或小规模访问量的在线网站)。以MongoDB为代表的文档数据库,表现为写入,每秒可以达到几万条到几十万条记录;每秒读出则可以达到几百万条。
- 文档格式处理:最擅长的就是基于JSON、XML、BSON类似的格式文档数据处理。
- 查询功能强大:相对于键值数据库而言,文档数据库具有强大的查询支持功能
- 分布式处理:具有分布式多服务器处理功能,具有很强的可伸缩性,可以轻松解决PB级甚至是EB级的数据存储应用需要
缺点:
- 缺少约束:给NoSQL数据库程序员提出了更高的代码编写要求,自己解决输入数据的验证工作,自己解决多数据集之间的关系问题,要考虑它们的操作的一致性。
- 数据出现冗余:文档数据库里允许数据出现合理的冗余,NoSQL数据库程序员应该具有权衡意识,在什么样的环境下可以允许数据更多的冗余,什么样的情况下应该减少冗余,什么样的环境下应用用类似MongoDB的文档数据库,什么样的环境下应该用Radis,什么样的环境下可以用MySQL。
- 相对低效:相对于基于内存的键值数据库而言是低效的,文档数据库是基于硬盘直接读写而进行数据操作的。
应用案例
- 大都会人寿保险公司,使用MongoDB来应对客户快速有效的在线操作体验
- 国内:阿里云、新浪云、腾讯云均提供基于云的MongoDB服务;华为、携程、中国银行、中国东方航空公司均在使用.
三、列族数据存储模式
列族数据库(Wide Column Store / Column Families)是为处理大数据而生的。为了提高数据操作效率,针对传统数据库的弱点,采用了去规则、去约束化的思路。目前在数据库引擎排行网上,最靠前的列族数据库为Cassandra、HBase,都是Hadoop生态体系下的NoSQL数据库。
列族数据库实现基本原理
- 数据库物理层
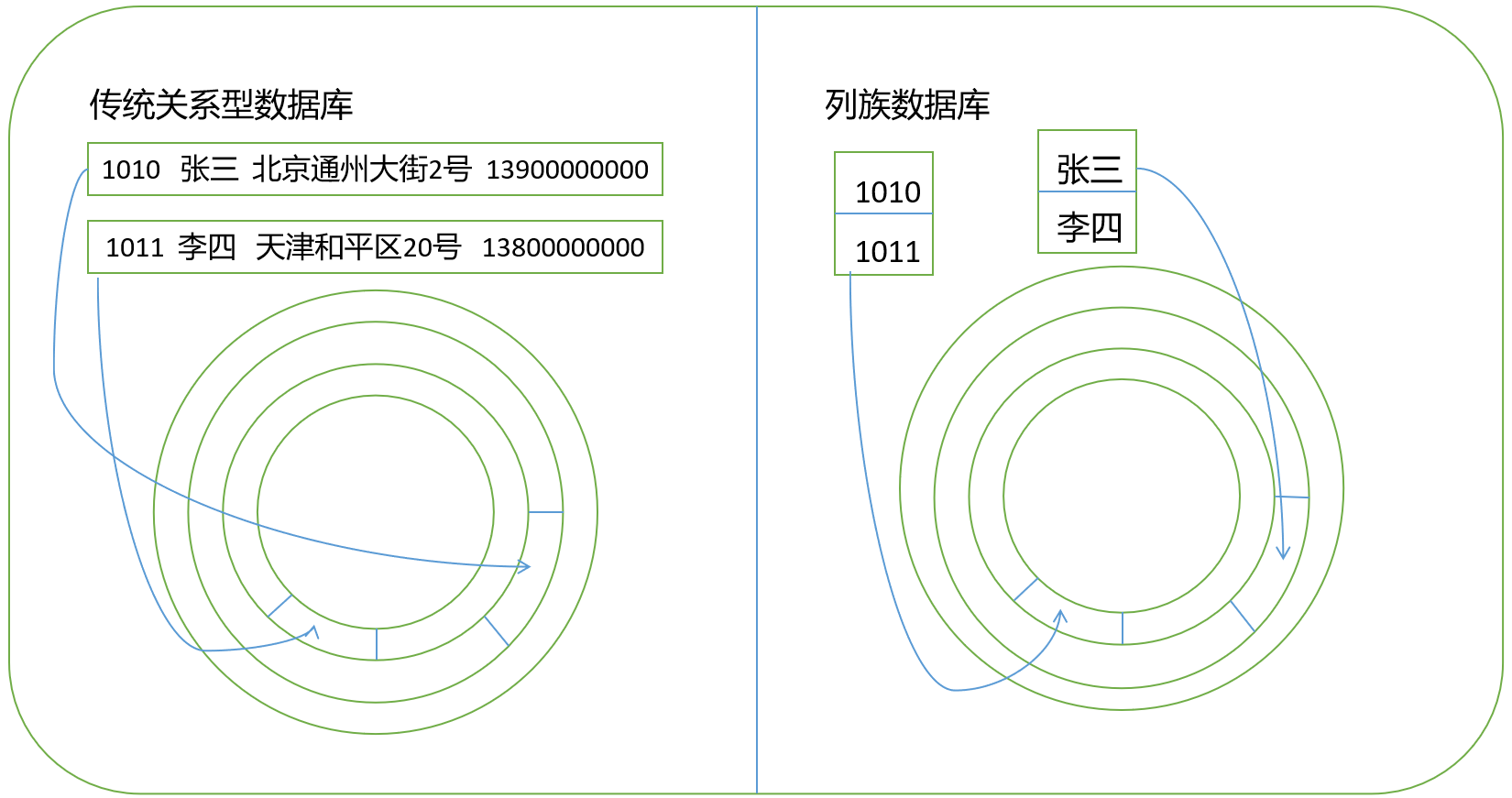
- 传统关系型数据库典型的以行为基本单位的磁盘记录方式:两条数据记录对应磁盘上两个数据块,以行为单位进行读写。
- 列族数据库典型的以列为单位的磁盘记录方式:“客户编号”字段内容作为一个数据库记录在一起,“姓名”字段内容作为另一个数据库记录在一起,“地址”“联系电话”都如此处理,以列为单位进行读写。
- 数据库逻辑层面:采用稀疏矩阵实现对数据存储的设计和管理。

- 通过命名空间->行键->列族名->列名->时间戳,即可以确定值
列族数据库存储结构基本要素
- 命名空间(namespace):是列族数据库的顶级数据库结构,相当于传统关系型数据库的表名
- 行键(Row Key):用来唯一确定列族数据库中不同行数据区别的标识符,作用与传统关系型数据库表的行主键作用类似,但列族数据库的行是虚的,只存在逻辑关系,另外,行键还起分区和排序作用。
- 列族(Column Family): 由若干个列所构成的一个集合称为列族。对于关系紧密的列可以放到一个列族里,目的是提高查询速度。
- 列(Column): 是列族数据库里用来存放单个数值的数据结构。有的列族数据库只能存放表示成字符串的各种值,不再区分值的其他类型,如Hbase。列的每个值都附带时间戳,通过时间戳来区分值的不同版本。
基本数据操作方式
列族数据库也提供读、写、删除等基本方式。
列族存储特定
- 擅长大数据处理,特别是PB、EB级别的大数据存储和从几千台到几万台级别的服务器分布式存储管理,体现了更好的可扩展性和高可用性;
- 对于命名空间、行键、列族需要预先定义,列无需预先定义,随时可以增加;
- 在大数据应用环境下,管理复杂,需要借助各种高效的管理工具来监控系统的正常运行;
- 数据存储模式相对于键值数据库、文档数据库要复杂;
- 查询功能相对更加丰富;
- 高密度写入处理能力,一般都能达到每秒百万次的并发插入处理能力;
四、图数据存储模式
图数据存储模式(Graph Database Management Systems)不是说的图片,这里的图,就是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。
图数据存储结构基本要素
- 节点(Node):代表一个事物实体,可以是城市、人、网站文章、病毒基因、包裹、网址等;
- 边(Edge): 表明实体之间的关系;
- 属性(Attribute): 节点和边都可以附加属性;
- 图(Graph):图存储是一个包含若干个节点、节点之间存在边关系,节点和边可以附加相关属性的结合系统,简称图。
图存储特点
- 处理各种具有图结构的数据。这里的图结构包括无向图、有向图、流动网络图、二分图、多重图、加权图、树等;
- 应用领域相对明确
- 具有关系的互联网社交。如QQ、微信里的群及成员关系;
- 基于地图的交通运输,如物流公司用来选择最佳派送路径;
- 生物领域比较研究,如传染病、蛋白质等相关关系的专业研究;
- 物联网跟踪,如汽配企业全球范围配件使用跟踪;
- 游戏开发,如建立玩家与道具的关系;
- 规则推理,如根据网评决定去哪家餐馆;
- 以单台服务器运行的图数据库为主。目前,只有少数图数据库具备分布式处理能力,如Titan, Neo4j;
- 图偏重于查找、统计、分析应用
应用案例
- Neo4j在eBay公司成功应用,订单快递查询业务。
五、其他数据存储模式
- 多模式数据库
- 对象数据库
- 网格和云数据库
- XML数据库
- 多维数据库
- 多值数据库
- 事件驱动数据库
- 时间序列/流数据库
- 科学、专业的数据库
- 未解决和归类的数据库
附表:主要NoSQL数据库产品特点
| NoSQL类型 | 排行前两名数据库 | 主要特点 |
|---|---|---|
| 键值数据库 | Redis、Memcached | 基于内存数据处理,相对速度最快;数据存储结构最简单,只有key-value对形式; 对值的查询统计功能支持很弱;由于基于内存数据处理,数据持久性相对弱。 Redis具备大数据管理能力(主从管理模式);事务处理能力弱 |
| 文档数据库 | MongoDB、Couchbase | MongoDB基于硬盘数据处理,速度比SQL数据库提高十几倍;Couchbase基于内存处理; 两者都具有很强的横向扩展能力;文档数据库的值具备复杂文档结构数据的处理能力, 查询统计性能相对比键值数据库要强。具备大数据处理能力;无事务处理能力 |
| 列族数据库 | Cassandra、Hbase | 基于硬盘数据处理,由于主要面向大数据存储,写速度明显比读速度要快,整体读写 速度较键值数据库、文档数据库要慢;具有强大的数据查询统计功能; 无事务处理能力 |
| 图数据库 | Neo4j、OrientDB | 基于硬盘的数据处理,侧重图数据查询计算。ACID事务 |
| 其他数据库 | MarkLogic、InfluxDB | 略 |
MongoDB安装及数据库建立
MongoDB 是NoSQL文档存储模式数据库的重要一员,目前在数据库排行网上高居前几位,体现了其受欢迎程度。
MongoDB中的“Mongo”取自于“Humongous”,代表“极大”的意思。
MongoDB是一款开源、跨平台、分布式,具有大数据处理能力的文档存储数据库。在2007年由MongoDB软件公司开发完成,并实现全部代码开源发展。目前,该文档数据库被国内外众多知名网站所采纳,用于提高数据访问的处理速度和大数据存储问题。
文档数据库MongoDB用于记录文档(document)结构的数据,如JSON、XML结构的数据。一条文档就是一条记录(含数据和数据结构),一条记录里可以包含若干个键值对(key-value pair),键又叫字段(field),值可以是普通值,如字符串、整型等;也可以是其他值,如文档、数组及文档数组。
MongoDB的主要特性
- 高性能
- 丰富的查询语言
- 高可用性。提供自动故障转移和数据冗余处理功能
- 水平扩展能力。提供基于多服务器集群的分布式数据处理能力,具体处理时分主从和权衡两种处理模式
- 多个存储引擎的支持。MongoDB提供多个存储引擎,如WiredTiger引擎、MMAPv1引擎和In-Memory,前两个基于硬盘读写的存储引擎,后一个基于内存的存储引擎。从3.2版本开始默认数据库引擎为WiredTiger。
MongoDB 存储概念比较
MongoDB与TRDB在概念上存在一些可以比较的地方。
| MongoDB | TRDB | 比较说明 |
|---|---|---|
| 数据库DB | 数据库DB | 都有数据库概念,需要用命令建立数据库名 |
| 集合 | 表 | 一个集合对应于一个表。MongoDB无须事先定义表结构,TRDB必须事先强制定义 |
| 文档 | 行 | 每个文档都有一个特殊的_id,_id值在文档所属集合中是唯一的,默认由MongoDB 自己维护,当然也可以由程序员编程指定。一个文档类似于TRDB一行记录,文档要 避免不同集合的关联关系(join),而以行为基础的TRDB强调关联关系 |
| 键值对 | 字段值 | 文档的一个键值对类似于TRDB里的一个字段值。不过文档里的值可以嵌入更复杂的数据结构 |
MongoDB安装
- 建立YUM源文件
[mongodb-org-4.2]name=MongoDB Repositorybaseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.2/x86_64/gpgcheck=1enabled=1gpgkey=https://www.mongodb.org/static/pgp/server-4.2.asc
- 安装
yum install -y mongodb-org
- 启动服务
[root@slave01 ~]# systemctl start mongod.service[root@slave01 ~]# systemctl status mongod.service● mongod.service - MongoDB Database ServerLoaded: loaded (/usr/lib/systemd/system/mongod.service; enabled; vendor preset: disabled)Active: active (running) since 六 2019-12-28 19:16:30 CST; 41s agoDocs: https://docs.mongodb.org/manualProcess: 1799 ExecStart=/usr/bin/mongod $OPTIONS (code=exited, status=0/SUCCESS)Process: 1796 ExecStartPre=/usr/bin/chmod 0755 /var/run/mongodb (code=exited, status=0/SUCCESS)Process: 1792 ExecStartPre=/usr/bin/chown mongod:mongod /var/run/mongodb (code=exited, status=0/SUCCESS)Process: 1790 ExecStartPre=/usr/bin/mkdir -p /var/run/mongodb (code=exited, status=0/SUCCESS)Main PID: 1802 (mongod)CGroup: /system.slice/mongod.service└─1802 /usr/bin/mongod -f /etc/mongod.conf12月 28 19:16:30 slave01 systemd[1]: Starting MongoDB Database Server...12月 28 19:16:30 slave01 mongod[1799]: about to fork child process, waiting until server is ready for connections.12月 28 19:16:30 slave01 mongod[1799]: forked process: 180212月 28 19:16:30 slave01 mongod[1799]: child process started successfully, parent exiting12月 28 19:16:30 slave01 systemd[1]: Started MongoDB Database Server.
- 相关数据文件及目录
/etc/mongod.conf #配置文件/var/lib/mongo #数据目录/var/log/mongodb #日志目录
- 修改配置文件
[root@slave01 ~]# vim /etc/mongod.confnet:port: 27017 #默认侦听端口bindIp: 0.0.0.0 #默认侦听127.0.0.1,修改到任意地址
数据库类型
- admin数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin数据库中,那么该用户就自动继承了所有数据库的权限。
- local数据库:这个数据库永远不会被负责,可以用来存储本地单台服务器的任意集合。
- config数据库:当MongoDB使用分片模式时,config数据库在内部使用,用于保存分片的信息。
- test数据库:MongoDB安装后的默认数据库,可以用于数据库命令的各种操作,包括测试。
- 自定义数据库:根据应用系统需要建立的业务数据库。
登录数据库
mongo : MongoDB shell工具
语法:usage: mongo [options] [db address] [file names (ending in .js)]# mongo 连接本地运行的MongoDB实例,默认端口27017# mongo --port 28015 连接非默认端口的MongoDB本地实例# mongo "mongodb://mongodb0.example.com:28015" 连接远程主机# mongo --host mongodb0.example.com:28015 连接远程主机# mongo --host mongodb0.example.com --port 28015 连接远程主机
数据库基本操作
| 命令 | 操作 |
|---|---|
| show dbs | 显示数据库列表,不显示空数据库 |
| db | 显示当前数据库 |
| use 数据库名 | 切换或创建数据(有则切换,无则创建) |
| db.dropDatabase() | 删除当前所在数据库(D大写) |
> use cisco #建立新库ciscoswitched to db cisco> db #查看当前的库cisco> show dbs #显示数据库admin 0.000GBconfig 0.000GBlocal 0.000GB> db.mytest.insert({'name':'liu'}) #插入一条数据WriteResult({ "nInserted" : 1 })> show dbsadmin 0.000GBcisco 0.000GBconfig 0.000GBlocal 0.000GB> db.dropDatabase() #删除当前库,使用"show dbs"不显示,但是使用"db"命令的时候还会看到。{ "dropped" : "cisco", "ok" : 1 }> show dbsadmin 0.000GBconfig 0.000GBlocal 0.000GB>
统计某数据库信息
语法:db.stats()
> db.stats(){"db" : "test", #数据库名称"collections" : 0, #集合数量"views" : 0,"objects" : 0, #文档对象的个数,所有集合的记录数之和"avgObjSize" : 0, #平均每个对象的大小"dataSize" : 0, #当前库所有集合的数据大小"storageSize" : 0, #磁盘存储大小"numExtents" : 0, #所有集合的扩展数据量统计数"indexes" : 0, #已建立索引数量"indexSize" : 0,"scaleFactor" : 1,"fileSize" : 0,"fsUsedSize" : 0,"fsTotalSize" : 0,"ok" : 1}
查看当前数据库下的集合名称
语法:db.getCollectionNames()
> db.getCollectionNames()[ ]> use testswitched to db test> db.mytest.insert({'name':'liu'})WriteResult({ "nInserted" : 1 })> db.getCollectionNames()[ "mytest" ]
show collections/show tables 查看集合
> use testswitched to db test> show collectionsbooksmytest> show tablesbooksmytest
db.集合名.drop() 删除集合

若有收获,就点个赞吧
0 人点赞
