- 索引及索引限制
- 查询高级分析
- 可视化管理工具
- 复制(replication)
- 三. Primary选举情况
- 四. 部署复制集
- 4.2 各节点安装MongoDB
- 4.3 修改配置文件
- 4.4 初始化副本集
- 4.5 显示副本集的配置
- 4.6 确保副本集有一个主节点
- 4.7 添加新成员到副本集中
- 4.8 从副本集中移除一个成员
- EXAMPLE
- mongod_C.example.net is in position 2 of the following configuration file:
- EXAMPLE
- To remove mongod_C.example.net:27017 use the following JavaScript operation:
索引及索引限制
MongoDB是基于集合建立索引(index),索引的作用类似于传统关系型数据库,目的是为了提高查询速度。如果没有建立索引,MongoDB在读取数据时必须扫描集合中的所有文档记录。这种全集合扫描效率是非常低的,尤其是在处理大数据时,查询可能需要花费几十秒到几分钟的时间,这对基于互联网应用的网站来说是无法容忍的。
当集合建立索引后,查询将扫描索引内容,而不会去扫描对应的集合。
但在建立索引的同时,是需要增加额外存储开销的;在已经建立索引的情况下,若新插入了集合文档记录,则会引起索引重排序,这个过程会影响查询速度。MongoDB的索引基于B-tree数据结构及对应算法形成。
默认情况下,在建立集合的同时,MongoDB数据库自动为集合_id建立唯一索引,可避免重复插入同一_id值的文档记录。
一. 使用索引
1. 单一字段(键)索引
语法:db.collection_name.createIndex({:})
命令说明:对一个集合文档的键建立索引,key为键名,n=1为升序,n=-1为降序。
> use testswitched to db test> db.books.find(){ "_id" : ObjectId("5e0cb711eb18ea3208bc19a8"), "name" : "C语言编程", "price" : 32 }{ "_id" : ObjectId("5e0cb746eb18ea3208bc19a9"), "name" : "Python入门", "price" : 48 }{ "_id" : ObjectId("5e0cb8e0eb18ea3208bc19aa"), "name" : "Java学习", "price" : 65 }{ "_id" : ObjectId("5e0cbbd2eb18ea3208bc19b7"), "name" : "小学生教材", "price" : 20 }{ "_id" : ObjectId("5e0cbbd2eb18ea3208bc19b8"), "name" : "初中生教材", "price" : 30 }{ "_id" : ObjectId("5e0cbbd2eb18ea3208bc19b9"), "name" : "高中生教材", "price" : 40 }{ "_id" : ObjectId("5e0cbc16eb18ea3208bc19ba"), "name" : "英文教材", "price" : 49 }> db.books.createIndex({name:1}){"createdCollectionAutomatically" : false,"numIndexesBefore" : 1,"numIndexesAfter" : 2,"ok" : 1}> db.books.find({name:{$regex:/教材$/}}){ "_id" : ObjectId("5e0cbbd2eb18ea3208bc19b8"), "name" : "初中生教材", "price" : 30 }{ "_id" : ObjectId("5e0cbbd2eb18ea3208bc19b7"), "name" : "小学生教材", "price" : 20 }{ "_id" : ObjectId("5e0cbc16eb18ea3208bc19ba"), "name" : "英文教材", "price" : 49 }{ "_id" : ObjectId("5e0cbbd2eb18ea3208bc19b9"), "name" : "高中生教材", "price" : 40 }> db.books.getIndexes()[{"v" : 2,"key" : {"_id" : 1},"name" : "_id_","ns" : "test.books"},{"v" : 2,"key" : {"name" : 1},"name" : "name_1","ns" : "test.books"}]
2.字段值唯一索引
语法:db.collection_name.createIndex({:,:,…},{unique:true})
命令说明:对一个或多个字段建立唯一索引。key为键名,n=1为升序,n=-1为降序。
>db.books.createIndex({name:1},{unique:true})# 注意MongoDB的命令是大小写敏感的
与上例的区别是,name的值必须是唯一的,不能有重复值出现;否则,MongoDB将新插入的重复文档予以拒绝。在没有指定{unique:true}参数选项的情况下,索引方法允许存在字段值重复的多文档记录。
说明:在集合的同一个键上不能重复建立单一索引;若已经建立了索引,再在同一个key上建立索引,将给予出错提示。
> db.books.createIndex({price:1},{unique:true}){"ok" : 0,"errmsg" : "E11000 duplicate key error collection: test.books index: price_1 dup key: { price: 30.0 }","code" : 11000,"codeName" : "DuplicateKey","keyPattern" : {"price" : 1},"keyValue" : {"price" : 30}}
3. 多字段索引
语法:db.collection_name.createIndex({:,:,…})
语法说明:对两个或两个以上的字段建立索引。key为键名,n=1为升序,n=-1为降序。
> db.foo.insert(... [... {... name:"《a cat 故事》",price:20,color:"red"... },... {... name:"《crying birds 故事》",price:20,color:"green"... },... {... name:"《big Dogs 故事》",price:25,color:"blue"... }... ])> db.foo.find(){ "_id" : ObjectId("5e2ea2dded620c2c56011be1"), "name" : "《a cat 故事》", "price" : 20, "color" : "red" }{ "_id" : ObjectId("5e2ea2dded620c2c56011be2"), "name" : "《crying birds 故事》", "price" : 20, "color" : "green" }{ "_id" : ObjectId("5e2ea2dded620c2c56011be3"), "name" : "《big Dogs 故事》", "price" : 25, "color" : "blue" }> db.foo.createIndex(... {... price:1,color:-1... }... ) //对两个字段建立索引{"createdCollectionAutomatically" : false,"numIndexesBefore" : 1,"numIndexesAfter" : 2,"ok" : 1}#使用find()查找文档记录,然后对结果用sort排序查询,先对price做升序,在price价格一样的情况下,再做color降序排序。> db.foo.find({},{_id:0}).sort({price:1,color:-1}){ "name" : "《a cat 故事》", "price" : 20, "color" : "red" }{ "name" : "《crying birds 故事》", "price" : 20, "color" : "green" }{ "name" : "《big Dogs 故事》", "price" : 25, "color" : "blue" }#用sort组price降序排序,color升序排序> db.foo.find({},{_id:0}).sort({price:-1,color:1}){ "name" : "《big Dogs 故事》", "price" : 25, "color" : "blue" }{ "name" : "《crying birds 故事》", "price" : 20, "color" : "green" }{ "name" : "《a cat 故事》", "price" : 20, "color" : "red" }用sort组price升序排序,color升序排序> db.foo.find({},{_id:0}).sort({price:1,color:1}){ "name" : "《crying birds 故事》", "price" : 20, "color" : "green" }{ "name" : "《a cat 故事》", "price" : 20, "color" : "red" }{ "name" : "《big Dogs 故事》", "price" : 25, "color" : "blue" }
多字段唯一索引
db.foo.createIndex({name:1,price:1},{unique:true})
只要name和price组合起来的值保持唯一性,就是允许的。
4. 文本索引
语法:db.collection_name.createIndex({:“text”,:“text”,…})
命令说明:在集合里,为文本字段内容的文档建立文本索引。
>db.books.createIndex({name:"text"}) //为name建立文本索引
通配符文本索引
为指定集合中的所有字符串内容进行搜索提供通配符索引,这在高度非结构化的文档里比较有用。
>db.books.createIndex({"$**":"text"})
5. 哈希索引
用于支持对分片键(带哈希键值对的分片集合)的分片数据索引,主要用于分布式数据索引。
语法:db.collection_name.createIndex({key:“hashed”})
命令说明:key为含有哈希值的键。
> db.foo.createIndex({_id:"hashed"}){"createdCollectionAutomatically" : false,"numIndexesBefore" : 2,"numIndexesAfter" : 3,"ok" : 1}
- hashed索引不支持多字段索引;
- hashed会把浮点数的小数部分自动去掉,所以对浮点数字段进行索引时,要注意该特殊情况。如2.2、2.3、2.4都会当做2进行索引排序处理;
- hashed不支持唯一索引。
6. ensureIndex()索引
语法:db.collection_name.ensureIndex({:n,:n,…},option)
命令说明:key1、key2是集合里的键名;n=1为升序,n=-1为降序;option为可选参数。
> db.foo.ensureIndex({_id:"hashed"})
- 早期的MongoDB索引命令
- MongoDB 3.0开始用createIndex命令代替ensureIndex。
7. 与索引相关的其他方法
- db.collection.dropIndex(index):移除集合指定的索引功能。index参数为指定需要删除的集合索引名,可用getIndexes()函数获取集合的所有索引名称。
- db.collection.dropIndexes():移除一个集合的所有索引功能。
- db.colleciton.getIndexes():返回一个指定集合的现有索引描述信息的文档数组。
- db.collection.reIndex():删除指定集合上所有索引,并重新构建所有现有索引。在具有大量数据集合的情况下,该操作将大量消耗服务器的运行资源,引起运行性能急剧下降等问题的发生。
- db.collection.totalIndexSize():提供指定集合索引大小的报告信息。
二. 高级索引
高级索引主要实现对文档中的子文档和数组建立索引,实现地理空间数据索引。
1. 子文档索引
语法:db.collection_name.createIndex({:,:,…})
命令说明:在集合里,对子文档建立索引。key为指向子文档的带“.”的字符串。
> use eshopsswitched to db eshops> db.books.insert(... [... {... name:"《生活百科故事1》",price:50,summary:{kind:"学前",content:"1-7岁用"}... },... {... name:"《生活百科故事2》",price:50,summary:{kind:"少儿",content:"8-16岁用"}... }... ])#对一个子文档的两个键的值进行索引。1位升序,-1为降序。> db.books.createIndex(... {... "summary.kind":1,"summary.content":-1... }... ){"createdCollectionAutomatically" : false,"numIndexesBefore" : 1,"numIndexesAfter" : 2,"ok" : 1}> db.books.find({"summary.kind":"少儿"}).pretty(){"_id" : ObjectId("5e2fef859581899dc57c2980"),"name" : "《生活百科故事2》","price" : 50,"summary" : {"kind" : "少儿","content" : "8-16岁用"}}
2. 数组索引
语法:db.collection_name.createIndex({:,:,…})
命令说明:在集合里,对数组建立索引时,MongoDB会为数组中的指定元素创建一个索引键。key为指向数组的带“.”字符串。
#插入两个带数组的文档> db.books.insert(... [... {... name:"《e故事》",... price:30,... tags:[{no:1,press:"x出版社"},{no:2,press:"y出版社"},{no:3,press:"z出版社"}]... },... {... name:"《f故事》",... price:30,... tags:[{no:11,press:"x出版社"},{no:4,press:"y出版社"},{no:2,press:"z出版社"}]... }... ])#对一个数组的两个键的值进行索引。1位升序、-1位降序> db.books.createIndex(... { "tags.no":1,"tags.press":-1}... ){"createdCollectionAutomatically" : false,"numIndexesBefore" : 2,"numIndexesAfter" : 3,"ok" : 1}> db.books.find({"tags.no":2}).pretty(){"_id" : ObjectId("5e2ff4989581899dc57c2981"),"name" : "《e故事》","price" : 30,"tags" : [{"no" : 1,"press" : "x出版社"},{"no" : 2,"press" : "y出版社"},{"no" : 3,"press" : "z出版社"}]}{"_id" : ObjectId("5e2ff4989581899dc57c2982"),"name" : "《f故事》","price" : 30,"tags" : [{"no" : 11,"press" : "x出版社"},{"no" : 4,"press" : "y出版社"},{"no" : 2,"press" : "z出版社"}]}
- 多键值索引时,只能针对集合里的一条文档的一个数组建立多键索引,不允许建立多数组索引;
- 不能为分片建立多键值索引。
3. 2dsphere(地理空间索引)
2dsphere索引支持所有MongoDB数据库地理空间查询:包含、交集和邻近的查询;并支持GeoJSON存储格式的数据。
语法:db.collection_name.createIndex({:“2dsphere”})
命令说明:在集合里,为指定键建立2dsphere索引。
#插入一条地理空间属性文档数据> db.places.insert(... {... location:{type:"Point",coordinates:[ -29.32, 50.11 ]},... name: "北海公园",... category:"公园"... }... )WriteResult({ "nInserted" : 1 })#建立2dsphere索引> db.places.createIndex({location:"2dsphere"}){"createdCollectionAutomatically" : false,"numIndexesBefore" : 1,"numIndexesAfter" : 2,"ok" : 1}> db.places.find( { location: { $near:{$geometry:{type: "Point",coordinates:[-29,49]},$maxDistance:200000} } } ).pretty(){"_id" : ObjectId("5e2ff7f29581899dc57c2983"),"location" : {"type" : "Point","coordinates" : [-29.32,50.11]},"name" : "北海公园","category" : "公园"}
三. 索引限制
建立索引的目的是为了提高查询效率,但在有些情况下,建立索引反而会出现各种问题,所以必须清楚地了解建立索引所带来的限制条件,否则很可能导致业务系统响应变得迟缓,好事变成了坏事。
1. 索引额外开销
建立一个索引至少需要8KB的数据存储空间,也就是索引是需要消耗内存和磁盘的存储空间的。
另外,对集合做插入、更新和删除时,若相关字段建立了索引,同步也会引起对索引内容的更新操作(锁独占排他性操作),这个过程是影响数据库的读写性能的,有时甚至会比较严重。所以,如果业务系统所使用的集合很少对集合进行读取操作,则建议不使用索引。
2. 内存使用限制
索引在使用时,是驻内存中持续运行的,所以索引大小不能超过内存的限制。MongoDB在索引大小超过内存限制范围后,将会删除一些索引,这将导致系统运行性能下降。索引占用空间大小,可以通过db.collection_name.totalIndexSize()方法来获取。
3. 查询限制
索引不能被以下的查询使用:
- 正则表达式及非操作符,如nin、nin、not等
- 算术运算符,如$mod等
- $where子句
说明:
- 查询语句能否使用索引功能,可以用find()的explain()来查看
- 对重要的集合进行索引查询操作,使用前建议进行严格的模拟测试
4. 索引最大范围
集合中的索引不能超过64个;索引名的长度不能超过125个字符;一个多值索引最多可以有31个字段。
如果现有的索引字段的值超过索引键的限制,MongoDB中不会创建索引。
5. 不应该使用索引场景
使用索引是否合适,主要看查询操作的使用场景,预先进行模拟测试非常重要。
- 如果查询要返回的结果超过集合文档记录的1/3,那么是否建立索引,需要慎重考虑;
- 对于以写为主的集合,建议慎用索引,默认情况下_id够用了。
查询高级分析
在集合文档记录建立索引的情况下,索引性能是数据库操作员非常关心的问题。因此find()提供了Explain()、Hint()等方法来进行检查和测试。
在实际环境下,测试的数据一个集合应该达到10万条、100万条级别;在存储容量应该考虑500GB或几个TB级别。并且应该考虑对比测试方法,如插入1万条需要多少时间、插入10万条需要多少时间等。
Explain()分析
Explain()通过对find()、count()、distinct()、group()、remove()、update()命令执行结果的分析,为程序员提供了索引是否可靠等性能的判断依据。
1. Explain()命令格式
语法:db.Collection.Command().explain(modes)
- db为当前数据库
- Collection为命令需要操作的集合名
- Command()为上述find()、update()等命令
- explain的modes参数为“queryPlanner”、“executionStats”或“allPlansExecution”
- queryPlanner模式,为改命令的默认运行模式,通过运行查询优化器对当前的查询进行评估,并选择一个最佳的查询计划,最后返回查询评估相关信息。
- executionStats模式,运行查询优化器对当前的查询进行评估并选择一个最佳的查询计划执行,在执行完毕后返回相关统计信息,但是,该模式不会为被拒绝的计划提供查询执行统计信息。
- allPlansExecution模式,该模式结合了前两种模式的特点,返回统计数据,描述获胜计划的执行情况以及在计划选择期间捕获的其他候选计划的统计数据。
2. Explain()执行返回结果及分析
> use testswitched to db test> db.books.find().explain("executionStats"){"queryPlanner" : {"plannerVersion" : 1,"namespace" : "test.books","indexFilterSet" : false,"parsedQuery" : {},"winningPlan" : {"stage" : "COLLSCAN","direction" : "forward"},"rejectedPlans" : [ ]},"executionStats" : {"executionSuccess" : true,"nReturned" : 8,"executionTimeMillis" : 14,"totalKeysExamined" : 0,"totalDocsExamined" : 8,"executionStages" : {"stage" : "COLLSCAN","nReturned" : 8,"executionTimeMillisEstimate" : 10,"works" : 10,"advanced" : 8,"needTime" : 1,"needYield" : 0,"saveState" : 0,"restoreState" : 0,"isEOF" : 1,"direction" : "forward","docsExamined" : 8}},"serverInfo" : {"host" : "slave01","port" : 27017,"version" : "4.2.2","gitVersion" : "a0bbbff6ada159e19298d37946ac8dc4b497eadf"},"ok" : 1}
Explain()在不同的模式不同运行环境下,产生的结果会不同,相关参数也会变化。
主要参数:
- winningPlan.stage:最佳的计划阶段,其值为(含子阶段值):
- SINGLE_SHARD:单一分片操作
- SHARD_MERGE:多分片合并操作
- IXSCAN:带索引查询
- COLLSCAN:集合扫描。在处理海量数据时,尽量避免出现这种执行方式。因为集合扫描过程比较低效,甚至影响系统的运行性能。
- AND_HASH:带哈希索引的操作
- OR:索引操作的条件里带“$or”表达式
- SHARDING_FILTER:分片索引
- SORT:在内存中进行了排序,在处理大规模数据时,需要慎重考虑是否需要这样做,因为它消耗内存,影响系统运行性能
- LIMIT:使用limit()命令限制返回数
- SKIP:使用skip()进行跳过
- IDHACK:针对_id进行查询
- COUNT:使用count()进行了查询
- TEXT:使用全文索引进行查询
- COUNT_SCAN:查询时使用Index进行count()。
- shardName:分片名,如“shard003”。
- connectionString:分片所在的服务器地址,如“localhost:27023”。
- serverInfo:服务器相关的信息,如host、port等
- namespace:find()数据库空间,包含了数据库名和集合名
- indexFilterSet:代表find()运行时,是否使用了带索引key条件
- parsedQuery:解析查询条件,如”eq”:1、”e*q“:1、”and”:[]等
- inputStage:嵌套文档操作类型
- rejectedPlans:查询优化器考虑和拒绝的候选计划数组,如果没有候选计划,数组为空。
上述参数内容,在Explain()为“queryPlanner”模式下类似。下面为executionStats模式下的新增统计内容:
- nReturned:返回符合查询条件的文档数;
- executionTimeMillis:查询计划选择和查询执行所需的总时间(单位:毫秒),该时间越小,系统响应越快,若超过2、3秒就应该引起重视;
- totalKeysExamined:扫描的索引条目数量;扫描索引条目的数量越少越好;
- totalDocsExamined:扫描文档的数量;越少越好
- executionStages.works:查询工作单元数,一个查询执行可以将其工作分成若干个小单元,如检查单个索引字、从集合中获取单个文档,将投影应用于单个文档等;
- executionStages.advanced:优先返回的结果数目;
- executionStages.needTime:在子阶段,执行未优化的操作过程所需要的时间;
- executionStages.needYield:数据库查询时,产生的锁的次数;次数越少越好,越多说明查询性能存在问题,并发查询冲突等问题严重;
- executionStages.isEOF:指定执行阶段是否结束,如果结束该值为true或1;如果没有结束该值为false或0。
- executionStages.invalidates:执行字阶段无效的数量。
利用Explain()的执行结果信息,在生产环境下,可以发现存在的各种运行性能问题。
3. Hint()分析
虽然MongoDB查询优化器一般工作的很不错,但是也可以使用hint来强制MongoDB使用一个指定的索引。
这种方法某些情形下会提升性能。
hint()可以为查询临时指定需要索引的字段,其主要用法有两种:
- 强制指定一个索引key,如db.collection.find().hint(“age_1”);
- 强制对集合做正向扫描或反向扫描,如:
- db.users.find().hint({$natural:1}) //强制执行正向扫描
- db.users.find().hint({$natural:-1}) //强制执行反向扫描
> use eshopsswitched to db eshops> db.books.getIndexes()[{"v" : 2,"key" : {"_id" : 1},"name" : "_id_","ns" : "eshops.books"},{"v" : 2,"key" : {"summary.kind" : 1,"summary.content" : -1},"name" : "summary.kind_1_summary.content_-1","ns" : "eshops.books"},{"v" : 2,"key" : {"tags,no" : 1,"tags.press" : -1},"name" : "tags,no_1_tags.press_-1","ns" : "eshops.books"}]
通过db.books.getIndexes()查找,可以发现books集合有3个索引,一个是_id索引(集合默认索引),一个是子文档复合索引(含kind和content键),第三个是数组复合索引(含no和press数组键名)。
> db.books.find({"summary.kind":"少儿"}).hint({_id:1}).explain("executionStats")#在hint()强制执行基于_id正向扫描时,其执行结果Explain()主要时间参数如下:{#省略部分内容"executionStats" : {"executionSuccess" : true,"nReturned" : 1,"executionTimeMillis" : 15,"totalKeysExamined" : 4,"totalDocsExamined" : 4,#省略部分内容}
在没有强制指定索引方式时,其执行结果Explain()主要时间参数如下:
> db.books.find({"summary.kind":"少儿"}).explain("executionStats"){#省略部分内容"executionStats" : {"executionSuccess" : true,"nReturned" : 1,"executionTimeMillis" : 12,"totalKeysExamined" : 1,"totalDocsExamined" : 1,#省略部分内容}
两次虽然在总用时时间上差不多,但是在查找执行过程中,在强制方式下扫描了4个索引对象,并检查了4个文档;在没有强制方式下,只扫描了一个索引对象,一个文档;这在大数据环境下,后者效率要高很多。
可以通过指定不同的索引键来测试并对比,采用哪种索引查询最优。
可视化管理工具
MongoDB支持好多可视化管理工具:
- Robomongo 管理工具
- Rockmongo
- Mongo Vue
- Ops 管理工具(MongoDB Ops Manager)
- Compass数据浏览和分析工具
- Cloud管理工具(MongoDB Cloud Manager)
Robomongo
- 免费且开源,官方下载地址:https://robomongo.org/download

- 安装后建立连接
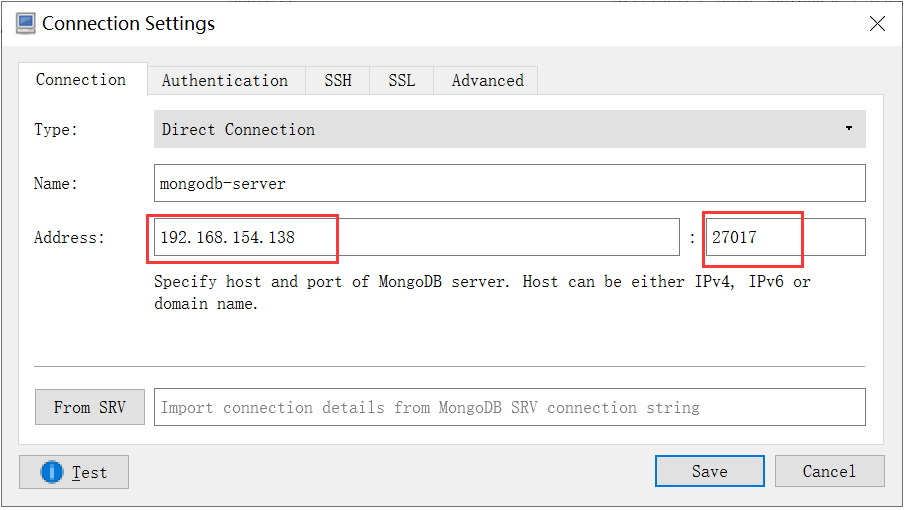
- 建立连接后既可以进行操作
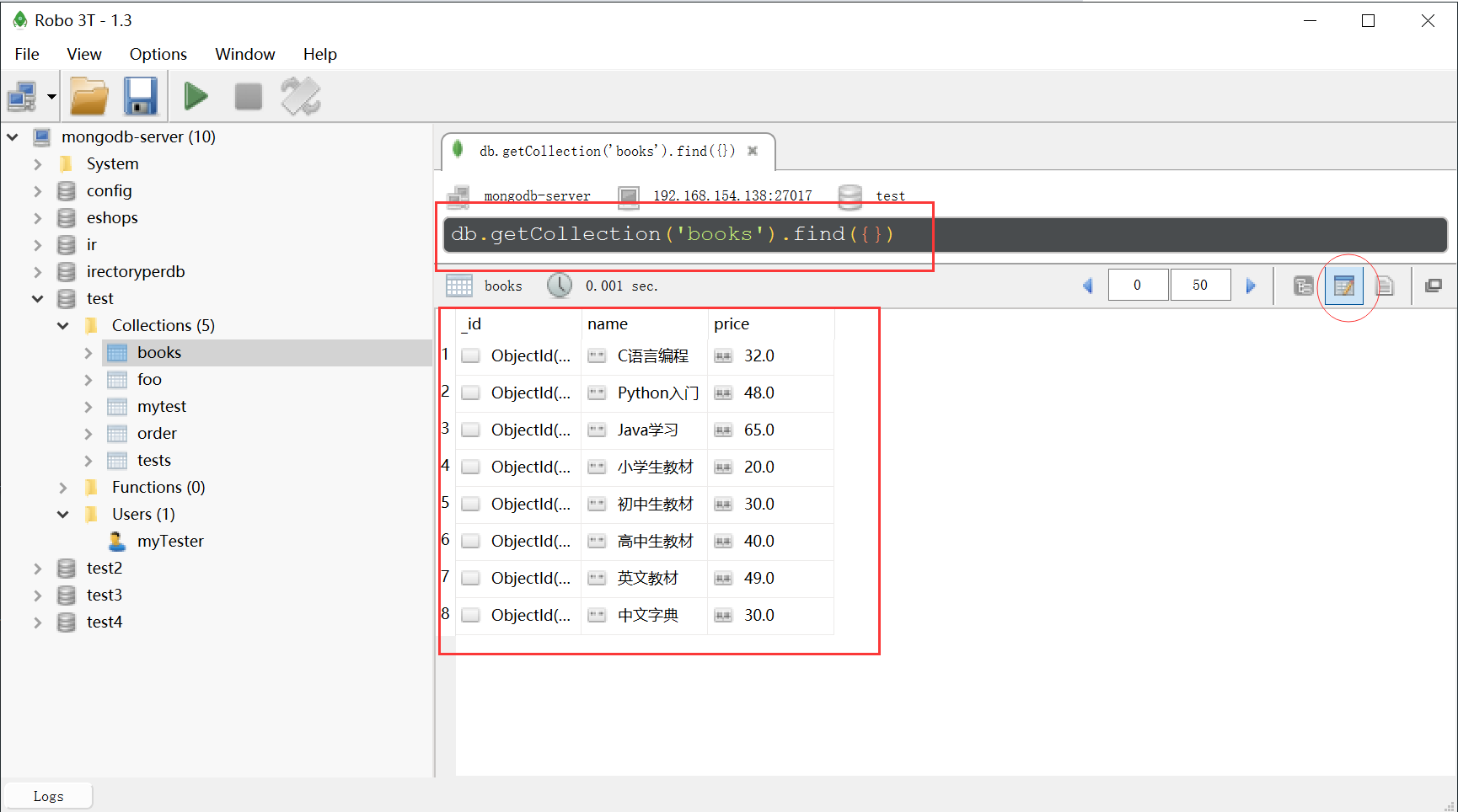
Robomongo安装后的可操作主界面是在MongoDB自带的JavaScript引擎的基础上开发而成,而JavaScript引擎是缩小版本的shell,这意味着前面在MongoDB shell操作过的命令,都可以在此界面中以可视化操作的方式来实现。Robomongo其本身提供语法高亮,自动完成,并且支持不同的显示模式(文本、树或表格)。
- 查看功能
- 集合建立、修改、删除功能
- 索引功能
- 数据库相关操作功能
- 其他相关功能
复制(replication)
MongoDB数据库在实际生产环境下,多数基于多服务器集群运行,并进行相应的数据分布式处理。必须要考虑数据库读写的可用性和安全性,如一台服务器出现故障,应该能保证MongoDB数据处理的正常进行。
复制(replication,在MongoDB数据库里又称副本集:replica set)就是为解决上述问题而产生的,通过复制功能可以实现多服务器的数据冗余备份操作;使备份数据的服务器具备额外提供独立读访问请求的功能(分布式读取数据,可以解决高并发客户端读用户访问问题);当服务器出故障时,提供自动故障转移、自动数据恢复。
MongoDB中的副本集是一组mongod进程,它们维护着相同的数据集,副本集提供冗余(redundancy)和高可用(high availability),是所有生产部署的基本。
一. 冗余和数据可用性
复制提供冗余并提高数据可用性。使用不同数据库服务器上的多个数据副本,复制可提供一定程度的容错能力,以防止丢失单个数据库服务器。
在某些情况下,复制可以提供更大的读取容量,因为客户端可以将读取操作发送到不同的服务器。在不同的数据中心,维护数据副本可以提高数据本地性和分布式应用程序的可用性。您还可以维护其他副本以用于专用目的,例如灾难恢复,报告或备份。
二. 复制
副本集包含多个数据承载节点(data bearing nodes )和一个可选的仲裁节点(arbiter node)。在数据承载节点中,一个且仅一个成员为主节点(primary node),而其他节点为从节点(secondary nodes)。
主节点是副本集中接收写操作的唯一成员。MongoDB在主数据库上应用写操作,然后在主数据库的oplog上记录操作。从节点复制此日志,并将操作应用于其数据集。

副本集的所有成员都可以接受读取操作。但是,默认情况下,应用程序将其读取操作定向到主节点。
从节点维护主节点数据集的副本。为了复制数据,一个从节点从主节点的oplog日志中执行本地操作回放,来保持与主节点数据一致。
如果当前主节点不可用,则副本集将举行一次选举,以选择哪个从节点成为新主节点。
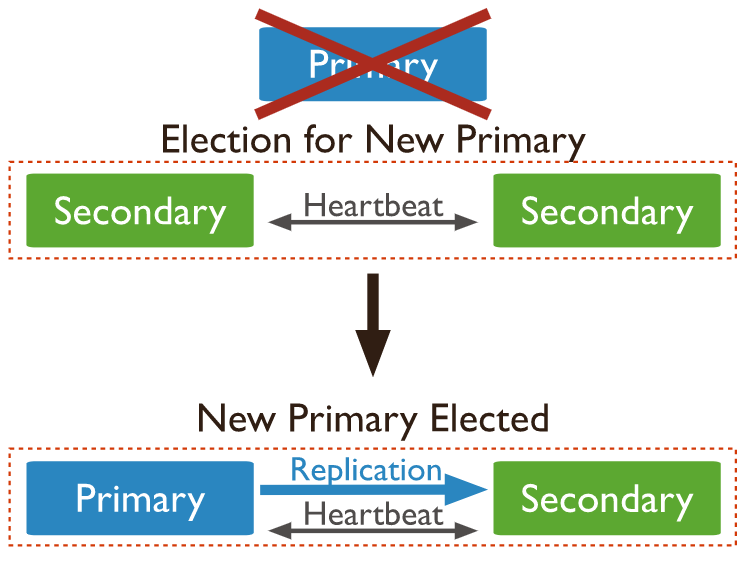
建议最小的副本集应该有3个节点:一个主节点和2个从节点。一个副本集最多可有50个成员,但只有7个有投票权的成员。
在某些情况下,例如,您有一个主服务器和一个从服务器,但成本限制禁止添加另一个从服务器),您可以选择包含仲裁器。仲裁者参与选举,但不保存数据(即不提供数据冗余)。仲裁者将永远是仲裁者,只参与投票,不能被选为Primary,并且不从Primary同步数据。
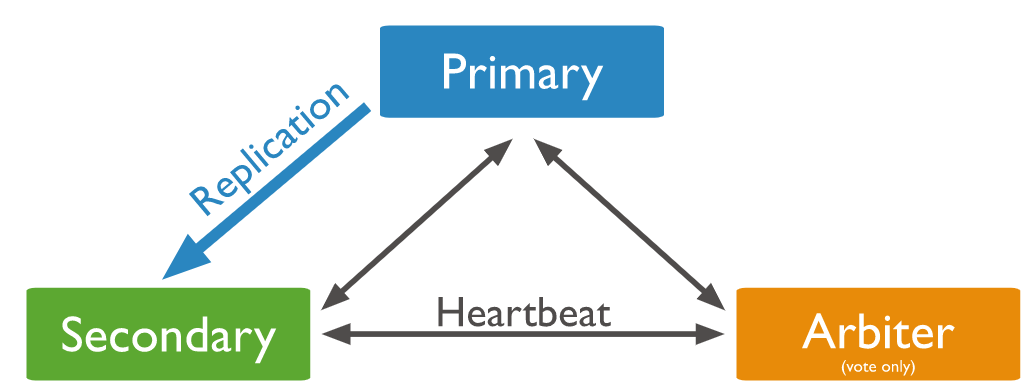
是否能被选为Primary,该属性由priority控制,priority越高,就越有机会成为Primary,通常情况下,Primary总是复制集中priority最高的成员,priority为0的Secondary不能被选为Primary,该特性一般用于跨机房部署时,避免failover后新Primary切到另一个机房;
“大多数”的定义
心跳检测:复制集内成员每隔两秒向其他成员发送心跳检测信息,若10秒内无响应,则标记其为不可用;
假设复制集内投票成员数量为 N,则大多数为 N/2 + 1,当复制集内存活成员数量不足大多数时,整个复制集将无法选举出 Primary,复制集将无法提供写服务,处于只读状态。
| 投票成员数 | 大多数 | 容忍失效数 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
Vote0
Mongodb 3.0里,复制集成员最多50个,参与 Primary 选举投票的成员最多7个,其他成员(Vote0)的 vote 属性必须设置为0,即不参与投票。
Hidden
Hidden 节点不能被选为主(Priority 为0),并且对 Driver 不可见。
因 Hidden 节点不会接受 Driver 的请求,可使用 Hidden 节点做一些数据备份、离线计算的任务,不会影响复制集的服务。
Delayed
Delayed 节点必须是 Hidden 节点,并且其数据落后于 Primary 一段时间(可配置,比如1个小时)。
因 Delayed 节点的数据比 Primary 落后一段时间,当错误或者无效的数据写入 Primary 时,可通过 Delayed 节点的数据来恢复到之前的时间点。
三. Primary选举情况
集群初始化
复制集通过 replSetInitiate 命令(或 mongo shell 的 rs.initiate())进行初始化,初始化后各个成员间开始发送心跳消息,并发起 Primary选举操作,获得大多数成员投票支持的节点,会成为 Primary,其余节点成为 Secondary。
复制集被 reconfig
Secondary 节点检测到 Primary 宕机时,会触发新 Primary 的选举,当有 Primary 节点主动 stepDown(主动降级为 Secondary)时,也会触发新的 Primary 选举。Primary 的选举受节点间心跳、优先级、最新的 oplog 时间等多种因素影响。
节点优先级
每个节点都倾向于投票给优先级最高的节点。优先级为0的节点不会主动发起 Primary 选举。当 Primary 发现有优先级更高的 Secondary,并且该 Secondary 的数据落后在10s内,则 Primary 会主动降级,让优先级更高的 Secondary 有成为 Primary 的机会。
Optime
拥有最新optime(最近一条oplog 的时间戳)的节点才能被选为 Primary。
四. 部署复制集
环境介绍:
| Replica Set Member | IP地址 | 主机名 | 角色 | MongoDB版本 | 操作系统 |
|---|---|---|---|---|---|
| member0 | 192.168.154.101 | mongodb0.example.net | primary | 4.2.2 | CentOS7.7 |
| member1 | 192.168.154.102 | mongodb1.example.net | secondary | 4.2.2 | CentOS7.7 |
| member2 | 192.168.154.103 | mongodb2.example.net | secondary | 4.2.2 | CentOS7.7 |
4.1 基础环境准备
4.1.1 配置静态IP地址和主机名,并通过/etc/hosts文件可以互相解析
4.1.2 关闭SELinux
4.1.3 配置epel源(这里配置的是阿里镜像源)
#安装阿里镜像源wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repowget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.reposed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
4.2 各节点安装MongoDB
4.2.1. 建立YUM源文件
[mongodb-org-4.2]name=MongoDB Repositorybaseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.2/x86_64/gpgcheck=1enabled=1gpgkey=https://www.mongodb.org/static/pgp/server-4.2.asc
4.2.2. 安装
yum install -y mongodb-org
4.2.3. 启动服务
[root@mongodb0 ~]# systemctl start mongod.service[root@mongodb0 ~]# systemctl status mongod.service● mongod.service - MongoDB Database ServerLoaded: loaded (/usr/lib/systemd/system/mongod.service; enabled; vendor preset: disabled)Active: active (running) since 六 2019-12-28 19:16:30 CST; 41s agoDocs: https://docs.mongodb.org/manualProcess: 1799 ExecStart=/usr/bin/mongod $OPTIONS (code=exited, status=0/SUCCESS)Process: 1796 ExecStartPre=/usr/bin/chmod 0755 /var/run/mongodb (code=exited, status=0/SUCCESS)Process: 1792 ExecStartPre=/usr/bin/chown mongod:mongod /var/run/mongodb (code=exited, status=0/SUCCESS)Process: 1790 ExecStartPre=/usr/bin/mkdir -p /var/run/mongodb (code=exited, status=0/SUCCESS)Main PID: 1802 (mongod)CGroup: /system.slice/mongod.service└─1802 /usr/bin/mongod -f /etc/mongod.conf12月 28 19:16:30 slave01 systemd[1]: Starting MongoDB Database Server...12月 28 19:16:30 slave01 mongod[1799]: about to fork child process, waiting until server is ready for connections.12月 28 19:16:30 slave01 mongod[1799]: forked process: 180212月 28 19:16:30 slave01 mongod[1799]: child process started successfully, parent exiting12月 28 19:16:30 slave01 systemd[1]: Started MongoDB Database Server.
4.2.4 防火墙放行MongoDB端口
[root@mongodb2 ~]# firewall-cmd --add-service=mongodb --permanentsuccess[root@mongodb2 ~]# firewall-cmd --reloadsuccess
4.3 修改配置文件
- 设置副本集名称
- 绑定IP/主机名
[root@mongodb0 ~]# vim /etc/mongod.confnet:port: 27017bindIp: localhost,mongodb0.example.netreplication:replSetName: "rs0"[root@mongodb0 ~]# systemctl restart mongod.service
4.4 初始化副本集
连接到任意一个mongod服务,运行rs.initiate()进行初始化
#连接到mongod[root@mongodb0 ~]# mongo#运行初始化> rs.initiate( {... _id: "rs0",... members: [... { _id: 0, host: "mongodb0.example.net:27017","priority": 3 },... { _id: 1, host: "mongodb1.example.net:27017","priority": 2 },... { _id: 2, host: "mongodb2.example.net:27017","priority": 1 }... ]... }){"ok" : 1,"$clusterTime" : {"clusterTime" : Timestamp(1580438578, 1),"signature" : {"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),"keyId" : NumberLong(0)}},"operationTime" : Timestamp(1580438578, 1)}
4.5 显示副本集的配置
rs0:PRIMARY> rs.conf(){"_id" : "rs0","version" : 1,"protocolVersion" : NumberLong(1),"writeConcernMajorityJournalDefault" : true,"members" : [{"_id" : 0,"host" : "mongodb0.example.net:27017","arbiterOnly" : false,"buildIndexes" : true,"hidden" : false,"priority" : 3,"tags" : {},"slaveDelay" : NumberLong(0),"votes" : 1},{"_id" : 1,"host" : "mongodb1.example.net:27017","arbiterOnly" : false,"buildIndexes" : true,"hidden" : false,"priority" : 2,"tags" : {},"slaveDelay" : NumberLong(0),"votes" : 1},{"_id" : 2,"host" : "mongodb2.example.net:27017","arbiterOnly" : false,"buildIndexes" : true,"hidden" : false,"priority" : 1,"tags" : {},"slaveDelay" : NumberLong(0),"votes" : 1}],"settings" : {"chainingAllowed" : true,"heartbeatIntervalMillis" : 2000,"heartbeatTimeoutSecs" : 10,"electionTimeoutMillis" : 10000,"catchUpTimeoutMillis" : -1,"catchUpTakeoverDelayMillis" : 30000,"getLastErrorModes" : {},"getLastErrorDefaults" : {"w" : 1,"wtimeout" : 0},"replicaSetId" : ObjectId("5e33943266477853906b6631")}}
4.6 确保副本集有一个主节点
rs0:PRIMARY> rs.status(){"set" : "rs0","date" : ISODate("2020-01-31T02:47:07.812Z"),"myState" : 1,"term" : NumberLong(2),"syncingTo" : "","syncSourceHost" : "","syncSourceId" : -1,"heartbeatIntervalMillis" : NumberLong(2000),"majorityVoteCount" : 2,"writeMajorityCount" : 2,"optimes" : {"lastCommittedOpTime" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"lastCommittedWallTime" : ISODate("2020-01-31T02:47:01.985Z"),"readConcernMajorityOpTime" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"readConcernMajorityWallTime" : ISODate("2020-01-31T02:47:01.985Z"),"appliedOpTime" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"durableOpTime" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"lastAppliedWallTime" : ISODate("2020-01-31T02:47:01.985Z"),"lastDurableWallTime" : ISODate("2020-01-31T02:47:01.985Z")},"lastStableRecoveryTimestamp" : Timestamp(1580438761, 1),"lastStableCheckpointTimestamp" : Timestamp(1580438761, 1),"electionCandidateMetrics" : {"lastElectionReason" : "priorityTakeover","lastElectionDate" : ISODate("2020-01-31T02:43:20.648Z"),"electionTerm" : NumberLong(2),"lastCommittedOpTimeAtElection" : {"ts" : Timestamp(1580438592, 1),"t" : NumberLong(1)},"lastSeenOpTimeAtElection" : {"ts" : Timestamp(1580438592, 1),"t" : NumberLong(1)},"numVotesNeeded" : 2,"priorityAtElection" : 3,"electionTimeoutMillis" : NumberLong(10000),"priorPrimaryMemberId" : 1,"numCatchUpOps" : NumberLong(0),"newTermStartDate" : ISODate("2020-01-31T02:43:21.757Z"),"wMajorityWriteAvailabilityDate" : ISODate("2020-01-31T02:43:22.479Z")},"electionParticipantMetrics" : {"votedForCandidate" : true,"electionTerm" : NumberLong(1),"lastVoteDate" : ISODate("2020-01-31T02:43:09.531Z"),"electionCandidateMemberId" : 1,"voteReason" : "","lastAppliedOpTimeAtElection" : {"ts" : Timestamp(1580438578, 1),"t" : NumberLong(-1)},"maxAppliedOpTimeInSet" : {"ts" : Timestamp(1580438578, 1),"t" : NumberLong(-1)},"priorityAtElection" : 3},"members" : [{"_id" : 0,"name" : "mongodb0.example.net:27017","ip" : "192.168.154.101","health" : 1,"state" : 1,"stateStr" : "PRIMARY", #主节点"uptime" : 2138,"optime" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"optimeDate" : ISODate("2020-01-31T02:47:01Z"),"syncingTo" : "","syncSourceHost" : "","syncSourceId" : -1,"infoMessage" : "","electionTime" : Timestamp(1580438600, 1),"electionDate" : ISODate("2020-01-31T02:43:20Z"),"configVersion" : 1,"self" : true,"lastHeartbeatMessage" : ""},{"_id" : 1,"name" : "mongodb1.example.net:27017","ip" : "192.168.154.102","health" : 1,"state" : 2,"stateStr" : "SECONDARY", #从节点"uptime" : 249,"optime" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"optimeDurable" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"optimeDate" : ISODate("2020-01-31T02:47:01Z"),"optimeDurableDate" : ISODate("2020-01-31T02:47:01Z"),"lastHeartbeat" : ISODate("2020-01-31T02:47:07.659Z"),"lastHeartbeatRecv" : ISODate("2020-01-31T02:47:07.226Z"),"pingMs" : NumberLong(1),"lastHeartbeatMessage" : "","syncingTo" : "mongodb0.example.net:27017","syncSourceHost" : "mongodb0.example.net:27017","syncSourceId" : 0,"infoMessage" : "","configVersion" : 1},{"_id" : 2,"name" : "mongodb2.example.net:27017","ip" : "192.168.154.103","health" : 1,"state" : 2,"stateStr" : "SECONDARY", #从节点"uptime" : 249,"optime" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"optimeDurable" : {"ts" : Timestamp(1580438821, 1),"t" : NumberLong(2)},"optimeDate" : ISODate("2020-01-31T02:47:01Z"),"optimeDurableDate" : ISODate("2020-01-31T02:47:01Z"),"lastHeartbeat" : ISODate("2020-01-31T02:47:07.659Z"),"lastHeartbeatRecv" : ISODate("2020-01-31T02:47:07.165Z"),"pingMs" : NumberLong(6),"lastHeartbeatMessage" : "","syncingTo" : "mongodb0.example.net:27017","syncSourceHost" : "mongodb0.example.net:27017","syncSourceId" : 0,"infoMessage" : "","configVersion" : 1}],"ok" : 1,"$clusterTime" : {"clusterTime" : Timestamp(1580438821, 1),"signature" : {"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),"keyId" : NumberLong(0)}},"operationTime" : Timestamp(1580438821, 1)}
4.7 添加新成员到副本集中
- 启动新的mongod实例
- 指定数据目录和副本集名称
- 绑定IP地址或主机名
- 连接到副本集的主节点,可以通过db.isMaster()命令查看
使用rs.add()命令添加新成员
rs.add( { host: "mongodb3.example.net:27017", priority: 0, votes: 0 } )
- 当一个新成员的votes和priority的值大于0时,它在初始同步期间,是具有投票权的,即使它无法提供读服务,也不能成为主服务,因为它的数据尚未一致;这可能会导致大多数有投票权的成员在线,但没有主节点被选出。所以在开始添加时设置priority和votes为0。然后,一旦成员转换为SECONDARY状态,再使用rs.reconfig()更新。
确认新节点到达SECONDARY状态
rs.status()
确认新节点到达SECONDARY状态后,更新其priority和votes
var cfg = rs.conf();cfg.members[4].priority = 1cfg.members[4].votes = 1rs.reconfig(cfg)
- 此方法可以强制当前的primary下台,从而导致选举。当主节点关闭时,mongod将关闭所有客户端连接。这通常需要10-20秒,请尝试在计划的维护期间进行这些更改。
4.8 从副本集中移除一个成员
方法一:使用rs.remove()
- 关闭mongod实例。在要移除的节点上,使用db.shutdownServer()方法;
- 连接到当前的主节点,使用db.isMaster()进行确认;
- 使用以下两种方式进行移除
如果需要重新选主,MongoDB可能会暂时断开连接。在这种情况下,shell会自动重新连接。即使命令成功,shell也可能显示DBClientCursor::init call() failed错误。rs.remove("mongod3.example.net:27017")rs.remove("mongod3.example.net")
方法二: 使用rs.reconfig()
- 关闭mongod实例。在要移除的节点上,使用db.shutdownServer()方法;
- 连接到当前的主节点,使用db.isMaster()进行确认;
- 使用rs.conf()方法查看当前配置文档并确定要删除的成员在成员数组中的位置:
```EXAMPLE
mongod_C.example.net is in position 2 of the following configuration file:
{ “_id” : “rs”, “version” : 7, “members” : [ { “_id” : 0, “host” : “mongod_A.example.net:27017” }, { “_id” : 1, “host” : “mongod_B.example.net:27017” }, { “_id” : 2, “host” : “mongod_C.example.net:27017” } ] }
4. 将当前配置文档分配给变量cfg
cfg = rs.conf()
5. 修改cfg对象以删除成员
EXAMPLE
To remove mongod_C.example.net:27017 use the following JavaScript operation:
cfg.members.splice(2,1)
6. 用新配置覆盖原有配置
rs.reconfig(cfg)
7. 确认新配置
{ “_id” : “rs”, “version” : 8, “members” : [ { “_id” : 0, “host” : “mongod_A.example.net:27017” }, { “_id” : 1, “host” : “mongod_B.example.net:27017” } ] }
<a name="5ea9d696"></a>### 4.9 副本集中的读和写从客户端应用程序的角度来看,MongoDB实例是作为单个服务器(即“独立”)还是副本集运行是透明的。但是,MongoDB为副本集提供其他读取和写入配置。<a name="dd504573"></a>#### Write Concern 写确认描述在操作返回成功之前必须确认写入操作的数据承载成员(即主成员和辅助成员,但不是仲裁成员)的数量。成员只有在成功接收并应用写入操作后才能确认写入操作。默认情况下,Primary完成写操作即返回确认消息,即: w:1;可以设置大于1的整数,以要求指定的主从节点数量进行确认。也可以设置为“majority”,表示需要“大多数”具有投票权的数量确认后返回成功消息,还可以结合日志,使用"j:true"选项,可以防止Write Concern确认数据的回滚。**语法**:
{ w:
**案例**:
db.products.insert( { item: “envelopes”, qty : 100, type: “Clasp” }, { writeConcern: { w: “majority” , wtimeout: 5000 } } )
<a name="675be046"></a>#### Read Preference 读首选项描述了MongoDB客户端如何将读取操作路由到副本集的成员。默认情况下,复制集的所有读请求都发到Primary,Driver可通过设置Read Preference来将读请求路由到其他的节点。- primary: 默认规则,所有读请求发到Primary- primaryPreferred: Primary优先,如果Primary不可达,请求Secondary- secondary: 所有的读请求都发到secondary- secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary- nearest:读请求发送到最小网络延迟的可达节点上(通过ping探测得出最近的节点)**案例**:
db.collection.find({}).readPref( “secondary”, [ { “region”: “South” } ] ) ```
更多的复制集的配置参考官方文档:https://docs.mongodb.com/manual/replication/

若有收获,就点个赞吧
0 人点赞
