YUM安装MySQL数据库
MySQL是目前使用最受信赖和广泛使用的开源数据库平台。全球十大最受欢迎和高流量的网站中有10个依赖于MySQL。MySQL 8.0通过提供全面的改进建立在这一势头上,旨在使创新的DBA和开发人员能够在最新一代的开发框架和硬件上创建和部署下一代Web,嵌入式,移动和云/ SaaS / PaaS / DBaaS应用程序平台。MySQL 8.0亮点包括:
- MySQL文档存储
- 交易数据字典
- SQL角色
- 默认为utf8mb4
- 公用表表达式
- 窗口功能
- 以及更多
安装过程:
- 下载MySQL YUM仓库:
wget https://dev.mysql.com/get/mysql80-community-release-el7-2.noarch.rpm
- 安装MySQL YUM仓库:
rpm -Uvh mysql80-community-release-el7-2.noarch.rpm
- 安装MySQL数据库
#默认安装最新GA版MySQL#可以通过运行以下命令并检查其输出来验证是否已启用和禁用了正确的子存储库[root@python-test yum.repos.d]# yum repolist enabled | grep mysqlmysql-connectors-community/x86_64 MySQL Connectors Community 95mysql-tools-community/x86_64 MySQL Tools Community 84mysql80-community/x86_64 MySQL 8.0 Community Server 82#安装MySQL# yum install mysql-community-server
- 启动数据库
#systemctl start mysqld.service#systemctl status mysqld.service
MySQL服务器初始化(从MySQL 5.7开始):在服务器初始启动时,如果服务器的数据目录为空,则会发生以下情况:
- 服务器已初始化。
- 在数据目录中生成SSL证书和密钥文件。
- 该validate_password插件安装并启用。
将’root’@‘localhost’ 创建一个超级用户帐户。设置超级用户的密码并将其存储在错误日志文件中。要显示它,请使用以下命令:
grep 'temporary password' /var/log/mysqld.log
通过使用生成的临时密码登录并为超级用户帐户设置自定义密码,尽快更改root密码:
mysql -u root -p#进入数据库后更改密码:mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'MyNewPass4!';#注意:#MySQL的 validate_password 插件默认安装。这将要求密码包含至少一个大写字母,一个小写字母,一个数字和一个特殊字符,#并且密码总长度至少为8个字符。
二进制安装
前提:
- 如果您以前使用操作系统本机程序包管理系统(如Yum或APT)安装了MySQL,则使用本机二进制文件安装时可能会遇到问题。确保您之前的MySQL安装已完全删除(使用您的包管理系统),并且还删除了任何其他文件,例如旧版本的数据文件。您也应该检查配置文件,如/etc/my.cnf或/etc/mysql目录,并删除它们。
- MySQL依赖于libaio库。如果未在本地安装此库,则数据目录初始化和后续服务器启动步骤将失败
# yum install libaio
要安装压缩的tar文件二进制分发版,请在您选择的安装位置(通常/usr/local/mysql)将其解压缩。这将创建下表中显示的目录。
通用Unix / Linux二进制包的MySQL安装布局:
| 目录 | 目录的内容 |
|---|---|
| bin | mysqld服务器,客户端和实用程序 |
| docs | 信息格式的MySQL手册 |
| man | Unix手册页 |
| include | 包含(标题)文件 |
| lib | 库文件 |
| share | 用于数据库安装的错误消息,字典和SQL |
| support-files | 其他支持文件 |
安装过程:
- 创建一个MySQL用户和组
# groupadd mysql# useradd -r -g mysql -s /bin/flase mysql
- 解压下载的二进制安装包
# cd /usr/local/# tar xvf /root/mysql/mysql-8.0.15-linux-glibc2.12-x86_64.tar.xz创建一个链接目录mysql# ln -s mysql-8.0.15-linux-glibc2.12-x86_64 mysql为了避免在使用MySQL时始终键入客户端程序的路径名,可以将/usr/local/mysql/bin目录添加到PATH变量中# export PATH=$PATH:/usr/local/mysql/bin如何希望永远生效,可以写到/root/.bash_profile文件中
- 安装后设置与测试
为导入和导出操作创建安全目录,进入安装目录:# cd /usr/local/mysql创建目录:# mkdir mysql-files设置属主属组为mysql,并设置权限# chown mysql:mysql mysql-files/# chmod 750 mysql-files/初始化命令:# bin/mysqld --initialize --user=mysql会生成一个密码,这个密码已经默认设置为过期,必须要更改才可以使用也可以初始化的时候,指定一些选项:# bin/mysqld --initialize --user=mysql--basedir=/opt/mysql/mysql 指定安装目录--datadir=/opt/mysql/mysql/data 指定数据库根目录也可以将选项放到配置文件中,假设选项文件名是 /opt/mysql/mysql/etc/my.cnf[mysqld]basedir=/opt/mysql/mysqldatadir=/opt/mysql/mysql/data然后初始化时候调用:# bin/mysqld --defaults-file=/opt/mysql/mysql/etc/my.cnf--initialize --user=mysql
- 安全启动数据库:
# bin/mysqld_safe --user=mysql &要确保使用mysql用户启动连接到数据库# mysql -uroot -pEnter password: 输入初始化的密码mysql> alter user 'root'@'localhost' identified by 'Com.123456'; 修改为新密码
- 测试服务器
使用mysqladmin验证服务器是否正在运行。以下命令提供简单的测试,以检查服务器是否已启动并响应连接:
[root@web01 mysql]# mysqladmin version -uroot -pCom.123456mysqladmin: [Warning] Using a password on the command line interface can be insecure.mysqladmin Ver 8.0.16 for linux-glibc2.12 on x86_64 (MySQL Community Server - GPL)Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.Oracle is a registered trademark of Oracle Corporation and/or itsaffiliates. Other names may be trademarks of their respectiveowners.Server version 8.0.16Protocol version 10Connection Localhost via UNIX socketUNIX socket /tmp/mysql.sockUptime: 2 min 32 secThreads: 2 Questions: 8 Slow queries: 0 Opens: 144 Flush tables: 3 Open tables: 45 Queries per second avg: 0.052
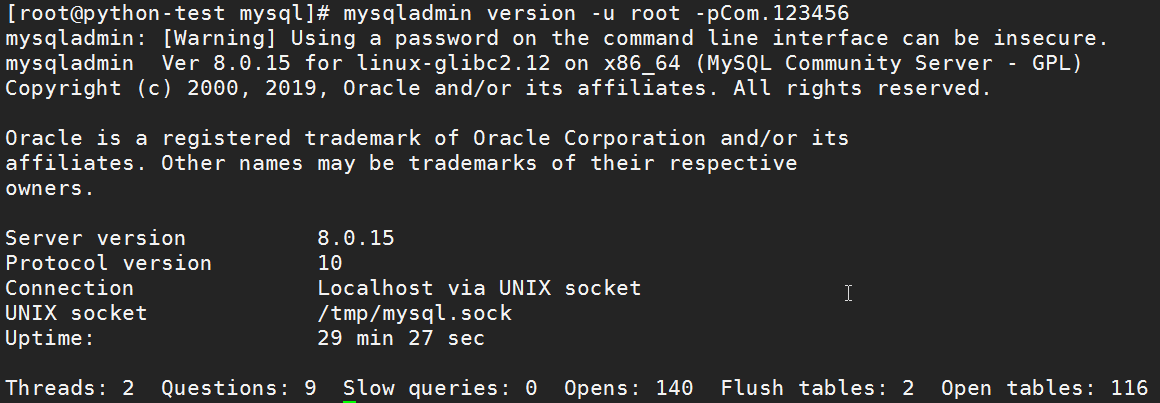
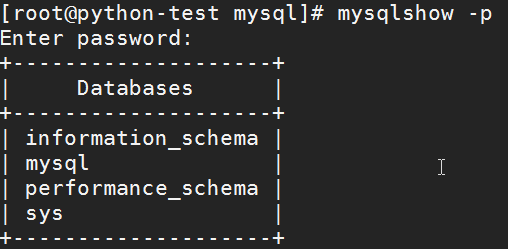
# mysqladmin variables -uroot -pCom.123456 显示可用变量验证您是否可以关闭服务器:# mysqladmin -uroot -pCom.123456 shutdown使用mysqlshow查看存在哪些数据库:# mysqlshow -p
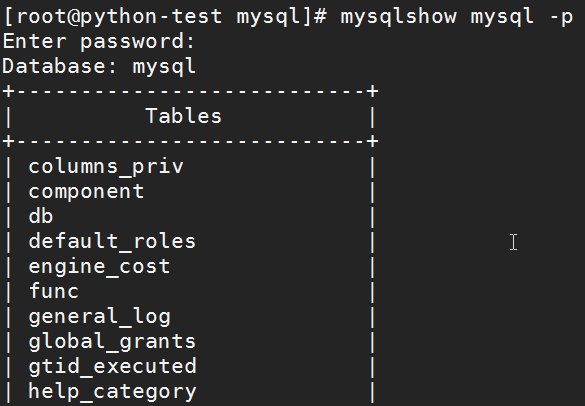
如果指定数据库名称,mysqlshow将 显示数据库中的表列表:[root@python-test mysql]# mysqlshow mysql -p
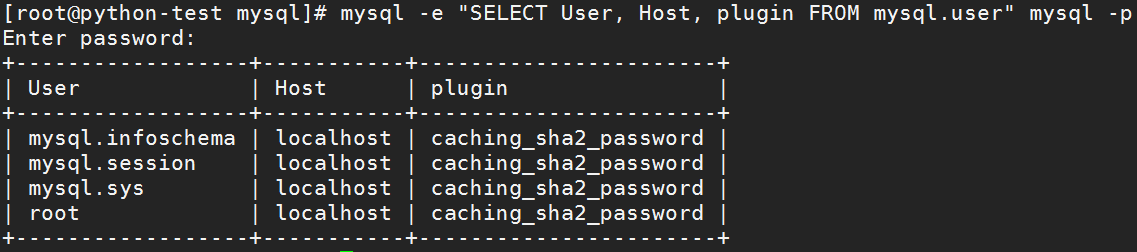
使用mysql程序从mysql架构中的表中选择信息:# mysql -e "SELECT User, Host, plugin FROM mysql.user" mysql -p
- 使用systemd启动服务器
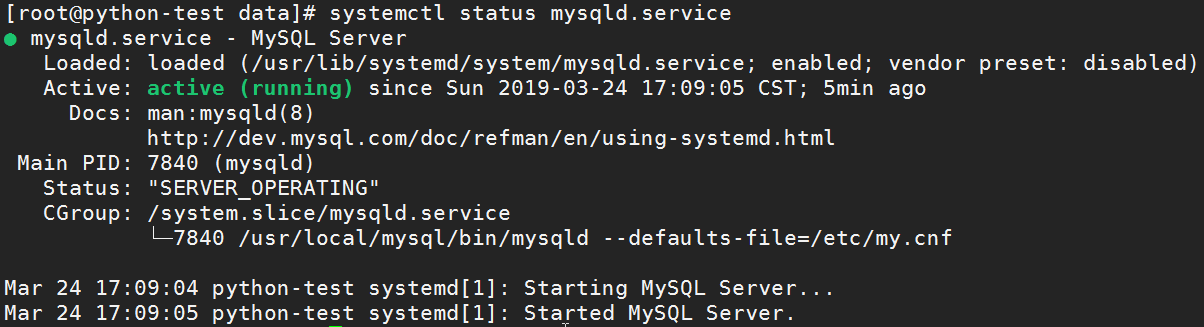
# 构建主配置文件[root@python-test mysql]# touch /etc/my.cnf[root@python-test mysql]# chmod 644 /etc/my.cnf[root@python-test data]# vim /etc/my.cnf[mysqld]datadir=/usr/local/mysql/databasedir=/usr/local/mysqlsocket=/tmp/mysql.sockport=3306log-error=/usr/local/mysql/data/python-test.erruser=mysqlsecure_file_priv=/usr/local/mysql/mysql-fileslocal_infile=OFF# 构建systemd服务单元配置文件[root@python-test data]# cat /usr/lib/systemd/system/mysqld.service[Unit]Description=MySQL ServerDocumentation=man:mysqld(8)Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.htmlAfter=network.targetAfter=syslog.target[Install]WantedBy=multi-user.target[Service]User=mysqlGroup=mysqlType=notify# Disable service start and stop timeout logic of systemd for mysqld service.TimeoutSec=0# Start main serviceExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf $MYSQLD_OPTS# Use this to switch malloc implementationEnvironmentFile=-/etc/sysconfig/mysql# Sets open_files_limitLimitNOFILE = 10000Restart=on-failureRestartPreventExitStatus=1# Set environment variable MYSQLD_PARENT_PID. This is required for restart.Environment=MYSQLD_PARENT_PID=1PrivateTmp=false# 配置MySQL开机启动:[root@python-test data]# systemctl daemon-reload[root@python-test data]# systemctl enable mysqld.service[root@python-test data]# systemctl start mysqld.service[root@python-test data]# systemctl status mysqld.service
1. 连接MySQL
使用命令行工具连接数据库
命令:mysql
- –help 查看帮助
- -h 指定主机
- -p 指定密码
- -P 指定端口 默认3306
- -u 指定登陆用户
例如:
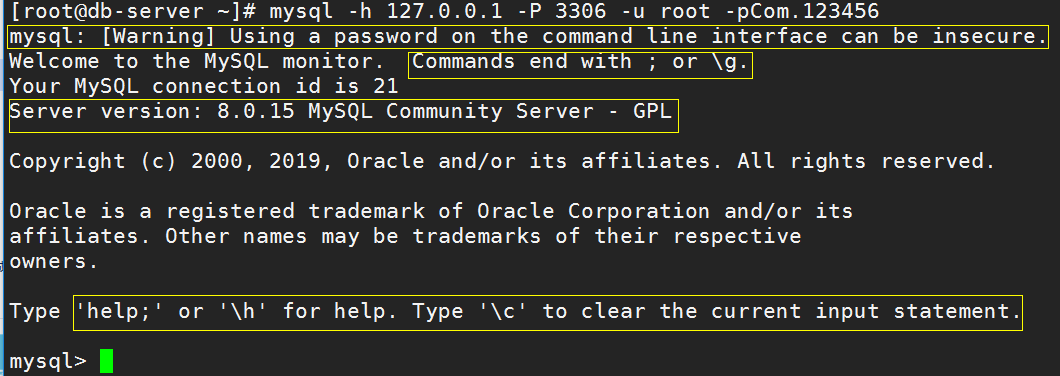
[root@db-server ~]# mysql --host=localhost --port=3306 --user=root --password=Com.123456[root@db-server ~]# mysql -h 127.0.0.1 -P 3306 -u root -pCom.123456
登陆成功界面如下:
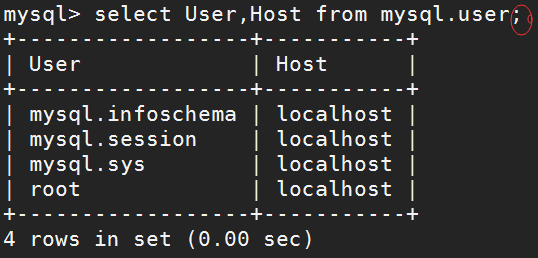
在数据库中可以输入sql语句,默认使用结束符“;”或“\g”,都是输出水平显示;如果使用“\G”,则是输出垂直显示;
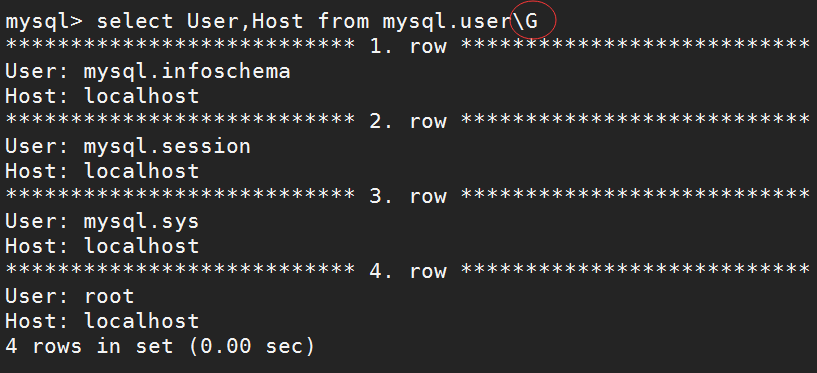
使用\G
如果想退出数据库,输入exit或者Ctrl+D
如果想撤销命令,使用Ctrl+C
基本数据库操作sql语句
数据库服务器可以容纳很多个数据库,数据库是许多表的组合,逻辑关系如下:
数据库服务器->数据库->表(由列定义)->行
表是由行和列组成。
数据库和表称为数据库对象。任何操作(如创建、修改或删除数据库对象)都称为数据定义语言(DDL)操作。
数据按某种蓝图组织构建数据库(分为数据库和表),这种数据的组织形式被称为schema。
- 创建数据库:
mysql> create database company;mysql> create database `my.contacts`;
反引号(`)用于引用标识符,如果数据库名称或者表名称中包含特殊字符,需要使用。
查看你有权访问的都有哪些数据库:
mysql> show databases;
- 切换数据库:
mysql> use company;Database changed
查看当前使用了哪个数据库:
mysql> select database();+------------+| database() |+------------+| company |+------------+1 row in set (0.00 sec)
数据库被创建为数据目录中的一个目录,如果是yum安装的默认目录是/var/lib/mysql,如果是二进制安装的,数据目录是/usr/local/mysql/data/。可以通过以下命令来查看数据目录位置。
mysql> show variables like 'datadir';+---------------+------------------------+| Variable_name | Value |+---------------+------------------------+| datadir | /usr/local/mysql/data/ |+---------------+------------------------+1 row in set (0.01 sec)
- 创建表
更难的部分是决定数据库的结构应该是什么:您需要哪些表以及每个表中应该包含哪些列。
在表中定义列时,应该指定列的名称、数据类型和默认值(如果有的话)。
MySQL支持多种类型的SQL数据类型:数字类型,日期和时间类型,字符串(字符和字节)类型,spatial 类型和 JSON数据类型
例如:
mysql> create table if not exists company.customers (-> id int unsigned auto_increment primary key,-> first_name varchar(20),-> last_name varchar(20),-> country varchar(20)-> ) engine=InnoDB;
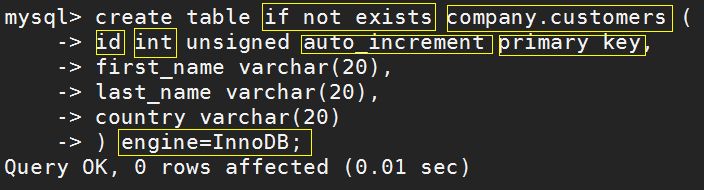
- IF NOT EXISTS:如果存在一个具有相同名字的表,并且你指定了这个字句,MySQL只会抛出一个警告,告知表已经存在。否则,MySQL将抛出一个错误。
- company.customers :前面是数据库名字,后面是表名
- id:这个是列名
- int:代表是整数型
- AUTO_INCREMENT:自动增长序列值
- PRIMARY KEY: 指定主键
- ENGINE:指定存储引擎,默认就是InnoDB
再来一个例子:
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
- sex:‘male’和 ‘female’。最简单的是使用单个字符’m’和’f’

再来一个例子:
mysql> create table company.payments (-> customer_name varchar(20) primary key,-> payment float-> );
- 查看创建的表:
mysql> show tables ;+-------------------+| Tables_in_company |+-------------------+| customers || new_customers || payments || pet |+-------------------+4 rows in set (0.00 sec)
- 查看表中的列结构:
mysql> describe pet;+---------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+---------+-------------+------+-----+---------+-------+| name | varchar(20) | YES | | NULL | || owner | varchar(20) | YES | | NULL | || species | varchar(20) | YES | | NULL | || sex | char(1) | YES | | NULL | || birth | date | YES | | NULL | || death | date | YES | | NULL | |+---------+-------------+------+-----+---------+-------+6 rows in set (0.00 sec)
mysql> show create table customers\G
mysql> show create table customers\G*************************** 1. row ***************************Table: customersCreate Table: CREATE TABLE `customers` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`first_name` varchar(20) DEFAULT NULL,`last_name` varchar(20) DEFAULT NULL,`country` varchar(20) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci1 row in set (0.00 sec)
mysql会在数据目录内创建.ibd文件
[root@db-server company]# ls -lhtr /usr/local/mysql/data/company/total 240K-rw-r-----. 1 mysql mysql 112K Apr 5 18:17 customers.ibd-rw-r-----. 1 mysql mysql 112K Apr 5 18:30 pet.ibd-rw-r-----. 1 mysql mysql 112K Apr 5 22:00 payments.ibd
- 克隆表结构
mysql> create table new_customers like customers;Query OK, 0 rows affected (0.03 sec)mysql> describe new_customers;+------------+------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+------------+------------------+------+-----+---------+----------------+| id | int(10) unsigned | NO | PRI | NULL | auto_increment || first_name | varchar(20) | YES | | NULL | || last_name | varchar(20) | YES | | NULL | || country | varchar(20) | YES | | NULL | |+------------+------------------+------+-----+---------+----------------+4 rows in set (0.00 sec)
insert、update、delete和select操作称为数据操作语言(DML)语句。insert、update和delete也称为写操作,或者简称为写(write)。select是一个读操作,简称为读(read)。
- 插入数据(insert)
mysql> insert ignore into company.customers (first_name,-> last_name,country)-> values-> ('mike','christensen','USA'),-> ('andy','Hollands','Australia'),-> ('ravi','vedantam','India'),-> ('rajiv','perera','Sri lanka');
或者明确写出id列,如果你想插入特定的id
mysql> insert ignore into company.customers (id,first_name,-> last_name,country)-> values-> (1,'mike','christensen','USA'),-> (2,'andy','Hollands','Australia'),-> (3,'ravi','vedantam','India'),-> (4,'rajiv','perera','Sri lanka');Query OK, 0 rows affected, 4 warnings (0.00 sec)Records: 4 Duplicates: 4 Warnings: 4
ignore:如果该行已经存在,并给出了ignore字句,则新数据将被忽略,insert语句仍然会执行成功,同时生成一个警告和重复数据的数目。反之,如果未给出ignore字句,则insert语句会生成一条错误信息。行的唯一性由主键标识。
mysql> show warnings;+---------+------+---------------------------------------+| Level | Code | Message |+---------+------+---------------------------------------+| Warning | 1062 | Duplicate entry '1' for key 'PRIMARY' || Warning | 1062 | Duplicate entry '2' for key 'PRIMARY' || Warning | 1062 | Duplicate entry '3' for key 'PRIMARY' || Warning | 1062 | Duplicate entry '4' for key 'PRIMARY' |+---------+------+---------------------------------------+4 rows in set (0.00 sec)
- 更新语句(update)
update用于修改表中现有数据
mysql> update customers set first_name='rajiv',country='UK' where id=4;
where:这是用于过滤的字句。在where字句后指定的任何条件都会用于过滤,被筛选出来的行都会被更新。where字句是强制性的。如果没有给出它,update会更新整个表。
- 删除语句(delete)
mysql> delete from customers where id=4 and first_name='rajiv';Query OK, 1 row affected (0.01 sec)
where字句是强制性的。如果没有给出它,delete将删除表中的所有行。
- replace、insert、on duplicate key update
在很多情况下,我们需要处理重复项。行的唯一性由主键标识。如果行已经存在,则replace会简单的删除行并插入新行;如果行不存在,则replace等同于insert。
如果你想在行已经存在的情况下处理重复项,则需要使用on duplicate key update。如果指定了on duplicate key update选项,并且insert语句在primary key中引发了重复值,则MySQL会用新值更新已有行。
假设你希望每次从同一客户那里收到付款后更新之前的金额,并且在客户首次付款时插入新记录,那么你需要定义一个金额栏,并在每次收到新付款时进行更新:
mysql> replace into customers values (1,'Mike','Christensen','America');Query OK, 2 rows affected (0.00 sec)
可以看到有两行受到影响,一个重复行被删除,一个新行被插入;
mysql> insert into payments values ('Mike Christensen',200) on duplicate key-> update payment=payment+values(payment);Query OK, 1 row affected (0.00 sec)mysql> insert into payments values ('Ravi Vedantam',500) on duplicate key-> update payment=payment+values(payment);Query OK, 1 row affected (0.00 sec)
当Mike Christensen 下次支付300美元时,将更新该行并将此付款金额添加到以前的金额中:
mysql> insert into payments values ('Mike Christensen',300) on duplicate key-> update payment=payment+values(payment);Query OK, 2 rows affected (0.00 sec)
values(payment):指的insert语句中给出的值,payment指的是表中的列。
mysql> select * from payments;+------------------+---------+| customer_name | payment |+------------------+---------+| Mike Christensen | 500 || Ravi Vedantam | 500 |+------------------+---------+2 rows in set (0.00 sec)
- truncating table
删除整个表需要很长时间,因为mysql需要逐行执行操作。删除表的所有行(保留表结构)的最快方法是使用truncate table语句。truncating table 是mysql中的DDL操作,也就是说一旦数据被清空,就不能被回滚:
mysql> truncate table info_tables;Query OK, 0 rows affected (0.03 sec)
sql查询
为了更好的练习操作,我们需要更多的数据。MySQL提供了一个示例employee数据库和大量数据提供给我们学习使用。
加载样例库步骤:
下载压缩文件:
# wget https://github.com/datacharmer/test_db/archive/master.zip
解压缩文件:
# unzip master.zip
加载数据:
# cd test_db-master/# mysql -u root -p < employees.sql
验证数据:
# mysql -uroot -p employees 登录employees库mysql> show tables;+----------------------+| Tables_in_employees |+----------------------+| current_dept_emp || departments || dept_emp || dept_emp_latest_date || dept_manager || employees || salaries || titles |+----------------------+8 rows in set (0.00 sec)
从数据库中检索数据是经常的操作,使用select可以做很多事情,这里先看最经常的用法。
从数据库的表中查询所有的数据:
mysql> select * from departments;
查询特定列的信息:
mysql> select emp_no,dept_no from dept_manager;
从employees表中查找员工的数量:
mysql> select count(*) from employees;
条件过滤:使用where字句。
所有的过滤条件都是通过where字句给出的,除整数型和浮点数外,其他所有内容都应放在引号内。
找到first_name为Georgi且last_name为Facello的员工的emp_no:mysql> select emp_no from employees where first_name='Georgi' and-> last_name='Facello';
操作符
MySQL支持使用许多操作符来筛选结果。- equality:使用=进行过滤
IN:检查一个值是否在一组值中,例如,找出姓氏为Christ、Lamba或者Baba的所有员工的人数:
mysql> select count(*) from employees where last_name in-> ('Christ','Lamba','Baba');
BETWEEN…AND:检查一个值是否在一个范围内。例如:找出1986年12月入职的员工人数:
mysql> select count(*) from employees where hire_date between-> '1986-12-01' and '1986-12-31';
NOT:简单地用NOT运算符来否定结果。例如:找出不是在1986年12月入职的员工的人数:
mysql> select count(*) from employees where hire_date not between-> '1986-12-1' and '1986-12-31';
简单模式匹配
可以使用like运算符来实现简单模式匹配。使用下划线(_)来精准匹配一个字符,使用(%)来匹配任意数量的字符。
找出名字以Christ开头的所有员工的人数:
找出名字以Christ开头并以ed结尾的所有员工的人数:
找出名字中包含sri的所有员工的人数:
找出名字以er结尾的所有员工的人数:
找出名字以任意两个字符开头、后面跟随ka、再后面跟随任意数量字符的所有员工人数:mysql> select count(*) from employees where first_name like 'Christ%';
mysql> select count(*) from employees where first_name like 'Christ%ed';
mysql> select count(*) from employees where first_name like '%sri%';
mysql> select count(*) from employees where first_name like '%er';
mysql> select count(*) from employees where first_name like '__ka%';
正则表达式:
可以使用RLIKE或者REGEXP运算符在where字句中使用正则表达式。
常用正则:
| 字符 | 含义 |
|---|---|
| * | 0次或者多次重复 |
| + | 一个或多个重复 |
| ? | 可选字符 |
| . | 任何字符 |
| . | 区间 |
| ^ | 以。。。。开始 |
| $ | 以…结束 |
| [abc] | 只有a、b或c |
| [^abc] | 非a、非b、非c |
| [a-z] | 字符a到z |
| [0-9] | 数字0到9 |
| ^…$ | 开始和结束 |
| \d | 任何数字 |
| \D | 任何非数字字符 |
| \s | 任何空格 |
| \S | 任何非空白字符 |
| \w | 任何字母数字字符 |
| \W | 任何非字母数字字符 |
| {m} | 重复m次 |
| {m,n} | 重复m到n次 |
找出名字以Christ开头的所有员工的人数:
mysql> select count(*) from employees where first_name rlike '^Christ';
找出姓氏以ba结尾的所有员工的人数:
mysql> select count(*) from employees where last_name regexp 'ba$';
查找姓氏不包含元音(a、e、i、o和u)的所有员工的人数:
mysql> select count(*) from employees where last_name not regexp '[aeiou]';
限定结果:limit
可以在查询语句末尾使用limit字句来实现限定
查询hire_date在1986年之前的任何10名员工的姓名:
mysql> select first_name,last_name from employees where hire_date < '1986-01-01' limit 10;
使用表别名:as
可以使用as语句来做别名显示
将conut(*)显示列改为numbers列输出
mysql> select count(*) as numbers from employees where hire_date < '1986-01-01';
排序和使用聚合函数
对结果排序
可以根据列或者别名列队结果进行排序,也可以使用DESC指定按降序或用ASC指定按升序来排序。默认情况下,排序安装升序来进行。
可以将LIMIT字句与ORDER BY结合使用以限定结果集。
查找薪水最高的前5名员工的员工编号
mysql> select emp_no,salary from salaries order by salary desc limit 5;+--------+--------+| emp_no | salary |+--------+--------+| 43624 | 158220 || 43624 | 157821 || 254466 | 156286 || 47978 | 155709 || 253939 | 155513 |+--------+--------+5 rows in set (1.36 sec)
也可以在select语句中提及列的位置,而不是指定列名称。例如,想对位于第二列的工资进行排序,那么可以指定order by 2;
mysql> select emp_no,salary from salaries order by 2 desc limit 5;+--------+--------+| emp_no | salary |+--------+--------+| 43624 | 158220 || 43624 | 157821 || 254466 | 156286 || 47978 | 155709 || 253939 | 155513 |+--------+--------+5 rows in set (1.41 sec)
结果也是一样的
对结果分组(聚合函数)
可以在列上使用GROUP BY字句对结果进行分组,然后使用聚合函数(aggregate),例如COUNT、MAX、MIN和AVERAGE。还可以在group by字句中的列上使用函数。
COUNT
分别找出男性和女性员工的人数:
mysql> select gender ,count(*) as count from employees group by gender;+--------+--------+| gender | count |+--------+--------+| M | 179973 || F | 120051 |+--------+--------+2 rows in set (0.40 sec)
找出员工名字中最常见的10个名字
mysql> select first_name,count(first_name) as count from employees group by first_name order by count desc limit 10;+-------------+-------+| first_name | count |+-------------+-------+| Shahab | 295 || Tetsushi | 291 || Elgin | 279 || Anyuan | 278 || Huican | 276 || Make | 275 || Sreekrishna | 272 || Panayotis | 272 || Hatem | 271 || Giri | 270 |+-------------+-------+10 rows in set (0.34 sec)
SUM
查找每年给予员工的薪水总额,并按薪水高低对结果进行排序。YEAR()函数返回给定日期所在的年份:
mysql> select '2017-05-13',year('2017-6-13');+------------+-------------------+| 2017-05-13 | year('2017-6-13') |+------------+-------------------+| 2017-05-13 | 2017 |+------------+-------------------+1 row in set (0.00 sec)mysql> select year(from_date),sum(salary) as sum from salaries-> group by year(from_date) order by sum desc limit 5;+-----------------+-------------+| year(from_date) | sum |+-----------------+-------------+| 2000 | 17535667603 || 2001 | 17507737308 || 1999 | 17360258862 || 1998 | 16220495471 || 1997 | 15056011781 |+-----------------+-------------+5 rows in set (2.99 sec)
AVERAGE
查找平均工资最高的10名员工:
mysql> select emp_no,avg(salary) as avg from salaries-> group by emp_no order by avg desc limit 10;+--------+-------------+| emp_no | avg |+--------+-------------+| 109334 | 141835.3333 || 205000 | 141064.6364 || 43624 | 138492.9444 || 493158 | 138312.8750 || 37558 | 138215.8571 || 276633 | 136711.7333 || 238117 | 136026.2000 || 46439 | 135747.7333 || 254466 | 135541.0625 || 253939 | 135042.2500 |+--------+-------------+10 rows in set (2.45 sec)
DISTINCT
可以使用DISTINCT字句过滤出表中的不同条目:
mysql> select distinct title from titles;+--------------------+| title |+--------------------+| Senior Engineer || Staff || Engineer || Senior Staff || Assistant Engineer || Technique Leader || Manager |+--------------------+7 rows in set (0.31 sec)
HAVING过滤
可以通过添加HAVING字句来过滤GROUP BY字句的结果
例如:找出平均工资超过140000美元的员工:
mysql> select emp_no, avg(salary) as avg from salaries-> group by emp_no having avg > 140000 order by avg desc;+--------+-------------+| emp_no | avg |+--------+-------------+| 109334 | 141835.3333 || 205000 | 141064.6364 |+--------+-------------+2 rows in set (1.40 sec)

若有收获,就点个赞吧
0 人点赞
