MySQL高可用方案简介
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。很多公司的高可用目标是4个9,也就是99.99%,这就意味着,系统的年停机时间为8.76个小时。
考虑MySQL数据库的高可用的架构时,主要要考虑如下几方面:
- 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断。
- 用作备份、只读副本等功能的非主节点的数据应该和主节点的数据实时或者最终保持一致。
- 当业务发生数据库切换时,切换前后的数据库内容应当一致,不会因为数据缺失或者数据不一致而影响业务。
常见高可用方案
1. 主从或主主半同步复制
使用双节点数据库,搭建单向或者双向的半同步复制。在5.7以后的版本中,由于lossless replication、logical多线程复制等一些列新特性的引入,使得MySQL原生半同步复制更加可靠。
常见架构如下:
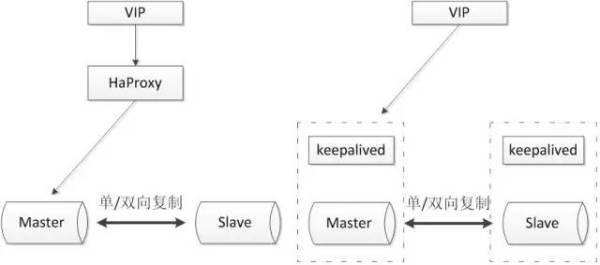
通常会和proxy、keepalived等第三方软件同时使用,即可以用来监控数据库的健康,又可以执行一系列管理命令。如果主库发生故障,切换到备库后仍然可以继续使用数据库。
优点:
- 架构比较简单,使用原生半同步复制作为数据同步的依据;
- 双节点,没有主机宕机后的选主问题,直接切换即可;
- 双节点,需求资源少,部署简单;
缺点:
- 完全依赖于半同步复制,如果半同步复制退化为异步复制,数据一致性无法得到保证;
- 需要额外考虑haproxy、keepalived的高可用机制。
2. 高可用架构优化
将双节点数据库扩展到多节点数据库,或者多节点数据库集群。可以根据自己的需要选择一主两从、一主多从或者多主多从的集群。
由于半同步复制,存在接收到一个从机的成功应答即认为半同步复制成功的特性,所以多从半同步复制的可靠性要优于单从半同步复制的可靠性。并且多节点同时宕机的几率也要小于单节点宕机的几率,所以多节点架构在一定程度上可以认为高可用性是好于双节点架构。
但是由于数据库数量较多,所以需要数据库管理软件来保证数据库的可维护性。可以选择MMM、MHA或者各个版本的proxy等等。常见方案如下:
2.1 MHA+多节点集群
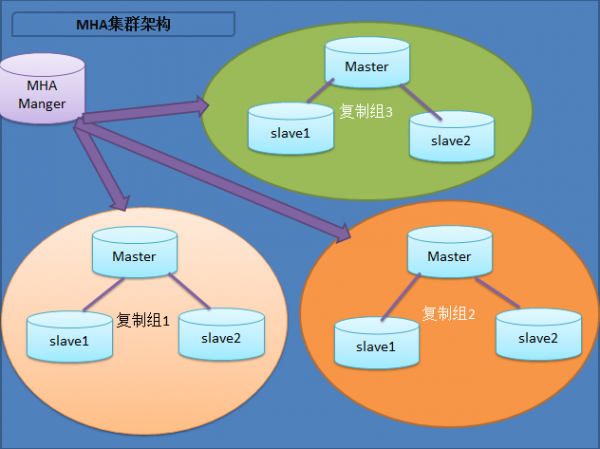
MHA集群架构:
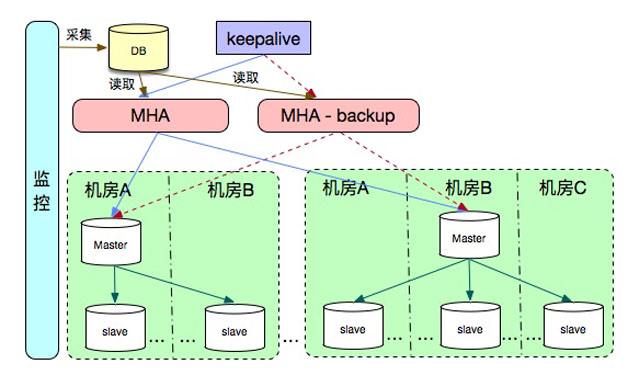
MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master,整个故障转移过程对应用程序完全透明。
MHA Node运行在每台MySQL服务器上,主要作用是切换时处理二进制日志,确保切换尽量少丢数据。
优点:
- 可以进行故障的自动检测和转移;
- 可扩展性较好,可以根据需要扩展MySQL的节点数量和结构;
- 相比于双节点的MySQL复制,三节点/多节点的MySQL发生不可用的概率更低
缺点:
- 至少需要三节点,相对于双节点需要更多的资源;
- 逻辑较为复杂,发生故障后排查问题,定位问题更加困难;
- 数据一致性仍然靠原生半同步复制保证,仍然存在数据不一致的风险;
- 可能因为网络分区发生脑裂现象;
2.2 MMM架构
MMM架构全称:Multi-Master Replication Manager。它主要是监控和管理Mysql的主主复制拓扑,并在当前的主服务器失效时,进行主和主备服务器之间的主从切换和故障转移等工作。主主复制有主动主动模式和主动被动模式两种,MMM用于主动被动模式的主主复制。它可以监控Mysql主从复制健康情况,在主库出现宕机时进行故障转移并自动配置其他从服务器对新主服务器的复制。MMM要解决的问题是如何找到从库对应的新的主库日志同步点以及多个从库出现数据不一致的情况。MMM提供了主,写虚拟IP,在主从服务器出现问题时可以自动迁移虚拟IP。MMM架构如下图所示:
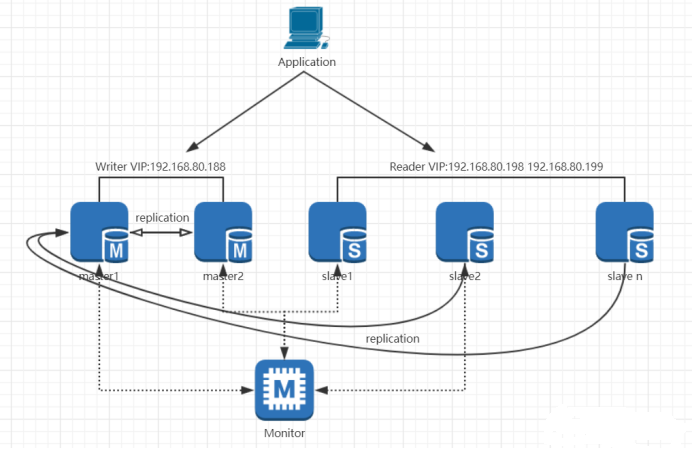
优点:
- 使用perl脚本语言开发及完全开源
- 提供了读写VIP,使服务器角色的变更对前端应用透明,在从服务器出现大量的主从延迟,主从链路中断时可以把这台从服务器上的读的虚拟IP,漂移到集群中其他正常的服务器上
- 提供了从服务器的监控延迟
- MMM提供了主数据库故障转移后从服务器对新主的重新同步功能,很容易让发生故障的主数据库重新上线。
缺点:
- MMM发布时间比较早不支持Mysql新的复制功能,对于Mysql5.6所提供的多线程复制技术也不支持
- 不支持Mysql新的复制功能,没有读负载均衡功能,需要通过LVS和F5来做负载均衡
- 在进行主从切换时,容易造成数据丢失
- MMM监控服务存在单点故障
3. 基于共享存储方案
共享存储实现了数据库服务器和存储设备的解耦,不同数据库之间的数据同步不再依赖于MySQL的原生复制功能,而是通过磁盘数据同步的手段,来保证数据的一致性。
SAN的概念是允许存储设备和处理器(服务器)之间建立直接的高速网络(与LAN相比)连接,通过这种连接实现数据的集中式存储。常用架构如下:
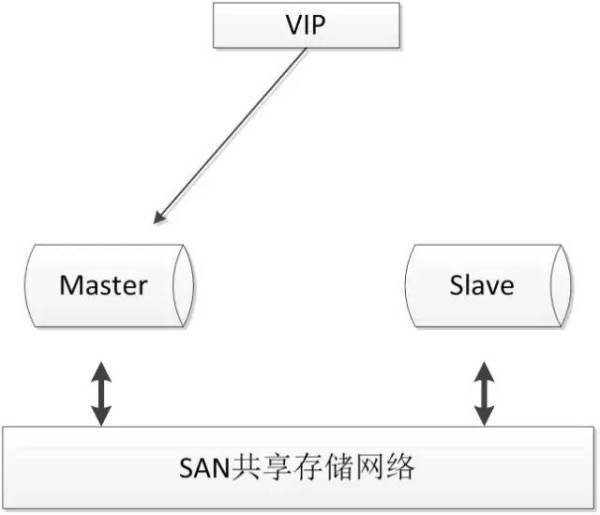
使用共享存储时,MySQL服务器能够正常挂载文件系统并操作,如果主库发生宕机,备库可以挂载相同的文件系统,保证主库和备库使用相同的数据。
优点:
- 两节点即可,部署简单,切换逻辑简单;
- 很好的保证数据的强一致性;
- 不会因为MySQL的逻辑错误发生数据不一致的情况;
缺点:
- 需要考虑共享存储的高可用;
- 价格昂贵;
4. 基于磁盘复制方案
分布式块设备复制DRDB(Distributed Relicated Block Deivce,DRBD)是一个以linux内核模块方式实现的块级别同步复制技术。它通过网卡将主服务器的每个块复制到另外一个服务器块设备上,并在主设备提交块之前记录下来。类似共享存储解决方案。
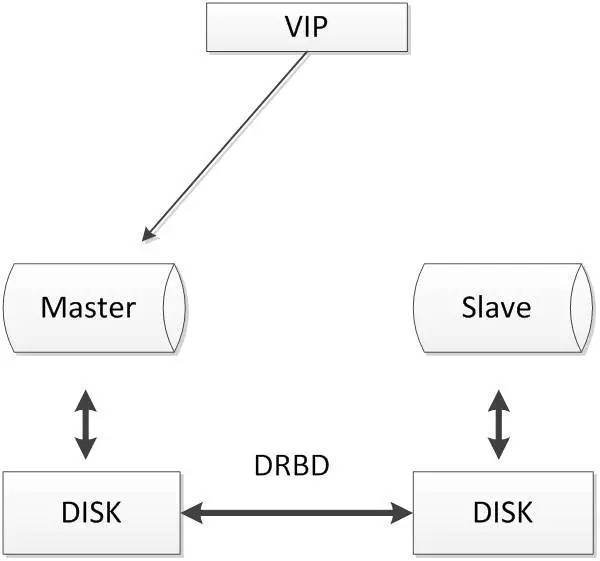
当本地主机出现问题,远程主机上还保留着一份相同的数据,可以继续使用,保证了数据的安全。DRBD是linux内核模块实现的快级别的同步复制技术,可以与SAN达到相同的共享存储效果。
优点:
- 两节点即可,部署简单,切换逻辑简单;
- 相比于SAN储存网络,价格低廉;
- 保证数据的强一致性;
缺点:
- 对io性能影响较大;
- 从库不提供读操作;
5. 分布式协议
分布式协议可以很好解决数据一致性问题。比较常见的方案如下:
5.1 MySQL cluster
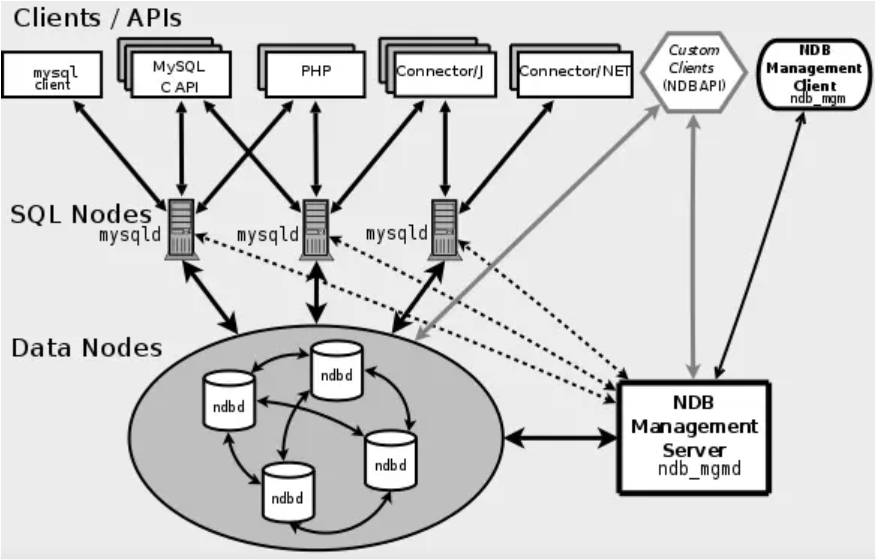
MySQL cluster是官方集群的部署方案,通过使用NDB存储引擎实时备份冗余数据,实现数据库的高可用性和数据一致性。
MySQL Cluster的访问过程大致是这样的,应用通常使用一定的负载均衡算法将对数据访问分散到不同的SQL节点,SQL节点对数据节点进行数据访问并从数据节点返回数据结果,管理节点仅仅只是对SQL节点和数据节点进行配置管理;
优点:
- 全部使用官方组件,不依赖于第三方软件;
- 可以实现数据的强一致性;
缺点:
- 国内使用的较少;
- 配置较复杂,需要使用NDB储存引擎,与MySQL常规引擎存在一定差异;
- 至少三节点;
5.2 Galera
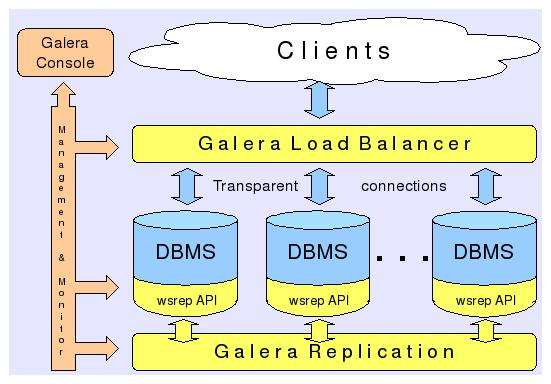
基于Galera的MySQL高可用集群, 是多主数据同步的MySQL集群解决方案,使用简单,没有单点故障,可用性高。
是一种新型的,数据不共享的,高度冗余的高可用的方案。目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster,都是基于Galera的,所以这里都统称为Galera Cluster了,因为Galera本身是具有多主特性的,所以Galera Cluster也就是multi-master的集群架构。
优点:
- 多主写入,无延迟复制,能保证数据强一致性;
- 有成熟的社区,有互联网公司在大规模的使用;
- 自动故障转移,自动添加、剔除节点;
缺点:
- 需要为原生MySQL节点打wsrep补丁
- 只支持innodb储存引擎
- 至少三节点;
5.3 MGR
MySQL Group Replication(MGR)是MySQL官方在5.7.17版本引进的一个数据库高可用与高扩展的解决方案,以插件形式提供,实现了分布式下数据的最终一致性。
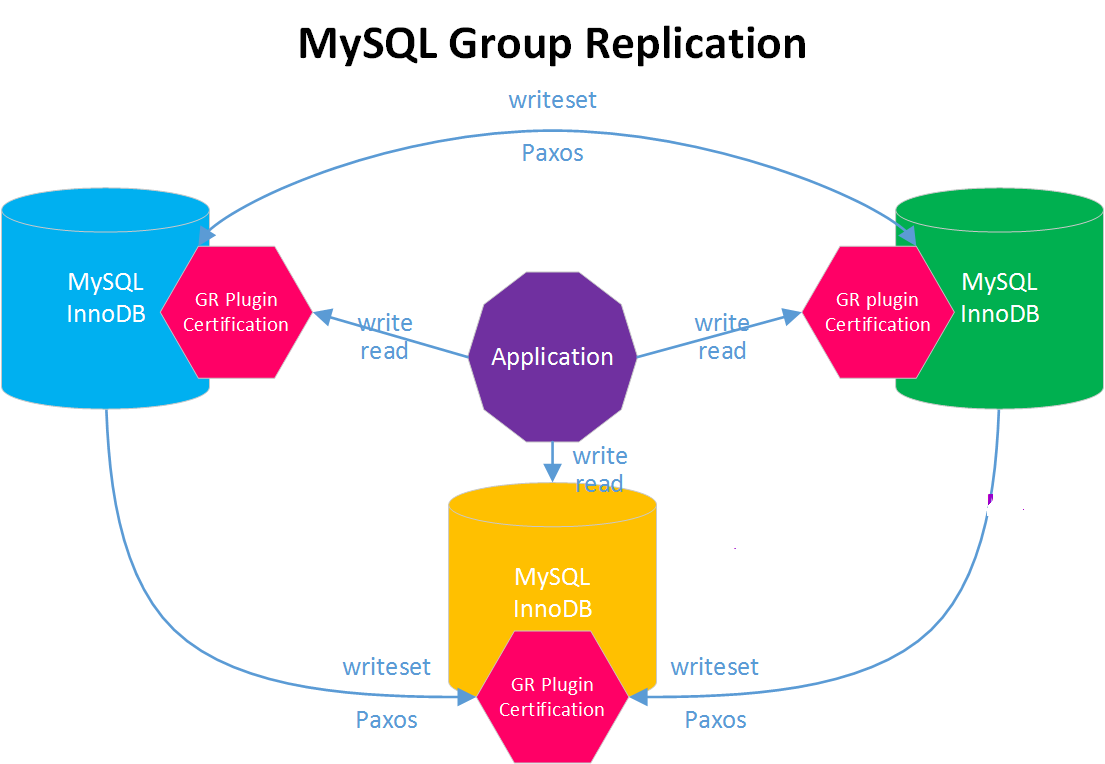
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。这个算法被认为是同类算法中最有效的。Paxos与MySQL相结合可以实现在分布式的MySQL数据的强一致性。
优点:
- 高一致性:基于分布式paxos协议实现组复制,保证数据一致性;
- 高容错性:自动检测机制,只要不是大多数节点都宕机就可以继续工作,内置防脑裂保护机制;
- 高扩展性:节点的增加与移除会自动更新组成员信息,新节点加入后,自动从其他节点同步增量数据,直到与其他节点数据一致;
- 高灵活性:提供单主模式和多主模式,单主模式在主库宕机后能够自动选主,所有写入都在主节点进行,多主模式支持多节点写入。
缺点:
- 只支持innodb储存引擎
- 至少三节点;
总结
随着人们对数据一致性的要求不断的提高,越来越多的方法被尝试用来解决分布式数据一致性的问题,如MySQL自身的优化、MySQL集群架构的优化、Paxos、Raft、2PC算法的引入等等。
而使用分布式算法用来解决MySQL数据库数据一致性的问题的方法,也越来越被人们所接受,一系列成熟的产品如PhxSQL、MariaDB Galera Cluster、Percona XtraDB Cluster等越来越多的被大规模使用。
随着官方MySQL Group Replication的GA,使用分布式协议来解决数据一致性问题已经成为了主流的方向。期望越来越多优秀的解决方案被提出,MySQL高可用问题可以被更好的解决。
MySQL高可用-MHA
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
一、理论介绍
MHA 里有两个角色一个是MHA Node(数据节点)另一个是 MHA Manager(管理节点)。MHA Manager 可以单独部署在一台独立的机器上管理多个 master-slave 集群,也可以部署在一台 slave 节点上。MHA Node 运行在每台 MySQL 服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在 MHA 自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过SSH访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL的半同步复制,可以大大降低数据丢失的风险。MHA 可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA 可以将最新的二进制日志应用于其他所有的slave 服务器上,因此可以保证所有节点的数据一致性。
半同步复制
如何理解半同步呢?首先我们来看看异步,全同步的概念:
异步复制(Asynchronous replication)
MySQL 默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主库如果 crash 掉了,此时主库上已经提交的事务可能并没有传到从库上,如果此时,强行将从库提升为主库,可能导致新主库上的数据不完整。
全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
半同步复制(Semisynchronous replication)
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到 relay log 中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
默认情况下,rpl_semi_sync_master_wait_point的值为after_sync,主库会一直等待,直到至少有一个从库接收到写入的数据。这意味着主库将事务同步到二进制日志,再由从库读取使用。之后,从库向主库发送确认消息,然后主库提交事务并将结果返回给客户端。所以,写入操作能到达中继日志就足够了,从库不需要提交这个事务。
可以将变量rpl_semi_sync_master_wait_point更改为AFTER_COMMIT,在这种情况下,主库将事务提交给存储引擎,但不会将结果返回给客户端。一旦事务在从库上提交,主库就会收到对事务的确认消息,然后将结果返回给客户端。
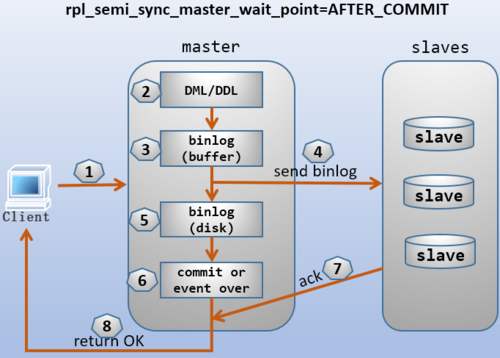
总结:异步与半同步异同
默认情况下 MySQL 的复制是异步的,Master 上所有的更新操作写入Binlog之后并不确保所有的更新都被复制到 Slave 之上。异步操作虽然效率高,但是在 Master/Slave 出现问题的时候,存在很高数据不同步的风险,甚至可能丢失数据。
MySQL引入半同步复制功能的目的是为了保证在 master 出问题的时候,至少有一台Slave的数据是完整的。在超时的情况下也可以临时转入异步复制,保障业务的正常使用,直到一台 salve 追赶上之后,继续切换到半同步模式。
MHA工作原理
相较于其它 HA 软件,MHA 的目的在于维持 MySQL Replication 中 Master 库的高可用性,其最大特点是可以修复多个 Slave 之间的差异日志,最终使所有 Slave 保持数据一致,然后从中选择一个充当新的 Master,并将其它 Slave 指向它。
- 从宕机崩溃的 master 保存二进制日志事件(binlog events)
- 识别含有最新更新的 slave
- 应用差异的中继日志(relay log)到其它 slave
- 应用从 master 保存的二进制日志事件(binlog events)
- 提升一个 slave 为新 master
- 使其它的 slave 连接新的 master 进行复制
目前 MHA 主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当 master,一台充当备用master,另外一台充当从库,因此至少需要三台服务器。
二、MHA部署
案例环境如下:
| 角色 | IP地址 | 主机名 | server_id | 类型 | 操作系统 |
|---|---|---|---|---|---|
| manager | 192.168.154.100 | manager | 管理节点 | CentOS7.7 | |
| master | 192.168.154.101 | master01 | 101 | 主库(写入) | CentOS7.7 |
| candicate master | 192.168.154.102 | slave01 | 102 | 从库(读) | CentOS7.7 |
| slave | 192.168.154.103 | slave02 | 103 | 从库(读) | CentOS7.7 |
其中 master 对外提供写服务,备选master(实际的slave01)提供读服务,slave也提供相关的读服务,一旦 master 宕机,将会把备选 master 提升为新的 master,slave 指向新的 master,manager 作为管理服务器。
2.1 基础环境准备
2.1.1 配置静态IP地址和主机名
2.1.2 关闭SELinux
2.1.3 配置epel源(这里配置的是阿里镜像源)
#安装阿里镜像源wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repowget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.reposed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
2.1.4 配置主机名解析
更改各主机节点的/etc/hosts文件
[root@manager ~]# vim /etc/hosts192.168.154.100 manager192.168.154.101 master01192.168.154.102 slave01192.168.154.103 slave02
2.1.5 设置时间同步
安装chrony服务,各主机均安装
[root@manager ~]# yum install chrony -y[root@manager ~]# systemctl enable chronyd.service[root@manager ~]# systemctl start chronyd.service
配置manager节点为时间服务器
manager同步互联网时间
[root@manager ~]# vim /etc/chrony.confallow 192.168.154.0/16 #配置允许同步的网段[root@manager ~]# systemctl restart chronyd.service#检查时间是否同步成功[root@manager ~]# chronyc sources210 Number of sources = 4MS Name/IP address Stratum Poll Reach LastRx Last sample===============================================================================^+ 119.28.206.193 2 7 377 79 +78us[ +46us] +/- 46ms^- de-user.deepinid.deepin.> 3 7 357 80 +2655us[+2622us] +/- 107ms^? ntp.wdc1.us.leaseweb.net 0 9 0 - +0ns[ +0ns] +/- 0ns^* 120.25.115.20 2 7 377 78 -240us[ -271us] +/- 24ms# 在防火墙放行NTP协议[root@manager ~]# firewall-cmd --add-service=ntp --permanent[root@manager ~]# firewall-cmd --add-service=ntp
配置其它主机节点的时间服务器为manager
mysql各节点同步manager时间
#以master01节点为例,注释掉默认时间服务器,配置manager为时间同步源[root@master01 ~]# vim /etc/chrony.confserver manager iburst[root@master01 ~]# systemctl restart chronyd.service#查看同步manager时间成功[root@master01 ~]# chronyc sources210 Number of sources = 1MS Name/IP address Stratum Poll Reach LastRx Last sample===============================================================================^* manager 2 6 377 16 +1098us[ +560us] +/- 102ms
2.1.6 建立SSH免秘钥登录环境
在各主机先生成秘钥
[root@manager ~]# ssh-keygenGenerating public/private rsa key pair.Enter file in which to save the key (/root/.ssh/id_rsa):Enter passphrase (empty for no passphrase):Enter same passphrase again:Your identification has been saved in /root/.ssh/id_rsa.Your public key has been saved in /root/.ssh/id_rsa.pub.The key fingerprint is:SHA256:vmviM2SHfJYrCF1DpEYC6M31ql6nASGRK5XEPm0deiM root@managerThe key's randomart image is:+---[RSA 2048]----+|o=+.... ||..=o oo ||.++o++.. ||.o++E *. ||. = =.+S. || . o.=.= || ..* =.. || .o O o. || .. o.*o. |+----[SHA256]-----+
在各主机运行以下脚本,拷贝公钥
[root@manager ~]# cat ssh-copy.sh#!/usr/bin/bashfor i in 100 101 102 103dossh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.154.$idone
验证可以互相成功SSH免秘钥登录
#检查脚本[root@manager ~]# cat check-ssh.sh#!/usr/bin/bashfor i in 100 101 102 103dossh 192.168.154.$i hostnamedone#成功检查[root@manager ~]# ./check-ssh.shmanagermaster01slave01slave02
2.2 配置MySQL半同步复制
为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置 MHA 的同时建议配置成MySQL 的半同步复制。 注:mysql 半同步插件是由谷歌提供,一个是 master用的semisync_master.so,一个是 slave 用的 semisync_slave.so,如果不清楚 Plugin的目录,用如下查找:
mysql> show variables like '%plugin_dir%';+---------------+--------------------------+| Variable_name | Value |+---------------+--------------------------+| plugin_dir | /usr/lib64/mysql/plugin/ |+---------------+--------------------------+1 row in set (0.02 sec)
2.2.1 分别在主从节点上安装相关的插件
在 MySQL 上安装插件需要数据库支持动态载入。
检查是否支持,用如下检测:
mysql> show variables like '%have_dynamic_loading%';+----------------------+-------+| Variable_name | Value |+----------------------+-------+| have_dynamic_loading | YES |+----------------------+-------+1 row in set (0.01 sec)
所有MySQL数据库服务器,安装半同步插件(semisync_master.so,semisync_slave.so)
# 安装插件mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';Query OK, 0 rows affected (0.02 sec)mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';Query OK, 0 rows affected (0.01 sec)#确认插件已激活mysql> select plugin_name, plugin_status from information_schema.plugins-> where plugin_name like '%semi%';+----------------------+---------------+| plugin_name | plugin_status |+----------------------+---------------+| rpl_semi_sync_master | ACTIVE || rpl_semi_sync_slave | ACTIVE |+----------------------+---------------+2 rows in set (0.00 sec)
查看半同步信息,应该是关闭OFF状态
mysql> show variables like '%semi_sync%';+-------------------------------------------+------------+| Variable_name | Value |+-------------------------------------------+------------+| rpl_semi_sync_master_enabled | OFF || rpl_semi_sync_master_timeout | 10000 || rpl_semi_sync_master_trace_level | 32 || rpl_semi_sync_master_wait_for_slave_count | 1 || rpl_semi_sync_master_wait_no_slave | ON || rpl_semi_sync_master_wait_point | AFTER_SYNC || rpl_semi_sync_slave_enabled | OFF || rpl_semi_sync_slave_trace_level | 32 |+-------------------------------------------+------------+8 rows in set (0.00 sec)
2.2.2 配置主从同步
注:若主MySQL服务器已经存在,只是后期才搭建从MySQL服务器,在置配数据同步前应先将主MySQL服务器的要同步的数据库拷贝到从MySQL服务器上(如先在主MySQL上备份数据库,再用备份在从MySQL服务器上恢复)。
首先,防火墙放行MySQL服务
[root@master01 ~]# firewall-cmd --add-service=mysql --permanent[root@master01 ~]# firewall-cmd --add-service=mysql
master01配置
修改主库配置文件
[root@master01 ~]# vim /etc/my.cnfserver_id=101log_bin=/var/lib/mysql/binlogs/master01log_bin_index=/var/lib/mysql/binlogs/master01.indexbinlog-ignore-db=mysqlgtid_mode=ONenforce_gtid_consistency=truerpl_semi_sync_master_enabled=1 #启用半同步:1启用,0关闭rpl_semi_sync_master_timeout=1000 # 毫秒单位,该参数主服务器等待确认消息1秒后,不再等待,变为异步方式。rpl_semi_sync_slave_enabled=1relay_log_purge=0
创建复制用户和管理用户
#创建复制用户mharep并授权mysql> create user 'mharep'@'192.168.154.%' identified-> with mysql_native_password by 'Com.123456';Query OK, 0 rows affected (0.00 sec)mysql> grant replication slave on *.* to 'mharep'@'192.168.154.%';Query OK, 0 rows affected (0.00 sec)#创建管理用户manager并授权mysql> create user 'manager'@'192.168.154.%' identified-> with mysql_native_password by 'Com.123456';Query OK, 0 rows affected (0.00 sec)mysql> grant all privileges on *.* to 'manager'@'192.168.154.%';Query OK, 0 rows affected (0.00 sec)
slave01配置(candicate master)
修改slave01主配置文件
[root@slave01 ~]# vim /etc/my.cnfserver_id=102log_bin=/var/lib/mysql/binlogs/slave01log_bin_index=/var/lib/mysql/binlogs/slave01.indexbinlog-ignore-db=mysqlgtid_mode=ONenforce_gtid_consistency=trueskip_slave_startrpl_semi_sync_master_enabled=1rpl_semi_sync_master_timeout=1000rpl_semi_sync_slave_enabled=1relay_log_purge=0#禁止SQL线程在执行完一个relay log后自动将其删除,对于MHA场景下,对于某些滞后从库的恢复#依赖于其他从库的relay log,因此采取禁用自动删除功能
创建复制用户和管理用户
mysql> create user 'mharep'@'192.168.154.%' identified-> with mysql_native_password by 'Com.123456';Query OK, 0 rows affected (1.01 sec)mysql> grant replication slave on *.* to 'mharep'@'192.168.154.%';Query OK, 0 rows affected (0.00 sec)mysql> create user 'manager'@'192.168.154.%' identified-> with mysql_native_password by 'Com.123456';Query OK, 0 rows affected (0.00 sec)mysql> grant all privileges on *.* to 'manager'@'192.168.154.%';Query OK, 0 rows affected (0.01 sec)
slave02配置
修改slave02主配置文件
[root@slave02 ~]# vim /etc/my.cnfserver_id=103log_bin=/var/lib/mysql/binlogs/slave02log_bin_index=/var/lib/mysql/binlogs/slave02.indexbinlog-ignore-db=mysqlgtid_mode=ONenforce_gtid_consistency=trueskip_slave_startrpl_semi_sync_slave_enabled=1read_only=1
创建管理用户
mysql> create user 'manager'@'192.168.154.%' identified-> with mysql_native_password by 'Com.123456';Query OK, 0 rows affected (0.01 sec)mysql> grant all privileges on *.* to 'manager'@'192.168.154.%';Query OK, 0 rows affected (0.00 sec)
启动同步
slave01上启动
mysql> change master to master_host='192.168.154.101',-> master_port=3306,master_user='mharep',-> master_password='Com.123456', master_auto_position = 1;Query OK, 0 rows affected, 2 warnings (0.01 sec)mysql> start slave;Query OK, 0 rows affected (0.00 sec)mysql> show slave status\G*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 192.168.154.101Master_User: mharepMaster_Port: 3306Connect_Retry: 60Master_Log_File: master01.000007Read_Master_Log_Pos: 527Relay_Log_File: slave01-relay-bin.000002Relay_Log_Pos: 739Relay_Master_Log_File: master01.000007Slave_IO_Running: YesSlave_SQL_Running: YesReplicate_Do_DB:Replicate_Ignore_DB:Replicate_Do_Table:Replicate_Ignore_Table:Replicate_Wild_Do_Table:Replicate_Wild_Ignore_Table:Last_Errno: 0Last_Error:Skip_Counter: 0Exec_Master_Log_Pos: 527Relay_Log_Space: 949Until_Condition: NoneUntil_Log_File:Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File:Master_SSL_CA_Path:Master_SSL_Cert:Master_SSL_Cipher:Master_SSL_Key:Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error:Last_SQL_Errno: 0Last_SQL_Error:Replicate_Ignore_Server_Ids:Master_Server_Id: 101Master_UUID: 6ccb9814-2efb-11ea-81a9-000c292bfa3eMaster_Info_File: mysql.slave_master_infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Slave has read all relay log; waiting for more updatesMaster_Retry_Count: 86400Master_Bind:Last_IO_Error_Timestamp:Last_SQL_Error_Timestamp:Master_SSL_Crl:Master_SSL_Crlpath:Retrieved_Gtid_Set: 6ccb9814-2efb-11ea-81a9-000c292bfa3e:1-2Executed_Gtid_Set: 609a58c5-27c8-11ea-96c1-000c29d09df1:1-4,6ccb9814-2efb-11ea-81a9-000c292bfa3e:1-2Auto_Position: 1Replicate_Rewrite_DB:Channel_Name:Master_TLS_Version:Master_public_key_path:Get_master_public_key: 0Network_Namespace:1 row in set (0.00 sec)
slave02上启动同步
mysql> change master to master_host='192.168.154.101',-> master_port=3306,master_user='mharep',-> master_password='Com.123456', master_auto_position = 1;Query OK, 0 rows affected, 2 warnings (0.03 sec)mysql> start slave;Query OK, 0 rows affected (0.00 sec)mysql> show slave status \G #要确保正常同步
master01上操作数据,进行状态查看
mysql> create database cisco;Query OK, 1 row affected (0.01 sec)mysql> show status like '%semi_sync%';+--------------------------------------------+-------+| Variable_name | Value |+--------------------------------------------+-------+| Rpl_semi_sync_master_clients | 2 || Rpl_semi_sync_master_net_avg_wait_time | 0 || Rpl_semi_sync_master_net_wait_time | 0 || Rpl_semi_sync_master_net_waits | 3 || Rpl_semi_sync_master_no_times | 1 || Rpl_semi_sync_master_no_tx | 2 || Rpl_semi_sync_master_status | ON || Rpl_semi_sync_master_timefunc_failures | 0 || Rpl_semi_sync_master_tx_avg_wait_time | 710 || Rpl_semi_sync_master_tx_wait_time | 710 || Rpl_semi_sync_master_tx_waits | 1 || Rpl_semi_sync_master_wait_pos_backtraverse | 0 || Rpl_semi_sync_master_wait_sessions | 0 || Rpl_semi_sync_master_yes_tx | 1 || Rpl_semi_sync_slave_status | OFF |+--------------------------------------------+-------+15 rows in set (0.00 sec)#Rpl_semi_sync_master_status :显示主服务是异步复制模式还是半同步复制模式#Rpl_semi_sync_master_clients :显示有多少个从服务器配置为半同步复制模式#Rpl_semi_sync_master_yes_tx :显示从服务器确认成功提交的数量#Rpl_semi_sync_master_no_tx :显示从服务器确认不成功提交的数量#Rpl_semi_sync_master_tx_avg_wait_time :事务因开启semi_sync ,平均需要额外等待的时间#Rpl_semi_sync_master_net_avg_wait_time :事务进入等待队列后,到网络平均等待时间
2.3 配置MySQL-MHA
MHA两种角色介绍:
MHA manager:管理节点
通常单独部署在一台独立的服务器上,用来管理多个master/slave集群,也可部署在一台slave节点上,每个master/slave集群称为一个application。
MHA Manager会定时探测集群中的master节点,当发现master节点出现故障时,它可以自动将具有最新数据的slave节点提升为新的master节点,然后将所有其它的slave节点重新指向新的master节点。整个故障转移过程对应用程序完全透明,完成故障转移(即主从切换)后,MHA manager会自动停止。
#Manager工具包主要包括以下几个工具:masterha_manger 启动MHAmasterha_check_ssh 检查MHA的SSH配置状况masterha_check_repl 检查MySQL复制状况masterha_master_monitor 检测master是否宕机masterha_check_status 检测当前MHA运行状态masterha_master_switch 控制故障转移(自动或者手动)masterha_conf_host 添加或删除配置的server信息
MHA node:数据节点
运行在每台MySQL服务器上(manager/master/slave),它通过监控具备解析和清理logs功能的脚本来加快故障转移。
#Node工具:这些工具通常由MHA Manager的脚本触发,无需人为操作save_binary_logs 保存和复制master的二进制日志apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的purge_relay_logs 清除中继日志(不会阻塞SQL线程)
2.3.1 下载安装程序
软件包地址:https://github.com/yoshinorim/
wget -c https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpmwget -c https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
2.3.2 安装MHA程序
安装MySQL server节点
[root@master01 ~]# yum localinstall mha4mysql-node-0.58-0.el7.centos.noarch.rpm#作为依赖,要安装的包如下:perl-Compress-Raw-Bzip2.x86_64 0:2.061-3.el7perl-Compress-Raw-Zlib.x86_64 1:2.061-4.el7perl-DBD-MySQL.x86_64 0:4.023-6.el7perl-DBI.x86_64 0:1.627-4.el7perl-IO-Compress.noarch 0:2.061-2.el7perl-Net-Daemon.noarch 0:0.48-5.el7perl-PlRPC.noarch 0:0.2020-14.el7
安装管理manager节点
[root@manager ~]# yum localinstall mha4mysql-node-0.58-0.el7.centos.noarch.rpm[root@manager ~]# yum localinstall mha4mysql-manager-0.58-0.el7.centos.noarch.rpm#作为依赖被安装:perl-Class-Load.noarch 0:0.20-3.el7 perl-Config-Tiny.noarch 0:2.14-7.el7perl-Data-OptList.noarch 0:0.107-9.el7 perl-Email-Date-Format.noarch 0:1.002-15.el7perl-IO-Socket-IP.noarch 0:0.21-5.el7 perl-IO-Socket-SSL.noarch 0:1.94-7.el7perl-List-MoreUtils.x86_64 0:0.33-9.el7 perl-Log-Dispatch.noarch 0:2.41-1.el7.1perl-MIME-Lite.noarch 0:3.030-1.el7 perl-MIME-Types.noarch 0:1.38-2.el7perl-Mail-Sender.noarch 0:0.8.23-1.el7 perl-Mail-Sendmail.noarch 0:0.79-21.el7perl-MailTools.noarch 0:2.12-2.el7 perl-Module-Implementation.noarch 0:0.06-6.el7perl-Module-Runtime.noarch 0:0.013-4.el7 perl-Mozilla-CA.noarch 0:20130114-5.el7perl-Net-LibIDN.x86_64 0:0.12-15.el7 perl-Net-SMTP-SSL.noarch 0:1.01-13.el7perl-Net-SSLeay.x86_64 0:1.55-6.el7 perl-Package-DeprecationManager.noarch 0:0.13-7.el7perl-Package-Stash.noarch 0:0.34-2.el7 perl-Package-Stash-XS.x86_64 0:0.26-3.el7perl-Parallel-ForkManager.noarch 0:1.18-2.el7 perl-Params-Util.x86_64 0:1.07-6.el7perl-Params-Validate.x86_64 0:1.08-4.el7 perl-Sub-Install.noarch 0:0.926-6.el7perl-Sys-Syslog.x86_64 0:0.33-3.el7 perl-TimeDate.noarch 1:2.30-2.el7perl-Try-Tiny.noarch 0:0.12-2.el7
2.3.3 配置MHA
与绝大多数 Linux 应用程序类似,MHA的正确使用依赖于合理的配置文件。MHA 的配置文件与MySQL的my.cnf文件配置相似,采取的是param=value的方式来配置,配置文件位于管理节点,通常包括每一个MySQL Server 的主机名,MySQL用户名,密码,工作目录等等。编辑/etc/masterha/app1.conf,内容如下:
#创建配置文件目录[root@manager ~]# mkdir -p /etc/mha#创建日志目录[root@manager ~]# mkdir -p /var/log/mha/app1[root@manager ~]# vim /etc/mha/app1.cnf[server default]manager_workdir=/masterha/app1manager_log=/masterha/app1/manager.loguser=managerpassword=Com.123456ssh_user=rootrepl_user=mhareprepl_password=Com.123456ping_interval=2[server1]hostname=192.168.154.101port=3306master_binlog_dir=/var/lib/mysql/binlogscandidate_master=1[server2]hostname=192.168.154.102port=3306master_binlog_dir=/var/lib/mysql/binlogscandidate_master=1[server3]hostname=192.168.154.103port=3306master_binlog_dir=/var/lib/mysql/binlogsno_master=1
配置项说明:
- manager_workdir=/masterha/app1 //设置 manager 的工作目录
- manager_log=/masterha/app1/manager.log //设置 manager 的日志
- user=manager //设置管理用户 manager
- password=123456 //管理用户 manager 的密码
- ssh_user=root //ssh 连接用户
- repl_user=mharep //主从复制用户
- repl_password=123.abc //主从复制用户密码
- ping_interval=2 //设置监控主库,发送 ping 包的时间间隔,默认是 3 秒,尝试三次没有回应的时候自动进行 railover
- master_binlog_dir=/usr/local/mysql/data //设置 master 保存 binlog 的位置,以便 MHA 可以找到 master 的日志。
- candidate_master=1 //设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库。
2.3.4 验证SSH互相免秘钥登录
[root@manager ~]# masterha_check_ssh --conf=/etc/mha/app1.cnfSun Jan 5 19:07:54 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.Sun Jan 5 19:07:54 2020 - [info] Reading application default configuration from /etc/mha/app1.cnf..Sun Jan 5 19:07:54 2020 - [info] Reading server configuration from /etc/mha/app1.cnf..Sun Jan 5 19:07:54 2020 - [info] Starting SSH connection tests..Sun Jan 5 19:07:56 2020 - [debug]Sun Jan 5 19:07:54 2020 - [debug] Connecting via SSH from root@192.168.154.101(192.168.154.101:22) to root@192.168.154.102(192.168.154.102:22)..Sun Jan 5 19:07:55 2020 - [debug] ok.Sun Jan 5 19:07:55 2020 - [debug] Connecting via SSH from root@192.168.154.101(192.168.154.101:22) to root@192.168.154.103(192.168.154.103:22)..Sun Jan 5 19:07:56 2020 - [debug] ok.Sun Jan 5 19:07:57 2020 - [debug]Sun Jan 5 19:07:56 2020 - [debug] Connecting via SSH from root@192.168.154.103(192.168.154.103:22) to root@192.168.154.101(192.168.154.101:22)..Sun Jan 5 19:07:56 2020 - [debug] ok.Sun Jan 5 19:07:56 2020 - [debug] Connecting via SSH from root@192.168.154.103(192.168.154.103:22) to root@192.168.154.102(192.168.154.102:22)..Sun Jan 5 19:07:57 2020 - [debug] ok.Sun Jan 5 19:07:57 2020 - [debug]Sun Jan 5 19:07:55 2020 - [debug] Connecting via SSH from root@192.168.154.102(192.168.154.102:22) to root@192.168.154.101(192.168.154.101:22)..Sun Jan 5 19:07:56 2020 - [debug] ok.Sun Jan 5 19:07:56 2020 - [debug] Connecting via SSH from root@192.168.154.102(192.168.154.102:22) to root@192.168.154.103(192.168.154.103:22)..Sun Jan 5 19:07:56 2020 - [debug] ok.Sun Jan 5 19:07:57 2020 - [info] All SSH connection tests passed successfully.
2.3.5 集群复制的有效性验证:(MySQL必须都启动)
[root@manager ~]# masterha_check_repl --conf=/etc/mha/app1.cnfSun Jan 5 19:20:52 2020 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.Sun Jan 5 19:20:52 2020 - [info] Reading application default configuration from /etc/mha/app1.cnf..Sun Jan 5 19:20:52 2020 - [info] Reading server configuration from /etc/mha/app1.cnf..Sun Jan 5 19:20:52 2020 - [info] MHA::MasterMonitor version 0.58.Sun Jan 5 19:20:53 2020 - [info] GTID failover mode = 1Sun Jan 5 19:20:53 2020 - [info] Dead Servers:Sun Jan 5 19:20:53 2020 - [info] Alive Servers:Sun Jan 5 19:20:53 2020 - [info] 192.168.154.101(192.168.154.101:3306)Sun Jan 5 19:20:53 2020 - [info] 192.168.154.102(192.168.154.102:3306)Sun Jan 5 19:20:53 2020 - [info] 192.168.154.103(192.168.154.103:3306)Sun Jan 5 19:20:53 2020 - [info] Alive Slaves:Sun Jan 5 19:20:53 2020 - [info] 192.168.154.102(192.168.154.102:3306) Version=8.0.18 (oldest major version between slaves) log-bin:enabledSun Jan 5 19:20:53 2020 - [info] GTID ONSun Jan 5 19:20:53 2020 - [info] Replicating from 192.168.154.101(192.168.154.101:3306)Sun Jan 5 19:20:53 2020 - [info] Primary candidate for the new Master (candidate_master is set)Sun Jan 5 19:20:53 2020 - [info] 192.168.154.103(192.168.154.103:3306) Version=8.0.18 (oldest major version between slaves) log-bin:enabledSun Jan 5 19:20:53 2020 - [info] GTID ONSun Jan 5 19:20:53 2020 - [info] Replicating from 192.168.154.101(192.168.154.101:3306)Sun Jan 5 19:20:53 2020 - [info] Not candidate for the new Master (no_master is set)Sun Jan 5 19:20:53 2020 - [info] Current Alive Master: 192.168.154.101(192.168.154.101:3306)Sun Jan 5 19:20:53 2020 - [info] Checking slave configurations..Sun Jan 5 19:20:53 2020 - [info] read_only=1 is not set on slave 192.168.154.102(192.168.154.102:3306).Sun Jan 5 19:20:53 2020 - [info] Checking replication filtering settings..Sun Jan 5 19:20:53 2020 - [info] binlog_do_db= , binlog_ignore_db=Sun Jan 5 19:20:53 2020 - [info] Replication filtering check ok.Sun Jan 5 19:20:53 2020 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.Sun Jan 5 19:20:53 2020 - [info] Checking SSH publickey authentication settings on the current master..Sun Jan 5 19:20:53 2020 - [info] HealthCheck: SSH to 192.168.154.101 is reachable.Sun Jan 5 19:20:53 2020 - [info]192.168.154.101(192.168.154.101:3306) (current master)+--192.168.154.102(192.168.154.102:3306)+--192.168.154.103(192.168.154.103:3306)Sun Jan 5 19:20:53 2020 - [info] Checking replication health on 192.168.154.102..Sun Jan 5 19:20:53 2020 - [info] ok.Sun Jan 5 19:20:53 2020 - [info] Checking replication health on 192.168.154.103..Sun Jan 5 19:20:53 2020 - [info] ok.Sun Jan 5 19:20:53 2020 - [warning] master_ip_failover_script is not defined.Sun Jan 5 19:20:53 2020 - [warning] shutdown_script is not defined.Sun Jan 5 19:20:53 2020 - [info] Got exit code 0 (Not master dead).MySQL Replication Health is OK.
2.3.6 开启MHA
[root@manager ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover &> /tmp/mha_manager.log &[1] 1738#检查MHA状态[root@manager ~]# masterha_check_status --conf=/etc/mha/app1.cnfapp1 (pid:1738) is running(0:PING_OK), master:192.168.154.101[root@manager ~]# mysql -umanager -pCom.123456 -h master01 -e 'show variables like "server_id"'mysql: [Warning] Using a password on the command line interface can be insecure.+---------------+-------+| Variable_name | Value |+---------------+-------+| server_id | 101 |+---------------+-------+[root@manager ~]# mysql -umanager -pCom.123456 -h slave01 -e 'show variables like "server_id"'mysql: [Warning] Using a password on the command line interface can be insecure.+---------------+-------+| Variable_name | Value |+---------------+-------+| server_id | 102 |+---------------+-------+[root@manager ~]# mysql -umanager -pCom.123456 -h slave02 -e 'show variables like "server_id"'mysql: [Warning] Using a password on the command line interface can be insecure.+---------------+-------+| Variable_name | Value |+---------------+-------+| server_id | 103 |+---------------+-------+
2.3.7 故障转移验证 (自动 failover)
将当前主库停掉
[root@master01 ~]# systemctl stop mysqld.service
查看MHA日志
[root@manager ~]# cat /masterha/app1/manager.log----- Failover Report -----app1: MySQL Master failover 192.168.154.101(192.168.154.101:3306) to 192.168.154.102(192.168.154.102:3306) succeededMaster 192.168.154.101(192.168.154.101:3306) is down!Check MHA Manager logs at manager:/masterha/app1/manager.log for details.Started automated(non-interactive) failover.Selected 192.168.154.102(192.168.154.102:3306) as a new master.192.168.154.102(192.168.154.102:3306): OK: Applying all logs succeeded.192.168.154.103(192.168.154.103:3306): OK: Slave started, replicating from 192.168.154.102(192.168.154.102:3306)192.168.154.102(192.168.154.102:3306): Resetting slave info succeeded.Master failover to 192.168.154.102(192.168.154.102:3306) completed successfully.
查看slave02上的复制状态
可以看到已经切换到新的主库:192.168.154.102
mysql> show slave status\G*************************** 1. row ***************************Slave_IO_State: Waiting for master to send eventMaster_Host: 192.168.154.102Master_User: mharepMaster_Port: 3306Connect_Retry: 60Master_Log_File: slave01.000012Read_Master_Log_Pos: 523Relay_Log_File: slave02-relay-bin.000002Relay_Log_Pos: 653Relay_Master_Log_File: slave01.000012Slave_IO_Running: YesSlave_SQL_Running: YesReplicate_Do_DB:Replicate_Ignore_DB:Replicate_Do_Table:Replicate_Ignore_Table:Replicate_Wild_Do_Table:Replicate_Wild_Ignore_Table:Last_Errno: 0Last_Error:Skip_Counter: 0Exec_Master_Log_Pos: 523Relay_Log_Space: 863Until_Condition: NoneUntil_Log_File:Until_Log_Pos: 0Master_SSL_Allowed: NoMaster_SSL_CA_File:Master_SSL_CA_Path:Master_SSL_Cert:Master_SSL_Cipher:Master_SSL_Key:Seconds_Behind_Master: 0Master_SSL_Verify_Server_Cert: NoLast_IO_Errno: 0Last_IO_Error:Last_SQL_Errno: 0Last_SQL_Error:Replicate_Ignore_Server_Ids:Master_Server_Id: 102Master_UUID: b77923f7-2efa-11ea-93c2-000c29ede891Master_Info_File: mysql.slave_master_infoSQL_Delay: 0SQL_Remaining_Delay: NULLSlave_SQL_Running_State: Slave has read all relay log; waiting for more updatesMaster_Retry_Count: 86400Master_Bind:Last_IO_Error_Timestamp:Last_SQL_Error_Timestamp:Master_SSL_Crl:Master_SSL_Crlpath:Retrieved_Gtid_Set: b77923f7-2efa-11ea-93c2-000c29ede891:1Executed_Gtid_Set: 609a58c5-27c8-11ea-96c1-000c29d09df1:1-4,6ccb9814-2efb-11ea-81a9-000c292bfa3e:1-8,b77923f7-2efa-11ea-93c2-000c29ede891:1Auto_Position: 1Replicate_Rewrite_DB:Channel_Name:Master_TLS_Version:Master_public_key_path:Get_master_public_key: 0Network_Namespace:1 row in set (0.00 sec)
2.3.8 修复主库
发生主从切换后,MHAmanager 服务会自动停掉,且在 manager_workdir(/masterha/app1)
目录下面生成文件 app1.failover.complete,若要启动 MHA,必须先确保无此文件;
现在新主库切换到Candicate master上,需要把原主库修复成一个新的从库。
查看MHA日志文件
[root@manager ~]# grep "CHANGE MASTER TO MASTER" /masterha/app1/manager.logSun Jan 5 20:48:44 2020 - [info] All other slaves should start replication from here. Statement should be:CHANGE MASTER TO MASTER_HOST='192.168.154.102', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='mharep', MASTER_PASSWORD='xxx';
在原主库master01上配置主从复制
mysql> change master to master_host='192.168.154.102',-> master_port=3306,master_user='mharep',-> master_password='Com.123456',master_auto_position=1;Query OK, 0 rows affected, 2 warnings (0.02 sec)mysql> start slave;Query OK, 0 rows affected (0.00 sec)
修改MHA配置文件
[root@manager app1]# vim /etc/mha/app1.cnf#添加如下信息,故障后,此部分内容被删除[server1]candidate_master=1hostname=192.168.154.101master_binlog_dir=/var/lib/mysql/binlogsport=3306
重新启动MHA
[root@manager ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover &> /tmp/mha_manager.log &[1] 2579[root@manager ~]# masterha_check_status --conf=/etc/mha/app1.cnfapp1 (pid:2579) is running(0:PING_OK), master:192.168.154.102
2.3.9 定期删除中继日志
在配置主从复制中,slave 上设置了参数 relay_log_purge=0,所以 slave 节点需要定期删除中继日志,建议每个slave节点删除中继日志的时间错开。
制定cron计划任务即可,如每天清理一次。
crontab -e00 2 * * * purge_relay_logs --user=root --password=Com.123456 --port=3306 --disable_relay_log_purge >> /var/log/purge_relay.log 2>&1
2.3.10 配置VIP
vip 配置可以采用两种方式,一种通过 keepalived 的方式管理虚拟 ip 的浮动;另外一种通过脚本方式启动虚拟 ip 的方式(即不需要 keepalived 或者 heartbeat 类似的软件)。
为了防止脑裂发生,推荐生产环境采用脚本的方式来管理虚拟ip,而不是使用 keepalived 来完成。
在manager主机上编写脚本
样例脚本的位置:https://github.com/yoshinorim/mha4mysql-manager/tree/master/samples/scripts
[root@manager ~]# cd /usr/local/bin/[root@manager bin]# vim master_ip_failover#!/usr/bin/env perluse strict;use warnings FATAL => 'all';use Getopt::Long;my ($command, $ssh_user, $orig_master_host, $orig_master_ip,$orig_master_port, $new_master_host, $new_master_ip, $new_master_port);my $vip = '192.168.154.110/24';my $key = '1';my $ssh_start_vip = "/sbin/ifconfig ens32:$key $vip";my $ssh_stop_vip = "/sbin/ifconfig ens32:$key down";GetOptions('command=s' => \$command,'ssh_user=s' => \$ssh_user,'orig_master_host=s' => \$orig_master_host,'orig_master_ip=s' => \$orig_master_ip,'orig_master_port=i' => \$orig_master_port,'new_master_host=s' => \$new_master_host,'new_master_ip=s' => \$new_master_ip,'new_master_port=i' => \$new_master_port,);exit &main();sub main {print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";if ( $command eq "stop" || $command eq "stopssh" ) {my $exit_code = 1;eval {print "Disabling the VIP on old master: $orig_master_host \n";&stop_vip();$exit_code = 0;};if ($@) {warn "Got Error: $@\n";exit $exit_code;}exit $exit_code;}elsif ( $command eq "start" ) {my $exit_code = 10;eval {print "Enabling the VIP - $vip on the new master - $new_master_host \n";&start_vip();$exit_code = 0;};if ($@) {warn $@;exit $exit_code;}exit $exit_code;}elsif ( $command eq "status" ) {print "Checking the Status of the script.. OK \n";exit 0;}else {&usage();exit 1;}}sub start_vip() {`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;}sub stop_vip() {return 0 unless ($ssh_user);`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;}sub usage {"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";}#赋予可执行权限[root@manager bin]# chmod a+x /usr/local/bin/master_ip_failover#防止中文乱码[root@manager bin]# dos2unix /usr/local/bin/master_ip_failover
更改manager配置文件
[root@manager ~]# vim /etc/mha/app1.cnf#添加master_ip_failover_script=/usr/local/bin/master_ip_failover
主库上,手动生成第一个VIP地址
手工在主库上绑定vip,注意一定要和配置文件中的ensN一致,我的是ens32:1(1是key指定的值)
# 当前主库为salve01[root@slave01 ~]# ifconfig ens32:1 192.168.154.110/24#在manager主机上测试和VIP可以通信[root@manager ~]# ping -c 2 192.168.154.110PING 192.168.154.110 (192.168.154.110) 56(84) bytes of data.64 bytes from 192.168.154.110: icmp_seq=1 ttl=64 time=0.621 ms64 bytes from 192.168.154.110: icmp_seq=2 ttl=64 time=0.481 ms--- 192.168.154.110 ping statistics ---2 packets transmitted, 2 received, 0% packet loss, time 1000msrtt min/avg/max/mdev = 0.481/0.551/0.621/0.070 ms
重启MHA
#停止MHA[root@manager ~]# masterha_stop --conf=/etc/mha/app1.cnfStopped app1 successfully.[1]+ 退出 1 nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover &>/tmp/mha_manager.log#启动MHA[root@manager ~]# nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover &> /tmp/mha_manager.log &[1] 2694#检查MHA状态[root@manager ~]# masterha_check_status --conf=/etc/mha/app1.cnfapp1 (pid:2694) is running(0:PING_OK), master:192.168.154.102
测试VIP是否可以使用
#停止掉主库[root@slave01 ~]# systemctl stop mysqld.service#在新的主库上查看VIP[root@master01 ~]# ip addr show ens322: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:2b:fa:3e brd ff:ff:ff:ff:ff:ffinet 192.168.154.101/24 brd 192.168.154.255 scope global noprefixroute ens32valid_lft forever preferred_lft foreverinet 192.168.154.110/24 brd 192.168.154.255 scope global secondary ens32:1valid_lft forever preferred_lft foreverinet6 fe80::e26b:3325:3719:9cdd/64 scope link tentative noprefixroute dadfailedvalid_lft forever preferred_lft foreverinet6 fe80::6775:697a:8f41:d6a2/64 scope link noprefixroutevalid_lft forever preferred_lft forever
可以看到VIP已经切换到了新主库网卡上。

若有收获,就点个赞吧
0 人点赞
