导论
密集连接网络和卷积神经网络都有一个主要特点,那就是它们都没有记忆。它们单独处理每个输入,在输入与输入之间没有保存任何状态。 对于这样的网络,要想处理数据点的序列或时间序列,你需要向网络同时展示整个序列,即将序列转换成单个数据点。例如,你在 IMDB 示例中就是这么做的:将全部电影评论转换为一个大向量,然后一次性处理。这种网络叫作前馈网络**( feedforward network)**。
与此相反,当你在阅读这个句子时,你是一个词一个词地阅读(或者说,眼睛一次扫视一次扫视地阅读),同时会记住之前的内容。这让你能够动态理解这个句子所传达的含义。生物智能以渐进的方式处理信息,同时保存一个关于所处理内容的内部模型,这个模型是根据过去的信息构建的,并随着新信息的进入而不断更新。
RNN 介绍
循环神经网络**( RNN, recurrent neural network)采用同样的原理,不过是一个极其简化的版本:它处理序列的方式是,遍历所有序列元素,并保存一个状态( state),其中包含与已查看内容相关的信息。** 实际上, RNN是一类具有内部环的神经网络(见下图)。在处理两个不同的独立序列(比如两条不同的 IMDB 评论)之间, RNN 状态会被重置,因此,你仍可以将一个序列看作单个数据点,即网络的单个输入。真正改变的是,数据点不再是在单个步骤中进行处理,相反,网络内部会对序列元素进行遍历。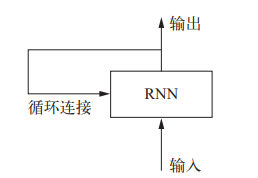
循环神经网络:带有环的网络
RNN 的简单实现
为了将环( loop)和状态的概念解释清楚,我们用 Numpy 来实现一个简单 RNN 的前向传递。 这个 RNN 的输入是一个张量序列,我们将其编码成大小为 (timesteps, inputfeatures)的二维张量。它对时间步( timestep)进行遍历,在每个时间步,它考虑 t 时刻的当前状态与 t时刻的输入[形状为 (input features,)],对二者计算得到 t 时刻的输出。然后,我们将下一个时间步的状态设置为上一个时间步的输出。对于第一个时间步,上一个时间步的输出没有定义,所以它没有当前状态。因此,你需要将状态初始化为一个全零向量,这叫作网络的初始状态( initial state)。
RNN 伪代码实现:
state_t = 0 # t 时刻的状态for input_t in input-sequences: # 对序列元素进行遍历,input_sequences的shape为(timesteps, input_features)output_t = f(input_t, state_t) # f实现从输入和状态到输出的变换state_t = output_t # 前一次的输出变成下一次迭代的状态
你甚至可以给出具体的函数 f:从输入和状态到输出的变换,其参数包括两个矩阵( W 和 U)和一个偏置向量。它类似于前馈网络中密集连接层所做的变换。这个函数我们称之为“时间步函数”。
state_t = 0for input_t in input_sequence:output_t = activation(dot(W, input_t) + dot(U, state_t) + b)state_t = output_t
简单 RNN 的 Numpy 实现
import numpy as nptimesteps = 100 # 输入序列的时间步数input_features = 32 # 输入特征空间的维度output_features = 64 # 输出特征空间的维度inputs = np.random.random((timesteps, input_features)) # 输入数据,随机噪声,仅作为示例state_t = np.zeros((output_features,)) # 初始状态,全零向量# 创建随机的权重矩阵W = np.random.random((output_features, input_features))U = np.random.random((output_features, output_features))b = np.random.random((output_features,))successive_outputs = [] # 用来存储每一步的输出for input_t in inputs: # input_t 是形状为 (input_features,) 的向量output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b) # 由输入和状态计算得到输出successive_outputs.append(output_t) # 将这个输出保存到一个列表中state_t = output_t # 更新网络的状态final_output_sequence = np.stack(successive_outputs, axis=0)
总之, RNN 是一个 for 循环,它重复使用循环前一次迭代的计算结果,仅此而已。
当然,你可以构建许多不同的 RNN,它们都满足上述定义。 RNN 的特征在于其时间步函数,比如前面例子中的这个函数:output_t = np.tanh(np.dot(W, input_t) + np.dot(U, state_t) + b),即 f。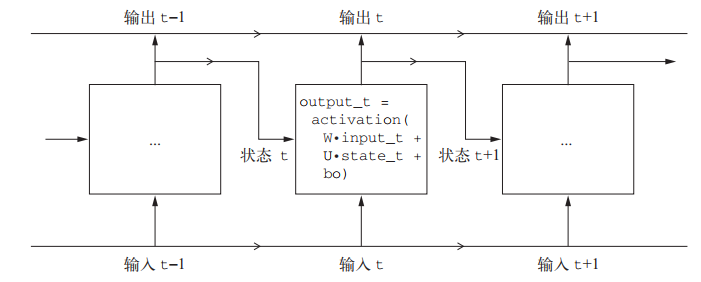
一个简单的 RNN,沿着时间展开
本例中,最终输出是一个形状为 (timesteps, output_features) 的二维张量,其中每个时间步是循环在 t 时刻的输出。输出张量中的每个时间步 t 包含输入序列中时间步 0~t 的信息,即关于全部过去的信息。因此,在多数情况下,你并不需要这个所有输出组成的序列,你只需要最后一个输出(循环结束时的 output_t),因为它已经包含了整个序列的信息。
Keras 中的循环层
上面 Numpy 的简单实现,对应一个实际的 Keras 层,即 SimpleRNN 层: keras.layers.SimpleRNN
二者有一点小小的区别: SimpleRNN 层能够像其他 Keras 层一样处理序列批量,而不是像 Numpy 示例那样只能处理单个序列。因此,它接收形状为 **(batch_size, timesteps, input_features) **的输入,而不是 (timesteps, input_features)。
与 Keras 中的所有循环层一样, SimpleRNN 可以在两种不同的模式下运行:
- 一种是返回每个时间步连续输出的完整序列,即形状为 (batch_size, timesteps, output_features) 的三维张量;
- 另一种是只返回每个输入序列的最终输出,即形状为 (batch_size, output_features) 的二维张量。
这两种模式由 return_sequences 这个构造函数参数来控制。
实战:SimpleRNN 应用于 IMDB 电影评论分类问题
1. 准备数据
from keras.datasets import imdbfrom keras.preprocessing import sequencemax_features = 10000 # 作为特征的单词个数(也就是数据集中只保留词频最高的前 max_features 个单词)maxlen = 500 # 在这么多单词之后截断文本(这些单词都是属于前 max_features 个最常见的单词)batch_size = 32(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features)input_train = sequence.pad_sequences(input_train, maxlen=maxlen)input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
2. 搭建模型(Embedding层 + SimpleRNN 层)
from keras.layers import Dense, Embedding, SimpleRNNfrom keras import Sequentialmodel = Sequential()model.add(Embedding(max_features, 32))model.add(SimpleRNN(32))model.add(Dense(1, activation='sigmoid'))model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
3. 训练模型
history = model.fit(input_train, y_train,epochs=10,batch_size=128,validation_split=0.2)
4. 绘制结果
%matplotlib inlineimport matplotlib.pyplot as pltacc = history.history['acc']val_acc = history.history['val_acc']loss = history.history['loss']val_loss = history.history['val_loss']epochs = list(range(1, len(acc) + 1))plt.plot(epochs, acc, 'bo', label='Training acc')plt.plot(epochs, val_acc, 'b', label='Validation acc')plt.title('Training and validation accuracy')plt.legend()plt.figure()plt.plot(epochs, loss, 'bo', label='Training loss')plt.plot(epochs, val_loss, 'b', label='Validation loss')plt.title('Training and validation loss')plt.legend()plt.show()
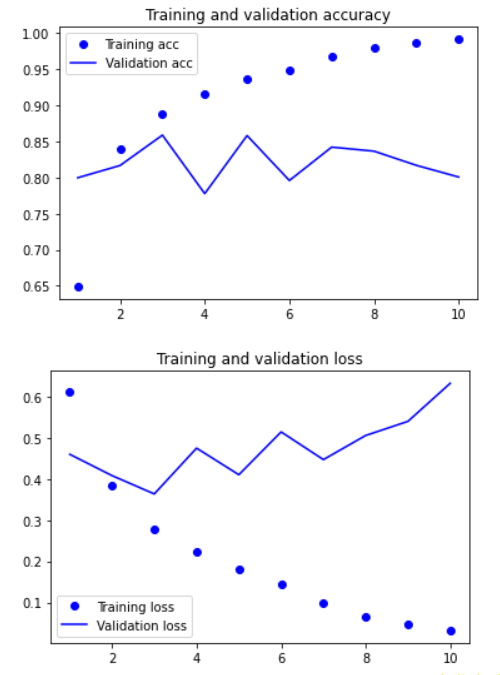
处理这个数据集的第一个简单方法(只通过 Dense 层)得到的测试精度是 88%。不幸的是,与这个基准相比,这个小型循环网络的表现并不好(验证精度只有 85%)。问题的部分原因在于,输入只考虑了前 500 个单词,而不是整个序列, 因此, RNN 获得的信息比前面的基准模型更少。另一部分原因在于, SimpleRNN 不擅长处理长序列,比如文本。
其他类型的循环层的表现要好得多。我们之后再来看几个更高级的循环层。

若有收获,就点个赞吧
0 人点赞
