
集成学习方法与经典机器学习算法的关系
集成方法并不是一种独立的机器学习算法,而是一套能够把独立的机器学习算法“捏”到一起,共同解决问题的协作框架。
要介绍集成方法,首先得介绍一个术语:学习器( Learner)。不用担心,它并不是一种新的概念,如前面我们介绍过的决策树、支持向量机等机器学习算法实现的机器学习模块,都可称为学习器。集成学习中把学习器分为两种,一种为“基学习器”(Base Learning)”,另一种为“弱学习器( Weak Learning)”。
- 基学习器:前面我们说过,集成学习就是把许多独立的机器学习算法“捏”在一起,如果它们是同一款机器学习算法,也就是将多个采用同一种算法的机器学习模块进行组合使用,譬如组合使用3个都采用了 Logistic回归算法的机器学习模块,这时的学习器称为“基学习器”。
- 弱学习器:当然还有另外一种情况,就是不同的机器学习模块并非来源于同一款机器学习算法,譬如将分别实现了决策树、支持向量机算法的两个机器学习模块组合使用,这时的学习器就称为“弱学习器”。
集成学习的主要思想
集成学习不是一种独立的机器学习算法,而是把彼此没有关联的机器学习“集成”起来,以取得更好的效果。
没有绝对好的算法,只有合适的算法,换而言之,任何算法都存在局限性,也即“天生不足”,与其绞尽脑汁让一个不合适的算法发挥潜力,不如干脆集成几款机器学习算法,把问题转化为如何在当前数据分布情况下选用更合适的算法来解决问题。集成方法的出发点就好比一个人的知识面总是有限,就算是“学霸”也有碰壁的时候,但人多力量大,多找几个尖子生凑在一起,就算碰到偏题怪题,最终也能够比较好地解决问题。前面介绍的算法都是单打独斗,像是“个人赛”,而用了集成学习之后,解决问题就变成了“团体赛”,可以集思广益了。
总的来说,将机器学习算法用集成学习的方法组织起来,主要有两种组织结构,一种是并联,另一种是串联。
并联
所谓并联就是训练过程是并行的。几个学习器相对独立地完成预测工作,互相之间既不知道也不打扰彼此,相当于大家拿到试卷后分别答题,期间互相不参考、不讨论,只是最后以某种方法把答案合成一份。

串联
串联则不同。所谣串联,就是训练过程是串行的。几个学习器串在一起合 作完成预测,第一个学习器拿到数据集后完成预测,然后把预测结果以及相关数据传递给第二二个学习器,第二个学习器也是在完成预测后把结果和相关数据传递下去。这个过程很像传声简游戏,同样也是第一个队员先听-段旋律,然后复述给第二个队员,依次进行下去,直到最后一个队员给出歌名。串联与并联的最大区别在于,并联的学习器彼此独立,而串联则是把预测结果传递给后面的学习器。
串联和并联各有各的优势,如果各个学习器没有分出高下,都是同等地位,那么最好的选择办法就是“是骡子是马拉出来遛遛”,在这种情况下就选择用并联。如果学习器已经明确了分工,知道谁是主攻而谁是辅助,则可以选择使用串联。
预测如何集成
多个学习器可能会产生多个预测结果,那么怎么将它们整合成一个结果并对外部输出呢?把多个结果整合成一个结果的方法主要有两大类,即平均法和投票法。
- 平均法又具体分为简单平均法和加权平均法,简单平均法就是先求和然后再求均值,加权平均则多了一步—每个学习器通过训练被分别赋予合适的权值,然后求各个预测结果的加权和,最后再求均值。
- 投票法,具体分为三种:简单多数投票法、绝对多数投票法和加权投票法。简单多数投票法就是哪个预测结果占大多数,这个结果就作为最终的预测结果。绝对多数投票法就多了一个限制,这个多数”必须达到半数,譬如有6个学习器,得出同一预测结果的必须达到3个,否则拒绝进行预测。加权投票法有点类似加权平均,首先仍然是给不同的学习器分配权值,第二步同样是查看哪个结果占大多数,但这里有一点儿不同,这里的“大多数”是权值相加后再比较得到的大多数,最后再以得票多的作为最终预测结果,譬如预测结果为A的有个学习器,权值分别为0.1、0.2和0.3,那么结果A的票数就为0.1+0.2+0.3=0.6,而预测结果为B的只有2个学习器,但权值分别为0.4和0.5,那么结果B的票数就为0.4+0.5=0.,也就是结果B的票数高于结果A,最终预测结果就是结果B。
集成学习方法的具体实现方式
1. Bagging 算法
Bagging 算法全称为 Bootstrap Aggregation,这是一种并行集成学习方法。要了解 Bagging,需要了解它的两个主要部分,一个是如何进行训练,另一个是如何完成预测在单个模型时,进行训练都是采用全部训练集,采用 Bagging集成学习则不同,每个具体的学习器所使用的数据集以放回的采样方式重新生成,也就是说,在每个学习器生成训练集时,每个数据样本都有同样的被采样概率。训练完成后, Bagging采用投票的方式进行预测。
2. Boosting 算法
Boosting算法是一种串行集成学习方法,同样需要了解如何训练和如何预测。 Boosting集成学习中学习器进行串行训练,也就是第一个学习器完成训练后,第二个学习器才开始训练。与 Bagging算法不同, Boosting算法的学习器使用全部训练集进行训练,但后面学习器的训练集会受前面预测结果的影响,对于前面学习器发生预测错误的数据,将在后面的训练中提高权值,而正确预测的数据则降低权值。
3. Stacking 算法
许多教材在介绍集成学习方法时,常常只介绍 Boosting和 Bagging算法,而选择忽略 Stacking算法。这让我在最开始接触时觉得特别疑惑,为什么单单跳过 Stacking算法呢?后来我发现一个可能的原因:Stacking算法的思路是不同的。虽然 Bagging算法 和 Boosting算法的具体训练过程不同,但都有一个共同的理念,就是通过组合弱学习 器使得预测能力增强,也就是弱学习器之间的地位是平等的。但 Stacking算法则不同 Stacking的学习器分两层,第一层还是若干弱学习器,它们分别进行预测,然后把预测 结果传递给第二层,第二层通常只有一个机器学习模型,这个模型将根据第一层的预测结果最终给出预测结果,也就是第二层学习器是基于预测结果的预测。
集成学习方法的 Python 实现
在 Scikit-Learn 机器学习库中只直接提供了 Bagging 和 Boosting 两种集成学习方法, 且都在 ensemble 类库下。当前版本一共有16个集成学习类,但实际上涉及的算法只有9 款,其中有7款集成学习算法被分别用于解决分类问题和回归问题,相当于一套算法产生两个类,因此才有16个类之多。较为知名的类包括:
- RandomForestClassifier类:使用随机森林( Random Forest)算法解决分类问题随机森林可谓 Bagging集成学习算法的典型代表它选择以CART决策树算法作为弱学习器,是一种当前非常常用的机器学习算法。
- RandomForestRegressor类:使用随机森林算法解决回归问题。
- ExtraTreesClassifier类:使用极端随机树Extra Tree)算法解决分类问题,极端随机树算法可以看作随机森林算法的一种变种,主要原理非常类似,但在决策条件选择时采用了随机选择的策略。
- ExtraTreesRegressor类:使用极端随机树算法解决回归问题。
- daBoostRegressor类:使用 AdaBoost算法解决分类问题, AdaBoost算法是最知名的 Boosting算法之一。
- AdaBoostRegressor类:使用 AdaBoost算法解决回归问题。 GradientBoostingClassifier类:使用 Gradient Boosting 算法解决分类问题 Gradient Boosting算法常常搭配CART决策树算法使用,这就是有名的梯度提升树(Gradient Boosting Decision Tree,GBDT)算法。
- GradientBoostingRegressor类:使用 Gradient Boosting算法解决回归问题。
Scikit-Learn 对于集成学习方法已经做了非常良好的封装,可以实现“开箱即用”,这里以知名的随机森林算法为例:
from sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifierX, y = load_iris(return_X_y=True)# 随机森林与决策树算法一样,含有一个 criterion 的参数# 可以传入 "gini" 或 "entropy",默认使用基尼指数clf = RandomForestClassifier().fit(X, y)clf.predict(X)clf.estimators_
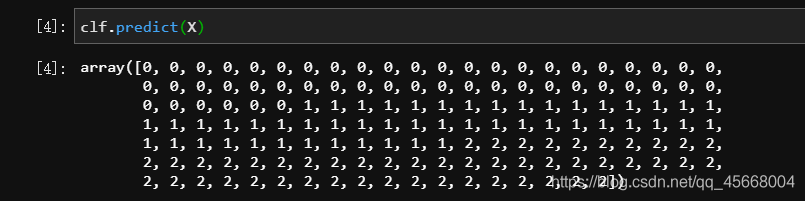
通过参数estimators_可以查看随机森林算法中作为弱学习器的使用的决策树分类算法的情况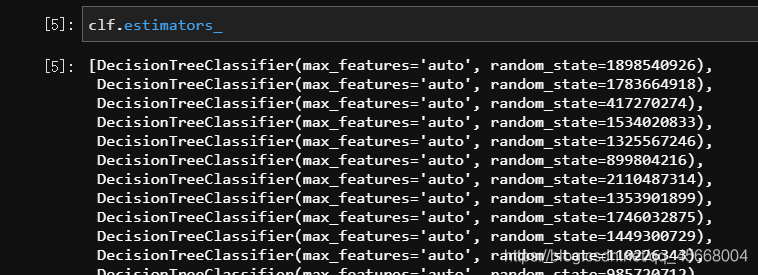
分数: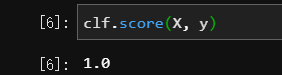
集成学习方法的使用场景
在 Kaggle 等机器学习领域竞赛中,今天已经很难看到使用单一模型,然后还能取得良好成绩的选手了,使用集成学习方法、博采众长已经成为大家的共识,在比赛中集成学习使用得好的选手往往都能取得比较好的成绩。相信在这个深度学习大行其道的时代,其他机器学习算法想要与之一较高下,使用集成学习方法是一种比较可行的策略。
集成学习不是一款别具匠心的机器学习算法,而是一套组合多种机器学习模型的框 架,它的适用面很广,可以用于分类问题、回归问题、特征选取和异常点检测等各类机器学习任务。

若有收获,就点个赞吧
0 人点赞
