利用 Keras 函数式 API,你可以构建类图(graph-like)模型、在不同的输入之间共享某一层, 并且还可以像使用 Python 函数一样使用 Keras 模型。
背景
对于 Sequential 模型假设,网路只有一个输入和一个输出,而且网络是层的线性堆叠: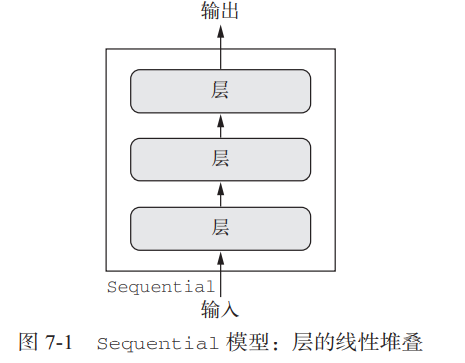
这种网络配置非常常见,但有些情况下这种假设过于死板。有些网络需要多个独立的输入,有些网络则需要多个输出,而有些网络在层与层之间具有内部分支,这使得网络 看起来像是层构成的图(graph),而不是层的线性堆叠。
例如,有些任务需要多模态(multimodal)输入,有些任务需要预测输入数据的多个目标属性。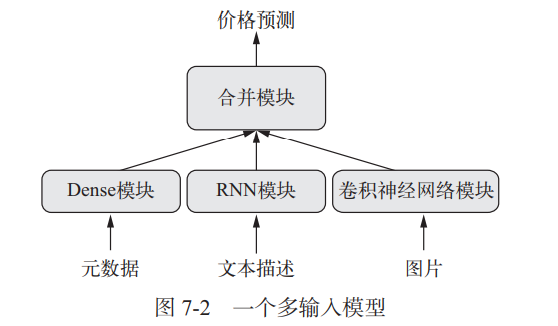
此外,许多最新开发的神经架构要求非线性的网络拓扑结构,即网络结构为有向无环图。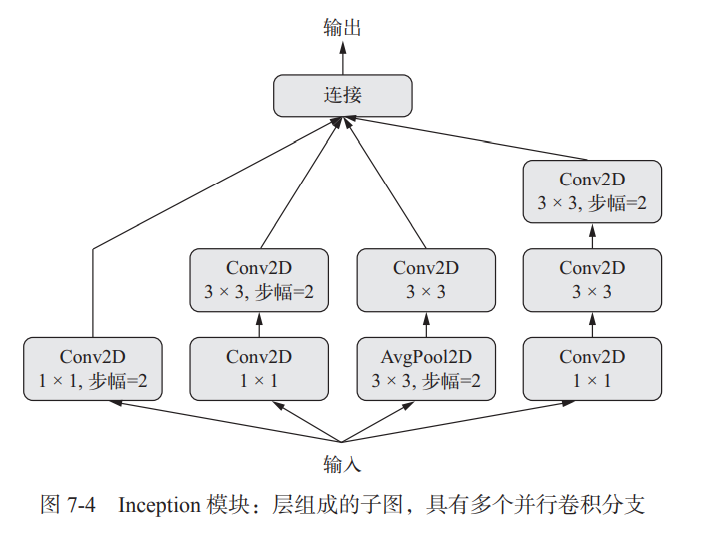
这些模型的实现需要一种更加通用、更加灵活的使用 Keras 的方式,就是函数式 API(functional API)。
函数式 API 简介
使用**函数式 API**,你可以直接操作张量,也可以把层当作函数来使用,接收张量并返回张量(因此得名函数式 API)。
from keras import Input, layersinput_tensor = Input(shape=(32,))dense = layers.Dense(32, activation='relu')output_tensor = dense(input_tensor)
我们首先来看一个最简单的示例,并列展示一个简单的 Sequential 模型以及对应的函数式 API 实现:
from keras.models import Sequential, Modelfrom keras import layersfrom keras import Input## Sequential 模型seq_model = Sequential()seq_model.add(layers.Dense(32, activation='relu', input_shape=(64,)))seq_model.add(layers.Dense(32, activation='relu'))seq_model.add(layers.Dense(10, activation='softmax'))## functional API 实现input_tensor = Input(shape=(64,))x = layers.Dense(32, activation='relu')(input_tensor)x = layers.Dense(32, activation='relu')(x)output_tensor = layers.Dense(10, activation='softmax')(x)model = Model(input_tensor, output_tensor)model.summary()
这里只有一点可能看起来有点神奇,就是将 Model 对象实例化只用了一个输入张量和一个输出张量。Keras 会在后台检索从 input_tensor 到 output_tensor 所包含的每一层, 并将这些层组合成一个类图的数据结构,即一个 Model。
对这种 Model 实例进行编译、训练或评估时,其 API 与 Sequential 模型相同。
多输入模型
函数式 API 可用于构建具有多个输入的模型。
通常情况下,这种模型会在某一时刻用一个可以组合多个张量的层将不同的输入分支合并,张量组合方式可能是相加、连接等。这通常利用 Keras 的合并运算来实现,比如 keras.layers.add、keras.layers.concatenate 等。
我们来看一个非常简单的多输入模型示例——一个问答模型: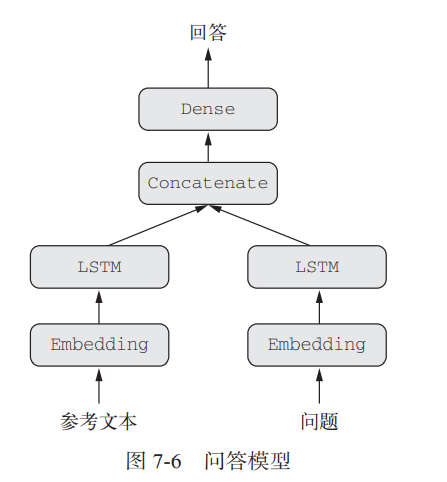
典型的问答模型有两个输入:一个自然语言描述的问题和一个文本片段(比如新闻文章), 后者提供用于回答问题的信息。然后模型要生成一个回答,在最简单的情况下,这个回答只包 含一个词,可以通过对某个预定义的词表做 softmax 得到。
"""用函数式 API 实现双输入问答模型"""from keras.models import Modelfrom keras import layersfrom keras import Inputtext_vocabulary_size = 10000question_vocabulary_size = 10000answer_vocabulary_size = 500# 文本输入是一个长度可变的整数序列。注意,你可以选择对输入进行命名text_input = Input(shape=(None,), dtype='int32', name='text')embedded_text = layers.Embedding(text_vocabulary_size, 64)(text_input) # 将输入嵌入长度为 64 的向量encoded_text = layers.LSTM(32)(embedded_text) # 利用 LSTM 将向量编码为单个向量# 对问题进行相同的处理(使用不同的层实例)question_input = Input(shape=(None,),dtype='int32',name='question')embedded_question = layers.Embedding(question_vocabulary_size, 32)(question_input)encoded_question = layers.LSTM(16)(embedded_question)# 将编码后的问题和文本连接起来concatenated = layers.concatenate([encoded_text, encoded_question],axis=-1)# 在上面添加一个 softmax 分类器answer = layers.Dense(answer_vocabulary_size, activation='softmax')(concatenated)model = Model([text_input, question_input], answer) # 在模型实例化时,指定两个输入和输出model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc'])
接下来要如何训练这个双输入模型呢?有两个可用的 API:
- 我们可以向模型输入一个由 Numpy 数组组成的列表
- 也可以输入一个将输入名称映射为 Numpy 数组的字典。
当然, 只有输入具有名称时才能使用后一种方法。
"""将数据输入到多输入模型中"""import numpy as npnum_samples = 1000max_length = 100# 生成虚构的 numpy 数据text = np.random.randint(1, text_vocabulary_size, size=(num_samples, max_length))question = np.random.randint(1, question_vocabulary_size, size=(num_samples, max_length))answers = np.random.randint(answer_vocabulary_size, size=(num_samples))answers = keras.utils.to_categorical(answers, answer_vocabulary_size)# 使用输入组成的列表来拟合model.fit([text, question], answers, epochs=10, batch_size=128)# 使用输入组成的字典来拟合(只有对输入进行命名之后才能用这种方法)model.fit({'text': text, 'question': question}, answers, epochs=10, batch_size=128)
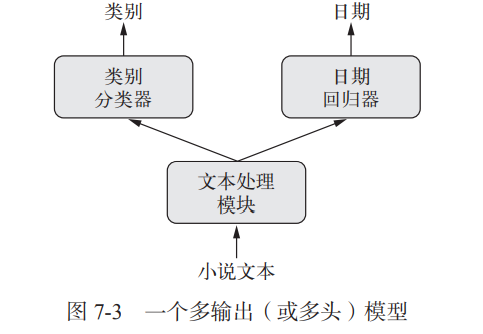
多输出模型
利用相同的方法,我们还可以使用函数式 API 来构建具有多个输出(或多头)的模型。
下面来实现这个模型: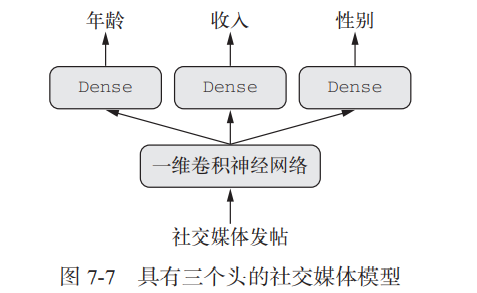
from keras import layersfrom keras import Inputfrom keras.models import Modelvocabulary_size = 50000num_income_groups = 10posts_input = Input(shape=(None,), dtype='int32', name='posts')embedded_posts = layers.Embedding(256, vocabulary_size)(posts_input)x = layers.Conv1D(128, 5, activation='relu')(embedded_posts)x = layers.MaxPooling1D(5)(x)x = layers.Conv1D(256, 5, activation='relu')(x)x = layers.Conv1D(256, 5, activation='relu')(x)x = layers.MaxPooling1D(5)(x)x = layers.Conv1D(256, 5, activation='relu')(x)x = layers.Conv1D(256, 5, activation='relu')(x)x = layers.GlobalMaxPooling1D()(x)x = layers.Dense(128, activation='relu')(x)age_prediction = layers.Dense(1, name='age')(x) # 注意输出层都具有名称income_prediction = layers.Dense(num_income_groups,activation='softmax',name='income')(x)gender_prediction = layers.Dense(1, activation='sigmoid', name='gender')(x)model = Model(posts_input,[age_prediction, income_prediction, gender_prediction])
重要的是,训练这种模型需要能够对网络的各个头指定不同的损失函数。例如,年龄预测是标量回归任务,而性别预测是二分类任务,二者需要不同的训练过程。但是,梯度下降要求将一个标量最小化,所以为了能够训练模型,我们必须将这些损失合并为单个标量。合并不同损失最简单的方法就是对所有损失求和。
Keras 中,你可以在编译时使用损失组成的列表或 字典来为不同输出指定不同损失,然后将得到的损失值相加得到一个全局损失,并在训练过程中将这个损失最小化。
model.compile(optimizer='rmsprop',loss=['mse', 'categorical_crossentropy', 'binary_crossentropy'])# 与上述写法等效的写法model.compile(optimizer='rmsprop',loss={'age': 'mse','income': 'categorical_crossentropy','gender': 'binary_crossentropy'})
注意,严重不平衡的损失贡献会导致模型表示针对单个损失值最大的任务优先进行优化, 而不考虑其他任务的优化。为了解决这个问题,我们可以为每个损失值对最终损失的贡献分配不同大小的重要性。如果不同的损失值具有不同的取值范围,那么这一方法尤其有用。
比如, 用于年龄回归任务的均方误差(MSE)损失值通常在 3~5 左右,而用于性别分类任务的交叉熵损失值可能低至 0.1。在这种情况下,为了平衡不同损失的贡献,我们可以让交叉熵损失的权重 取 10,而 MSE 损失的权重取 0.5。
model.compile(optimizer='rmsprop',loss=['mse', 'categorical_crossentropy', 'binary_crossentropy'],loss_weights=[0.25, 1., 10.])# 与上述写法等效model.compile(optimizer='rmsprop',loss={'age': 'mse','income': 'categorical_crossentropy','gender': 'binary_crossentropy'},loss_weights={'age': 0.25,'income': 1.,'gender': 10.})
与多输入模型相同,多输出模型的训练输入数据可以是 Numpy 数组组成的列表或字典:
model.fit(posts, [age_targets, income_targets, gender_targets],epochs=10, batch_size=64)model.fit(posts, {'age': age_targets,'income': income_targets,'gender': gender_targets},epochs=10, batch_size=64)
层组成的有向无环图
Inception 模块
Inception 是一种流行的卷积神经网络的架构类型,它是模块的堆叠, 这些模块本身看起来像是小型的独立网络,被分为多个并行分支。
Inception 模块最基本的形式 包含 3~4 个分支,首先是一个 1×1 的卷积,然后是一个 3×3 的卷积,最后将所得到的特征连接在一起。
这种设置有助于网络分别学习空间特征和逐通道的特征,这比联合学习这两种特征更 加有效。Inception 模块也可能具有更复杂的形式。
1×1 卷积的作用
卷积能够在输入张量的每一个方块周围提取空间图块,并对所有图块 应用相同的变换。极端情况是提取的图块只包含一个方块。这时卷积运算等价于让每个方块 向量经过一个 Dense 层:它计算得到的特征能够将输入张量通道中的信息混合在一起,但 不会将跨空间的信息混合在一起(因为它一次只查看一个方块)。这种 1×1 卷积[也叫作逐点卷积(pointwise convolution)]是 Inception 模块的特色,它有助于区分开通道特征学习和 空间特征学习。如果你假设每个通道在跨越空间时是高度自相关的,但不同的通道之间可能 并不高度相关,那么这种做法是很合理的。
注意,完整的 Inception V3 架构内置于Keras中,位置在keras.applications.inception_v3. InceptionV3,其中包括在 ImageNet 数据集上预训练得到的权重。与其密切相关的另一个模 型是 Xception,它也是 Keras 的 applications 模块的一部分。Xception 代表极端 Inception (extreme inception),它是一种卷积神经网络架构,其灵感可能来自于 Inception。Xception 将分 别进行通道特征学习与空间特征学习的想法推向逻辑上的极端,并将 Inception 模块替换为深度 可分离卷积,其中包括一个逐深度卷积(即一个空间卷积,分别对每个输入通道进行处理)和 后面的一个逐点卷积(即一个 1×1 卷积)。这个深度可分离卷积实际上是 Inception 模块的一种 极端形式,其空间特征和通道特征被完全分离。Xception 的参数个数与 Inception V3 大致相同, 但因为它对模型参数的使用更加高效,所以在 ImageNet 以及其他大规模数据集上的运行性能更好,精度也更高。
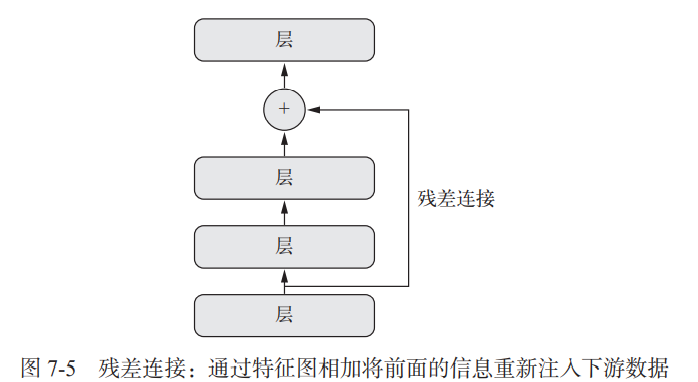
残差连接
残差连接(residual connection)是一种常见的类图网络组件。残差连接解决了困扰所有大规模深度学习模型的两个共性问题: 梯度消失和表示瓶颈。通常来说,向任何多于 10 层的模型中添加残差连接,都可能会有所帮助。
残差连接是让前面某层的输出作为后面某层的输入,从而在序列网络中有效地创造了一条捷径。前面层的输出没有与后面层的激活连接在一起,而是与后面层的激活相加(这里假设两个激活的形状相同)。如果它们的形状不同,我们可以用一个线性变换将前面层的激活改变成目标形状(例如,这个线性变换可以是不带激活的 Dense 层;对于卷积特征图,可以是不带激活 1×1 卷积)。
如果特征图的尺寸相同,在 Keras 中实现残差连接的方法如下,用的是恒等残差连接(identity residual connection)。这个例子假设我们有一个四维输入张量 x:
from keras import layersx = ...y = layers.Conv2D(128, 3, activation='relu', padding='same')(x)y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)y = layers.add([y, x]) # 将原始 x 与输出特征相加
如果特征图的尺寸不同,实现残差连接的方法如下,用的是线性残差连接(linear residual connection)。同样,假设我们有一个四维输入张量 x:
from keras import layersx = ...y = layers.Conv2D(128, 3, activation='relu', padding='same')(x)y = layers.Conv2D(128, 3, activation='relu', padding='same')(y)y = layers.MaxPooling2D(2, strides=2)(y)# 使用 1×1 卷积,将原始 x 张量线性下采样为与 y 具有相同的形状residual = layers.Conv2D(128, 1, strides=2, padding='same')(x)y = layers.add([y, residual]) # 将残差张量与输出特征相加
深度学习中的表示瓶颈问题
在 Sequential 模型中,每个连续的表示层都构建于前一层之上,这意味着它只能访问前一层激活中包含的信息。如果某一层太小(比如特征维度太低),那么模型将会受限于该层激活中能够塞入多少信息。
你可以通过类比信号处理来理解这个概念:假设你有一条包含一系列操作的音频处理流水线,每个操作的输入都是前一个操作的输出,如果某个操作将信号裁剪到低频范围(比如 0~15 kHz),那么下游操作将永远无法恢复那些被丢弃的频段。任何信息的丢失都是永久性的。 残差连接可以将较早的信息重新注入到下游数据中,从而部分解决了深度学习模型的这一问题。
深度学习中的梯度消失问题
反向传播是用于训练深度神经网络的主要算法,其工作原理是将来自输出损失的反馈信号 向下传播到更底部的层。如果这个反馈信号的传播需要经过很多层,那么信号可能会变得非常微弱,甚至完全丢失,导致网络无法训练。这个问题被称为梯度消失(vanishing gradient)。
深度网络中存在这个问题,在很长序列上的循环网络也存在这个问题。在这两种情况下, 反馈信号的传播都必须通过一长串操作。我们已经知道 LSTM 层是如何在循环网络中解决这 个问题的:它引入了一个携带轨道(carry track),可以在与主处理轨道平行的轨道上传播信 息。残差连接在前馈深度网络中的工作原理与此类似,但它更加简单:它引入了一个纯线性的信息携带轨道,与主要的层堆叠方向平行,从而有助于跨越任意深度的层来传播梯度。
共享层权重
函数式 API 还有一个重要特性,那就是能够多次重复使用一个层实例。如果你对一个层实例调用两次,而不是每次调用都实例化一个新层,那么每次调用可以重复使用相同的权重。这样你可以构建具有共享分支的模型,即几个分支全都共享相同的知识并执行相同的运算。也就是说,这些分支共享相同的表示,并同时对不同的输入集合学习这些表示。
举个例子,假设一个模型想要评估两个句子之间的语义相似度。这个模型有两个输入(需 要比较的两个句子),并输出一个范围在 0~1 的分数,0 表示两个句子毫不相关,1 表示两个句 子完全相同或只是换一种表述。这种模型在许多应用中都很有用,其中包括在对话系统中删除 重复的自然语言查询。
在这种设置下,两个输入句子是可以互换的,因为语义相似度是一种对称关系,A 相对 于 B 的相似度等于 B 相对于 A 的相似度。因此,学习两个单独的模型来分别处理两个输入句 子是没有道理的。相反,你需要用一个 LSTM 层来处理两个句子。这个 LSTM 层的表示(即它 的权重)是同时基于两个输入来学习的。我们将其称为连体 LSTM(Siamese LSTM)或共享 LSTM(shared LSTM)模型。
from keras import layersfrom keras import Inputfrom keras.models import Modellstm = layers.LSTM(32) # 将一个 LSTM 层实例化一次# 构建模型的左分支left_input = Input(shape=(None, 128))left_output = lstm(left_input)# 构建模型的右分支right_input = Input(shape=(None, 128))right_output = lstm(right_input)# 在上面构建一个分类器merged = layers.concatenate([left_output, right_output], axis=-1)predictions = layers.Dense(1, activation='sigmoid')(merged)model = Model([left_input, right_input], predictions)model.fit([left_data, right_data], targets)
自然地,一个层实例可能被多次重复使用,它可以被调用任意多次,每次都重复使用一组相同的权重。
将模型作为层
重要的是,在函数式 API 中,可以像使用层一样使用模型。实际上,你可以将模型看作“更大的层”。Sequential 类和 Model 类都是如此。这意味着你可以在一个输入张量上调用模型, 并得到一个输出张量。
y = model(x)
如果模型具有多个输入张量和多个输出张量,那么应该用张量列表来调用模型。
y1, y2 = model([x1, x2])
在调用模型实例时,就是在重复使用模型的权重,正如在调用层实例时,就是在重复使用 层的权重。调用一个实例,无论是层实例还是模型实例,都会重复使用这个实例已经学到的表示, 这很直观。
小结
以上就是对 Keras 函数式 API 的介绍,它是构建高级深度神经网络架构的必备工具。
- 如果你需要实现的架构不仅仅是层的线性堆叠,那么不要局限于 Sequential API。
- 如何使用 Keras 函数式 API 来构建多输入模型、多输出模型和具有复杂的内部网络拓扑结构的模型。
- 如何通过多次调用相同的层实例或模型实例,在不同的处理分支之间重复使用层或模型的权重。

若有收获,就点个赞吧
0 人点赞
