我们将数据划分为训练集、验证集和测试集,并没有在训练模型的相同数据上对模型进行评估,其原因很快显而易见:仅仅几轮过后,三个模型都开始过拟合。也就是说,随着训练的进行,模型在训练数据上的性能始终在提高,但在前所未见的数据上的性能则不再变化或者开始下降。
机器学习的目的是得到可以泛化( generalize)的模型。
训练集、验证集和测试集
评估模型的重点是将数据划分为三个集合:训练集、验证集和测试集。在训练数据上训练模型,在验证数据上评估模型。一旦找到了最佳参数,就在测试数据上最后测试一次。
为什么不是两个集合:一个训练集和一个测试集?
在于开发模型时总是需要调节模型配置,比如选择层数或每层大小[这叫作模型的超参数( hyperparameter),以便与模型参数(即权重)区分开]。这个调节过程需要使用模型在验证数据上的性能作为反馈信号。这个调节过程本质上就是一种学习:在某个参数空间中寻找良好的模型配置。因此,如果基于模型在验证集上的性能来调节模型配置,会很快导致模型在验证集上过拟合,即使你并没有在验证集上直接训练模型也会如此。
造成这一现象的关键在于信息泄露( information leak)。每次基于模型在验证集上的性能来调节模型超参数,都会有一些关于验证数据的信息泄露到模型中。如果对每个参数只调节一次,那么泄露的信息很少,验证集仍然可以可靠地评估模型。但如果你多次重复这一过程(运行一次实验,在验证集上评估,然后据此修改模型),那么将会有越来越多的关于验证集的信息泄露到模型中。最后,你得到的模型在验证集上的性能非常好(人为造成的),因为这正是你优化的目的。 因此你需要使用一个完全不同的、前所未见的数据集来评估模型,它就是测试集。你的模型一定不能读取与测试集有关的任何信息,即使间接读取也不行。
当数据集较少时的处理方法
将数据划分为训练集、验证集和测试集可能看起来很简单,但如果可用数据很少,还有几种高级方法可以派上用场。我们先来介绍三种经典的评估方法:简单的留出验证、 K 折验证,以及带有打乱数据的重复 K 折验证 。
1. 简单地留出验证
留出一定比例的数据作为测试集。在剩余的数据上训练模型,然后在测试集上评估模型。如前所述,为了防止信息泄露,你不能基于测试集来调节模型,所以还应该保留一个验证集。
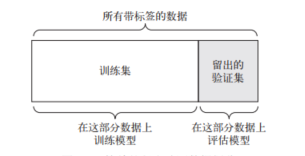
如果可用的数据很少,那么可能验证集和测试集包含的样本就太少,从而无法在统计学上代表数据。这个问题很容易发现:如果在划分数据前
进行不同的随机打乱,最终得到的模型性能差别很大,那么就存在这个问题。
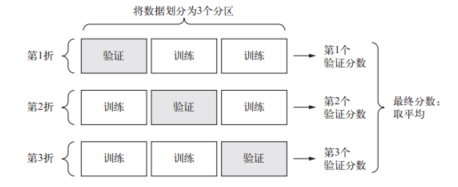
2. K 折验证
K 折验证( K-fold validation) 将数据划分为大小相同的 K 个分区。
K 折验证: 对于每个分区 i,在剩余的 K-1 个分区上训练模型,然后在分区 i 上评估模型。最终分数等于 K 个分数的平均值。
对于不同的训练集 - 测试集划分,如果模型性能的变化很大,那么这种方法很有用。
K 折交叉验证的实现伪代码:
K = 3 # 假设3折验证num_validation_samples = len(train_data) // K # 分区后每个分区的样本数validation_scores = [] # 记录每轮得分np.random.shuffle(train_data) # 可选,用于随机打乱数据for fold in range(K):# 划分分区vali_begin = num_validation_samples * foldvali_end = num_validation_samples * (fold + 1)# 分割出本折的训练集和验证集vali_data = train_data[vali_begin: vali_end]vali_targets = train_targets[vali_begin: vali_end]partial_train_data = train_data[: vali_begin] + train_data[vali_end:]partial_train_targets = train_targets[: vali_begin] + targets_data[vali_end:]# 获得一个模型并训练model = build_model()model.fit(partial_train_data, partial_train_targets)score = evaluate(model, vali_data, vali_targets)validation_scores.append(score)vali_score = np.mean(validation_scores) # 最终验证分数:K 折验证分数的平均值
3. 带有打乱数据的重复 K 折验证
如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择带有打乱数据的重复 K 折验证( iterated K-fold validation with shuffling)。
重复 K 折验证: 多次使用 K 折验证,在每次将数据划分为 K 个分区之前都先将数据打乱。最终分数是每次 K 折验证分数的平均值。
- 注意,这种方法一共要训练和评估 P × K 个模型( P是重复次数),计算代价很大。
评估模型的注意事项
- 数据代表性( data representativeness)。你希望训练集和测试集都能够代表当前数据。例如,你想要对数字图像进行分类,而图像样本是按类别排序的,如果你将前 80% 作为训练集,剩余 20% 作为测试集,那么会导致训练集中只包含类别 0~7,而测试集中只包含类别 8~9。这个错误看起来很可笑,却很常见。因此,在将数据划分为训练集和测试集之前,通常应该随机打乱数据。
- 时间箭头( the arrow of time)。如果想要根据过去预测未来(比如明天的天气、股票走势等),那么在划分数据前你不应该随机打乱数据,因为这么做会造成时间泄露( temporalleak):你的模型将在未来数据上得到有效训练。在这种情况下,你应该始终确保测试集中所有数据的时间都晚于训练集数据。
- 数据冗余( redundancy in your data)。如果数据中的某些数据点出现了两次(这在现实中的数据里十分常见),那么打乱数据并划分成训练集和验证集会导致训练集和验证集之间的数据冗余。从效果上来看,你是在部分训练数据上评估模型,这是极其糟糕的!一定要确保训练集和验证集之间没有交集。

若有收获,就点个赞吧
0 人点赞
