分类问题
学术上对分类问题做了细致区别,如果待分类只有两个,通常称之为“二元分类问题”,在机器学习中较多使用 Logistic 函数来解决;若待分类超过两个,则称之为“多分类问题”,较多使用 Softmax 函数来解决。
对二元分类,机器学习也专门规定了术语,将“是”类成为“正类(Positive)”,而将“否”类成为“负类(Negative)”,与之对应的训练集中也可划分为“正样本”和“负样本”。
Logistic 函数介绍
在神经网络算法中,也称之为 Sigmoid函数,它既是一种可导的函数,也是一种阶跃函数(或者说能够扮演类似阶跃函数的角色)。
Logistic函数作为阶跃函数来说,是尺度越大,其效果越明显。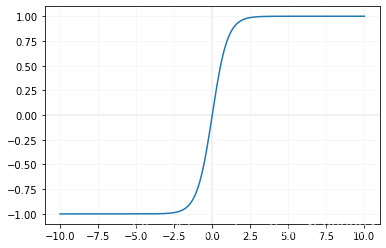
- X轴的值越是小于0,Y轴的值就越是接近于0;
- X轴的值越是大于0,Y轴的值就越是接近于1。
那么,通过Logistic函数就可以把线性模型的预测结果映射成分类问题所需的预测结果思路如下:
- 将线性模型的输出和 Logistic 函数的输入串接起来;
- 当样本为负类时,让线性模型输出的预测值小于0,而且越小越好;
- 当样本为正类时,让线性模型输出的预测值大于0,而且越大越好。
有了 Logistic 函数进行映射,线性模型不再需要输出某个特定的值,而只要满足 “让 Logistic 函数输出尽可能地接近0或者1”这一条要求即可。这条要求是线性模型可以满足的。
同时 Logistic 函数的返回值为 [0, 1],即它的输出区间符合概率的要求。
Logistic 回归介绍
本文的 Logistic 回归和其他文献中的“逻辑回归”“逻辑斯谛回归”以及“对数几率回归”指的都是同一套算法。
接着就要说说 Logistic回归名字本身了,这个名字至少有两处地方显示命名者掩藏不住的浓烈黑色幽默感:一是虽然名字赫然写着“回归”,但实际上解决的却是分类问题,堪称算法界的“身在曹营心在汉”;二是虽然名字没有半点“线性”的蛛丝马迹,但担纲的却都是地地道道的线性模型原班人马。
Logistic 回归的算法原理
基本思路
分类问题的预测结果自然预测的是类别, 也许你在日常生活中习惯以类别的名字作为不同类别的区分,但在机器学习中,使用的 是事前约定的数值来代表类别,常用的形式有如下三种:
- 数字形式:这是最为直接的一种形式,譬如直接用“1”代表正类,“-1”代表示负类,那么预测结果是正类就输出“1”,是负类就输出-1,简单明了。当然,指代的数字不是唯一的,只要能与类别对应就行,譬如另一种常见习惯是用“0“来指代负类。
- 向量形式:这是当前深度学习在分类问题上使用最多的一种形式,特别是在多分类问题上多采用这种形式,用向量中元素按顺序代表类别,譬如有A、B、C三类就可以用[x1,x2,x3]这样的向量元素依次代表,预测结果为哪一类,就把向量中的对应元素置1,其他置0。如预测的结果类别为“A”,则输出的预测结果就表示为[1,0,0];预测结果为“B”,则表示为[0,1,0]。
- 概率值形式:前面两种表示形式都以1或0等确值来表示预测结果是否为这个类但部分算法给出的预测结果不是绝对的“是/否”,而是每个类的可能概率。如上文对A、B、C三类的预测结果,用这种形式就表示为如0.84302000419,可以看出,虽然三个元素都存在一定概率,但显然“A”的概率要高于其他,同样能够起到预测类别的效果。
在套上Logistic函数的马甲后,凭什么就能保证线性模型对正类的预测结果大于0呢?这是个好问题,也是理解线性模型从线性回归到 Logistic回归的关键。
关键还是在于线性回归。我们俯下身子,学着从线性模型的视角看,就会发现这里根本不存在什么预测值是离散的分类问题,而是要预测得到一个连续值。对于任意一个非零数值,当然不是大于0就是小于0,为了使预测更准确,唯一的要求就是预测值距离0点越远越好,譬如说把正类看成是要预测3756.2、3890、3910.7,把负类结果看成要预测-21164、-2213、-2305.6这样的连续值。这当然还是典型的回归问题,然后就可以照葫芦画瓢地用线性回归那套老办法去拟合。只要线性回归圆满完成了它的任务我们自然就能保证正类的预测结果大于0,而负类小于0了。
Logistic回归的数学解析
1. Logsitic 回归的数学表达式
Logistic函数的数学表达式如下:
%20%3D%20%5Cfrac%20%7B1%7D%7B%201%20%2B%20e%5E%7B-z%7D%20%7D%0A#card=math&code=Logistic%28z%29%20%3D%20%5Cfrac%20%7B1%7D%7B%201%20%2B%20e%5E%7B-z%7D%20%7D%0A&height=40&width=163)
表达式为什么要写成这个样子,其实没必要细究。数学是门发现的学问,也是一门发明的学问,数学家出于各种目的也会“制造”一些产品,感觉需要阶跃函数了,就“制造”出Logistic函数。只需要记住这个Logistic函数就可以了。
Logistic回归的假设函数就是套上Logistic数的线性方程,也就是把线性方程表达式带入上式的 z,表达式如下:
%20%3D%20%5Cfrac%20%7B1%7D%7B%201%20%2B%20e%5E%7B-(%5Comega%5ET%20x_i%20%2B%20b)%7D%20%7D%0A#card=math&code=H%28x%29%20%3D%20%5Cfrac%20%7B1%7D%7B%201%20%2B%20e%5E%7B-%28%5Comega%5ET%20x_i%20%2B%20b%29%7D%20%7D%0A)
该假设函数的返回值便是样本为正样本(y = 1)的概率。
因为在我们假设正类为1,负类为0是,便已经把正类当做标准。
2. Logistic 回归的损失函数
Logistic 回归的损失函数表达式如下:
%20%3D%20-y%20%5Clog%7BH(x)%7D%20-%20(1%20-%20y)%20%5Clog%7B(%201%20-%20H(x)%20)%7D%0A#card=math&code=L%28x%29%20%3D%20-y%20%5Clog%7BH%28x%29%7D%20-%20%281%20-%20y%29%20%5Clog%7B%28%201%20-%20H%28x%29%20%29%7D%0A)
要弄清楚损失函数,首先还是回到假设函数。我们知道假设函数的返回值是正样本的概率,如果把预测结果看做概率,那可以写出第一版的损失函数:
%20%3D%20-H(x_i)%5E%7By_i%7D%20(1%20-%20H(x_i)%20)%5E%7B1%20-%20y_i%7D%0A#card=math&code=L%28x%29%20%3D%20-H%28x_i%29%5E%7By_i%7D%20%281%20-%20H%28x_i%29%20%29%5E%7B1%20-%20y_i%7D%0A)
这是根据概率巧妙设计出来的。函数的值由#card=math&code=H%28x_i%29)和
)#card=math&code=%281-H%28x_i%29%29)两部分相乘,但由于y的值只会为0或1所以实际上每次只会有一个部分能够输出值。当y=1时,
就为0,所以第二部分的值为1,相乘后不会对函数的值产生影响,函数值为
#card=math&code=H%28x_i%29)。同理,当y=0时,函数值为
#card=math&code=1-H%28x_i%29)。
现在确定一下损失函数是否正常工作。当y=1时如果预测正确,预测值则无限接近1, 也就是%5E%7By_i%7D#card=math&code=H%28x_i%29%5E%7By_i%7D)的值为1,损失值则为-1。如果预测错误,
%5E%7By_i%7D#card=math&code=H%28x_i%29%5E%7By_i%7D)的值为0,损失值也为0。预测错误的损失值确实比预测正确的大,满足要求。
损失函数的要求就是当模型越好时,损失函数的值越小。
第一版的损失函数虽然能够表达预测值和实际值之间的偏差,但存在一个致命的问题:它不是一个凸函数,这将导致无法使用梯度下降等优化方法使得损失值最小。好在机器学习界早就掌握了应对这种状况的解决方法:对数函数,也即取 。
3. Logistic 回归算法的具体步骤
- 为假设函数设定参数
,通过假设函数计算出一个预测值。
- 将预测值带入损失函数,计算出一个损失值。
- 通过得到的损失值,利用梯度下降等优化方法调整参数
Logistic 回归算法的 Python 实现
# 导入所需的包from sklearn.linear_model import LogisticRegressionfrom sklearn.datasets import load_iris# 获取鸢尾花数据集X, y = load_iris(return_X_y=True)# 生成模型并训练lr_model = LogisticRegression()clf = lr_model.fit(X, y)# 进行预测print(clf.predict(X))# 使用性能评估器进行分数评估print('score:', clf.score(X, y))
预测结果如下: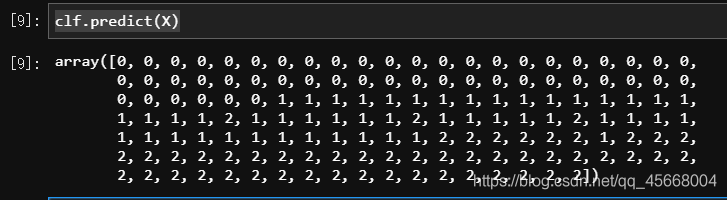

若有收获,就点个赞吧
0 人点赞
