1.读写分离
利用主从数据库来实现读写分离,从而分担主数据库的压力。在多个服务器上部署mysql,将其中一台认为主数据库,其他为从数据库,实现主从同步。其中主数据库负责主动写的操作,而从数据库则只负责主动读的操作。
实现MySQL读写分离的前提是MySQL的主从复制。
读写分离实现方式:
- 配置多数据源,参考spring集成mybatis实现mysql读写分离
- 使用数据库中间件代理工具(MySQL Proxy、MyCat 以及 Shardingsphere )

使用MyCat实现读写分离操作
MyCat是数据库中间件,介于数据库与应用之间,可以简单的理解成数据库代理,我们的应用只需要与数据库中间件交互,而无需关注复杂的数据库部署。数据的同步在mysql层面实现的,mycat不负责任何的数据库同步。
MyCat常用配置文件
| 文件 | 说明 |
|---|---|
| server.xml | MyCat的配置文件,设置账号、参数等 |
| schema.xml | MyCat对应的物理数据库和数据库表的设置 |
| rule.xml | MyCat分片(分库分表)规则 |
| wrapper.conf | MyCat启动日志信息 |
配置schema.xml
<?xml version="1.0"?><!DOCTYPE mycat:schema SYSTEM "schema.dtd"><mycat:schema xmlns:mycat="http://io.mycat/"><schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1"></schema><dataNode name="dn1" dataHost="localhost1" database="mycat_db" /><dataHost name="localhost1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><!-- 实现读写分离,写走hostM1,读走hostS1,若hostM1宕机了, hostS1也不可用 --><writeHost host="hostM1" url="192.168.1.210:3306" user="root" password="123456"><readHost host="hostS1" url="192.168.1.211:3306" user="root" password="123456" /></writeHost><!-- 实现高可用,hostM1宕机了, hostM2顶上 --><writeHost host="hostM2" url="192.168.1.211:3306" user="root" password="123456" /></dataHost></mycat:schema>
演示
我们手动停掉master上的mysql服务,看看mycat能不能自动的切换到下一个writeHost。

mycat将master从hostM1切换到hostM2需要一定的时间,切换过程中如果强制从master操作,会抛出(java.net.ConnectException: 拒绝连接),这是属于正常情况。
2.分库分表
一般分为垂直切分和水平切分。如果用户请求量太大,我们就堆机器搞定;如果单个库太大,这时要分析是因为表多而导致数据多,还是单张表里面的数据多。如果表多而数据多,使用垂直切分,根据业务切分成不同的库;如果单张表的数据量太大,使用水平切分,即把表数据按某种规则切分成多张表,甚至多个库上的多张表。
分库分表的顺序应该是先垂直分,后水平分。
垂直分库针对的是一个系统中的不同业务进行拆分,以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
垂直分表是以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
水平分库是以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
水平分表是以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。
水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
使用MyCat实现分库分表
配置schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- 取模分片 -->
<table name="student" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long" />
<table name="grade" primaryKey="id" dataNode="dn4"/>
</schema>
<!-- 申明节点对应的database -->
<dataNode name="dn1" dataHost="localhost1" database="beijing" />
<dataNode name="dn2" dataHost="localhost1" database="shanghai" />
<dataNode name="dn3" dataHost="localhost1" database="guangzhou" />
<dataNode name="dn4" dataHost="localhost1" database="basic" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可读写的数据库实例 -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="******">
</writeHost>
</dataHost>
</mycat:schema>
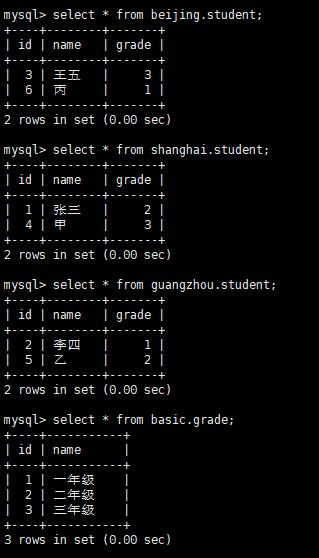
在逻辑库中插入一下数据验证一下:
insert into grade (id,name) values (1,'一年级');
insert into grade (id,name) values (2,'二年级');
insert into grade (id,name) values (3,'三年级');
insert into student (id,name,grade) values (1,'张三',2);
insert into student (id,name,grade) values (2,'李四',1);
insert into student (id,name,grade) values (3,'王五',3);
insert into student (id,name,grade) values (4,'甲',3);
insert into student (id,name,grade) values (5,'乙',2);
insert into student (id,name,grade) values (6,'丙',1);
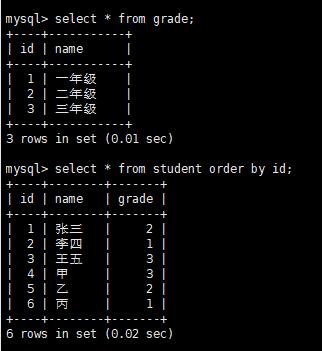
演示
逻辑数据库,查询grade和student两张表,已经数据聚合,还可以进行排序。
参考

若有收获,就点个赞吧
0 人点赞
