Java的集合容器框架中主要有四大类别:List、Set、Queue、Map。大家熟知的这些集合类ArrayList、LinkedList、HashMap这些容器都是非线程安全的。
同步容器可以简单地理解为通过synchronized来实现同步的容器,比如Vector、Stack、Hashtable以及Collections.synchronized方法生成的等容器。
java.util.concurrent包中提供了多种并发类容器。并发类容器是专门针对多线程并发设计的。
1.快速失败和安全失败
使用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除和修改),则会抛出Concurent Modification Exception。
场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改。
安全失败机制的集合容器,在遍历时不时直接在集合容器上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。基于拷贝内容的优点避免了Concurrent Modification Exception,但是迭代器并不能访问修改后的内容。
场景:java.util.concurrent包下的容器都是安全失败的,可以在多线程下并发使用,并发修改
public class Demo1{public static void main(String[] args) {final ArrayList<String> arrayList = new ArrayList<String>();for (int i = 0; i < 3; i++) {new Thread(new Runnable() {@Overridepublic void run() {arrayList.add("aaaaa");System.out.println(arrayList);}}).start();}}}

解决方式
- 使用Vector、等
- Collections.synchronized
-
ConcurrentHashMap
对应的非并发容器:HashMap
目标:代替Hashtable、synchronizedMap,支持复合操作
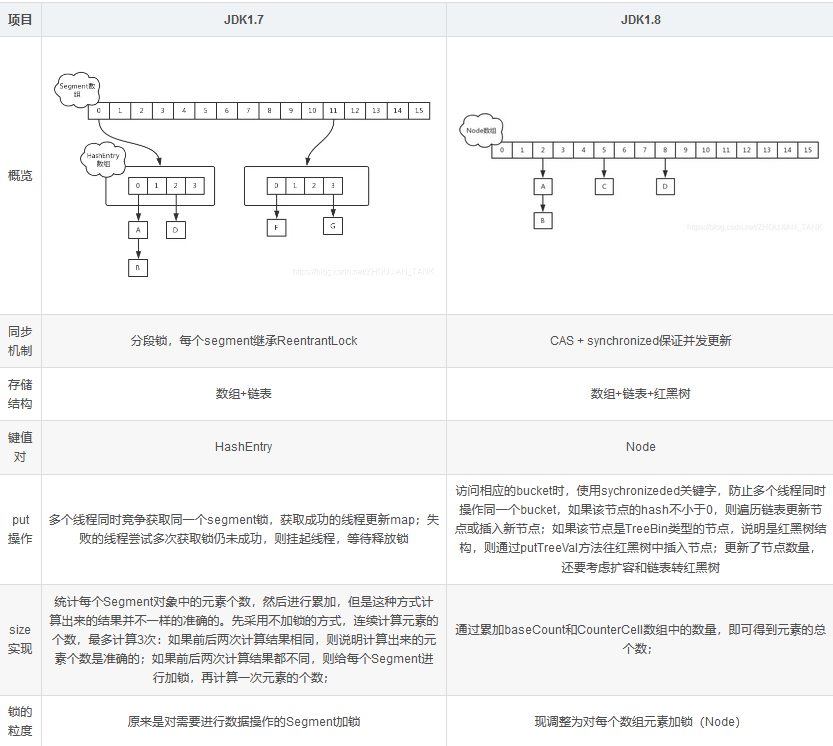
原理:JDK7中采用一种更加细粒度的加锁机制Segment“分段锁”,JDK8中采用CAS无锁算法。JDK1.7
ConcurrentHashMap采用了数组+Segment+分段锁的方式实现。
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment对象组成的数组。
ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作。第一次Hash定位到Segment,第二次Hash定位到元素所在链表的头部。
ConcurrentHashMap 在默认并发级别下会创建16个Segment对象的数组,如果键能均匀散列,每个 Segment 大约守护整个散列表中桶总数的 1/16 。
Concureent基于分段式的segment操作,对每个segment持有不同的锁,在进行put数据时对该segment加锁 对同一个segment读和写不干扰
- 对同一个segement进行写干扰
- 对不同的segment的读写不干扰 ```java
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 计算key的hash值
int hash = hash(key);
// 将hash值右移偏移量位,并与上31(11111),所以j为0-31之间的数
int j = (hash >>> segmentShift) & segmentMask;
//定位到段,ConcurrentHashMap不同于HashMap,它既不允许Key值为Null
//也不允许value值为null,
//根据key的hash值的高n位就可以确定元素到底在哪一个Segment中
//紧接着调用这个段的put()方法来将目标key/value对插入到段中
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
// 获取下标为j的segment的对象,如果未创建则用UNSAFE提供的CAS操作创建segment对象。并保证多个线程同时创建的正确性。
//我们从ConcurrentHashMap的构造函数可以发现Segment数组只初始化了Segment[0],
//其余的Segment是用到了延迟加载的策略,而延迟加载调用的就是ensureSegment(J)
s = ensureSegment(j);
//对对应段插入数据
return s.put(key, hash, value, false);
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//获得锁
/**
* 。需要注意的是,这里的加锁操作是针对某个具体的Segment,
* 锁定的也是该Segment而不是整个ConcurrentHashMap。
* 因为插入键/值对操作只是在这个Segment包含的某个桶中完成,不需要锁定整个ConcurrentHashMap。
* 因此,其他写线程对另外15个Segment的加锁并不会因为当前线程对这个Segment的加锁而阻塞。
*
* 相比于HashTable和由同步器包装的HashMap每次只能有一个线程执行读或写操作,
* ConcurrentHashMap在并发访问性能上有了质的提高。在理想状态下,ConcurrentHashMap可以支持16个线程执行并发写操作(如果并发级别设置为16)
*
*
*/
//尝试获取锁,获取不到时,调用scan..预先创建节点并返回(有点自旋锁的意味)。
HashEntry<K,V> node = tryLock() ? null :
// 在不超过最大重试次数MAX_SCAN_RETRIES通过CAS尝试获取锁
scanAndLockForPut(key, hash, value);
//旧的值
V oldValue;
try {
HashEntry<K,V>[] tab = table;//获得table
//计算此key在HashEntry[]数组的下标
int index = (tab.length - 1) & hash;//计算索引位置
// // 获取该下标下链表的头节点
HashEntry<K,V> first = entryAt(tab, index);//first指向桶中链表的表头
// // 遍历链表
for (HashEntry<K,V> e = first;;) {///此处有链表结构,一直循环到e==null
if (e != null) { //e不为空
K k;
if ((k = e.key) == key || //找到
(e.hash == hash && key.equals(k))) {//找到相同的节点,则替换
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;//不断向后遍历
}
else { //node不为null,设置node的next为first,node为当前链表的头节点
if (node != null)
node.setNext(first);
else//node为null,创建头节点,指定next为first,node为当前链表的头节点
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1; //大于阈值则需要进行扩容
//扩容条件 (1)entry数量大于阈值 (2) 当前数组tab长度小于最大容量。满足以上条件就扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//ConcurrentHashMap的重哈希实际上是对ConcurrentHashMap的某个端的冲哈喜
//因此ConcurrentHash的每个段锁包含的桶为自然也就不进相同
rehash(node);
else
//tab的index位置设置为node,
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();//释放锁
}
return oldValue;
}
<a name="g9bBl"></a>
### JDK1.8
利用 CAS + synchronized 来保证并发更新的安全,底层使用**数组+链表+红黑树**来实现。
table数组是被volatile关键字修饰的,这就代表我们不需要担心table数组的线程可见性问题,也就没有必要再加锁来实现并发了。 <br />假设table已经初始化完成,put操作采用CAS+synchronized实现并发插入或更新操作:
- 当前bucket为空时,使用CAS操作,将Node放入对应的bucket中。
- 出现hash冲突,则采用synchronized关键字。倘若当前hash对应的节点是链表的头节点,遍历链表,若找到对应的node节点,则修改node节点的val,否则在链表末尾添加node节点;倘若当前节点是红黑树的根节点,在树结构上遍历元素,更新或增加节点。
- 倘若当前map正在扩容f.hash == MOVED, 则跟其他线程一起进行扩容
<a name="eUEUp"></a>
## CopyOnWriteArrayList
对应的非并发容器:ArrayList<br />目标:代替Vector、synchronizedList<br />原理:利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,并通过volatile 保证其可见性,当然写操作的锁是必不可少的了。
写入时复制(CopyOnWrite,简称COW)思想是计算机程序设计领域中的一种优化策略。其核心思想是,如果有多个调用者(Callers)同时要求相同的资源(如内存或者是磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者视图修改资源内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。<br />并发版本ArrayList,底层结构是数组。使用场景:由于读操作不加锁,写(增,删,改)操作加锁,因此适用于读多写少的场景
<a name="g2s85"></a>
### set方法:加锁
```java
/*
* 读写分离,在读取数据时不用加锁,在写入数据时需要对数据进行加锁,
* 并获取原数据的一份拷贝,对这份拷贝进行操作,然后将操作完的数据再赋值给元数据的指向,这样就不会影响读
*/
public E set(int index, E element) {
//加锁
final ReentrantLock lock = this.lock;
lock.lock();
try {
//获取元数据
Object[] elements = getArray();
//
E oldValue = get(elements, index);
//数据不为空
if (oldValue != element) {
//对原数组进行一份拷贝
int len = elements.length;
//进行内部元素的完成整复制,因此,会生成一个新的数组newElements,然后将新的元素加入newElements
Object[] newElements = Arrays.copyOf(elements, len);
//将index出的数进行修改
newElements[index] = element;
//进行拷贝,将array的指向指向新的数值
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
final Object[] getArray() {
return array;
}
get方法
public E get(int index) {
return get(getArray(), index);
}
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
//读代码没有发生任何同步控制和锁操作,
//理由是内部数组array不会发生修改,只会被另外一个array替换,因此可以保证数据安全
return (E) a[index];
}
问题
- 只能保证数据的最终一致性,不能保证数据的实时一致性
- 存在内存占用, 频繁的垃圾回收行为,降低性能
CopyOnWriteArraySet
对应的非并发容器:HashSet
目标:代替synchronizedSet
原理:基于CopyOnWriteArrayList实现,其唯一的不同是在add时调用的是CopyOnWriteArrayList的addIfAbsent方法,其遍历当前Object数组,如Object数组中已有了当前元素,则直接返回,如果没有则放入Object数组的尾部,并返回。ConcurrentSkipListMap
对应的非并发容器:TreeMap
目标:代替synchronizedSortedMap(TreeMap)
原理:Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。ConcurrentSkipListSet
对应的非并发容器:TreeSet
目标:代替synchronizedSortedSet
原理:内部基于ConcurrentSkipListMap实现BlockingQueue
| 方法/处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 | | —- | —- | —- | —- | —- | | 插入方法 | add(e) | offer(e) | put(e) | offer(e,time,unit) | | 移除方法 | remove() | poll() | take() | poll(time,uniot) |
| 抛出异常 | 当阻塞队列满时,再往队列里面add插入元素会抛IllegalStateException: Queue full 当阻塞队列空时,再往队列Remove元素时候回抛出NoSuchElementException |
|---|---|
| 特殊值 | 插入方法,成功返回true 失败返回false 移除方法,成功返回元素,队列里面没有就返回null |
| 一直阻塞 | 当阻塞队列满时,生产者继续往队列里面put元素,队列会一直阻塞直到put数据or响应中断退出 当阻塞队列空时,消费者试图从队列take元素,队列会一直阻塞消费者线程直到队列可用. |
| 超时退出 | 当阻塞队列满时,队列会阻塞生产者线程一定时间,超过后限时后生产者线程就会退出 |

ArrayBlockingQueue分析
一个数组,定义显示锁访问数据结构;当数据不够时,通过condition实现线程间的通信。
//共享内存
final Object[] items;
/** items index for next take, poll, peek or remove */
int takeIndex;
/** items index for next put, offer, or add */
int putIndex;
/** Number of elements in the queue */
//队列中元素的数量
int count;
/** Main lock guarding all access */
//锁
final ReentrantLock lock;
/** Condition for waiting takes */
private final Condition notEmpty;
/** Condition for waiting puts */
private final Condition notFull;
阻塞的添加元素(put)
当底层数组是满的时候:这个线程等待在数组已经满的条件上 notFull.await();当数组不满时,向数组中添加数据,并唤醒notEmpty.signal
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
//尝试加锁
lock.lockInterruptibly();
try {
//若数组已经满了,在等待不满通知
while (count == items.length)
notFull.await();
//调用一个封装的方法
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
//对数组添加元素
items[putIndex] = x;
//循环数组,当数组满了
if (++putIndex == items.length)
putIndex = 0;
//计算数组中的元素怒
count++;
//通知 数组中有数据了,可以进行取值了
notEmpty.signal();
}
阻塞的获取元素take()
当数组中的元素为空时则阻塞,并等待在notEmpty.await()上,当数组中有元素时则取出数据,并通知notFull.signal
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
//加锁
lock.lockInterruptibly();
try {
//数组为空,在等待不是空通知的瞎弄
while (count == 0)
notEmpty.await();
//取数据
return dequeue();
} finally {
lock.unlock();
}
}
/从数组中取出元素///
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
final Object[] items = this.items;
@SuppressWarnings("unchecked")
//取数据了
E x = (E) items[takeIndex];
items[takeIndex] = null;
//循环
if (++takeIndex == items.length)
takeIndex = 0;
count--;
//
if (itrs != null)
itrs.elementDequeued();
//通知可以生产数据
notFull.signal();
return x;
}
LinkedBlockingQueue分析
static class Node {
E item;
Node<E> next;
Node(E x) { item = x; }
}
private final int capacity;
/** 当前队列中的元素 */
private final AtomicInteger count = new AtomicInteger();
/**
* Head of linked list.
* Invariant: head.item == null
* 链表的首部
*/
transient Node<E> head;
/**
* Tail of linked list.
* Invariant: last.next == null
* 链表的尾部
*/
private transient Node<E> last;
/** Lock held by take, poll, etc */
// take锁
private final ReentrantLock takeLock = new ReentrantLock();
/** Wait queue for waiting takes */
private final Condition notEmpty = takeLock.newCondition();
/** Lock held by put, offer, etc */
//put锁
private final ReentrantLock putLock = new ReentrantLock();
/** Wait queue for waiting puts */
private final Condition notFull = putLock.newCondition();
put方法
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
//加锁
putLock.lockInterruptibly();
try {
//LinkedBloking默认的长度Integer.mAXvALUE若没有指定会非常大则不会阻塞
//若达到设置的阈值,则假数据线程阻塞
while (count.get() == capacity) {
notFull.await();
}
//向链表中加数据
enqueue(node);
//通过cas进行加1
c = count.getAndIncrement();
//
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
ArrayBlockingQueue和LinkedBlocking
- ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点做维护连接对象的链表
- ArrayBlockingQUeue采用的是数组的存储容器,因此在插入或删除时不会产生或销毁任何额外的对象的实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效的并发处理大批量数据时,对于GC可能存在较大的影响
- ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加和溢出操作采用的是同一个ReentaranLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的是TakeLock没这样能大大提高队列的吞吐量,也意味着在高并发情况下生产者和消费者可以并行的操作队列中的数据,以此来提高整个队列的并发性能
- ArrayBlocking是有解的初始化必须指定大小,而LinkedBlockiung可以是有界的也可以是无界的,对于后者而言,当添加速度大于移除速度的时,在无界的情况下可能会造成内存溢出的情况 ,不允许null值
SynchronousQueue
SynchronousQueue是一个不存储元素的队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。它支持公平访问队列,默认情况下线程采用非公平性策略访问队列。 ```java public SynchronousQueue() { this(false); }
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue
PriorityBlockingQueue
构造时可以传入一个比较器,可以看做放进去的元素会被排序,然后读取的时候按顺序消费。某些低优先级的元素可能长期无法被消费,因为不断有更高优先级的元素进来。
不允许null值,入队和出队的时间复杂度是O(log(n))
如何实现阻塞队列
- 核心Synchronized以及objectwait
- 当数组满时,让添加线程阻塞;当数组空时让取出线程等待
- 当数组有元素的时候,通知 等待在空信号线程运行
参考
CurrentHashMap
阻塞队列LinkedBlockingQueue与ArrayBlockingQueue

若有收获,就点个赞吧
0 人点赞
