1.并发编程三要素
原子性
和数据库事务中的原子性一样,满足原子性特性的操作是不可中断的,要么全部执行成功要么全部执行失败。
基本类型的读取和赋值操作(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
比如:i = 2; j = i; i++; i = i + 1;
上面4个操作中,i=2是读取操作,是原子性操作;j=i分为两步,先读取i的值,然后再赋值给j,不是原子操作;i++和i = i + 1其实是等效的,读取i的值,加1,再写回主存,不是原子操作。
/**案例演示:5个线程各执行1000次 i++;*/public class Test02Atomicity{private static int number = 0;public static void main(String[] args) throws InterruptedException{//5个线程都执行1000次i++Runnable increment = () -> {for( int i = 0 ; i < 1000; i++){number++;}};//5个线程ArrayList<Thread> ts = new ArrayList<>();for(int i = 0; i < 5 ; i++){Thread t = new Thread(increment);t.start();ts.add(t);}for(Thread t : ts){t.join();}/* 最终的效果即,加出来的效果不是5000,可能会少于5000那么原因就在于i++并不是一个原子操作到时候会通过java反汇编的方式来进行演示和分析,这个i++其实有4条指令*/System.out.println("number = "+ number);}}
可见性
多个线程访问同一个共享变量时,其中一个线程对这个共享变量值的修改,其他线程能够立刻获得修改以后的值。
/**
案例演示:
一个线程对共享变量的修改,另一个线程不能立即得到最新值
*/
public class Test01Visibility{
//多个线程都会访问的数据,我们成为线程的共享数据
private static boolean run = false;
public static void main(String[] args) throws InterruptedException{
//t1线程不断的来读取run共享变量的取值
Thread t1 = new Thread(() -> {
while(run){
}
});
t1.start();
Thread.sleep(1000);
//t2线程对该共享变量的取值进行修改
Thread t2 = new Thread(() -> {
run = false;
System.out.println("时间到,线层2设置为false");
});
t2.start();
//可以观测得到t2线程对run共享变量的修改,t1线程并不能够读取到更改了之后的值;
//这就出现了可见性问题
}
}
有序性
程序执行的顺序按照代码的先后顺序执行。由于java在编译器以及运行期的优化,导致了代码的执行顺序未必就是开发者编写代码时的顺序。
并发测试工具:jcstress
jcstress:全名The Java Concurrency Stress tests,是一个实验工具和一套测试工具,用于帮助研究JVM、类库和硬件中并发支持的正确性。
官方github:https://github.com/openjdk/jcstress
<dependency>
<groupId>org.openjdk.jcstress</groupId>
<artifactId>jcstress-core</artifactId>
<version>${jcstress.version}</version>
</dependency>
/* I_Result为并发压测工具自带的类;
@Actor注解:表示到时候有多个线程来执行这两个方法;
@JCStressTest注解:表示用这个并发压测工具来对这个类的方法进行测试
@OutCome注解:对输出结果的处理;
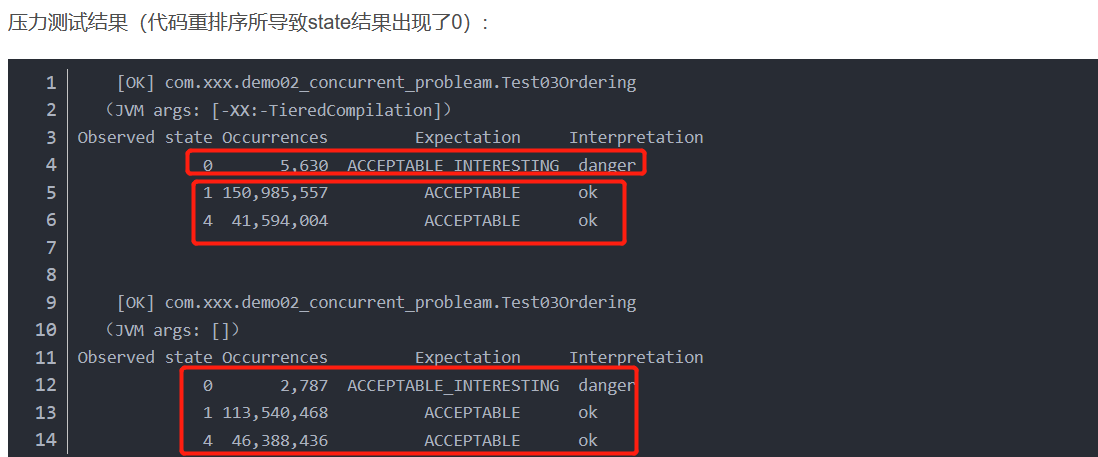
如果当id为{"1","4"}的时候,表示这种结果是我们所预期所接受的结果,则打印信息"ok";
如果程序最终I_Result当中保存的结果是0;则也认为结果是可接受感兴趣的;然后打印信息"danger"
*/
@JCStressTest
@OutCome(id = {"1" , "4"}, expect = Expect.ACCEPTABLE, desc = "ok")
@OutCome(id = 0, expect = EXPECT.ACCEPTABLE_INTERESTING, desc = "danger")
@State
public class Test03Orderliness{
int num = 0;
boolean ready = false;
/**
那么这里存在有几种情况;
分有线程A与线程B分别执行actor1(I_Result r)与actor2(I_Result r);
假设第一种情况是上面的线程A先走:r.r1 = 1
接着假设第二种情况下面的线程B先走:num=2、ready=true
接着CPU又切换到上面的线程A当中进行执行:r.r1 = 4
第三种可能性:先走线程B,执行到代码语句 num = 2时,CPU又切换到线程A中去执行;此时线程A获取得到ready变量的取值:为false;
由于是执行线程B执行到num=2;赋值完成之后但是并未执行ready=true该语句之前CPU进行切换到了线程A的操作上去了,r.r1=1
第四种可能性:由于java在编译时和运行时的优化,对actor2(I_Result r)当中的代码语句num = 2;ready = true;进行重排序。假设下面的线程B先走,执行了第一句ready = true;又切换到A线程,r.r1成员变量的取值为num+num=0;即赋值给r1的取值为0
**/
/* 线程一 执行的代码;先进行判断ready的值然后进行相关操作;
*/
@Actor
public void actor1(I_Result r){
if(ready){
r.r1 = num + num;
}else{
r.r1 = 1;
}
}
//线程二 执行的代码;对两个变量进行相应的修改;
@Actor
public void actor2(I_Result r){
num = 2;
ready = true;
}
}
#运行测试
mvn clean install;
java -jar target/jcstress.jar
2.JMM
Java 内存模型(JMM)是一种抽象概念,并不真实存在,它描述了一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段、静态字段和构成数组对象的元素)的访问方式。
它试图屏蔽各个硬件平台和操作系统的内存访问差异,以实现让Java程序在各种平台下都能达到一致的内存访问效果 。
主内存
所有线程共享的区域,存储线程共享的数据,包括实例变量、静态变量和构成数组的对象的元素,不包括局部变量和方法参数。
工作内存
每个线程独享的区域,存储主内存中的数据拷贝。
每个线程都有自己的工作内存。每个线程对共享数据的读、写操作都只在各自的工作内存中,不能直接在主内存中进行;在各自工作内存中对数据操作完成后,同步到主内存中;线程间不能访问各自工作内存中的数据,只能通过主内存来完成。
交互过程
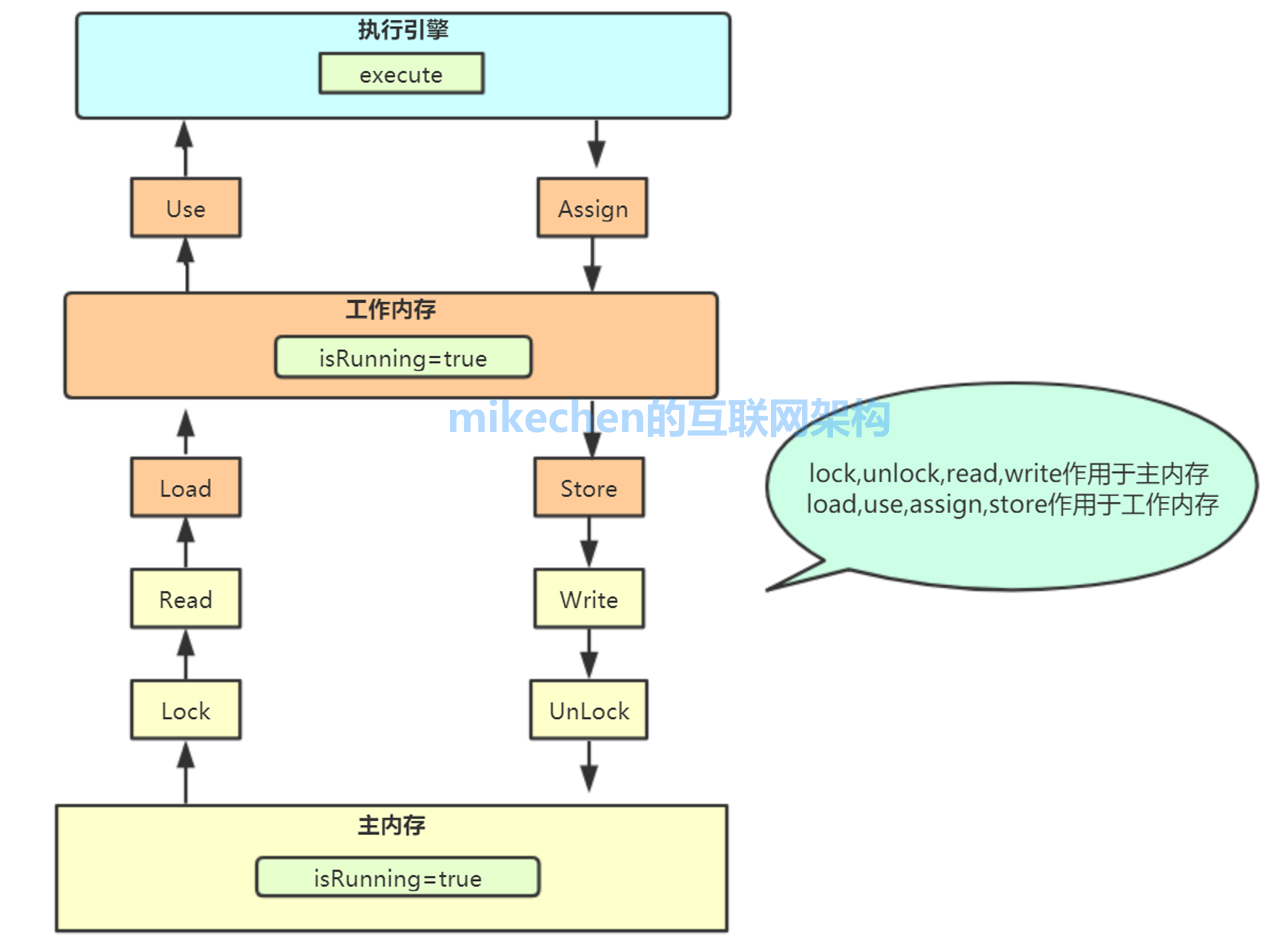
主内存和工作内存之间的交互有具体的交互协议,JMM定义了八种操作来完成,这八种操作是原子的、不可再分的,它们分别是:lock,unlock,read,load,use,assign,store,write,其中lock,unlock,read,write作用于主内存;load,use,assign,store作用于工作内存。
(1) lock:将主内存中的变量锁定,为一个线程所独占
(2) unclock:将lock加的锁定解除,此时其它的线程可以有机会访问此变量
(3) read:从主内存读取数据
(4) load:将read读取的值保存到工作内存中的变量副本中。
(5) use:将值传递给线程的代码执行引擎
(6) assign:将执行引擎处理返回的值重新赋值给变量副本
(7) store:将变量副本的值存储到主内存中。
(8) write:将store存储的值写入到主内存的共享变量当中。
- 从主存复制变量到当前工作内存(read and load)
- 执行代码,改变共享变量值 (use and assign)
- 用工作内存数据刷新主存相关内容 (store and write)
指令规则
- read 和 load、store和write必须成对出现
- assign操作,工作内存变量改变后必须刷回主内存
- 同一时间只能运行一个线程对变量进行lock,当前线程lock可重入,unlock次数必须等于lock的次数,该变量才能解锁。
- 对一个变量lock后,会清空该线程工作内存变量的值,重新执行load或者assign操作初始化工作内存中变量的值。
- unlock前,必须将变量同步到主内存(store/write操作)
3.CPU缓存
为了解决内存速度和CPU运算速度之间的不匹配, CPU厂商采用了缓存的解决方案。
缓存行(CacheLine)是位于CPU和内存中间的高速缓存。高速缓存一般分为三级,分别为L1、L2、L3。
一级缓存可分为一级指令缓存和一级数据缓存,一级指令缓存用于暂时存储并向CPU递送各类运算指令;一级数据缓存用于暂时存储并向CPU递送运算所需数据,这就是一级缓存的作用。CPU执行指令的速度非常快,所以要先预读一些指令到一级指令缓存中,如果数据和指令都放在L1中,一旦数据覆盖了指令,那么计算机将无法正确执行了,因此L1需要划分为两个区域,而L2和L3不需要参与指令的预读,所以不需要划分。
目前流行的多级缓存结构:

- 核0读取了一个字节,根据局部性原理,它相邻的字节同样被被读入核0的缓存
- 核3做了上面同样的工作,这样核0与核3的缓存拥有同样的数据
- 核0修改了那个字节,被修改后,那个字节被写回核0的缓存,但是该信息并没有写回主存
- 核3访问该字节,由于核0并未将数据写回主存,数据不同步
为了解决这个问题,CPU制造商制定了一个规则:当一个CPU修改缓存中的字节时,服务器中其他CPU会被通知,它们的缓存将视为无效。
4.局部性原理与缓存行
时间局部性:CPU读取数据时的顺序为寄存器->L1->L2->L3->内存,当从内存中读取到数据时,会一次将数据放入L3、L2、L1中,这样下次CPU再读取这个数据时直接从L1中获取,无需读取内存。CPU认为程序在短时间内有多次操作同一个数据的倾向,所以会将数据存储在高速缓存中。
空间局部性:CPU认为从内存中读取一个数据,下一次访问的很有可能是它旁边的数据,所以会进行预读取,目前工业界一次性预读取的大小一般为64Byte,这64个字节的大小一般称为缓冲行,也就是说CPU在读取数据的时候一次性读取一个缓冲行大小。
证明缓冲行的存在
例1:
package com.morris.concurrent.volatiledemo;
public class CacheLinePadding {
private static class T {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start) / 1_000_000);
}
}
//2710ms
将例1中的T类换成下面的,其余保持不变:
private static class T {
public volatile long p1, p2, p3, p4, p5, p6, p7;
public volatile long x = 0L;
public volatile long p8, p9, p10, p11, p12, p13, p14;
}
//1270ms
- 例1:arr[0].x与arr[1].x很大可能位于同一个缓存行中,这样多个核内的高速缓存中都有arr[0].x和arr[1].x的副本,当线程t1对arr[0].x进行修改时会使得其他核内的缓存行失效,导致其他线程每次对数据的操作需要从先从内存中读取,没有充分利用高速缓存,影响性能。
- 例2:变量x的前后被填充了7个long型变量,也就是前后填充了56个字节,加上x自身总共64个字节,而缓存行的大小为64个字节,这样就保证了arr[0].x与arr[1].x一定不会在同一个缓存行,当线程t1和线程t2分别对这样arr[0].x与arr[1].x进行写操作时,无需使用缓存一致性协议来保证数据的一致性,充分利用了高速缓存,所以性能有所提升。
jdk提供了@sun.misc.Contended注解来实现缓存行对齐,无需手动填充变量了,在运行时需要设置JVM启动参数-XX:-RestrictContended,使用方法如下:
private static class T {
@sun.misc.Contended
public volatile long x = 0L;
}
5.MESI缓存一致性协议
在多核CPU中,由于存在高速缓存,一个数据会在多个核的高速缓存中存在副本,当一个核中的数据发生修改时,另一个核中的数据就会发生不一致性问题,而缓存一致性协议就是为了解决CPU的高速缓存中数据不一致的问题。
缓存一致性协议的基本思想是:所有内存的传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线:缓存本身是独立的,但是内存是共享资源,所有的内存访问都要经过仲裁(同一个指令周期中,只有一个CPU缓存可以读写内存)。
CPU缓存不仅仅在做内存传输的时候才与总线打交道,而是不停在嗅探总线上发生的数据交换,跟踪其他缓存在做什么。所以当一个缓存代表它所属的处理器去读写内存时,其它处理器都会得到通知,它们以此来使自己的缓存保持同步。只要某个处理器一写内存,其它处理器马上知道这块内存在它们的缓存段中已失效。
缓存一致性协议有很多种,如MSI,MESI,MOSI,Synapse,Firefly及DragonProtocol等等。
MESI协议是当前最主流的缓存一致性协议,在MESI协议中,每个缓存行有4个状态,可用2个bit表示。
假如说当前有一个cpu去主内存拿到一个变量x的值初始为1,放到自己的工作内存中。此时它的状态就是独享状态E,然后此时另外一个cpu也拿到了这个x的值,放到自己的工作内存中。此时之前那个cpu会不断地监听内存总线,发现这个x有多个cpu在获取,那么这个时候这两个cpu所获得的x的值的状态就都是共享状态S。然后第一个cpu将自己工作内存中x的值带入到自己的ALU计算单元去进行计算,返回来x的值变为2,接着会告诉给内存总线,将此时自己的x的状态置为修改状态M。而另一个cpu此时也会去不断的监听内存总线,发现这个x已经有别的cpu将其置为了修改状态,所以自己内部的x的状态会被置为无效状态I,等待第一个cpu将修改后的值刷回到主内存后,重新去获取新的值。
MESI也会有失效的时候,缓存的最小单元是缓存行,如果当前的共享数据的长度超过一个缓存行的长度的时候,就会使MESI协议失败,此时的话就会触发总线加锁的机制,第一个线程cpu拿到这个x的时候,其他的线程都不允许去获取这个x的值。
6.CPU缓存、内存与Java内存模型的关系
对于硬件内存来说只有 寄存器、缓存内存、主内存的概念,并没有工作内存和主内存之分。
不管是 工作内存的数据 还是 主内存的数据,对于 计算机硬件来说 都会 存储在计算机主内存中,
当然也有可能 存储到CPU缓存或者寄存器中。因此总体上来说,Java内存模型和计算机硬件内存架构 是一个相互交叉的关系,是一种抽象概念划分 与 真实物理硬件的交叉。 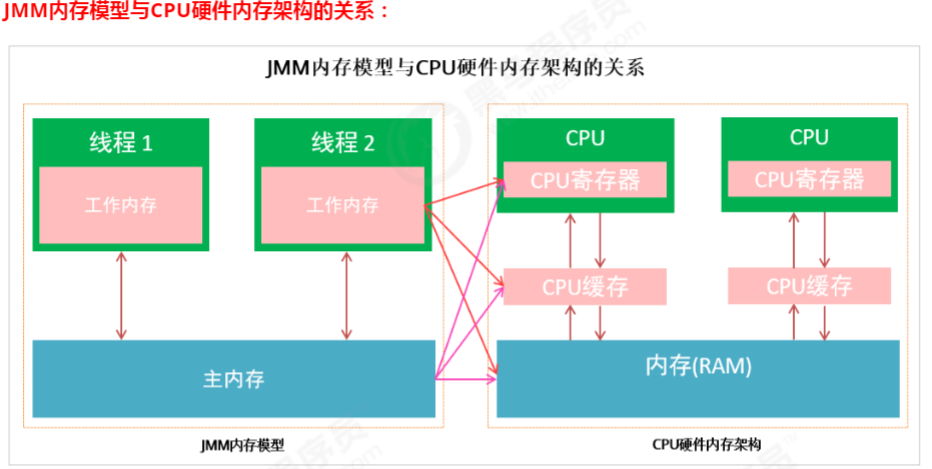
7.总线
总线是连接各个部件的一组信号线。 cpu和内存进行交互就得通过总线,它们不能隔空产生连接。总线就是一条共享的通信链路,它用一套线路来连接多个子系统。
五大类型:
数据总线(Data Bus):在CPU与RAM之间来回传送需要处理或是需要储存的数据。
地址总线(Address Bus):用来指定在RAM(Random Access Memory)之中储存的数据的地址。
控制总线(Control Bus):将微处理器控制单元(Control Unit)的信号,传送到周边设备。
扩展总线(Expansion Bus):外部设备和计算机主机进行数据通信的总线,例如ISA总线,PCI总线。
局部总线(Local Bus):取代更高速数据传输的扩展总线。
共享数据时,共享数据时,对共享数对共享数
8.happens-before原则
编译器、指令器可能对代码重排序,乱排,要守一定的规则,只要符合happens-before的原则,那么就不能胡乱重排,如果不符合这些规则的话,那可以自行排序。
(1)程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作。
(2)锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作。
(3)volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作。
volatile变量写,再是读,必须保证是先写,再读。
(4)传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C。
(5)线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作。
(6)线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生, 可以通过Thread.interrupt()方法检测到是否有中断发生。
(7)线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行。
(8)对象终结规则:一个对象的初始化完成先行发生于它的finalize()方法的开始。[
](https://blog.csdn.net/u022812849/article/details/109257860)

若有收获,就点个赞吧
0 人点赞
