什么是强化学习
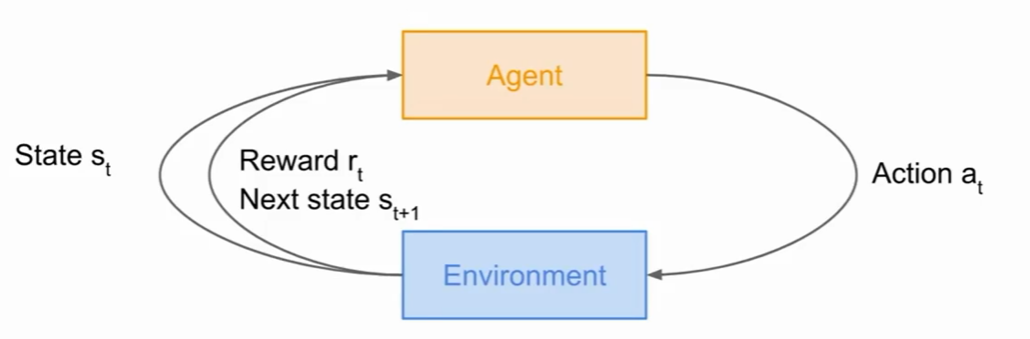
首先我们有环境和agent,环境给agent赋予一个状态s,agent根据s采取行动,环境回馈一个奖励
这个过程会持续下去。
例子:

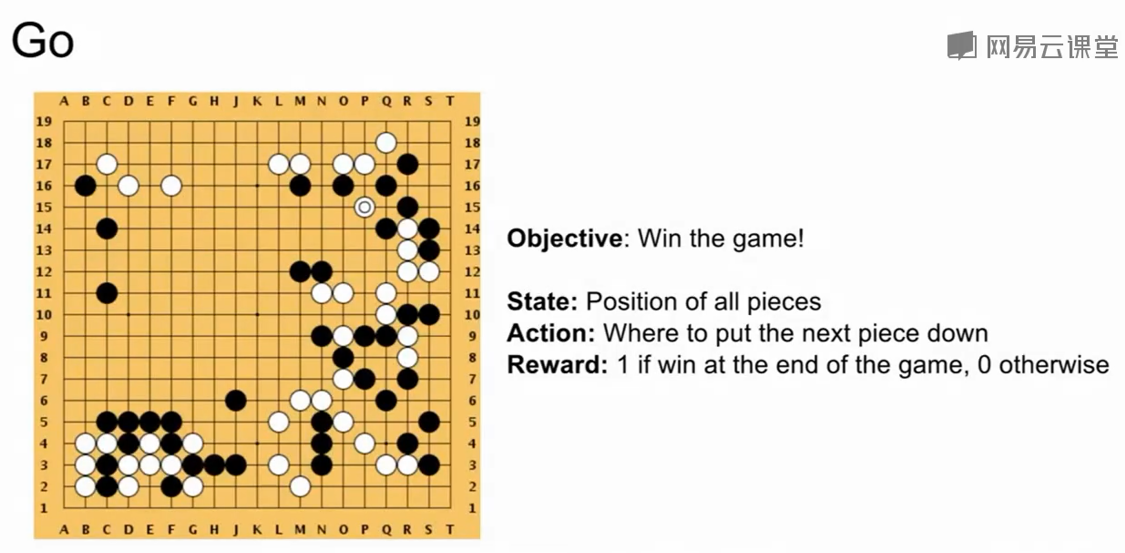
马尔可夫决策过程





Q-Learning



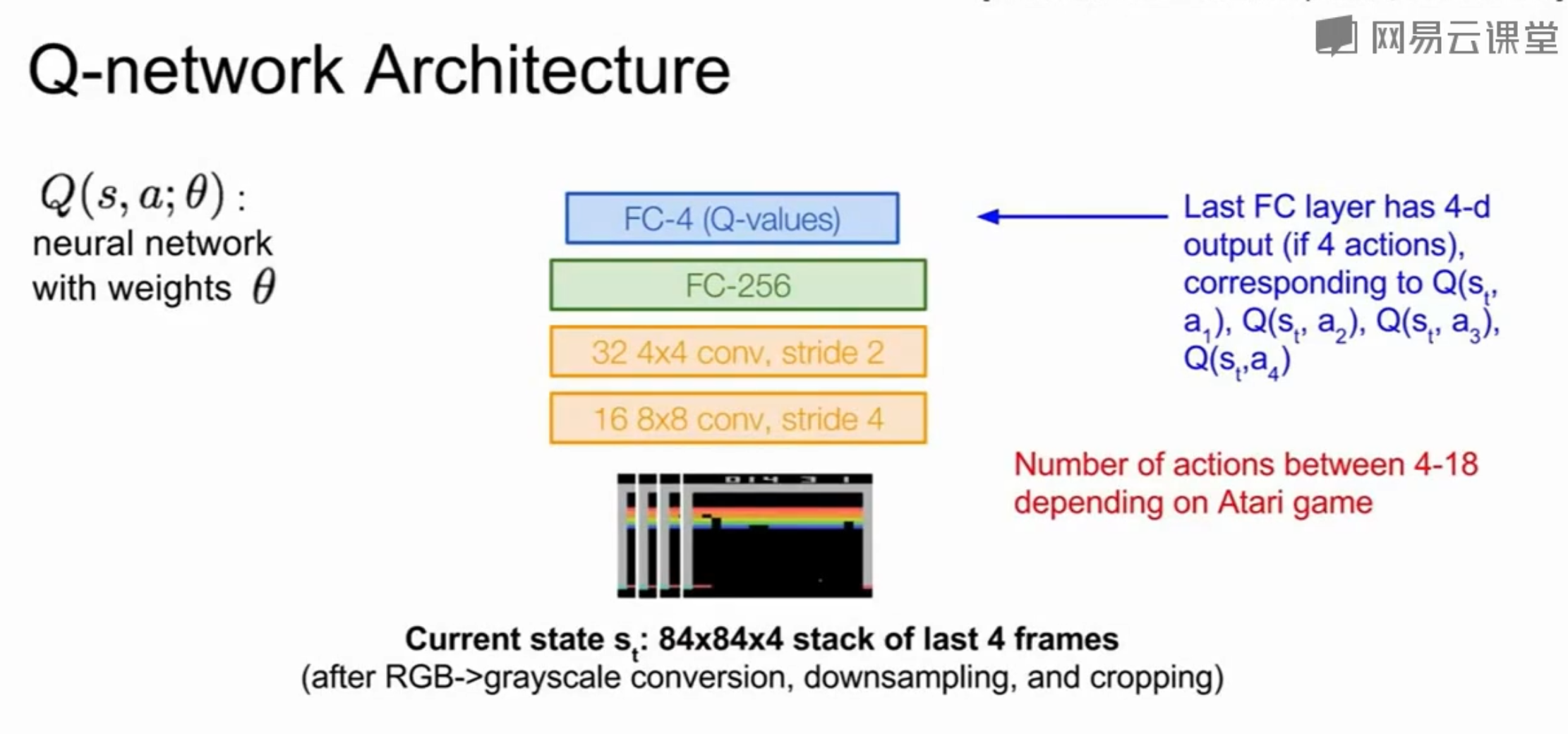
Q-Network结构
经验重放



策略梯度
Qlearning学习一大堆state,action对,但是很多情况下很复杂,策略梯度则直接学习策略。




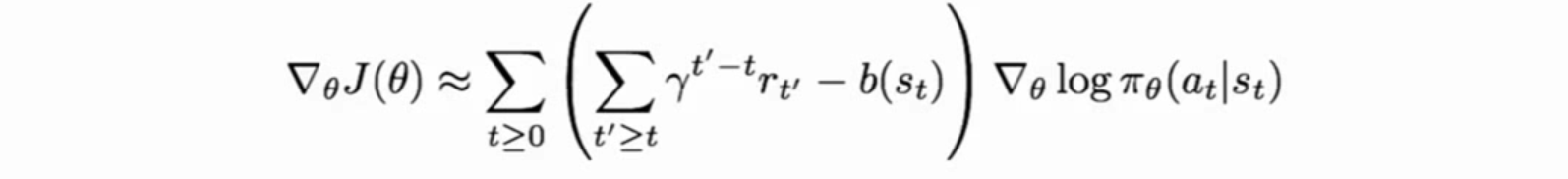

Actor-Critic Algorithm
把策略梯度和Qlearning结合起来,actor(the policy),critic(the Q-function)


若有收获,就点个赞吧
0 人点赞
