转自 https://blog.csdn.net/disanda/article/details/90744243
CIFAR 数据集是 Visual Dictionary
(Teaching computers to recognize objects) 的子集,由三个教授收集,主要来自 google 和各类搜索引擎的图片。
备注:cifar 官网
1.cifar10
由 60000 张 32*32 彩色图像组成,图像有 10 个类,每个类有 6000 个图像。分别包含有 50000 个训练图像和 10000 个测试图像。
类型如下:
2.cifar100
这个数据集和 cifar10 类似,它有 100 个类,每个类包含 600 个图像,600 个图像中有 500 个训练图像和 100 个测试图像。100 类实际是由 20 个类 (每个类又包含 5 个子类) 构成(5*20=100)。
类型如下:

3. 数据结构 (Python 版本)
- cifar10
数据格式如下:
<1×标签> <3072×像素>...<1×标签> <3072×像素>
第一个字节是第一个图像的标签,它是一个 0-9 范围内的数字。接下来的 3072 个字节是图像像素的值。前 1024 个字节是红色通道值,下 1024 个绿色,最后 1024 个蓝色。
- CIFAR-100
二进制版本与 CIFAR-10 的二进制版本相似,只是每个图像都有两个标签字节(粗略和细小)和 3072 像素字节,所以二进制文件如下所示:
<1 x粗标签> <1 x精标签> <3072 x像素>...<1 x粗标签> <1 x精标签> <3072 x像素>
def unpickle(file):import picklewith open(file, 'rb') as fo:dict = pickle.load(fo, encoding='bytes')return dictdict.keys()
4. 可视化
- pickle 模块
pickle 模块实现了基本的数据序列化和反序列化。
序列化过程将文本信息转变为二进制数据流,便于存储在硬盘之中,当需要读取文件的时候,从硬盘中读取数据。
反序列可以从文件中得到原始的数据,如字符串、列表、字典等数据。
- PIL
负责将三色像素合并为一张图片保存
- matplotlib.image
负责将单色道二维数组保存为一张图片
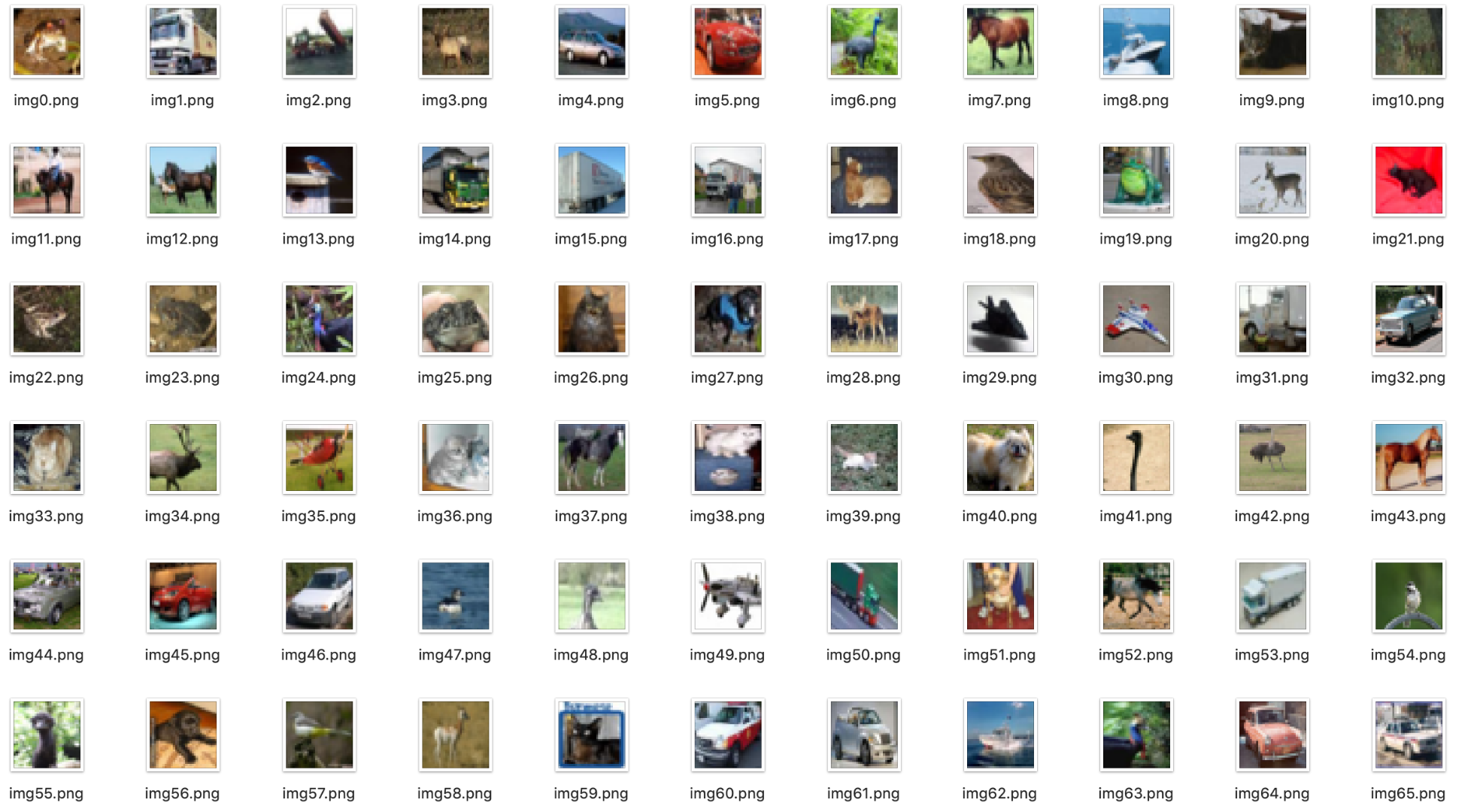
4.1 cifar10 可视化:
import numpy as np
from PIL import Image
import pickle
import os
import matplotlib.image as plimg
CHANNEL = 3
WIDTH = 32
HEIGHT = 32
data = []
labels=[]
classification = ['airplane','automobile','bird','cat','deer','dog','frog','horse','ship','truck']
for i in range(5):
with open("./cifar-10-batches-py/data_batch_"+ str(i+1),mode='rb') as file:
data_dict = pickle.load(file, encoding='bytes')
data+= list(data_dict[b'data'])
labels+= list(data_dict[b'labels'])
img = np.reshape(data,[-1,CHANNEL, WIDTH, HEIGHT])
data_path = "./pic4/"
if not os.path.exists(data_path):
os.makedirs(data_path)
for i in range(100):
r = img[i][0]
g = img[i][1]
b = img[i][2]
plimg.imsave("./pic4/" +str(i)+"r"+".png",r)
plimg.imsave("./pic4/" +str(i)+"g"+".png",g)
plimg.imsave("./pic4/" +str(i) +"b"+".png",b)
ir = Image.fromarray(r)
ig = Image.fromarray(g)
ib = Image.fromarray(b)
rgb = Image.merge("RGB", (ir, ig, ib))
name = "img-" + str(i) +"-"+ classification[labels[i]]+ ".png"
rgb.save(data_path + name, "PNG")
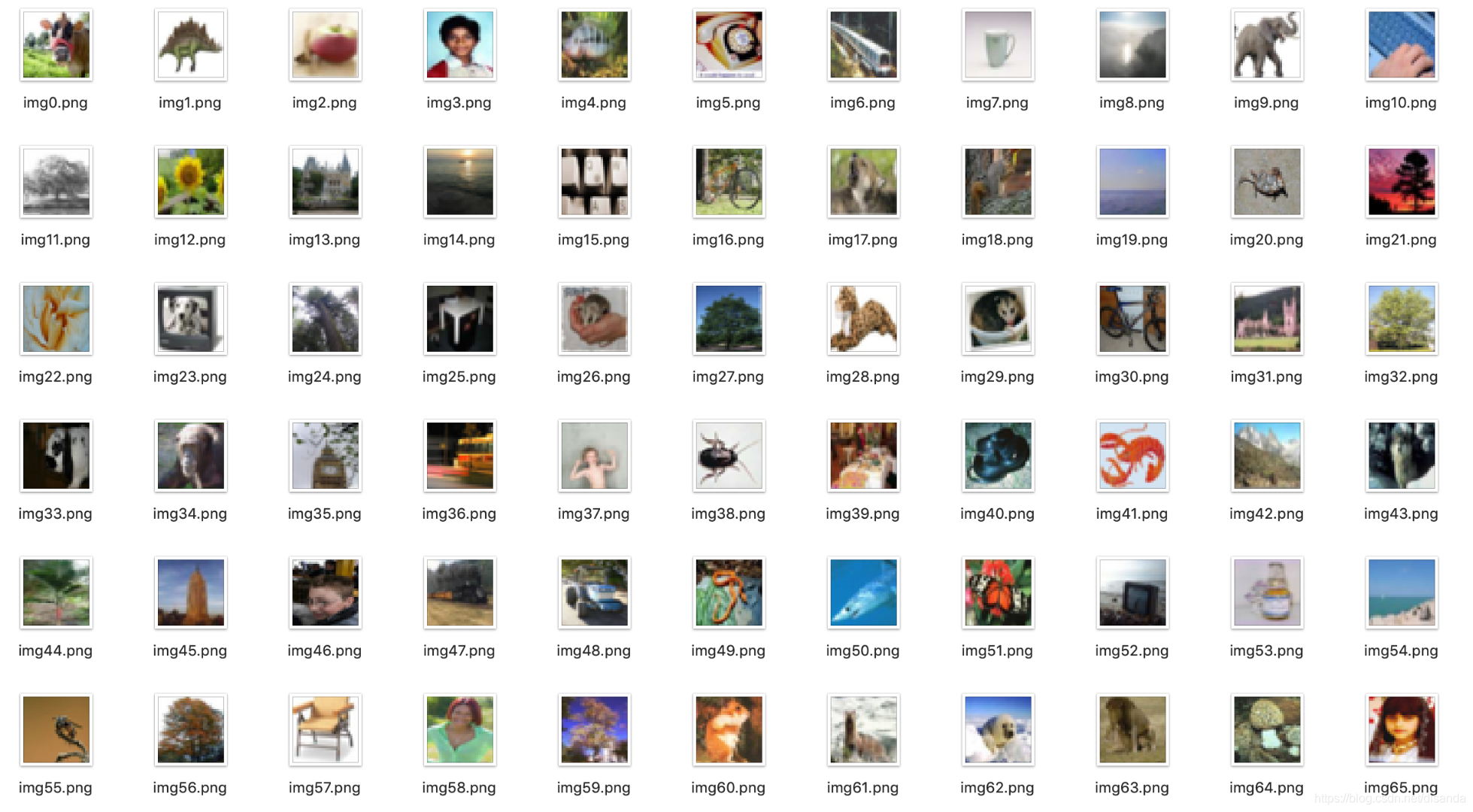
4.2 cifar100
cifar100 的文件结构和 cifar10 不同,数据只有一个文件夹里面有 50000 个图片,且有两个标签,可以从返回的 dict 的 key 查看其标签 (前文有提到)。
知道其与 cifar10 后,改写前段代码即可实现。
import pickle as p
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as plimg
from PIL import Image
def load_CIFAR_batch(filename):
""" load single batch of cifar """
with open(filename, 'rb')as f:
datadict = p.load(f,encoding='bytes')
X = datadict[b'data']
Y = datadict[b'coarse_labels']+datadict[b'fine_labels']
X = X.reshape(50000, 3, 32, 32)
Y = np.array(Y)
return X, Y
if __name__ == "__main__":
imgX, imgY = load_CIFAR_batch("./cifar-100-python/train")
print(imgX.shape)
print("正在保存图片:")
for i in range(imgX.shape[0]):
imgs = imgX[i]
if i < 100:
img0 = imgs[0]
img1 = imgs[1]
img2 = imgs[2]
i0 = Image.fromarray(img0)
i1 = Image.fromarray(img1)
i2 = Image.fromarray(img2)
img = Image.merge("RGB",(i0,i1,i2))
name = "img" + str(i)+".png"
img.save("./pic1/"+name,"png")
for j in range(imgs.shape[0]):
img = imgs[j]
name = "img" + str(i) + str(j) + ".jpg"
print("正在保存图片" + name)
plimg.imsave("./pic2/" + name, img)
print("保存完毕.")
注: 在另一个文件夹还保存了三色的单通道图

若有收获,就点个赞吧
0 人点赞
