风控模型总结 v1.0
备注:红色为重点、黄色为注意、蓝色为提醒
一、风控模型—业务+模型篇
作者:Summer Memories
链接:https://zhuanlan.zhihu.com/p/56474197
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Q:互联网金融场景下的的风控模型种类?—风控模型有哪些
- 获客阶段:用户响应模型,风险预筛选模型。
- 授信阶段:申请评分模型,反欺诈模型,风险定价模型,收益评分模型。
- 贷后阶段:行为评分模型,交易欺诈模型,客户流失模型。
- 催收阶段:早期催收模型,晚期催收模型。
Q:简单描述一下风控建模的流程?
- 前期准备工作:不同的模型针对不同的业务场景,在建模项目开始前需要对业务的逻辑和需求有清晰的理解,明确好模型的作用,项目周期时间和安排进度,以及模型效果的要求。
- 模型设计:包括模型的选择(评分卡还是集成模型),单个模型还是做模型的细分,是否需要做拒绝推论,观察期,表现期的定义,好坏用户的定义,数据的获取途径等都要确定好。
- 数据拉取及清洗:根据观察期和表现期的定义从数据池中取数,并进行前期的数据清洗和稳定性验证工作,数据清洗包括用户唯一性检查,缺失值检查,异常值检查等。稳定性验证主要考察变量在时间序列上的稳定性,衡量的指标有PSI,平均值/方差,IV等。
- 特征工程:主要做特征的预处理和筛选,如果是评分卡,需要对特征进行离散化,归一化等处理,再对特征进行降维,降维的方法有IV筛选,相关性筛选,显著性筛选等。另外会基于对业务的深入理解做特征构造工作,包括特征交叉,特征转换,对特征进行四则运算等。
- 模型建立和评估:选择合适的模型,像评分卡用逻辑回归,只需要做出二分类预测可以选择xgboost等集成模型,模型建好后需要做模型评估,计算AUC,KS,并对模型做交叉验证来评估泛化能力及模型的稳定性。
- 模型上线部署:在风控后台上配置模型规则,对于一些复杂的模型还得需要将模型文件进行转换,并封装成一个类,用Java等其他形式来调用。
- 模型监控:前期主要监控模型整体及变量的稳定性,衡量标准主要是PSI,并每日观察模型规则的拒绝率与线下的差异。后期积累一定线上用户后可评估线上模型的AUC,KS,与线下进行比较,衡量模型的线上的实际效果。
Q:评分卡,集成模型在线上是如何部署的?
- 评分卡的部署较为简单,因为评分卡将变量映射到了一个个区间及得分,所以在普通的风控决策引擎上就可配置。
- 像一些比较复杂的模型,例如xgboost和lightgbm,一般是将模型文件转换为pmml格式,并封装pmml,在风控后台上上传pmml文件和变量参数文件,并配置好模型的阈值。python模型和R模型都可以用这种方式来部署。
Q:对于金融场景,稳定胜于一切,那在建模过程中如何保证模型的稳定性?
- 在数据预处理阶段可以验证变量在时间序列上的稳定性,通过这个方法筛掉稳定性不好的变量,也能达到降维的目的。筛选的手段主要有:计算月IV的差异,观察变量覆盖率的变化,两个时间点的PSI差异等。
- 异常值的检查,剔除噪声,尤其对于逻辑回归这种对于噪声比较敏感的模型。
- 在变量筛选阶段剔除与业务理解相悖的变量,如果是评分卡,可以剔除区分度过强的变量,这种变量一般不适合放入模型中,否则会造成整个模型被这个变量所左右,造成模型的稳定性下降,过拟合的风险也会增加。
- 做交叉验证,一种是时间序列上的交叉验证,考察模型在时间上的稳定性,另一种是K折随机交叉验证,考察模型的随机稳定性。
- 选择稳定性较好的模型,例如随机森林或xgboost这类泛化能力较好的模型。
Q:为什么要做拒绝推断?常用的拒绝推断方法有哪些?
拒绝推断的目的:
- 如果只用好坏用户建模,则忽略了那些授信被拒的用户,加入拒绝用户是为了让建模样本更接近总体的分布,防止样本有偏,同时也能增加样本数量。
- 公司内部策略的变动,导致当前的申请者已不能代表建模时点的申请者,所以过去被拒的用户不一定现在也会被拒绝,因此,只使用审批通过的用户可能会造成误判。
- 做拒绝推断可以找出之前被拒的好用户,挖掘这些用户,改善风控流程,增加公司收益。
拒绝推断的适用范围:
高核准率不适合用拒绝推断,因为高核准率下好坏用户已接近于整体的申请用户。中低核准率适用用拒绝推断。
拒绝推断的常用方法:
- 硬性截断法:先用好坏用户建立初始模型,然后用这个初始模型对拒绝用户进行打分,设定一个阈值分数(根据对拒绝用户的风险容忍度),低于这个阈值的为坏用户,高于这个阈值的为好用户。再将已标记好的拒绝用户放入样本中,重新建立模型。
- 分配法:此方法适用于评分卡,先用好坏用户建立初始评分卡模型,再将样本跟据评分高低进行分组,计算各分组的违约率。然后对拒绝用户进行打分并按此前的步骤进行分组,以各分组的违约率为抽样比例,随机抽取改分组下的违约用户,指定其为坏用户,剩下的则是好用户。最后将已标记的拒绝用户加入样本中,重新建立模型。
- 平常工作中主要用到以上两种方法,个人建议做申请模型最好做一下拒绝推断,这样模型上线后的得分分布和拒绝率和线下才不会有很大的差异。
Q:模型转化为规则后决策点(cutoff点)怎么设定?
- 规则只是判断用户好坏,而不会像模型会输出违约概率,所以设定决策点时需要考虑到规则的评估指标(精准率,查全率,误伤率,拒绝率),一般模型开发前会设定一个预期的拒绝率,在这个拒绝率下再考量精确率,查全率和误伤率的取舍,找到最佳的平衡点。
- 好的模型能接受更多的好用户,拒绝掉更多的坏用户,也就是提高好坏件比例,所以可事先设定一个预期目标的好坏件比例来选择最佳的决策点。
Q:怎么做风控模型的冷启动?
风控模型的冷启动是指产品刚上线时,没有积累的用户数据,或者用户还没有表现出好坏,此时需要做模型就是一个棘手的问题,常用的方法如下:
- 不做模型,只做规则。凭借自己的业务经验,做一些硬性规则,比如设定用户的准入门槛,考量用户的信用历史和多头风险,而且可以接入第三方提供的反欺诈服务和数据产品的规则。另外可以结合人审来对用户的申请资料做风险评估。
- 借助相同模式产品的数据来建模。如果两个产品的获客渠道,风控逻辑,用户特征都差不多的话,可以选择之前已上线那个产品所积累的用户来建模,不过在模型上线后需要比较线上用户的特征是否与建模用户有较大的差异,如果差异较大,需要对模型对一些调整。
- 无监督模型+评分卡。这种方法适用于产品上线一段时间后,表现出好坏的用户比较少,但需要做一个模型出来,此时可用线上的申请用户做无监督模型,找出一部分坏样本和好样本,用这些数据来做评分卡模型,当然这种模型准确性是存疑的,需要后续对模型不断迭代优化。
- TrAdaboost(目标场景也就是新业务场景有少量标签)、JDA模型(目标场景也就是新业务场景无标签)
Q:模型上线后是怎么监控的?
前期监控(模型上线后一个月内):
- 模型最后设定cutoff点后可以得出模型的拒绝率(线下拒绝率), 上线后需要比较模型每日的拒绝率与线下拒绝率。如果两者差异较大,说明线上的用户与建模的用户分布有很大差异,原因可能是没做拒绝推断,或者用户属性随着时间发生了偏移。
- 监控模型整体的稳定性,通常用PSI来衡量两个时间点的差异程度。模型的稳定性是一个需要长期观察的指标,可绘制月/周PSI变化趋势图来分析稳定性的变化,从中可以发现用户是否随着时间推移属性发生了变化,以便及时对模型做出合理的调整。
- 变量稳定度分析,目的是如果模型的稳定性不好,可利用变量稳定度分析来了解是哪些变量造成的。对于不稳定的变量要分析其原因,并对模型做出调整,弃用不稳定的变量或者找其他变量来替换。
后期监控(用户表现出了好坏程度):
- 此时已积累了一些线上的好坏用户,可做模型的线上效果的评估,评估的指标有AUC, KS, 基尼系数,如果模型的线下效果好,但线上效果却不理想,这个模型是要做优化的。
- 好坏用户的评分分布。绘制线上好坏用户的评分分布图,如果符合期望(高分段好用户占比多,低分段坏用户占比多),则说明模型的线上的区隔能力较好。
- 变量鉴别力分析。用线上的好坏用户来计算变量的IV值,评价变量的预测能力,预测能力不好的变量可以考虑弃用。
Q:怎么设计反欺诈模型?
本人之前没做过风控的反欺诈模型,因为公司的反欺诈检测都是外包给第三方的,所以对于如何设计反欺诈模型只能给出自己的一些见解:
- 反欺诈模型不太适合用二分类监督模型来做,一是诈骗的类型很多,是一个多分类的问题,不可能只做单一类型的反欺诈模型。二是大部分数据都是没有标签的,各种监督学习模型几乎无用武之地,而且区分噪声和异常点难度很大,甚至需要一点点想象力和直觉。三是欺诈类型不断在变化,如果用历史数据建的模型来识别之前从未出现过的欺诈类型,几乎是做不到的。
- 个人觉得做模型之前需要确定两个问题,一是如何发现欺诈点,二是如何验证欺诈点。第一个问题可以用数据可视化的手段,做一下时序分析,或者用无监督学习来识别异常点。第二个问题可以用统计学的方法来验证异常点与总体是有显著性差异的,但有差异不一定就是欺诈,所以需要与领域专家进行讨论,也可以直接叫来领域专家来分析用户哪些行为是欺诈的。
- 反欺诈规则+机器学习模型来检测欺诈用户,不能单纯依靠机器学习模型来检测欺诈。规则和模型用到的变量一般有:用户的设备,位置信息,关系网络,异常操作记录和第三方黑名单等。总之反欺诈模型难度很高,有相关经验的小伙伴可以互相交流一下。
Q:当模型上线后发现稳定性不佳,或者线上的区分效果不好,你是怎么对模型作调整的?
- 模型稳定性不佳先检查当初建模时有没有考量过特征的稳定性,在模型前期监控一般会做变量的稳定性分析,如果发现稳定性不佳的变量,考虑弃用或用其他变量替代。另外可以分析下线上用户和建模用户的分布差异,考虑在建模时增加拒绝推断的步骤,让建模样本的分布更加接近于实际整体的申请用户。
- 线上的效果不好可以从变量角度分析,做一下变量鉴别度分析,剔除掉效果不好的变量,挖掘新的变量入模。如果一个模型已上线较长的时间,用户的属性也慢慢发生偏移,建议重新取数做一个新的模型替代旧模型。
Q:如何衡量一个风控模型的效果?
本人在工作中写过一个评分卡模型的评估方法,这里贴出来可以做个参考:
1.评分卡建模之前的评估:
主要评估建模样本的稳定性,根据评分卡的目的不同,比较对象为总体或者近段时间的样本。
2.分箱过程的评估
变量分箱的同时会计算WOE,这里是对WOE进行可解释性上的评估,包括变化趋势,箱体之间WOE差异,WOE绝对值大小等。
3.对逻辑回归模型的评估
- 将数据集随机划分为训练集和测试集,计算AUC, KS及Gini系数
- 通过交叉验证的方法,评估模型的泛化能力,评判指标选择AUC。
- 绘制学习曲线,评估模型是否有过拟合的风险,评判指标为准确率(Accuracy)。
4.转化评分之后的评估
- 对score进行可解释上的评估,评估原则与WOE评估大致相同。
- 绘制评分分布图,观察分布的形状及好坏用户分布的重叠程度。
- 绘制提升图和洛伦兹曲线,评估评分卡的可解释性和好坏用户区分效果。
- 评估准确性,根据对精确率和查全率的重视程度绘制PR曲线,并根据业务目标设定cutoff点。
5.评分卡上线后的评估
- 绘制评分分布表和评分分布图,计算评分的PSI,评估其稳定性。
- 评估每个入模变量的稳定性。
Q:在实际应用中,如何权衡模型的性能,可解释性和部署的难易程度?
首先要考虑到部署的难易程度,评分卡可以像普通规则一样在风控后台部署,但是像xgboost等比较复杂的模型需要考虑平台支不支持,一般来说能用评分卡解决的就最好用评分卡,部署简单而且可解释性好。然后关于可解释性和模型效果的权衡,个人认为模型的效果达到要求的情况下再去考虑可解释性,如果用评分卡做出来的效果不好,则可以考虑用集成模型或者神经网络等复杂的机器学习模型,只要你的风控后台支持部署。
Q:对于高维稀疏特征,或者是弱特征,你是怎么处理的?
- 对于高维稀疏特征,逻辑回归的效果要比GBDT好。这是由于逻辑回归的正则项是对特征权重的惩罚,以至于特征的权重不至于过大,而树模型的惩罚项主要是深度和叶子节点数目,而对于高维稀疏特征,10000个样本可能9990个值是0,那只需要一个节点就可以划分9990和剩下的10个样本,可见惩罚项之小,所以GBDT对于高维稀疏特征很容易过拟合。平时工作中如果用的是逻辑回归评分卡,则可以对稀疏特征进行离散化,离散成值为0或不为0,再用woe进行编码。而如果使用xgboost等集成模型,最好还是不要用高维的稀疏特征。
- 弱特征指的是与目标变量关系不大的特征,或者是区分能力较弱的特征。在大数据风控中弱特征的种类很多,包括社交,通话,位置等信息,而且建模时弱特征会多达数百个。如果是用评分卡建模,弱特征一般会被舍弃掉,因为评分卡的入模特征数不宜过多,一般在15个以下,所以要找寻比较强的特征。而对于xgboost等模型,本身对数据的要求不是很高,并且精度好,一些弱特征进行交叉组合或许能给模型带来不错的效果。
Q:对于成千上万维的特征你是怎么做特征筛选的,如何保证其模型的可解释性和稳定性?
- 可先做特征的粗筛选,例如缺失率高,方差为0,非常稀疏的特征可以先剔除。
- 根据变量的稳定性再次进行粗筛,衡量指标有月IV差异,两个时间点的PSI差异等。
- 根据IV值的高低筛选变量,或者直接用集成模型的特征重要性进行筛选。
- 为了保证模型的可解释性,需要将共线性的特征剔除。
- 最后考察各个特征与目标变量的关系,要求在业务上有良好的可解释能力,并且特征与目标变量的关系最好是呈单调线性变化的,这样也能保证模型的稳定性。
Q:如何根据风险因素对用户分层,构建客群差异化的模型?
做客群差异化模型之前最好做一下用户画像,在风控领域中做用户画像的目的是:
- 系统性的梳理用户群体,找到异同点对用户进行划分群体,分类的维度很多,可以是静态属性,购买偏好,也可以是褥羊毛党等风险属性。
- 便于更深刻的理解业务,理解用户需求,风控离不开业务,只有深刻理解业务后,才能发现更多潜在的风险。
- 便于后续的数据挖掘,了解坏用户的行为特征,并且根据用户特征做关联规则分析。
- 对不同类型的用户,做针对性的风控规则和风控模型。
平常工作中的做法:
- 对用户做静态属性的划分,比如按性别,年龄,收入,职业等。例如刚毕业工作的年轻人和收入比较稳定的中年人,他们的借款需求,风险程度就不一样,可以先对用户群体做这样的划分,再对每个群体单独建立模型。
- 根据用户风险属性做差异化模型,例如对手机分期业务做一个套现风险模型,挖掘套现风险属性,目标变量变成是否为套现用户。
Q:额度,利率的风险定价模型你是如何设计的?
- 首先做风险定价模型需要熟悉产品的属性和特点,像小额现金贷和大额分期贷两种产品的额度定价逻辑就不同。另外也要了解产品的盈利模式和预期的利润,这点需要与业务部门做好沟通,通常关于额度,利率也是业务或者产品制定的。
- 风险定价模型一般采用评分卡模型,最后设定cutoff点后对通过的用户进行风险等级划分,对于风险高的用户给的额度较低,或者利率较高。一般来说中低额度的用户占大部分,高额度用户占小部分,最后可以得出一个平均额度或利率,这个值事先可以根据预期的利润/资损来计算。
Q:风控流程中不同环节的评分卡是怎么设计的?
- 申请评分A卡用在贷前审核阶段,主要的作用是决定用户是否准入和对用户进行风险定价(确定额度和利率),用到的数据是用户以往的信用历史,多头借贷,消费记录等信息,并且做A卡一般需要做拒绝推断。A卡一般预测用户的首笔借款是否逾期,或者预测一段时间内是否会逾期,设计的方式也多种多样,有风险差异化评分卡,群体差异化评分卡,或者做交叉评分卡等。
- 行为B卡主要用在借贷周期较长的产品上,例如手机分期。作用一是防控贷中风险,二是对用户的额度做一个调整。用到的数据主要是用户在本平台的登录,浏览,消费行为数据,还有借还款,逾期等借贷表现数据。
- 催收C卡主要是对逾期用户做一个画像分析,通过深度挖掘用户特征,对逾期用户进行分群,做智能催收策略等。
二、风控模型—技术篇
Summer Memories
作者:Summer Memories
个人公众号:风控汪的数据分析之路
知乎专栏:小鑫的数据分析笔记
一.算法
- 逻辑回归
- 决策树
- 集成学习(随机森林,Adaboost,GBDT,XGBOOST,LightGbm)
二.特征工程
三.模型评估与优化
一. 算法
1.逻辑回归
Q : 逻辑回归的优缺点,在金融领域相比其他算法有什么优势,局限性在哪?
1)优点:
- 实现简单,速度快,占用内存小,可在短时间内迭代多个版本的模型。
- 模型的可解释性非常好,可以直接看到各个特征对模型结果的影响,可解释性在金融领域非常重要,所以在目前业界大部分使用的仍是逻辑回归模型。
- 模型客群变化的敏感度不如其他高复杂度模型,因此稳健更好,鲁棒性更强。
- 特征工程做得好,模型的效果不会太差,并且特征工程可以并行开发,大大加快开发的速度。
- 模型的结果可以很方便的转化为策略规则,且线上部署简单。
2)缺点和局限性:
- 容易欠拟合,相比集成模型,准确度不是很高。
- 对数据的要求比较高,逻辑回归对缺失值,异常值,共线性都比较敏感,且不能直接处理非线性的特征。所以在数据清洗和特征工程上会花去很大部分的时间。
- 在金融领域对场景的适应能力有局限性,例如数据不平衡问题,高维特征,大量多类特征,逻辑回归在这方面不如决策树适应能力强。
Q : 逻辑回归是线性模型吗?逻辑回归和线性回归的区别?
- 逻辑回归是一种广义线性模型,它引入了Sigmod函数,是非线性模型,但本质上还是一个线性回归模型,因为除去Sigmod函数映射关系,其他的算法原理,步骤都是线性回归的。
- 逻辑回归和线性回归首先都是广义的线性回归,在本质上没多大区别,区别在于逻辑回归多了个Sigmod函数,使样本映射到[0,1]之间的数值,从而来处理分类问题。另外逻辑回归是假设变量服从伯努利分布,线性回归假设变量服从高斯分布。逻辑回归输出的是离散型变量,用于分类,线性回归输出的是连续性的,用于预测。逻辑回归是用最大似然法去计算预测函数中的最优参数值,而线性回归是用最小二乘法去对自变量因变量关系进行拟合。
Q:逻辑回归做分类的样本应该满足什么分布?
应该满足伯努利分布,逻辑回归的分类标签是基于样本特征通过伯努利分布产生的,分类器要做的就是估计这个分布。
Q:逻辑回归解决过拟合的方法有哪些?
- 减少特征数量,在实际使用中会用很多方法进行特征筛选,例如基于IV值的大小,变量的稳定性,变量之间的相关性等。
- 正则化,常用的有L1正则化和L2正则化。
Q:什么是特征的离散化和特征交叉?逻辑回归为什么要对特征进行离散化?
- 特征离散化是将数值型特征(一般是连续型的)转变为离散特征,例如评分卡中的woe转化,就是将特征进行分箱,再将每个分箱映射到woe值上,就转换为了离散特征。特征交叉也叫作特征组合,是将单独的特征进行组合,使用相乘/相除/笛卡尔积等形成合成特征,有助于表示非线性关系。比如使用One-Hot向量的方式进行特征交叉。这种方式一般适用于离散的情况,我们可以把它看做基于业务理解的逻辑和操作,例如经度和纬度的交叉,年龄和性别的交叉等。
- 实际工作中很少直接将连续型变量带入逻辑回归模型中,而是将特征进行离散化后再加入模型,例如评分卡的分箱和woe转化。这样做的优势有以下几个:1)特征离散化之后,起到了简化模型的作用,使模型变得更稳定,降低了模型过拟合的风险。2)离散化之后的特征对异常数据有很强的鲁棒性,实际工作中的哪些很难解释的异常数据一般不会做删除处理,如果特征不做离散化,这个异常数据带入模型,会给模型带来很大的干扰。3)离散特征的增加和减少都很容易,且稀疏向量的内积乘法运算速度快,易于模型的快速迭代。4)逻辑回归属于广义线性模型,表达能力有限,特征离散化之后,每个离散变量都有单独的权重,相当于给模型引入了非线性,能够提高模型的表达能力。5)离散化后的特征可进行特征交叉,进一步引入非线性,提高模型的表达能力。
Q:在逻辑回归中,为什么要常常做特征组合(特征交叉)?
逻辑回归模型属于线性模型,线性模型不能很好处理非线性特征,特征组合可以引入非线性特征,提升模型的表达能力。另外,基本特征可以认为是全局建模,组合特征更加精细,是个性化建模,但对全局建模会对部分样本有偏,对每一个样本建模又会导致数据爆炸,过拟合,所以基本特征+特征组合兼顾了全局和个性化。
Q:做评分卡中为什么要进行WOE化?
- 更好的解释性,变量离散化之后可将每个箱体映射到woe值,而不是通常做one-hot转换。
- woe化之后可以计算每个变量的IV值,可用来筛选变量。
- 对离散型变量,woe可以观察各个level间的跳转对odds的提升是否呈线性。
- 对连续型变量,woe和IV值为分箱的合理性提供了一定的依据,也可分析变量在业务上的可解释性。
- 用woe编码可以处理缺失值问题。
Q:高度相关的特征带入逻辑回归到底有什么影响?为什么逻辑回归要将高度相关特征剔除?
- 在损失函数最终收敛的情况下,就算有很多相关度很高的特征,也不会影响模型的效果。假设一个特征将它重复100次,生成100个高度相关的特征。那么模型训练完之后,这100个特征和原来那一个特征扮演的效果一样,每一个特征的权重都是原来特征的1/100,只是可能中间很多特征的系数正负相互抵消了,比如做评分卡,如果引入了高度相关的特征,那么最后逻辑回归的系数符号可能就会不一致。
- 虽然高度相关特征对模型结果没什么大的影响,但还是要剔除相关性高的特征,原因是一个可以减少特征数量,提高模型的训练速度,减少过拟合的风险。二是去掉高相关特征可以让模型的可解释性更好。尤其在做评分卡时,为了使最后每个特征的系数符号一致,必须做特征相关性筛选。
Q:逻辑回归的特征系数的绝对值可以认为是特征的重要性吗?
首先特征系数的绝对值越大,对分类效果的影响越显著,但不能表示系数更大的特征重要性更高。因为改变变量的尺度就会改变系数的绝对值,而且如果特征是线性相关的,则系数可以从一个特征转移到另一个特征,特征间相关性越高,用系数解释变量的重要性就越不可靠。
Q:逻辑回归为什么要用极大似然函数作为损失函数?
- 数据归一到0和1,这样的话梯度下降会收敛的更快,相比不归一化,不会出现扁平的情况。
- 数据归一化之后可以提高结果的精度,尤其在与正则化同时使用时,数据归一化可以避免由于特征取值范围差距过大,对取值较小特征的参数影响更大的问题。
2.决策树
Q:决策树模型的优缺点及适用性?
优点:
- 易于理解,决策树可以生成IF..TEHN逻辑表达的树结构,可解释性很好。
- 相比逻辑回归对数据的处理较简单,不太需要做例如数据离散化,归一化等操作。
- 决策树是目前已知的对于处理非线性交互的最好的算法。
- 模型的效果比较好,例如随机森林,xgboost都是基于决策树构建的。
缺点:
- 很容易在训练过程中生成过于复杂的树结构,造成过拟合。
- 不适合处理高维数据,当属性数量过大时,部分决策树就不适用了。
- 泛化能力能力比较差,对于没有出现过的值几乎没有办法。
Q:简述一下决策树的原理以及树的构建过程。
决策树时基于树的结构进行决策的,学习过程包括特征选择,决策树的生成和剪枝过程。决策树的学习过程通常是递归地选择最优特征,并用最优特征对数据集进行分割。开始时,构建根节点,选择最优特征,该特征有几种值就划分为多少子集,每个子集递归调用此方法,返回结点,返回的结点就是上一层的子节点,直到所有特征都已经用完,或者数据集只有一维特征为止。
Q:简述一下ID3,C4.5,CART三类决策树的原理和异同点。
- ID3选择最佳分割点是基于信息增益的,信息增益越大,表明使用这个属性来划分所获得的“纯度提升”越大。C4.5对ID3进行了改进,因为ID3使用的信息增益对数据划分时,可能出现每个结点只包含一个样本,这些子节点的纯度已经达到最大,但是,这样的决策树并不具有泛化能力,无法对新样本进行预测。且ID3不能处理连续型变量和缺失值。而C4.5使用信息增益率来选择属性,克服了信息增益选择属性时偏向选择值多的属性的不足。且可以处理连续型变量和缺失值。
- C4.5是基于ID3的改进版,只能用于分类。而CART树既可以做分类,也可以做回归。CART的本质是对特征空间进行二元划分,所以CART生成的是一颗二叉树,且可以对类别型变量和数值型变量进行分裂。对分类型变量进行划分时,分为等于该属性和不等于该属性,在对连续型变量进行划分时,分为大于和小于,在做分类是使用的是GINI系数作为划分标准,在做回归时使用的是均方误差。
Q:分类树和回归树的区别在哪里?
- 分类树以C4.5为例,在对一个特征进行划分时,是穷举这个特征的每一个阈值,找到使得特征<=阈值和特征>阈值分成的两个分支的熵的最大值,按照该标准分支得到两个新的节点,用同样的方法继续分支,直到得到种类唯一的叶子节点,或者达到预设的终止条件为止。
- 回归树的流程是类似分类树的,区别在于划分时的标准不再是最大熵,而是最小化均差,如果节点的预测值错的越离谱,均方差越大,通过最小化均差能够找到最可靠的分支依据。
Q:决策树对缺失值是如何处理的?
决策树处理缺失要考虑以下三个问题:
- 当开始选择哪个属性来划分数据集时,样本在某几个属性上有缺失怎么处理:
- 忽略这些缺失的样本。
- 填充缺失值,例如给属性A填充一个均值或者用其他方法将缺失值补全。
- 计算信息增益率时根据缺失率的大小对信息增益率进行打折,例如计算属性A的信息增益率,若属性A的缺失率为0.9,则将信息增益率乘以0.9作为最终的信息增益率。
- 一个属性已经被选择,那么在决定分割点时,有些样本在这个属性上有缺失怎么处理?
- 忽略这些缺失的样本。
- 填充缺失值,例如填充一个均值或者用其他方法将缺失值补全。
- 把缺失的样本,按照无缺失的样本被划分的子集样本个数的相对比率,分配到各个子集上去,至于那些缺失样本分到子集1,哪些样本分配到子集2,这个没有一定准则,可以随机而动。
- 把缺失的样本分配给所有的子集,也就是每个子集都有缺失的样本。
- 单独将缺失的样本归为一个分支。
3.决策树模型构建好后,测试集上的某些属性是缺失的,这些属性该怎么处理?
- 如果有单独的缺失值分支,依据此分支。
- 把待分类的样本的属性A分配一个最常出现的值,然后进行分支预测。
- 待分类的样本在到达属性A结点时就终止分类,然后根据此时A结点所覆盖的叶子节点类别状况为其分配一个发生概率最高的类。
Q:为什么决策树不需要对数据做归一化等预处理?
决策树是一种概率模型,所以不需要做归一化,因为它不关心变量的值,而是关心变量的分布和变量之间的条件概率,所以归一化这种数值缩放,不影响分裂结点位置。
Q:如何解决决策树的过拟合问题?
- 预剪枝的方法:通过提前停止树的构建而对树剪枝,是目前解决过拟合的主要方法。常用的剪枝条件包括限制树的深度,限制叶节点最小样本数,限制叶节点的最小样本权重,限制叶节点的信息增益值的阈值等。
- 后剪枝的方法:首先构造完整的决策树,允许树过度拟合数据,然后应单个结点代替子树,节点的分类采用子树的主要分类。剪枝方法有错误率降低剪枝,悲观错误剪枝,代价复杂度剪枝
3.集成学习
Q:什么是集成学习?集成学习有哪些框架?简单介绍各个框架的常用算法。
- 集成学习是一种优化手段和策略,通常是结合多个简单的弱分类器来集成模型组,去做更可靠的决策。一般的弱分类器可以是决策树,SVM,kNN等构成,其中的模型可以单独来训练,并且这些弱分类器以某种方式结合在一起去做出一个总体预测。集成学习就是找出哪些弱分类器可以结合在一起,以及如何结合的方法。目前集成学习主要有bagging,boosting,stacking三种:
- bagging:对训练集进行随机子抽样,对每个子训练集构建基模型,对所有的基模型的预测结果进行综合产生最后的预测结果。如果是分类算法,则用多数投票法确定最终类别,如果是回归算法,则将各个回归结果做算术平均作为最终的预测值。常用的bagging算法:随机森林
- boosting:训练过程为阶梯状,基模型按照次序进行训练(实际上可以做到并行处理),先给定一个初始训练数据,训练出第一个基模型,根据基模型的表现对样本进行调整,在之前基模型预测错误的样本上投入更多的关注,然后用调整后的样本训练下一个基模型,重复上述过程N次,将N个基模型进行加权结合,输出最后的结果。常用的算法有GBDT,XGBOOST等。
- stacking:是一种组合分类器的方法,以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为训练集进行再训练(一般用LR进行回归组合),从而得到完整的stacking模型。要得到stacking模型,关键在于如何构造第二层的特征,构造第二层特征的原则是尽可能的避免信息泄露,因此对原始训练集常常采用类似于K折交叉验证的划分方法。各个基模型要采用相同的Kfold,这样得到的第二层特征的每一折(对应于之前的K折划分)都将不会泄露进该折数据的目标值信息 ,从而尽可能的降低过拟合的风险。
Q : 简单描述一下模型的偏差和方差?bagging和boosting主要关注哪个?
- 偏差描述的是预测值与真实值的差距,偏差越大,越偏离真实数据。
- 方差描述的是预测值的变化范围,离散程度,方差越大,数据分布越分散。
- bagging主要关注的是降低方差,boosting主要关注降低偏差。
随机森林
Q:简述一下随机森林的原理,随机森林的构造过程。
随机森林是bagging算法的代表,使用了CART树作为弱分类器,将多个不同的决策树进行组合,利用这种组合来降低单棵决策树的可能带来的片面性和判断不准确性。对于普通的决策树,是在所有样本特征中找一个最优特征来做决策树的左右子树划分,而随机森林会先通过自助采样的方法(bootstrap)得到N个训练集,然后在单个训练集上会随机选择一部分特征,来选择一个最优特征来做决策树的左右子树划分,最后得到N棵决策树,对于分类问题,按多数投票的准则确定最终结果,对于回归问题,由多棵决策树的预测值的平均数作为最终结果。随机森林的随机性体现在两方面,一个是选取样本的随机性,一个是选取特征的随机性,这样进一步增强了模型的泛化能力。
Q:随机森林的优缺点?
优点:
- 训练可以高度并行化,训练速度快,效率高。
- 两个随机性的引入,使得随机森林不容易过拟合,具有很好的抗噪声能力。
- 由于每次不再考虑全部的特征属性,二是特征的一个子集,所以相对于bagging计算开销更小,效率更高。
- 对于数据的适应能力强,可以处理连续型和离散型的变量,数据无需规范化。
- 可以输出变量的重要程度,被认为是一种不错的降维方法。
缺点:
- 在某些噪声较大的分类问题和或回归问题上容易过拟合。
- 模型的可解释性比较差,无法控制模型内部的运行。
- 对于小数据或者低维数据,效果可能会不太好。
Q:随机森林为什么不容易过拟合?
随机森林由很多棵树组合在一起,单看每一棵树可以是过拟合的,但是既然是过拟合,就会拟合到非常小的细节,随机森林通过引入随机性,让每一棵树过拟合的细节不同,再将这些树组合在一起,过拟合的部分就会抵消掉,不过随机森林还是可能会出现过拟合的现象,只是出现的概率相对较低。
Q:随机森林输出特征重要性的原理?
- 随机森林对于特征重要性的评估思想:判断每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。其中关于贡献的计算方式可以是基尼指数或袋外数据错误率。
- 基于基尼系数:如果特征X出现在决策树J中的结点M,则计算节点M分枝前后的Gini指数变化量,假设随机森林由N棵树,则计算N次的Gini系数,最后将所有的Gini系数做一个归一化处理就得到了该特征的重要性。
- 基于袋外数据错误率:袋外数据指的是每次随机抽取未被抽取达到的数据,假设袋外的样本数为O,将这O个数据作为测试集,代入已生成好的随机森林分类器,得到预测的分类结果,其中预测错误的样本数为X,则袋外数据误差为X/O,这个袋外数据误差记为errOOB1,下一步对袋外数据的特征A加入噪声干扰,再次计算袋外误差errOOB2,假设随机森林由N个分类器,则特征A的重要性为:sum(errOOB2-errOOB1)/N,其依据就是,如果一个特征很重要,那么其变动后会非常影响测试误差,如果测试误差没有怎么改变,则说明特征A不重要。
Adaboost
Q:简单描述一下Adaboost的算法原理和流程。
- Adaboost基于分类器的错误率分配不同的权重系数,最后得到累加加权的的预测结果。
算法流程:
- 给数据中每一个样本一个权重,若有N个样本,则每个样本的权重为1/N.
- 训练数据的每一个样本,得到第一个分类器。
- 计算该分类器的错误率,根据错误率计算给分类器分配的权重。
- 将第一个分类器分错的样本权重增加,分对的样本权重减少,然后再用新的样本权重训练数据,得到新的分类器。
- 迭代这个训练步骤直到分类器错误为0或达到迭代次数。
- 将所有的弱分类器加权求和,得到分类结果(分类器权重),错误率低的分类器获得更高的决定系数,从而在数据进行预测起关键作用。
Q:Adaboost的优点和缺点?
优点:
- 分类精度高,构造简单,结果可理解。
- 可以使用各种回归分类模型来构建弱学习器,非常灵活。
- 不容易过拟合。
缺点:
- 训练时会过于偏向分类困难的数据,导致Adaboost容易受噪声数据干扰。
- 依赖于弱分类器,训练时间可能比较长。
GBDT
Q:简单说一下GBDT的原理。
- GBDT是boosting的一种方法,主要思想是每一次建立单个分类器时,是在之前建立的模型的损失函数的梯度下降方向。损失函数越大,说明模型越容易出错,如果我们的模型能让损失函数持续的下降,则说明我们的模型在持续不断的改进,而最好的方式就是让损失函数在其梯度的方向上下降。
- GBDT的核心在于每一棵树学的是之前所有树结论和的残差,残差就是真实值与预测值的差值,所以为了得到残差,GBDT中的树全部是回归树,之所以不用分类树,是因为分类的结果相减是没有意义的。
- Shrinkage(缩减)是 GBDT 的一个重要演进分支,Shrinkage的思想在于每次走一小步来逼近真实的结果,要比直接迈一大步的方式更好,这样做可以有效减少过拟合的风险。它认为每棵树只学到了一小部分,累加的时候只累加这一小部分,通过多学习几棵树来弥补不足。这累加的一小部分(步长*残差)来逐步逼近目标,所以各个树的残差是渐变的而不是陡变的。
- GBDT可以用于回归问题(线性和非线性),也可用于分类问题。
Q:为什么对于高维稀疏特征不太适合用GBDT?
- GBDT在每一次分割时需要比较大量的特征,特征太多,模型训练很耗费时间。
- 树的分割往往只考虑了少部分特征,大部分的特征都用不到,所有的高维稀疏的特征会造成大量的特征浪费。
Q:GBDT和随机森林的异同点?
相同点:
- 都是由多棵树构成,最终的结果也是由多棵树决定。
不同点:
- 随机森林可以由分类树和回归树组成,GBDT只能由回归树组成。
- 随机森林的树可以并行生成,而GBDT只能串行生成,所以随机森林的训练速度相对较快。
- 随机森林关注减小模型的方差,GBDT关注减小模型的偏差。
- 随机森林对异常值不敏感,GBDT对异常值非常敏感。
- 随机森林最终的结果是多数投票或简单平均,而GBDT是加权累计起来。
Q:GBDT的优缺点?
优点:
- GBDT每一次的残差计算都增大了分错样本的权重,而分对的权重都趋近于0,因此泛化性能比较好。
- 可以灵活的处理各种类型的数据。
缺点:
- 对异常值比较敏感。
- 由于分类器之间存在依赖关系,所以很难进行并行计算。
XGBOOST
Q : 简单介绍一下XGBOOST。
XGBOOST是一种梯度提升的算法,用来解决分类和回归问题。它的基学习器可以是CART树,也可以是线性分类器。当用CART树做基学习器时,训练的时候采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差。XGBoost对GBDT进行了一系列优化,比如损失函数进行了二阶泰勒展开、目标函数加入正则项、特征粒度上支持并行计算和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升。
Q:XGBOOST和GBDT的区别在哪里?
- 传统的GBDT是以CART树作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题),线性分类器的速度是比较快的,这时候xgboost的速度优势就体现了出来。
- 传统的GBDT在优化时只使用一阶导数,而xgboost对损失函数做了二阶泰勒展开,同时用到了一阶和二阶导数,并且xgboost支持使用自定义损失函数,只要损失函数可一阶,二阶求导。
- xgboost在损失函数里加入了正则项,用来减小模型的方差,防止过拟合,正则项里包含了树的叶节点的个数, 每个叶子节点上输出的score的L2模的平方和。
- xgboost里有一个参数叫学习速率(learning_rate), xgboost在进行完一次迭代后,会将叶子节点的权重乘上学习速率,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把learing_rate设置得小一点,然后迭代次数(n_estimators)设置得大一点。
- xgboost借鉴了随机森林的原理,支持行抽样(subsample)和列抽样(colsample_bytree,colsample_bylevel), 行抽样指的是随机森林里对数据集进行有放回抽样,列抽样指的是对特征进行随机选择,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
Q:为什么XGBOOST要用泰勒展开,优势在哪里?
xgboost使用了一阶和二阶偏导,二阶导数有利于梯度下降的更快更准,使用泰勒展开取得函数做自变量的二阶导数形式,可以在不选定损失函数具体形式的情况下,仅仅依靠输入数据的值就可以进行叶子分裂优化计算,本质上也就把损失函数的选取和模型算法的优化分开来了,这种去耦合增加了xgboost的适用性,使得它按需选取损失函数,既可以用于分类,也可以用于回归。
Q:XGBOOST是如何寻找最优特征的?
xgboost在训练过程中给出各个特征的增益评分,最大增益的特征会被选出来作为分裂依据,从而记忆了每个特征在模型训练时的重要性,从根到叶子中间节点涉及某特征的次数作为该特征重要性排序。
Q:XGBOOST是如何处理缺失值的?
xgboost为缺失值设定了默认的分裂方向,xgboost在树的构建过程中选择能够最小化训练误差的方向作为默认的分裂方向,即在训练时将缺失值划入左子树计算训练误差,再划入右子树计算训练误差,然后将缺失值划入误差小的方向。
Q:XGBOOST的并行化是如何实现的?
- xgboost的并行不是在tree粒度上的并行,xgboost也是一次迭代完才能进行下一次迭代(第t次迭代的损失函数包含了第t-1次迭代的预测值),它的并行处理是在特征粒度上的,在决策树的学习中首先要对特征的值进行排序,然后找出最佳的分割点,xgboost在训练之前,就预先对数据做了排序, 然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
Q:XGBOOST采样时有放回的还是无放回的?
xgboost属于boosting方法的一种,所以采样时样本是不放回的,因而每轮计算样本不重复,另外,xgboost支持子采样,每轮计算可以不使用全部的样本,以减少过拟合。另外一点是xgboost还支持列采样,每轮计算按百分比随机抽取一部分特征进行训练,既可以提高速度又能减少过拟合。
Q:XGBOOST的调参步骤是怎样的?
PS:这里使用Gridsearch cv来穷举检索最佳的参数,如果时间允许,可以通过设置步数先粗调,再细调。
- 保持learning rate和其他booster相关的参数不变,调节和estimators的参数。learing_rate可设为0.1, max_depth设为4-6之间,min_child_weight设为1,subsample和colsample_bytree设为0.8 ,其他的参数都设为默认值即可。
- 调节max_depth 和 min_child_weight参数,首先,我们先大范围地粗调参数,然后再小范围地微调。
- gamma参数调优
- subsample和colsample_bytree 调优
- 正则化参数调优,选择L1正则化或者L2正则化
- 缩小learning rate,得到最佳的learning rate值
Q:XGBOOST特征重要性的输出原理?
xgboost是用getscore方法输出特征重要性的,其中importance_type参数_支持三种特征重要性的计算方法:
- importancetype=_weight(默认值),使用特征在所有树中作为划分属性的次数。
- importancetype=_gain,使用特征在作为划分属性时loss平均的降低量。
- importancetype=_cover,使用特征在作为划分属性时对样本的覆盖度。
LightGbm
Q:LightGBM相比XGBOOST在原理和性能上的差异?
1.速度和内存上的优化:
- xgboost用的是预排序(pre-sorted)的方法, 空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如排序后的索引,为了后续快速的计算分割点),这里需要消耗训练数据两倍的内存。 其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
- LightGBM用的是直方图(Histogram)的决策树算法,直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
2.准确率上的优化:
- xgboost 通过level(depth)-wise策略生长树, Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
- LightGBM通过leaf-wise(best-first)策略来生长树, Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。Leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
3.对类别型特征的处理:
- xgboost不支持直接导入类别型变量,需要预先对类别型变量作亚编码等处理。如果类别型特征较多,会导致哑变量处理后衍生后的特征过多,学习树会生长的非常不平衡,并且需要非常深的深度才能来达到较好的准确率。
- LightGBM可以支持直接导入类别型变量(导入前需要将字符型转为整数型,并且需要声明类别型特征的字段名),它没有对类别型特征进行独热编码,因此速度比独热编码快得多。LightGBM使用了一个特殊的算法来确定属性特征的分割值。基本思想是对类别按照与目标标签的相关性进行重排序,具体一点是对于保存了类别特征的直方图根据其累计值(sum_gradient/sum_hessian)重排序,在排序好的直方图上选取最佳切分位置。
二. 特征工程
Q:什么是特征工程?为什么特征工程对机器学习很重要?
- 特征工程指的是使用专业知识和技巧来处理数据,使得特征在机器学习算法上发挥更好的作用的过程。这个过程包含了数据预处理,特征构建,特征筛选等。特征工程的目的就是筛选出好的特征,得到更好的训练数据,使模型达到更好的效果。
- 从数据中提取出来的特征好坏会直接影响到模型的效果,有的时候,如果特征工程做得好,仅使用一些简单的机器学习算法,也能达到很好的效果。由此可见特征工程在实际的机器学习中的重要性。
Q:特征工程的一般步骤是什么?什么是特征工程的迭代?
特征工程常规步骤:
- 数据获取,数据的可用性评估(覆盖率,准确率,获取难度)
- 探索性数据分析,对数据和特征有一个大致的了解,同时进行数据的质量检验,包括缺失值,异常值,重复值,一致性,正确性等。
- 特征处理,包括数据预处理和特征转换两部分,数据预处理主要做清洗工作(缺失值,异常值,错误值,数据格式),特征转换即对连续特征,离散特征,时间序列特征进行转换,便于入模。
- 特征构建,特征构建的目的是找寻与目标变量相关且区分度较好的特征。常用的方法有特征交叉,四则运算,基于业务理解进行头脑风暴构建特征等。
- 特征筛选,大量的特征中选择少量的有用特征,也叫作特征降维,常用的方法有过滤法,包装法,嵌入法。
特征工程的迭代:
- 选择特征:具体问题具体分析,通过查看大量的数据和基于对业务的理解,从数据中查找可以提出出数据的关键。
- 设计特征:可以自动进行特征提取工作,也可以手工进行特征的构建。
- 选择特征:使用不同的特征构造方法,从多个角度来评判这个特征是否适合放入模型中。
- 计算模型:计算模型在该特征上所提升的准确率。
- 上线测试:通过在线测试的效果来评估特征是否有效。
Q:常用的特征工程方法有哪些?
- 特征处理:数据的预处理包括异常值和缺失值,要根据实际的情况来处理。特征转换主要有标准化,归一化,区间缩放,二值化等,根据特征类型的不同选择合适的转换方法。
- 特征构建:特征之间的四则运算(有业务含义),基于业务理解构造特征,分解类别特征,特征交叉组合等。
- 特征筛选:过滤法,封装法,嵌入法。
Q:在实际的风控建模中怎么做好特征工程?
本人工作中的一些经验总结:
- 因为做风控模型大部分的数据源来自第三方,所以第三方数据的可用性评估非常重要,一方面需要了解这些特征底层的衍生逻辑,判断是否与目标变量相关。另一方面考察数据的覆盖率和真实性,覆盖率较低和真实性存疑的特征都不能使用在模型中。
- 基于金融的数据特点,在特征筛选这个步骤上考量的因素主要有:一个是时间序列上的稳定性,衡量的指标可以是PSI,方差或者IV。一个是特征在样本上覆盖率,也就是特征的缺失率不能太高。另外就是特征的可解释性,特征与目标变量的关系要在业务上要解释的通。
- 如果第三方返回有用户的原始底层数据,例如社保的缴纳记录,运营商的通话/短信记录,则需要在特征衍生上多下功夫,基于自身对数据的敏感性和业务的理解,构建具有金融,风险属性的特征,也可以与业务部门进行沟通找寻与业务相关的特征。
Q:实际项目中原始数据通常有哪些问题?你是如何解决的?
- 一些特征的底层逻辑不清晰,字面上的意思可能与实际的衍生逻辑相悖,这个需要与第三方数据供应商进行沟通,了解清楚特征的衍生逻辑。
- 数据的真实性可能存在问题。比如一个特征是历史总计,但第三方只是爬取了用户近2年的数据,这样的特征就不符合用户的真实情况。所以对数据的真实性校验显得非常重要。
- 有缺失的特征占的比例较高。在进行缺失值处理前先分析缺失的原因,而不是盲目的进行填充,删除等工作。另外也要分析缺失是否有风险属性,例如芝麻分缺失的用户相对来说风险会较高,那么缺失可以当做一个类别来处理。
- 大量多类特征如何使用。例如位置信息,设备信息这些特征类别数较多,如果做亚编码处理会造成维度灾难,目前常用的方法一个是降基处理,减少类别数,另一个是用xgboost来对类别数做重要性排序,筛选重要性较高的类别再做亚编码处理。
Q:在做评分卡或其他模型中,怎么衡量特征(数据)的有用性?
- 特征具有金融风险属性,且与目标变量的关系在业务上有良好的可解释性。
- 特征与目标变量是高度相关的,衡量的指标主要是IV。
- 特征的准确率,这个需要了解特征的衍生逻辑,并与实际一般的情况相比较是否有异常。
- 特征的覆盖率,一般来说覆盖率要达到70%以上。
- 特征的稳定性,特征的覆盖率,分布,区分效果在时间序列上的表现比较稳定。
- 特征的及时性,最好是能代表用户最近的信用风险情况。
Q:为什么探索性数据分析(EDA)在机器学习中非常重要?
- EDA不单是看看数据的分布,而是对数据整体有一个大概的了解。通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律。从中发现关键性的价值信息,这些信息对于后续建模及对模型的正确理解有很重要的意义。
- 通过EDA可以发现数据的异常,可以分析每个特征与目标变量之间的关系,特征与特征之间的关系,为特征构建和特征筛选提供有价值的信息。
- EDA分析可以验证数据是不是你认为的那样,实际情况中由于数据和特征量比较大,往往忽视这些数据是如何生成的,数据突出的问题或模型的实施中的错误会被长时间忽视,这可能会导致基于错误信息做出决策。
Q:缺失值的处理方式有哪些?风控建模中该如何合理的处理缺失?
- 首先要了解缺失产生的原因,因数据获取导致的缺失建议用填充的方式(缺失率比较低的情况下),因用户本身没有这个属性导致的缺失建议把缺失当做一个类别。另外可以分析缺失是否有风险属性,有的话最好当做一个类别来处理。
- 风控模型对于缺失率的要求比较高,尤其是评分卡。个人认为,缺失率在30%以上的特征建议不要用,缺失率在10%以下的变量可用中位数或随机森林来填充,10%-30%的缺失率建议当做一个类别。对于xgboost和lightgbm这类可以自动处理缺失值的模型可以不做处理。
Q:如何发现数据中的异常值?对异常值是怎么处理的?
- 一种是基于统计的异常点检测算法例如极差,四分位数间距,均差,标准差等,这种方法适合于挖掘单变量的数值型数据。另一种主要通过距离方法来检测异常点,将数据集中与大多数点之间距离大于某个阈值的点视为异常点,检测的标准有欧式距离,绝对距离。
- 对于异常值先检查下是不是数据错误导致的,数据错误的异常作删除即可。如果无法判别异常的原因,要根据实际情况而定,像评分卡会做WOE转换,所以异常值的影响不大,可以不做处理。若异常值的数量较多,建议将异常值归为一类,数量较少作删除也可以。
Q:对于时间序列特征,连续特征,离散特征这三类是怎么做特征转换的?
- 时间序列特征:将时间变量的维度进行分离(年/月/日/时/分/秒),或者与位置变量进行结合衍生成新的特征。
- 连续型特征:标准化,归一化,区间缩放,离散化。在评分卡中主要用的是离散化,离散化常用的方法有卡房分箱,决策树分箱,等频和等深分箱。
- 离散型特征:如果类别数不是很多,适合做亚编码处理,对于无序离散变量用独热编码,有序离散变量用顺序编码。如果类别数较多,可用平均数编码的方法。
Q:如何处理样本不平衡的问题?
- 在风控建模中出现样本不平衡主要是坏样本的数量太少,碰到这个问题不要急着试各种抽样方法,先看一下坏用户的定义是否过于严格,过于严格会导致坏样本数量偏少,中间样本偏多。坏用户的定义一般基于滚动率分析的结果,不过实际业务场景复杂多样,还是得根据情况而定。
- 确定好坏用户定义是比较合理的之后,先尝试能不能扩大数据集,比如一开始取得是三个月的用户数据,试着将时间线延长来增加数据。因为机器学习是使用现在的数据在整个数据分布上进行估计,因此更多的数据往往能够得到更多的分布信息,以及更好的分布估计。
- 对数据集进行抽样,一种是进行欠采样,通过减少大类的数据样本来降低数据的不平衡,另一种是进行过采样,通过增加小类数据的样本来降低不平衡,实际工作中常用SMOTE方法来实现过采样。
- 尝试使用xgboost和lightgbm等对不平衡数据处理效果较好的模型。
- 尝试从新的角度来理解问题,可以把那些小类样本当做异常点,因此该分类问题转化为异常检测问题或变化趋势检测问题,这种方法笔者很少用到,就不详细说明了。
Q:特征衍生的方法有哪些?说说你平时工作中是怎么做特征衍生的?
常规的特征衍生方法:
- 基于对业务的深入理解,进行头脑风暴,构造特征。
- 特征交叉,例如对类别特征进行交叉相乘。
- 分解类别特征,例如对于有缺失的特征可以分解成是否有这个类别的二值化特征,或者将缺失作为一个类别,再进行亚编码等处理。
- 重构数值量(单位转换,整数小数拆分,构造阶段性特征)
- 特征的四则运算,例如取平均/最大/最小,或者特征之间的相乘相除。
平时工作特征衍生的做法:
- 因为风控模型通常需要好的解释能力,所以在特征衍生时也会考虑到衍生出来的特征是否与目标变量相关。例如拿到运营商的通话记录数据,可以衍生一个”在敏感时间段(深夜)的通话次数占比”,如果占比较高,用户的风险也较大。
- 平常会将大量的时间和精力花在底层数据的衍生上,这个不仅需要对业务的理解,也需要一定的想象力进行头脑风暴,即使衍生出来的特征90%都效果不佳,但只要剩下的10%是好的特征,那对于模型效果的提升是很显著的。
- 对于评分卡来说,特征需要好的解释能力,所以一些复杂的衍生方法,像特征交叉,log转换基本不会用到。但如果是xgboost等复杂模型,进行特征交叉等方法或许有比较好的效果。
Q:特征筛选的作用和目的?筛选的特征需要满足什么要求?
作用和目的:
- 简化模型,增加模型的可解释性, 降低模型过拟合的风险。
- 缩短模型的训练时间。
- 避免维度灾难。
筛选特征满足的要求:
- 具有良好的区分能力。
- 可解释性好,与目标变量的关系在业务上能解释的通。
- 在时间序列上有比较好的稳定性。
- 特征的用户覆盖率符合要求。
Q:特征筛选的方法有哪些?每种方法的优缺点?实际工作中用到了哪些方法?
Filter(过滤法):按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- 相关系数,方差(适用于连续型变量),卡方检验(适用于类别型变量),信息熵,IV。实际工作中主要基于IV和相关性系数(皮尔逊系数)。
- 优点:算法的通用性强;省去了分类器的训练步骤,算法复杂性低,因而适用于大规模数据集;可以快速去除大量不相关的特征,作为特征的预筛选器非常合适。
- 缺点:由于算法的评价标准独立于特定的学习算法,所选的特征子集在分类准确率方面通常低于Wrapper方法。
Wrapper(封装法):封装式特征选择是利用学习算法的性能评价特征子集的优劣。因此,对于一个待评价的特征子集,Wrapper方法需要训练一个分类器,根据分类器的性能对该特征子集进行评价。
- 方法有完全搜索(递归消除法),启发式搜索(前向/后向选择法,逐步选择法),随机搜索(训练不同的特征子集)。实际工作中主要用到启发式搜索,例如评分卡的逐步逻辑回归。
- 优点:相对于Filter方法,Wrapper方法找到的特征子集分类性能通常更好。
- 缺点:Wrapper方法选出的特征通用性不强,当改变学习算法时,需要针对该学习算法重新进行特征选择;由于每次对子集的评价都要进行分类器的训练和测试,所以算法计算复杂度很高,尤其对于大规模数据集来说,算法的执行时间很长。
Embedded(嵌入法):先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
- 一种是基于惩罚项,例如岭回归,lasso回归,L1/L2正则化。另一种是基于树模型输出的特征重要性,在实际工作中较为常用,可选择的模型有随机森林,xgboost,lightgbm。
- 优点:效果最好速度最快,模式单调,快速并且效果明显。
- 缺点:如何参数设置, 需要对模型的算法原理有较好的理解。
三.模型评估和优化
Q:简单介绍一下风控模型常用的评估指标。
- 混淆矩阵指标:精准率,查全率,假正率。当模型最后转化为规则时,一般用这三个指标来衡量规则的有效性。要么注重精准率,要么注重查全率,两者不可兼而得之。
- ROC曲线和AUC值,ROC曲线是一种对于查全率和假正率的权衡,具体方法是在不同阈值下以查全率作为纵轴,假正率作为横轴绘制出一条曲线。曲线越靠近左上角,意味着越多的正例优先于负例,模型的整体表现也就越好。AUC是ROC曲线下面的面积,AUC可以解读为从所有正例中随机选取一个样本A,再从所有负例中随机选取一个样本B,分类器将A判为正例的概率比将B判为正例的概率大的可能性。在对角线(随机线)左边的点上TPR总大于FPR,意为正例被判为正例的概率大于负例被判为正例的概率。从另一个角度看,由于画ROC曲线时都是先将所有样本按分类器的预测概率排序,所以AUC反映的是分类器对样本的排序能力。AUC越大,自然排序能力越好,即分类器将越多的正例排在负例之前。
- KS:用于区分预测正负样本分隔程度的评价指标,KS越大,表示模型能将好坏样本区分开的程度越大。KS的绘制方法是先将每个样本的预测结果化为概率或者分数,将最低分到最高分(分数越低,坏的概率越大)进行排序做样本划分,横轴就是样本的累计占比,纵轴则是好坏用户的累计占比分布曲线,KS值为两个分布的最大差值(绝对值)。KS值仅能代表模型的区隔能力,KS不是越高越好,KS如果过高,说明好坏样本分的过于开了,这样整体分数(概率)就是比较极端化的分布状态,这样的结果基本不能用。
- 基尼系数:其横轴是根据分数(概率)由高到低累计的好用户占总的好用户的比例,纵轴是分数(概率)从高到低坏用户占总的坏用户的比例。由于分数高者为低风险用户,所以累计坏用户比例的增长速度会低于累计好用户比例,因此,基尼曲线会呈现向下弯曲的形式,向下突出的半月形的面积除以下方三角形的面积即是基尼系数。基尼系数越大,表示模型对于好坏用户的区分能力越好。
Q:为什么ROC适合不平衡数据的评价?
- ROC曲线的纵轴是TPR= ,横轴是FPR= ,TPR聚焦于正例,FPR聚焦于与负例,所以ROC兼顾了正样本和负样本的权衡,使其成为一个比较均衡的评估方法。
- 因为TPR用到的TP和FN都是正样本,FPR用到的FP和TN都是负样本,所以说正样本或负样本发生了改变,TPR和FPR也不会相互影响,因此即使类别分布发生了改变,数据变得不平衡了,ROC曲线也不会产生大的变化。ROC曲线的优点,即具有鲁棒性,在类别分布发生明显改变的情况下依然能客观地识别出较好的分类器。
Q:AUC和KS的关系是什么?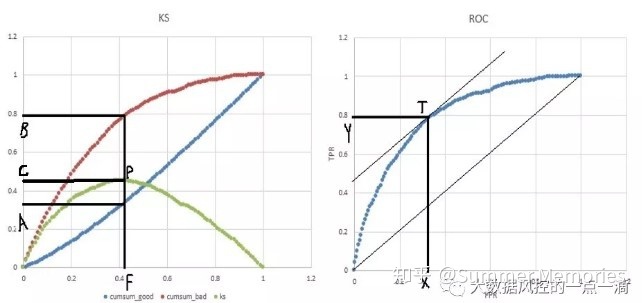
- 左图是KS曲线,红色的是TPR曲线(累计正样本占比),蓝色的是FPR曲线(累计负样本占比)。由于按照正样本预测概率降序排列,所以排在前面的样本为正的概率更大,但为正的概率是递减的;相反排在前面的样本为负的概率更小,但为负的概率递增。所以KS图中,TPR曲线在FPR曲线上方,并且TPR曲线的导数递减,FPR曲线的导数递增,而KS曲线先上升到达峰值P点(导数为0)后下降,P点对应的C值就是KS值。ROC图中,ROC曲线的导数是递减的,且刚开始导数大于1,逐渐递减到导数为1的T点(T点对应P点),然后导数继续降低。另外,A值对应X值,B值对应Y值,且C=B-A=Y-X
- 在用KS评估模型时,除了看P点对应的KS值C,还要看P点的横坐标F值的大小,F值表示的是将分数从低到高排序后的累计样本占比,F值越小,说明模型对正样本的预测越精确,也就是说在识别出正样本的同时也能保证对负样本更小的误杀率。
- 假设F值不变,C值增大,即P点沿着垂直方向向上移动,那么A值应该减小,B值应该增大;对应地,X值减小,Y值增大,T点会向左上角移动;所以ROC曲线下方的面积会增大,也就是AUC值增大。
- 假设C值不变,F值减小,即P点沿着水平方向向左移动,因为C=B-A,所以A和B减小相同的幅度,也是就说X和Y减小相同的幅度,即T点沿着斜率为1的切线方向向下移动,此时ROC曲线下方的面积也会增大,即AUC值增大。
- 所以P点的位置决定了T点的位置,C值和F值均会影响AUC值。AUC值看上去更像一个综合评估指标,但缺乏对模型细节的评估。而KS值结合F值,可以评估每一段评分的效果,还可以找出评分切分的阈值等。
Q:什么是模型的欠拟合和过拟合?
- 欠拟合指的是模型没有很好的捕捉到数据特征,不能很好的拟合数据。
- 过拟合指的是模型把数据学习的太彻底,以至于把噪声数据学习进去了,这样模型在预测未知数据时,就不能正确的分类,模型的泛化能力太差。
Q:如何判断模型是否存在过拟合或欠拟合?对应的解决方法有哪些?
- 判断模型是否存在过拟合/欠拟合主要用学习曲线,学习曲线指的是通过画出不同训练集大小时训练集和交叉验证的准确率,可以看到模型在新数据上的表现,进而来判断模型是否方差偏高(过拟合)或偏差过高(欠拟合)。当训练集和测试集的误差收敛但却很高时,即为欠拟合,当训练集和测试集的误差之间有大的差距时,为过拟合。
- 解决欠拟合的方法:增加效果好的特征,添加多项式特征,减小正则化参数等。
- 解决过拟合的方法:使用更多的数据,选择更加合适的模型,加入正则项等。
Q:什么是正则化?什么是L1正则化和L2正则化?
- 正则化是在模型的loss function的基础上,加上了一些正则化项或者称为模型复杂度惩罚项,它会向学习算法略微做些修正,从而让模型能更好地泛化。这样反过来能提高模型在不可见数据上的性能。
- L1正则化就是在loss function后边所加正则项为L1范数,加上L1范数容易得到稀疏解,所以L1正则化会趋向于产生少量的特征。
- L2正则化就是loss function后边所加正则项为L2范数的平方,加上L2正则相比于L1正则来说,得到的解比较平滑(不是稀疏),所以L2正则化会使特征的解趋近于0,但不会为0。
Q:正则化为什么可以防止过拟合?
最简单的解释是正则化对模型参数添加了先验,在数据少的时候,先验知识可以防止过拟合。举个例子:抛一枚硬币5次,得到的全是正面,则得出结论:正面朝上的概率为1,这类似于模型的过拟合,如果加上硬币朝上的概率是0.5的先验,结果就不会这么离谱,这就是正则。
Q:什么是交叉验证?交叉验证的目的是什么?有哪些优点?
交叉验证概念:
交叉验证,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓”交叉”。
交叉验证的目的:
评估给定算法在特定数据集上训练后的泛化性能,比单次划分训练集和测试集的方法更加稳定,全面。
交叉验证的优点:
- 如果只是对数据随机划分为训练集和测试集,假如很幸运地将难以分类的样本划分进训练集中,则在测试集会得出一个很高的分数,但如果不够幸运地将难以分类的样本划分进测试集中,则会得到一个很低的分数。所以得出的结果随机性太大,不够具有代表性。而交叉验证中每个样本都会出现在训练集和测试集中各一次,因此,模型需要对所有样本的泛化能力都很好,才能使其最后交叉验证得分,及其平均值都很高,这样的结果更加稳定,全面,具有说服力。
- 对数据集多次划分后,还可以通过每个样本的得分比较,来反映模型对于训练集选择的敏感性信息。
- 对数据的使用更加高效,可以得到更为精确的模型。
Q:交叉验证常用的方法有哪些?
- 标准K折交叉验证:K是自定义的数字,通常取5或10,如果设为5折,则会训练5个模型,得到5个精度值。
- 分层K折交叉验证:如果一个数据集经过标准K折划分后,在测试集上只有一种类别,则无法给出分类器整体性能的信息,这种情况用标准K折是不合理的。而在分层K折交叉验证中,每个折中的类别比例与整个数据集类别比例相同,这样能对泛化性能做出更可靠的估计。
- 留一法交叉验证:每次划分时,把单个数据点作为测试集,如果数据量小,能得到更好的估计结果,数据量很大时则不适用。
- 打乱划分交叉验证:每次划分数据时为训练集取样train_size个点,为测试集取样test_size个点,将这一划分划分方法重复n_splits次。这种方法还允许每次迭代中使用部分数据,可通过设置train_size和test_size之和不为0来实现,用这种方法对数据进行二次采样可能对大型数据上的试验很用用。另外也有分层划分的形式( StratifiedShuffleSplit),为分类任务提供更可靠的结果。
- 分组交叉验证:适用于数据中的分组高度相关时,以group数组作为参数,group数组表示数据中的分组,在创建训练集和测试集的时候不应该将其分开,也不应该与类别标签弄混。
三、金融风控20问+12问
作者:七月在线 七仔
链接:https://www.zhihu.com/question/264073676/answer/797409794
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
金融风控二十问
第一问:
什么我们做评分卡的时候要用woe编码,而不是用别的编码方式呢?比如onehot之类的,仅仅是因为woe可以把特征从非线性变成线性的吗?
答: 因为onehot后高维稀疏,模型学习是有困难的。一般模型会做embedding,但是做了embedding就不可解释了。这不符合某些风控场景的解释性要求。所以用woe来代替。当然WOE有一点点的过拟合倾向,但是对分类变量来说,依旧是业内最佳实践方案。
第二问:
分箱后,各箱badrate单调递增从业务上怎么理解呀?
答:我们有个先验知识,多头越多badrate越大,历史逾期越多badrate越大…等等,如果变量分箱后不符合这个先验,可能就把他剃掉了。
第三问:
5万负样本,200正样本,B卡,不只是提高额度,会拒绝一部分客户,怎么建模?
答:5万负样本是没有做下采样的必要的,200正样本无论用什么方法做过采样说实话由于自身携带的信息量比较少,学习的应该也不是完全的。
所以这时候建议先略作改动,评价函数加一项,负样本的召回率,也就是说这时候不是主要关注KS,而是对负样本究竟能抓到多少,然后负样本学习的时候一定要加权,权重就按照sklearn中逻辑回归默认的balanced方法就ok,而且如果是我可能生成一个决策树,把坏账从0.4%下降到0.12%左右我觉得就蛮好的了 。
第四问
leader 给你的任务是对短信打标签,也就是判断出短信属于的标签是哪一类,这样一个任务是提取文本关键词的任务吗?
答:我建议先确定每个词对每个类别的贡献度。简单来做就是每种类别找几个词,手动划分一下有这个词,就属于这个类别。
复杂一点来做,就训练个模型,确定每个词对每种类别的贡献度,然后对每条记录做个预测,排名前几的标签都给leader 。
第五问:
那简单的除了之前说的那种统计坏的词,然后正则匹配的还有其他的吗?
leader 之前说拿到词的重要度,是在整个语料中的一个重要度的话,tf-idf 是不可行的,现在要出一个版本的话,您有什么建议吗?
答:首先需要每篇文档的标签,然后去找词的重要度,不然只能拍脑袋呀 。然后想知道每篇文档的标签,你们可以先用之前的方法挑选一些特别明显的词 。给文档打标签。然后这样迭代着做。
第六问:
数据分析师岗位,和算法岗有什么不一样么?会提到数据敏感,究竟应该怎么回答?
答:区别是分析师是业务+报表+算法,工程师是业务+算法+工程。
数据敏感是玄学,关键要知道数据怎么分析,数据要对比着分析,随便拿出一个值就知道这个值是什么水平还是比较困难的。比如我们分析模型表现,分析变量稳定性。不是给出一个月份的分布我们就知道模型好不好,而是要两个月作对比才知道。
第七问:
想问一下,现在公司是不是先准入规则,然后再进入一个pre-A模型,然后再是反欺诈模型,然后是A卡之类的?
答:可以理解成模型是嵌在规则里面的,规则到处都有
第八问:
就是你说准入规则,pre-A, 反欺诈规则反欺诈引擎,还有风控模型,一般都不会选用相同的特征?因为客户群体会越来越少,这个我有点不理解……
答:这个问题不只有一个同学问过我。也是不单单我们这个场景才有的。
基本上每个机器学习模型或多或少都会遇到我们这种问题。我们一般是不会用相同的特征做重复筛选的。这样会导致样本偏移更严重。就是说,被拒绝的人,是由于某些特征表现差,被拒绝的,那随着时间推移,下次建模的样本里面,就没有这些人了…这些这些特征上的样本分布就变了 。
第九问:
我看之前逻辑评分卡 ,评分转化的部分 ,ln(odds) =Xbeta+intercept 但是我看您写的转换没有考虑常数项,行业内都是这么做的么,不考虑常数项?
答: 我记得代码里面有一项应该把他平衡掉了,那个公式的目的其实是,()中的那一项决定等于基础分的概率值,()的系数决定步长,()+决定基础分等于多少
第十问:
用三种标签学出来的三个模型,从三个维度给一个人的欺诈风险打分,怎么给这三个模型进行融合?
因为单个用户申请线上预测,无法根据客户在各个模型排名取平均。但这三个模型的输出的概率区间又是不同的,比如模型A的输出区间是[0-0.4],模型B输出区间[0-0.9],也不是正态分布,zscore标准化不能用,只能MinMax先进行标准化?再进行分数融合?
答:对的,一般要minmax,规约到一样的范围内
第十一问:
使用BiLSTM 对用户行为进行建模时,神经网络的输入层是什么?输出层是什么?怎么把用户行为数据转换成神经网络输入层的向量?
答:打个比方啊,额度使用率按照月份的时间序列就是,前0-30天的额度使用率,前30-60的额度使用率,前60-90的额度使用率…变成一个列向量。有多少特征(额度使用率是一个特征)就有多少个列向量
第十二问:
在ks上训练集和测试集相差不大,但在auc上却相差较大,这是为啥?
与模型的稳定性有关系,因为数据、特征影响,生成的模型roc曲线就可能比较陡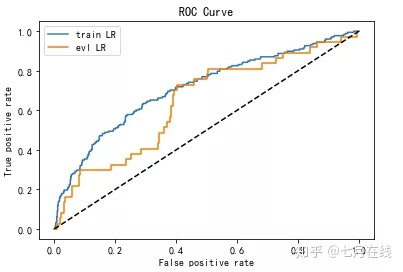
答:下图是KS的差距,两者差不多,曲面面积可以理解成是AUC的差距,差的就很多了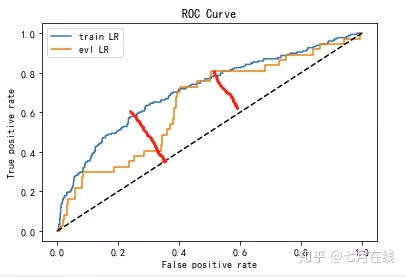
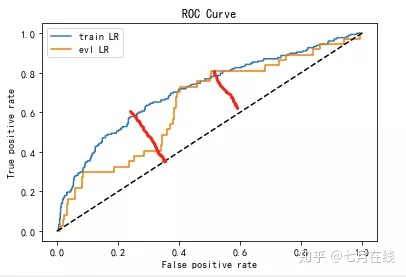
第十三问:
在xgboost或者lightgbm建模之前是否进行相关性处理,去掉相关性较高的变量?
答:要的。lr中我们是为了对向量空间描述的最好。在xgb主要是想去掉相互替代性较强的特征。
比如一个特征给他找相关性特别强的9个特征放在模型里面,存成不同的名字,你会发现他本来重要性是10,每划分一次,一个特征就比另一个好用那么一点,这么弄了之后十个特征的重要性都变成了1,然后被我们用feature_importance>5给筛掉了……这多尴尬
第十四问:
在评分卡上线以后。进行监控的时候,监控的周期是多少,是将新数据下载到本地来计算ks、psi以及变量稳定性等这些指标吗 ?
答:一般有日报周报月报,看客群量大的话,周期可以短一点,量少的话,计算指标没什么意义
第十五问:
怎么样才能具备招聘中所反欺诈岗位所要求的?

答: 归纳一下就是要,明确欺诈的定义,使用数据分析方法,对接第三方数据 。
第十六问:
想了解下金融风控的架构知识,能不能发点资料学习下
答:见思维导图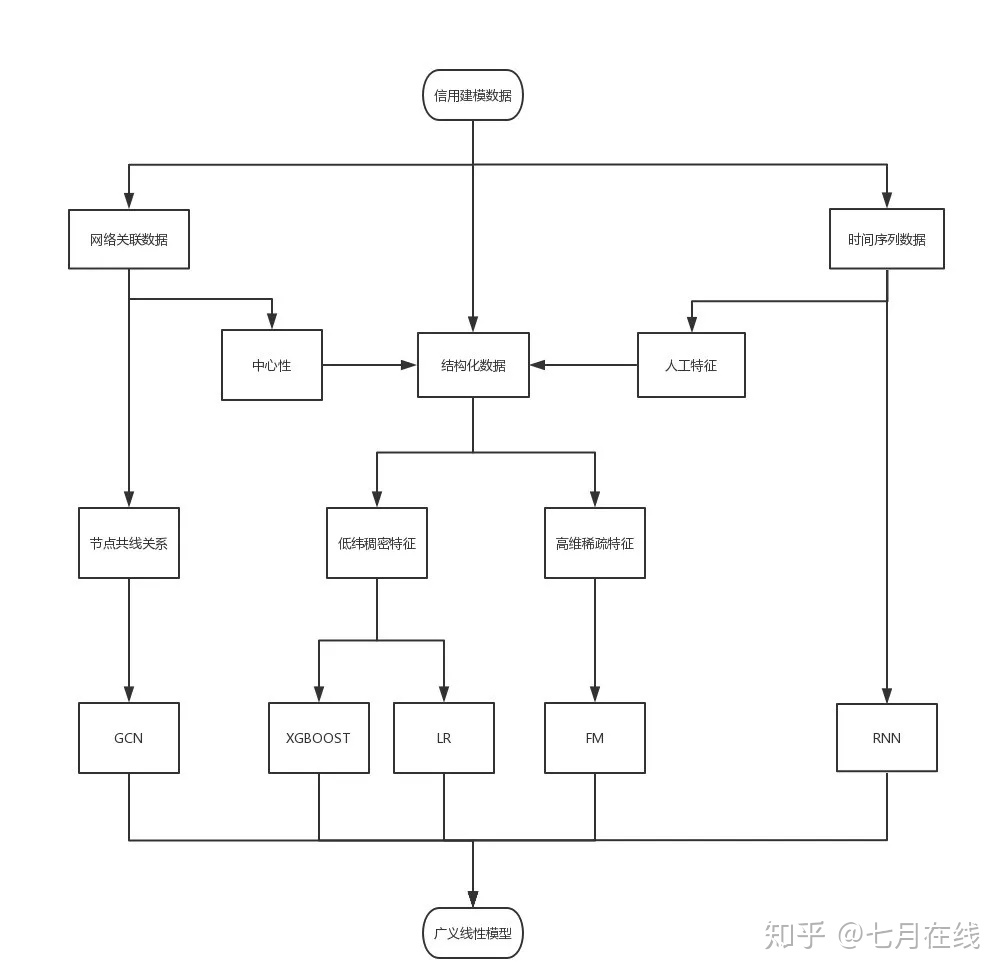
第十七问:
关于xgboost使用泰勒展开式的优点?
泰勒展开取得函数做自变量的二阶导数形式, 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算, 本质上也就把损失函数的选取和模型算法优化/参数选择分开了.
请问为什么在 可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子分裂优化计算?
答:下图中,g和h都是和损失函数有关的,所以不可能完全不考虑损失函数,这个表述是错误的。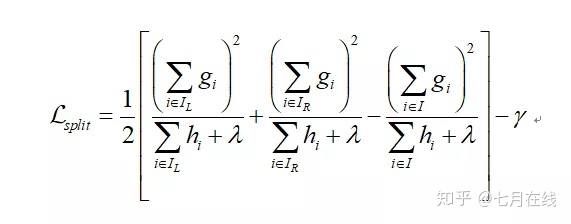
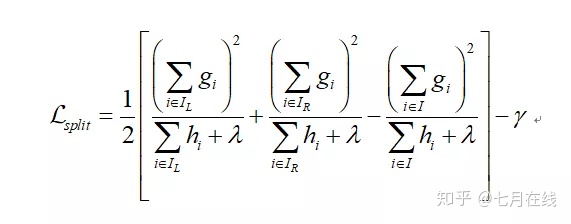
第十八问:
不平衡场景下的过采样(朴素、SMOTE)后训练的模型都需要结果概率校正吧?如何操作?
答:只有单个模型不需要做校正,如何需要和其他模型做融合或者做比较的时候可以做.
第十九问:
现在市面上在金融风控中用的无监督算法都有哪些?
答:主要是基于图的离群检测和聚类,还有个体反欺诈中常用的孤立森林,LOF等。
*第二十问:
xgb变量重要性用哪一个指标?
答:
①、通常我会直接用weight,他们筛选出的变量略有区别,但是使用下来区别主要在于重要性最低的那几个可以互相替代的特征,具体用谁其实并不重要。经验告诉我们total_gain效果可能会略好。
②、是的,xgb筛选特征,然后用新的特征建模,但是通常不建议筛选后还用xgb建模,这不符合模型融合的策略。
③、xgb其实是没法解释的,如果希望有逻辑回归的可解释度,建议相同数据、相同变量,带入lr建立一个陪跑的模型,寻求解释的时候去lr中找原因。特征相同的前提下,不会有太大出入的。
④、xgb筛选特征可以理解为用均方差最小来做特征筛选,和IV、WOE属于同一种筛选方式,描述的都是特征对分类任务的贡献度,一般用一个就行了,每个人的方法都不一样,见仁见智。
十二道大厂面试常见问题
你们公司的主要业务是什么?
1、属于什么类型的贷款产品。(现金贷、消费分期等等)
2、客户一般来自什么渠道,是特定的群体。(比如滴水贷只借给滴滴平台的司机),还是面向所有人的。(比如常规的p2p公司)
3、贷款额度、还款周期。
你们的业务做得怎么样?
1、通过率是多少。
2、pd0、pd7、pd30 大概是多少。
注意:这些都反应了你的模型做的如何,通过率越高,逾期率越低,模型越好。
PS:pd0指的是到期当天,pd1指的是逾期一天。
你都负责哪些业务?
1、准入策略。
2、风控模型。
3、贷后监控。
PS:我们要时刻关心模型的通过率和贷后表现是否有异常,警惕欺诈。
你模型是怎么做的?
1、确定y如何标记。(逾期几天为1,几天为0,每种产品不一样,如果不知道,我建议你说15天为分割点,没什么大问题)
2、前期数据准备。(数据来自 HIVE?MySQL?MongoDB?Spark?)
3、这里就可以接上学过的风控项目,包括各种算法,建模技巧,基本上都是这里引出的。
你是标记客户好坏的?
1、逾期天数作为标记好坏的依据。
2、因为本身样本不均衡,会偏向扩充坏人的数量。(比如以pd1来标记好坏,坏人肯定比pd15会多很多)
PS:很多公司建模的时候,去除一部分灰色客户。(比如去掉pd1~pd5的客户)
做模型时用到了哪些数据源?
1、征信数据。
2、运营商数据。
3、埋点数据。
4、平台自有数据。
5、用户手填数据。
6、数据有很多,每家都各有不同,小心点也可能问你数据来自哪家平台哦。
PS:见过很多小型公司都喜欢用运营商数据,因为便宜,很多都是免费的。
模型的效果怎么样?
1、测试集和跨时间验证集的KS和AUC是多少。
2、上线后一个月或者几个月后,模型的KS是多少,AUC是多少。
你们模型是怎么部署上线的?
我经历过的几种上线方法可以分享给大家:
1、最简单的,把评分卡每个区间加多少分减多少分,怎么做映射的逻辑,讲给开发小哥,他会帮你在线上写 if else。
2、生成一个pmml文件,给开发小哥调用。
3、公司自己做的决策引擎,或者是租的,自己写变量逻辑上线。
4、用flask或者Django自己写接口上线。
上线需要注意什么?
1、线上线下变量的逻辑必须完全一致,这是最重要的。
2、很多公司会做类似于A\B test,两套模型竞争。(一个champion做决策,和一个challenger空跑,也有可能champion 70%,challenger 30%)
推一下逻辑回归
对于别人可能有些难度,但我相信咱们平台的学员是完全没有问题的。
讲一下评分卡的分数映射公式
1、推导主要是换底公式,详见评分卡文档。
2、如果现在刻度区间过大应该如何调整。
PS:这里的逻辑要搞清楚,不然通过率出了问题,连怎么调整都不知道。
最近看有些同学在找金融风控方面的工作。咱们课程涉及到的,主要是建模的过程。有些同学对整个业务框架不是很了解,所以总结了一下平时面试聊的比较多的一些点。
前九道题都是工作中一定会碰到的基本内容,如果有一些这方面的工作经验,基本上都会聊到。后面的因人而异,工作经验少的同学,面试官可能会重点看一下对算法的理解,以及一些SQL能力。
第一题:你们公司的主要业务是什么?
- 属于什么类型的贷款产品(现金贷、消费分期等等)
- 客户一般来自什么渠道,是特定的群体(比如滴水贷只借给滴滴平台的司机),还是面向所有人的(比如常规的p2p公司)
- 贷款额度、还款周期
第二题:你们的业务做得怎么样?
- 通过率是多少
- pd0、pd7、M1大概是多少
注意:这些都反应了你的模型做的如何,通过率越高,逾期率越低,模型越好。
ps:pd0指的是到期当天,pd1指的是逾期一天。
第三题:你都负责哪些业务?
- 准入策略
- 风控模型
- 贷后监控
主要是风控模型这块。监控也是必须的,我们要时刻关心模型的通过率和贷后表现是否有异常,警惕欺诈。
第四题:你讲一讲你模型是怎么做的?
- 确定y如何标记(逾期几天为1,几天为0,每种产品不一样,如果不知道,我建议你说15天为分割点,没什么大问题)
- 前期数据准备(数据来自 HIVE?MySQL?MongoDB?Spark?)
- 这里就可以接上学过的风控项目
包括各种算法,建模技巧,基本上都是这里引出的。
第五题:你是标记客户好坏的?
- 逾期天数作为标记好坏的依据
- 因为本身样本不均衡,会偏向扩充坏人的数量(比如以pd1来标记好坏,坏人肯定比pd15会多很多)
- 注意很多公司建模的时候,去除一部分灰色客户(比如去掉pd1~pd5的客户)
第六题:你做模型时用到了哪些数据源?
- 征信数据
- 运营商数据
- 埋点数据
- 平台自有数据
- 用户手填数据
数据有很多,每家都各有不同,小心点也可能问你数据来自哪家平台哦。
ps:见过很多小型公司都喜欢用运营商数据,因为便宜,很多都是免费的。
第七题 模型的效果怎么样?
- 测试集和跨时间验证集的KS和AUC是多少
- 模型psi、单变量IV、cutoff、模型策略部署后的roi
- 上线后一个月或者几个月后,随机样本上模型的KS是多少,AUC是多少(如果没有随机样本线上auc就没有太大意义了)
第八题:你们模型是怎么部署上线的?
我经历过的几种上线方法可以分享给大家。
- 最简单的,把评分卡每个区间加多少分减多少分,怎么做映射的逻辑,讲给开发小哥,他会帮你在线上写 if else
- 生成一个pmml文件,给开发小哥调用
- 公司自己做的决策引擎,或者是租的,自己写变量逻辑上线
- 用flask或者Django自己写接口上线(性能就比较差了)
第九题:上线需要注意什么?
- 线上线下变量的逻辑必须完全一致,这是最重要的
- 很多公司会做类似于A\B test,两套模型竞争(一个champion做决策,和一个challenger空跑,也有可能champion 70%,challenger 30%)
第十题:推导一下逻辑回归 & XGBOOST
- 略
第十一题:讲一下评分卡的分数映射公式
- 推导主要是换底公式,详见评分卡文档
- 如果现在刻度区间过大应该如何调整
这里的逻辑要搞清楚,不然通过率出了问题,连怎么调整都不知道
第十二题:手写一下SQL代码
一般算法岗对SQL能力都是有要求的,稍加练习基本没有问题,这里放一个我们公司的笔试题。
- 请取出,每个班级 所有课程 平均分大于80分的 学生名字
四、风控经验
作者:风控猎人
链接:https://zhuanlan.zhihu.com/p/300959033
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
本文转自知乎楼小轰的文章《信贷风控模型岗的一些面试经验》 https://zhuanlan.zhihu.com/p/283062065
另外本人基于自己的积累写了一些问题的答案,文中灰色部分为本人所答,可能会有错误或理解不当之处,望多多指正。
简历细节怎么写就不描述了,但是很关键的一点是一些互联网大厂很看重面试者“新想法”,所以可以准备一个比较有想法有价值的方案。技术栈可以重点准备几个方面:
算法:
1、评分卡一系列流程,包括LR,WOE,IV简单公式, 为什么用WOE,为什么WOE 要用ln,评分卡分数转化。
答:主要写下为什么用WOE以及WOE为什么要用ln。
为什么用WOE:一种理解是为什么需要对变量进行分箱,另一种理解是为什么使用WOE值而不是原始数据入模。主要原因有让变量更有鲁棒性、简化模型、引入非线性、加快运算速度。
为什么WOE使用ln:赋予逻辑回归一定程度的非线性拟合能力。因为WOE和bad_rate一定是单调的,但是变量值却不一定。 关于WOE的深入思考可以看这篇文章 https://zhuanlan.zhihu.com/p/135856159
2、XGBOOST 的推导(主要是损失函数,泰勒公式,正则项),以及与RF/LGBM/GBDT的差异。另外决策树ID3,C4.5,CART还是得了解下。这两个基本是大多数风控团队的常用算法。数据集划分方法:开发集(训练、验证)和跨时间测试集。
答:XGB推导以及与GBDT区别:



关于机器学习算法准备这块可以看《百面机器学习》这本书,或者我之前写过推导算法的文章常用机器学习原理推导,上文中的算法都写到了。
3、特征工程:特征衍生(最好有一套熟悉衍生方案)、特征选择(可解释性,稳定性,预测能力,怎么万里挑百到百里挑十的过程)、特征分箱方法。
答: 特征衍生可以根据时间切片、特征、统计方式来进行衍生。这块没有什么实际经验。
特征选择的话常见的有IV值、相关系数、稳定性CSI、逻辑回归系数一致、逻辑回归变量显著性、xgb特征重要度。逻辑回归评分卡筛选变量的步骤案例如下:
1、保留IV值大于0.02的变量,共500个;
2、把初筛的到的量进行WOE编码;
3、变量间两两相关检验并筛选,删除相关性大于0.7的变量400个,剩余100;
4、变量稳定性检验,把稳定性大于0.05的变量删除,剩余60个;
5、逐步回归法筛选最终入模变量,剩余入模变量10个。
4、模型优化:调参方法(主要是XGB的调参,从训练速度、精度、过拟合三个方面回答+网格搜索或者贝叶斯优化),自定义损失函数和评价函数经验,过拟合和欠拟合解决方法、梯度下降和牛顿法。
答:XGB调参可以看之前写过的文章xgb调参小结或者网上也有调参的步骤,主要是用网格搜索算法,贝叶斯优化调参没实际用过。



自定义损失函数和评价函数:
只需要保证损失函数二阶可导,通过评价函数最大化即可对模型参数求解,可根据业务指标对二者进行调整。这块也没有实际经验。
5、模型评估:从特征/模型结果评估KS/AUC/PSI,跨时间窗口badrate的趋势稳定性、可解释性。KS/AUC/PSI怎么算。当然要是做的不是二分类模型,就要准备其他的内容。
6、拒绝推断:简历提到会被问。为啥要用拒绝推断,有啥效果,有啥方法。
答:如果只用放贷样本建模,由于存在“部分样本估计总体”的问题,对全量申请用户的风险估计就会不准确,会让模型出现估计偏差。
如果放贷率很高(如90%+),这时就没必要做拒绝推断,样本偏差问题已经不明显。
如果放贷率很低(如5%左右),那么由于拒绝推断与真实贷后表现之间存在较大的差异,可能导致模型性能反而下降。
关于拒绝推断可以看求是汪老师的这篇文章《风控建模中的样本偏差与拒绝推断》 https://zhuanlan.zhihu.com/p/88624987
7、模型监控:基本回答一下监控哪些内容,大概多久或者什么情况更新模型。
答:模型监控分为前端监控和后端监控。前端监控报告可以在模型上线后一个月开始执行,目的是观察申请客户或者近期客户的类型与模型开发样本是否一致。后端监控报告在模型上线后一段时间(可以为坏客户的延滞月数或表现期长度)开始执行,即需要有样本表现。目的是为了观察评分模型对申请客户或近期客户群体是都仍具备鉴别力。即前端监控报告监控稳定度,后端监控报告监控区分度。其维度都是开发样本和现行样本。
8、其他:稍微理解一下神经网络比如CNN,DNN,Resnet,RNN,LSTM。了解下什么参数共享、稀疏交互,梯度消失,梯度爆炸、BP,dropout啥的。面试时候经常会被问到有没有了解神经网络啊,这应该算加分项,要是说没有还是比较尴尬,可以花一天时间看看。
投简历方式
简历和技术栈准备60-70%差不多就可以投了。一般3-5天左右可以接到面试,所以准备时间蛮充裕的。有内推找内推,不过内推虽然流程快,但是可能对候选人要求会更严格,因为有可能他们团队当前不缺人,所以更看重候选人能够给团队带来哪些新的价值。没内推挂猎聘,时不时刷新简历,坐等hr或者猎头联系。猎头还是蛮好的,会给一些面经。
工作机会
可以考虑互金、银行系、风控的乙方平台。
常见的面试题(包括HR)
个人介绍,为啥换工作。 项目细节。可以围绕是什么,为什么,怎么做,结果怎么样,创新点在哪,还能怎么提升来准备。 自己当前的工作内容,对风控的理解,所属团队架构,负责的产品类型,贷款规模,客户数,笔均金额,额度,定价等等。有些问题可能比较涉及公司隐私,尽量别说太细。
技术栈:基本是1中列的问题。当然如果简历中有写其他,也会被问道。 会让描述一个具体建模的流程。我觉得这问题比较扯,所以都会回答建模流程都是大同小异,然后描述整体流程以及注意的细节。 坏客户怎么定义以及为什么这么定义。
团队与其他部门怎么合作的:比如运营,IT?
客户画像相关。比如产品的目标客户,不同渠道的客户的直观差异。
你觉得对团队的价值在哪。
人行征信报告有哪些内容,一代二代有啥区别。
答:
1.提供了欠税信息、判决信息、强制执行信息、处罚信息
2.提供运营商缴费、欠费等信息
3.长达5年的还款纪律,提供易解析的结构化数据
4.个人手机号码新增至5个
5.提供了更丰富的异常提示信息和个人异议信息
用过哪些三方数据,效果怎么样。
答:以下为本人了解的一些:
黑名单类:同盾、融慧
征信类:鹏元、前海、上资
运营商:数尊
社交类:游昆
平时工作的工具和算法有哪些。尽量多说一点,当然要真的有相关经验。 哪些特征你觉得比较有用。
答:最近一笔贷款距现在的时间间隔、现行最近12个月无逾期个人消费贷款本月实还款最大、最近6个月内贷款审批次数、信用卡审批查询次数。
贷前贷中贷后看重哪些指标?策略看重哪些指标?比如过件率,违约率,支取率啥的。我主要做贷前,所以就回答贷前的。
答:贷前看通过率、首/次逾、Vintage逾期率,贷后看回收率、迁徙率、资产占比逾期率、不良率、坏账率。
冷启动怎么做?专家规则+反欺诈+三方数据/评分 反欺诈怎么做?可以从核人核借贷意图,模型+策略的方法来描述。我不是专业做反欺诈的所以随便聊聊。
答:欺诈的类型有第一方、第二方、第三方欺诈。第一方欺诈指利用真实信息申请贷款,可以理解为个人欺诈;第二方欺诈指内外勾结骗贷;第三方欺诈则为中介黑产欺诈。
模型的话可以谈一些无监督学习算法,比如孤立森林以及异常检测的其它算法。
策略的话主要从集中性,异常性,稳定性,结合各个维度(设备,位置,行为等)构造各类反欺诈策略。
集中性:比如一定时间内,同一个设备上出现的手机号数量超过多少就预警。
异常性:异常性指的是该客户和正常客户的区分性。例如设备是伪造过的设备,ip为代理ip,gps是伪造的地址位置,客户在一分钟之内操作完所有流程。
稳定性:稳定性指的是客户与自身经常发生的行为对比。例如客户本次申请贷款的位置在广东,但是客户之前从来没有买东西到广东。
线下防范渠道欺诈,线上防范中介欺诈。
树模型可解释性:Shapley value,Lime啥的,稍微了解下就行,一般也没细问。
答:如何解决机器学习树集成模型的解释性问题
定价和额度策略怎么做。可以从政策、风险、收入负债去描述。
答:
量化风险定价:https://zhuanlan.zhihu.com/p/267965054
额度策略:https://zhuanlan.zhihu.com/p/153004627
除了工作内容,平时会去了解哪些知识来提高自己。
对未来的职业规划。 自我评价。可以从执行力,解决问题能力,专业能力,抗压力,沟通合作,领导,组织等等去聊。
自身优缺点。同上。
有啥要问的?基本每次有被问到这个问题。我也会抱着学习心态去了解一下对方业务情况、团队架构大小、技术栈、意向候选人品质啥的。了解这些还是蛮重要的,毕竟找工作也是双向选择的过程。如果对对方回答非常喜欢,可以趁机舔一舔,同时描述自己的适配性和意向度。 有没有其他offer?如果有,最想去哪家。 换工作最考虑哪些因素?
面试的一些心得
项目描述要恰当:尽可能用”让信贷初学者听得懂的语言“来描述你的项目的目的、过程和结果,同时尽可能突出项目的高大上,这一部分最好多花心思去琢磨一下描述项目的话术。这点我一开始面试时也吃了几个闭门羹,我以为每家公司的风控流程内容都差不多,实则互金、银行、风控乙方做的方向有所区别,风控前台和中台的算法也有区别。有些侧重业务,有些侧重模型算法,有时候要是描述不够恰当,对方无法理解你做的东西。面挂了3家之后,我调整了下描述方式,剩下5家都到谈薪阶段。 心态要好:一个萝卜一个坑,被人拒绝也不代表你能力有问题,也有可能只是做的东西不一样,面试不论结果怎么样都要保持自信迎接下一场面试。我们知道评分卡解决方案在银行业就很吃得开,但是对于互联网来说,他们更喜欢树模型,神经网络啥的,评分卡做的再好对互联网来讲可能欠缺吸引力。反过来对银行来说,一堆高大上的模型经验他们也不一定感冒。等等 简历内容要一清二楚:面试官经常会问得特别细,细到用了多少个特征,多少样本,ks多少,上线后结果怎么样这种问题都可能问到。我觉得这种问题蛮无聊,但是如果支支吾吾回答得话也说明对项目了解不够熟悉。 珍惜每次面试机会:每一次面试其实就是对个人的一次全方位的专业性质检,每个人都可以很快的发现自身不足。面试者可以及时自我迭代,以更好状态应对下一次面试。所以有面试,不管公司大小都不妨尝试接触一下。如果对自己不是特别自信,可以把自己意向度最高的公司排在靠后的时间,这样面试时候会更多经验和自信心。我最先面的几家表现确实不理想,但是后面几家就很轻松。 代码问题:我的数据结构能力真的孬,我个人更关注模型和业务场景的结合的问题,平时对代码要求也不高。不过一些公司比如头条、PDD、美团对代码能力要求还是蛮高的,有意向还是得刷leetcode(我直接放弃)。阿里系有可能一面会有代码题,也可能没有,要求相对没那么严格。大部分其实不怎么要求现场写代码啦。
五、风控习题
作者:风控猎人
链接:https://zhuanlan.zhihu.com/p/352860054
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
笔试试题
第一部分 数据分析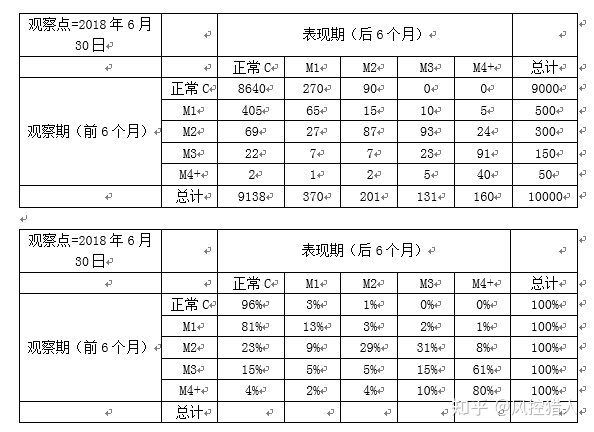
上图为逾期滚动率表,观察点为2018年6月30日,我们取10,000个客户作为研究对象,统计该10,000个客户从观察期到表现期的最大逾期状态的变化情况。请问:
1.您可以通过上表分析出哪些有用的信息?
逾期状态为M0的客户,在未来6个月里,有96%会继续保持正常状态,4%会恶化为M1和M2;
逾期状态为M1的客户,未来有81%会回到正常状态,即回收率为81%,有7%会恶化,13%会保持M1状态;
逾期状态为M2的客户,回收率为23%,有39%会恶化为M3和M4+;
逾期状态为M3的客户,回收率为14.7%,有60.7%会恶化为M4+;
逾期状态为M4+的客户,回收率仅为4%,有80%会继续保持此状态。
2.如何使用上表帮助定义客户的好坏程度?
第一步,历史逾期状态为M4+的客户几乎不会回收。因此坏用户定义为逾期状态为M4+(逾期超过90天)
第二步,以M4+作为资产质量指标,统计Vintage数据表,绘制Vintage曲线。目的是分析账户成熟期。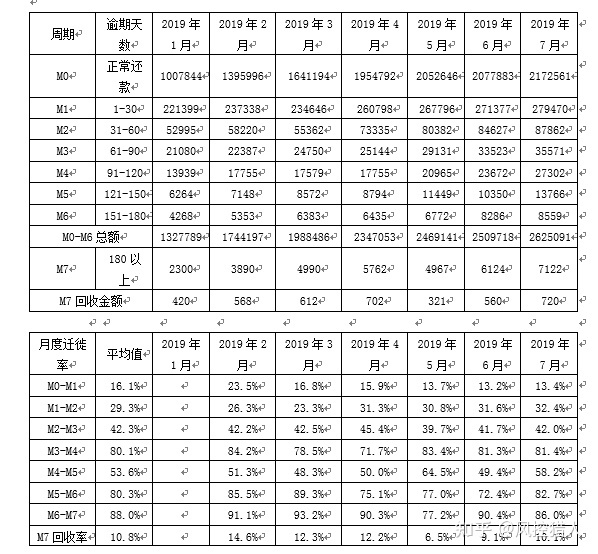
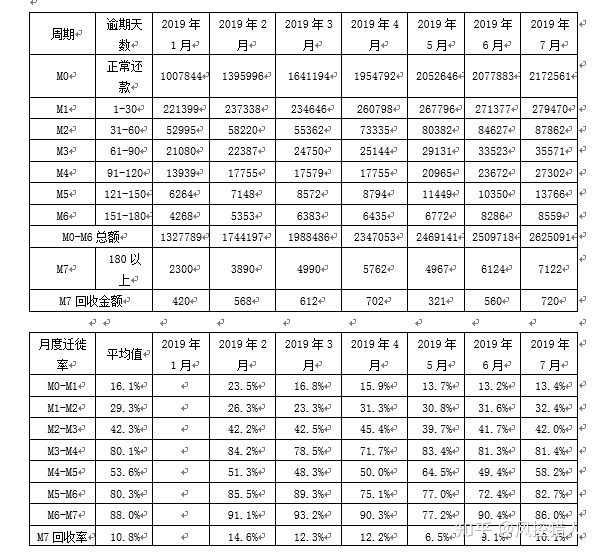
3.上图为迁徙率表,表示在2019年1月到2019年7月资产从M0-M7的变迁情况。你可以通过上图分析出那些有用的信息?
一、各阶段的平均月度迁徙率以及M0-M4综合迁徙率,可以对比各月份之间迁徙率的变化来分析资产的变化趋势。
二、可以分析出不良资产的恶化迁移路径。如1月末的资产为1007844元,最终有8559元逾期到M6+,Vintage口径下的不良率为0.85%。
三、M6+资产的平均回收率为10.8%,可用于计算净坏账损失率。
4.请通过以上数据计算M0资产迁徙到坏账(M7)的转化率;净坏账损失率以及坏账拨备率
一、M0-M7转化率:
16.1%29.3%42.3%80.1%53.6%80.3%88.0%=0.60%
二、净坏账损失率
0.60%(1-10.79%)=0.54%
三、坏账拨备率
坏账拨备率等于当月应计拨备额 / 总资产金额,而当月应计拨备额 = SUM(净坏账损失率 月末应收账款余额)。因此需要先计算各逾期阶段的净坏账损失率以及余额。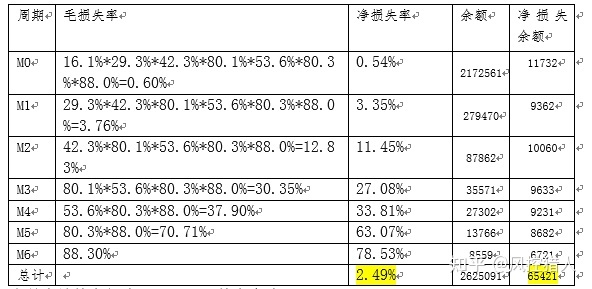
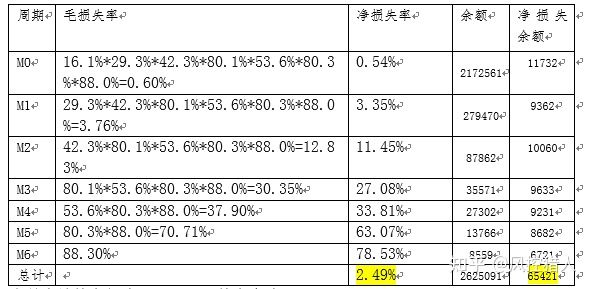
当月应计拨备额为65421元,拨备率为2.49%。
以下是三张表的信息介绍,请根据这三张表的信息回答以下3个问题
表1名称:s;Sid:学生id;Sname:学生姓名
| Sid | Sname |
|---|---|
| 1 | 赵四 |
| 2 | 张三 |
| 3 | 王二 |
| … |
表2名称:sc;Sid:学生id;Cid:课程id;Score:分数
| id | Cid | score |
|---|---|---|
| 1 | 1 | 80 |
| 1 | 2 | 90 |
| 2 | 1 | 99 |
| 3 | 1 | 70 |
| 3 | 2 | 60 |
| … |
表3名称:c;Cid:课程id;Cname:课程名称
| Cid | Cname |
|---|---|
| 1 | 语文 |
| 2 | 数学 |
| 3 | 英文 |
| … |
5.用一条SQL语句查询每门课程都是大于80分的学生的姓名
找出有科目没有达到80分的姓名,然后过滤:
select distinct name from s where name not in (select distinct name from sc where score<=80)
通过分组过滤方式:
select sc.Sid,s.Sname,sc_min.score from sc
inner join (select Sid,min(score) as score from sc) sc_min
on sc.Sid=sc_min.Sid
inner join s
on sc.Sid=s.Sid
where sc_min.score>80
6.查询“语文”课程比“数学”课程成绩高的学生的信息以及课程分数
SELECT
from (
SELECT a.Sid,a.score ‘语文’,b.score as ‘数学’
FROM (SELECT from sc WHERE sc.CId = 1)as a
inner join (SELECT from sc WHERE sc.CId = 2)as b
on a.Sid = b.Sid
WHERE a.score > b.score
)c
left join s a
ON a.Sid = c.Sid
7.查询平均成绩大于65分的学生的id和姓名以及平均成绩
SELECT Sid, Sname, avg_score FROM s
inner JOIN
(SELECT Sid,AVG(score) AS avg_score FROM sc GROUP BY Sid HAVING avg_score >65)scON s.Sid = sc.Sid
第二部分 风控策略
8.最近模型团队新开发违约模型,为了验证新模型效果,将人群随机分配进行AB测试,实验组A使用新模型,对照组B使用旧模型。观察了一段时间的结果后,得到如下观测结果:实验组A样本量10000人,逾期量300人;对照组B样本量10000人,逾期量400人。请从假设检验的统计学方法说明在降低逾期率上新模型效果是否优于旧模型?
上述问题属于两个总体比例相等的假设检验。
第一步,构建原假设和备择假设。
由于是检验新模型效果是否优于旧模型,所以是单边检验。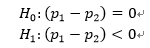
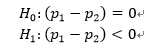
第二步,构建检验统计量。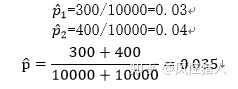
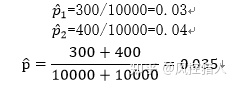
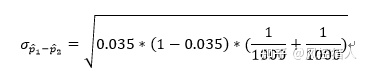
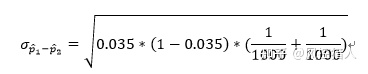
计算得到Z值等于: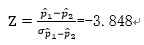
第三步,拒绝域
查表,或者通过Excel NORMSDIST函数算可得P值等于0.00006
第四步,结论
设定α=0.05,P值小于α。说明落入拒绝域,即有充分的理由拒绝原假设,接受备择假设。所以新模型效果优于旧模型。
关于两个总体之间假设检验内容可以参考贾俊平《统计学》第八章假设检验,或者参看知乎文章https://zhuanlan.zhihu.com/p/144924899。以下为本人以前的一些笔记:

9.如何辨识业务中的信用风险和欺诈风险,常用的反欺诈策略都有哪些。
信用风险表现为逾期天数较短且通过催收可以回收,而欺诈风险则表现为首期开始则逾期,且催收多为失联,资产无法回收,最终变为坏账。
常见的反欺诈策略,主要通过交叉检验和集中申请来识别。可以从集中性,异常性,稳定性,结合各个维度(设备,位置,行为等)构造各类反欺诈策略。
集中性:
近15天申请人手机号被其他申请人作为亲属联系的次数>X
近24小时同一IP地址申请订单数>X
异常性:异常性指的是该客户和正常客户的区分性。例如设备是伪造过的设备,ip为代理ip,gps是伪造的地址位置,客户在一分钟之内操作完所有流程。
稳定性:稳定性指的是客户与自身经常发生的行为对比。例如客户本次申请贷款的位置在广东,但是客户之前从来没有买东西到广东。
线下防范渠道欺诈,线上防范中介欺诈。
10.在引入外部数据源的时候,有哪些关键点需要考虑,为什么?
1、首先需要了解外部数据源的产品特征、类型,一般数据源类型分为决策类和排序类。决策类有黑名单类(多头、逾期、黑产、失信、罪犯等),验证类(学历、社保公积金、运营商实名与在网时长、地址信息、收入信息等),刻画类(关注类、消费画像、第三方规则),排序类有评分类(芝麻信用分、芝麻欺诈分等)。根据不同的目的引入合适的数据源。
2、提供线下测试样本。测试样本需要有适当的好坏比例,加入真实定性的客户数据去验真,如果需要回溯测试的话则需要回溯到申请日期。
3、测试方向考察。名单类三方数据源的考察可以从5个指标公式进行:
查得率(Search rate)=查得数/样本量
覆盖率(Cover rate)=查得命中黑名单数/样本中命中黑名单量
误拒率(Error reject rate)=查得命中黑名单数/样本中通过且为Good量
有效差异率(Effective difference rate)=查得命中黑名单数/样本中通过且Bad量
无效差异率(Invalid difference rate)=查得命中黑名单数/样本中其他拒绝量
黑名单类一般用在反欺诈环节,所以主要考虑到查得率和覆盖率,即命中的用户逾期概率比较高。
评分类一般用作策略和模型,应考虑4个方面:
查得率——是否高,是否与其它评分互补
单调性——评分是否对样本单调
准确性——低分段是否坏样本浓度更高
风险增益——相关性分析以及KS增益
对于评分类外部数据,如果评分的排序性好且IV比较高,则考虑入模,如果评分有明显的尾部极端优势,那适合做策略,用来拦截掉极端的坏用户。
4、数据源产品定价以及成本考虑。包年还是按查询条数收费,或者是搭配主要产品附赠免费查询。
5、上线之后数据源监控。
主要包括接口调用异常监测、数据分布异常监测以及风险拦截效果监测。
11.由于疫情原因,公司逾期率出现明显上升,请结合你的工作经验谈谈如何调整风控策略和模型降低逾期水平。
在策略层面,可以适当做一些准入策略收紧,根据疫情影响范围也可做一些差异化策略调整,另外也可增加一些风险提示给到审批;在审批层面,适当调整审批策略以适当降低审批通过率;在机构层面,我们要对机构进件情况做精细化监控,并根据监控指标异常情况做差异化管理,这个是用来预防因疫情导致的冲击过大导致前端不可控。
主要说下差异化策略调整,步骤如下:
1.取近3个月数据,FPD 7+(首逾7天以上)定义为坏;
2.分城市标签、城市类别标签行业标签, 分客户类型标签(私营业主,个体户,授薪)、主要收入来源标签(工资发放,兼职收入,其他等等)了解受疫情影响最严重的业务特征变量;
3.看下已经在使用的三方信息(近期消费记录与以往消费记录对比,近期多头记录,近期还款情况,近期位置变化情况,近期偿债压力指数),间接了解什么类型客户财务状况不稳定;
4.业务特征变量和三方信息结合综合评估客户近期资金情况和未来职业稳定性。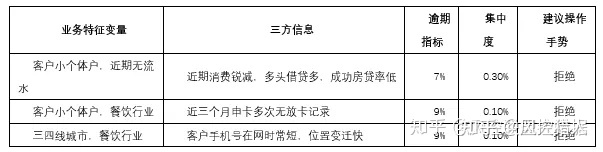
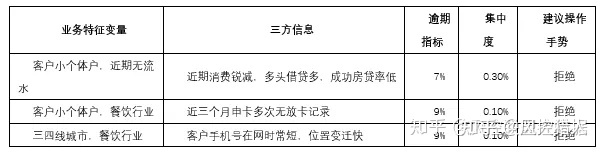
风险提示可从客户借贷倾向,还款能力以及融资能力方面可以结合推导客户资金抗压能力,然后审批过程中进行相应核实。
第三部分 信用评分卡案例
(代码由Python编写,同时使用scorecardpy评分卡包)
原始数据cs-training.csv, 150000行,11个向量,概况如下:
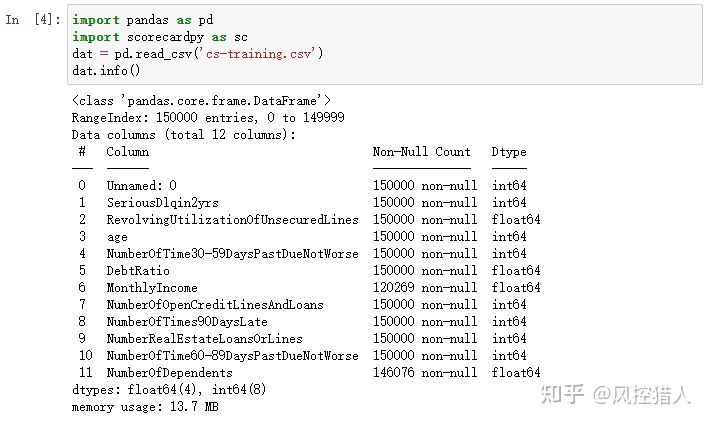
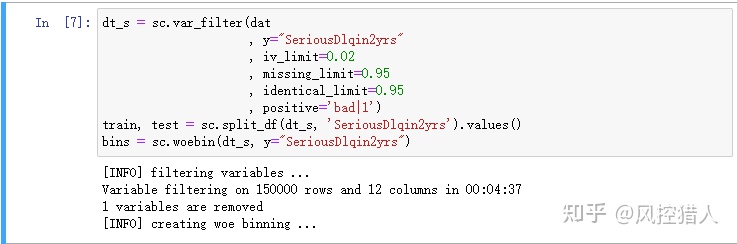
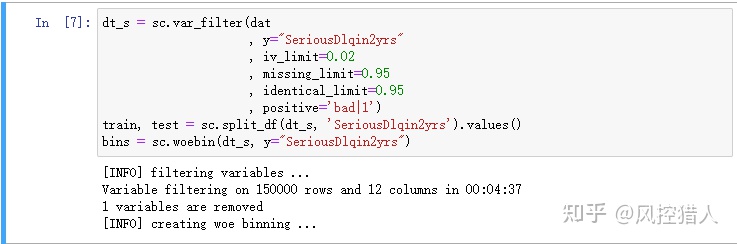
12.请问上述代码中参数missing_limit=0.95表示对缺失率超过95%的特征进行删除,那么对于缺失的特征常用的处理方式还有哪些,这些处理方式具有哪些局限性。
缺失值处理的方法有剔除、填补以及不处理三种方式。
剔除:可以剔除单个特征或者单个样本。一般对缺失率较高的样本或者特征进行剔除操作。
填补:类别型变量可以将缺失值单独填充为一箱,数值型变量可使用中位数、众数、均值以及决策树、随机森林方法进行填补。
1.针对缺失率在5%以下的变量用中位数填充
2.缺失率在5%—15%的变量用随机森林填充,可先对缺失率较低的变量先用中位数填充,在用没有缺失的样本来对变量作随机森林填充
3.缺失率超过15%的变量建议当做一个类别
不处理:不处理缺失值,直接在包含空值的数据上进行数据挖掘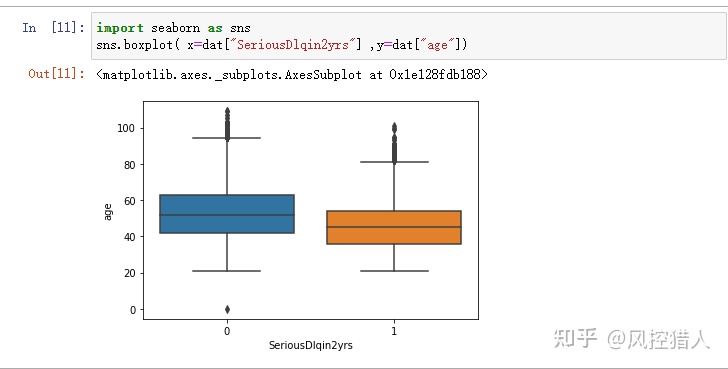
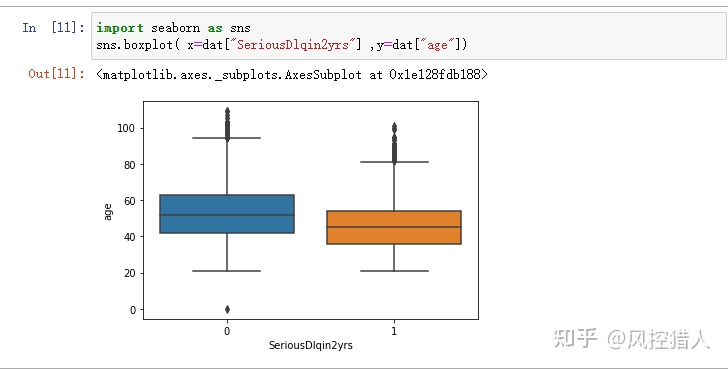
13.通过上图您发现了哪些问题,请说明解决这些问题的方法都有哪几种。
箱线图可以验证变量的分布是否对称,是否存在离群点。上图说明年龄变量中有大量离群点,即需要进行异常值处理。
需要了解异常值出现的原因,根据实际情况决定是否保留异常值。
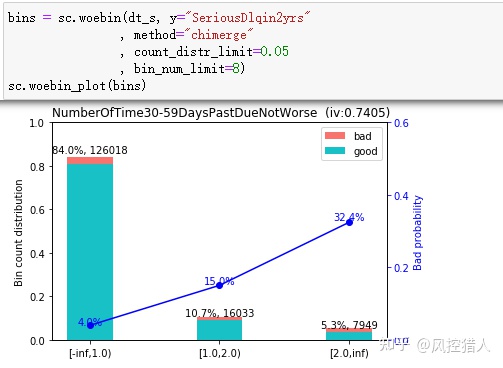
14.以上代码对特征进行了什么样的处理,这种处理的原理是什么。
对变量进行分箱。分箱就是将连续型的数据离散化,比如年龄这个变量是,可以分箱为0-18,18-30,30-45,45-60。由于评分卡需要模型有很强的业务可解释性,所以需要对变量进行分箱处理。如果使用xgb、lgb等机器学习算法的话,模型会变得不可解释,此时不分箱也是可以的。
分箱的好处主要有这些:
1. 分箱后的特征对异常数据有更强的鲁棒性。比如年龄中有一个异常值为300,分箱之后就可能划到>80这一箱中,而如果直接入模的话会对模型造成很大干扰。
2. 特征离散化之后,每个变量有单独的权重,可以为逻辑回归模型引入了非线性,能够提升模型表达能力,加大拟合。
3. 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
4. 可以将缺失作为独立的一类带入模型。
5. 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展。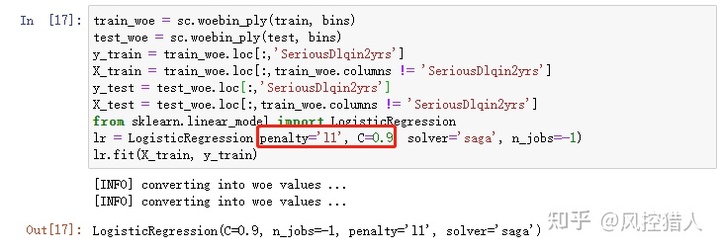
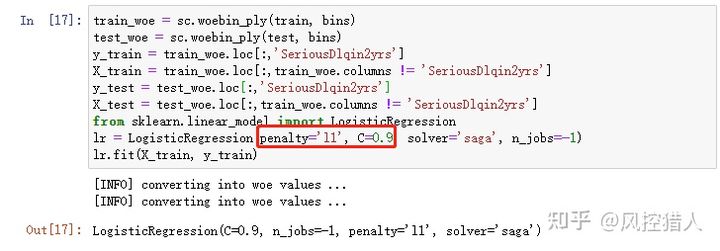
15.上述代码中最后第二行参数penalty=’l1’中l1是什么意思,参数C的变大会对模型训练结果产生什么影响。
逻辑回归的评价函数,由损失函数和正则项组成: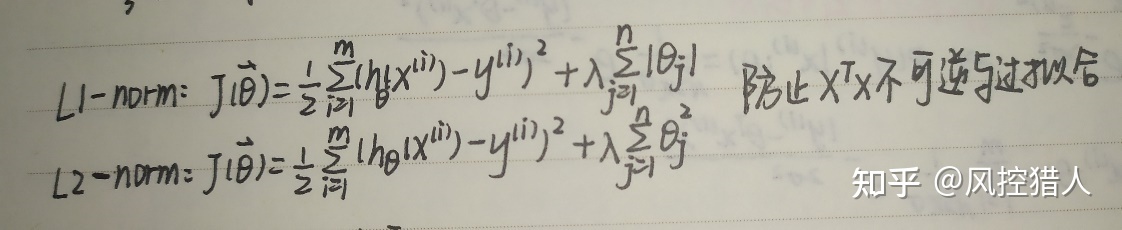

L1是正则项,主要有L1和L2正则两种。
C表示正则化强度的倒数,较小的值指定更强的正则化。C越大,λ越小,对正则项的惩罚力度越小,参数选择的空间会变大。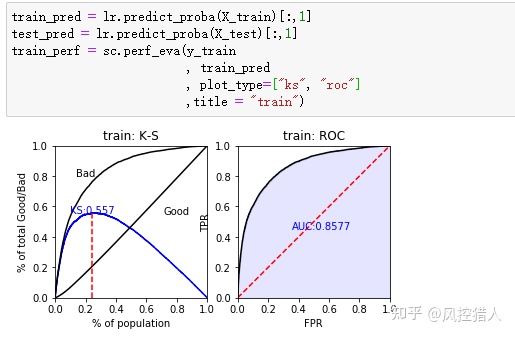
16.上右图中为什么说AUC越大,模型的区分度越高。如模型上线没多久发现模型的区分度快速下降,可能的原因是什么,如何避免这类情况发生?
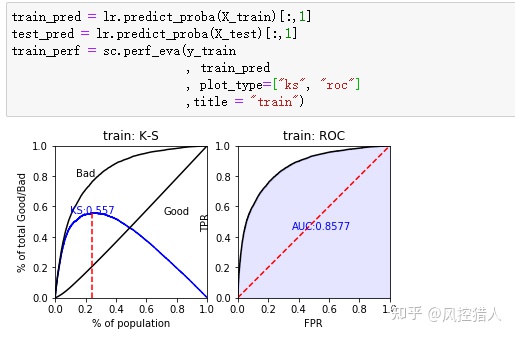
AUC越大,模型的区分度越高,可以从AUC以及ROC曲线的原理出发进行解释。这里提供另外一种与KS相关的思路:因为KS=TPR-FPR,所以TPR=FPR+KS。而ROC曲线的横纵坐标为TPR、TPR,因此KS值可以理解为斜率为1的直线与ROC曲线切线与Y轴截距的最大值。
模型上线之后区分度快速下降,可能原因有:
1.线上模型的特征和线下逻辑不一致。
2.特征的稳定性出现问题。需要分析每个特征的PSI值,必要时进行模型重构。
3.模型样本和进件样本分布不一致导致的模型误差。需要进行拒绝推断模拟进件样本的真实分布。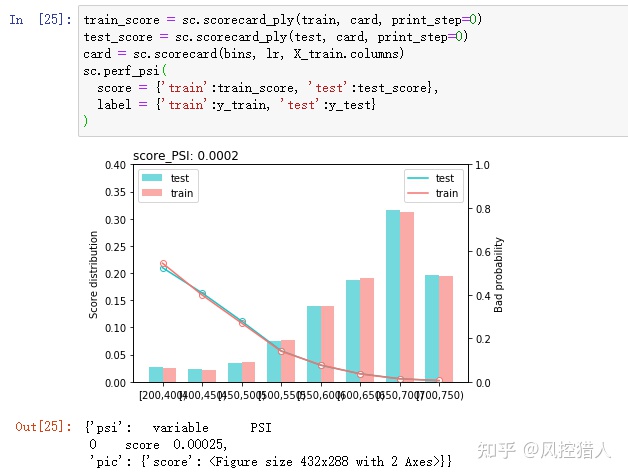
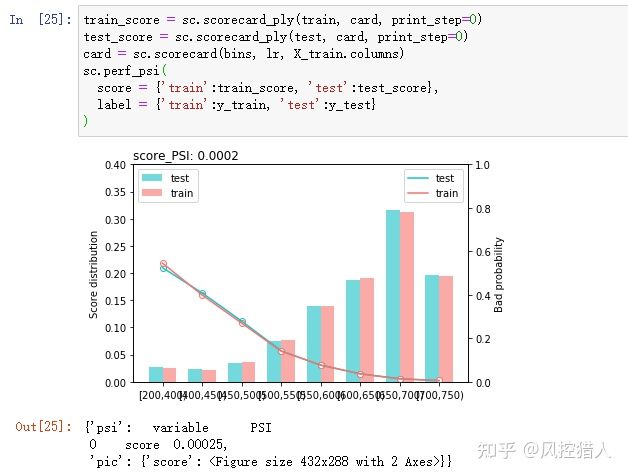
17.上图统计的指标PSI是指什么,如果PSI指超过0.25将带来什么影响,结合你的工作经验分析影响PSI的因素有哪些,如何降低或解决这些负面因素。
PSI全称群体稳定性指标,反映了验证样本在各分数段的分布与建模样本分布的稳定性。在建模中常用来筛选特征变量、评估模型稳定性。
时间推移、政策监管、市场波动等都会影响PSI。,实际评估需要分时间粒度(按月、按样本集)、订单层次(放贷层、申请层)、人群(分群建模)。
实践中,我们一般会先观察PSI,如果PSI显示模型分数不稳定,那么此时再去观察CSI,从特征级分析原因。因此,PSI偏于宏观,CSI偏于微观。PSI指标不稳定时的因素主要包括:
1.申贷客群变化:获客渠道一般决定了客群质量,我们只是从客群的有限特征维度来大致判断是否变化,但这只是有偏判断,因为无法完全获知用户画像。当然,在获客阶段也会做前置风控,预先筛选流量,以及保证客群的稳定。
2.数据源不稳定:先从CSI指标观察入模特征的分数漂移,对于影响较大和偏移较大的变量予以重点关注。再从数据源上确认采集是否可靠,比如数据服务商是否正常提供、接口是否正常工作、网关数据传输过程是否正常等。
3.特征逻辑有误:在模型上线时,特征逻辑可能没有确认清楚,导致上线后出现意想不到的问题。因此,需要将入模特征的逻辑再次予以Review。
4.其他相关原因:模型监控报表是否正确计算?线上依赖于离线T+1产出的数据是否正常调度?特征缺失值处理逻辑?
18.什么是模型的偏差和方差,如何降低模型的高偏差和高方差问题。
模型的误差来源于偏差和方差两方面。偏差是指数据偏离平均值的差,方差是指数据偏离期望值的差,衡量数据波动程度。偏差和方差是解释学习算法泛化性能的一种重要工具。
偏差和方差另一种更通俗的解释,偏差是指所有可能的训练数据集训练出的所有模型的输出的平均值与真实模型的输出值之间的差异。对应于集成学习中的boosting算法,随着模型迭代偏差不断降低。
方差是指是不同的训练数据集训练出的模型输出值之间的差异。对应于集成学习中的bagging算法,通过取各分类器的平均来降低模型的方差。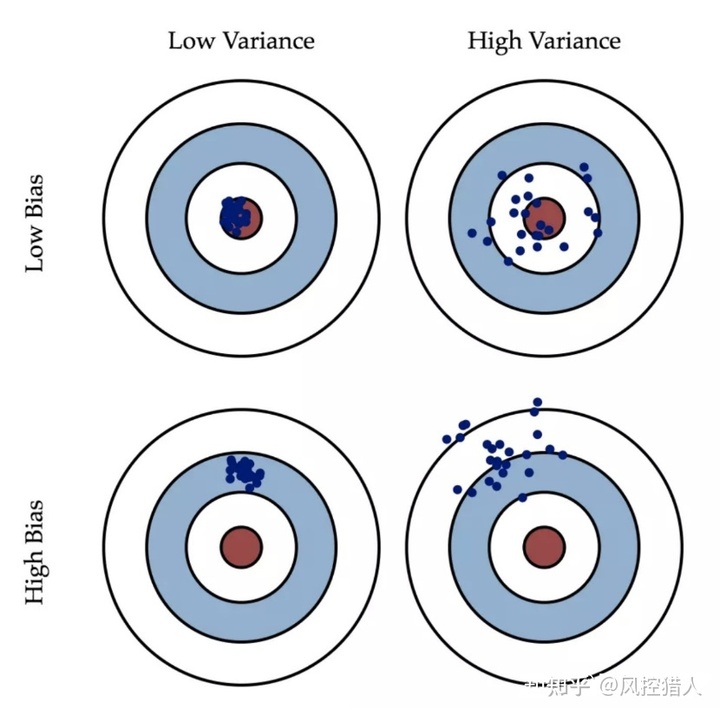
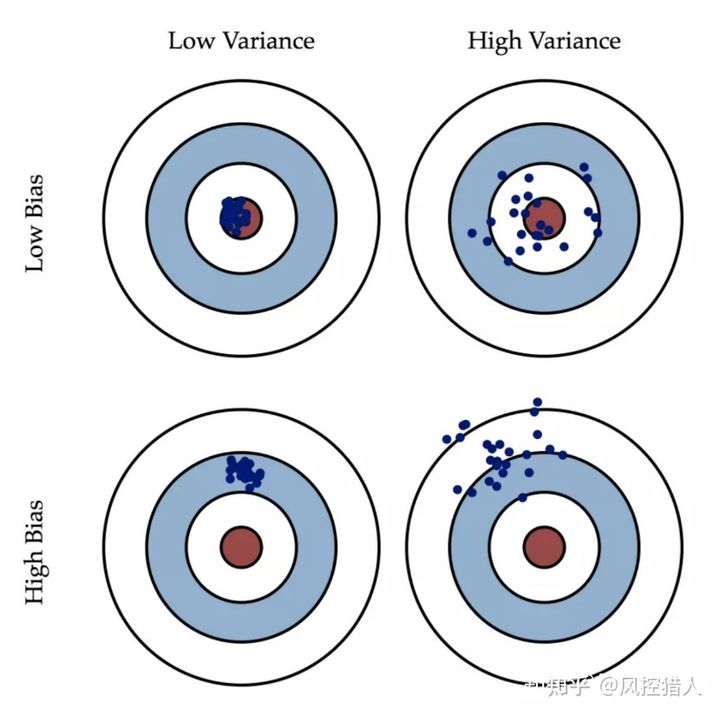
模型过于简单必然导致偏差过大,体现为欠拟合,需要通过特征工程、减小正则化系数提高模型预测精度;过于复杂必然导致方差过大,体现为过拟合,可以增加样本、减少特征、增加正则化系数来简化模型。
参考文章
冠军/挑战者试验(A/B Test)
https://zhuanlan.zhihu.com/p/144924899
信贷风控中Vintage、滚动率、迁移率的理解
https://zhuanlan.zhihu.com/p/81027037
风控模型—群体稳定性指标(PSI)深入理解应用
https://zhuanlan.zhihu.com/p/79682292
*风控模型—特征稳定性指标(CSI)深入理解应用
https://zhuanlan.zhihu.com/p/86559671
疫情期间的风控方案调整策略
六、什么是风控系统
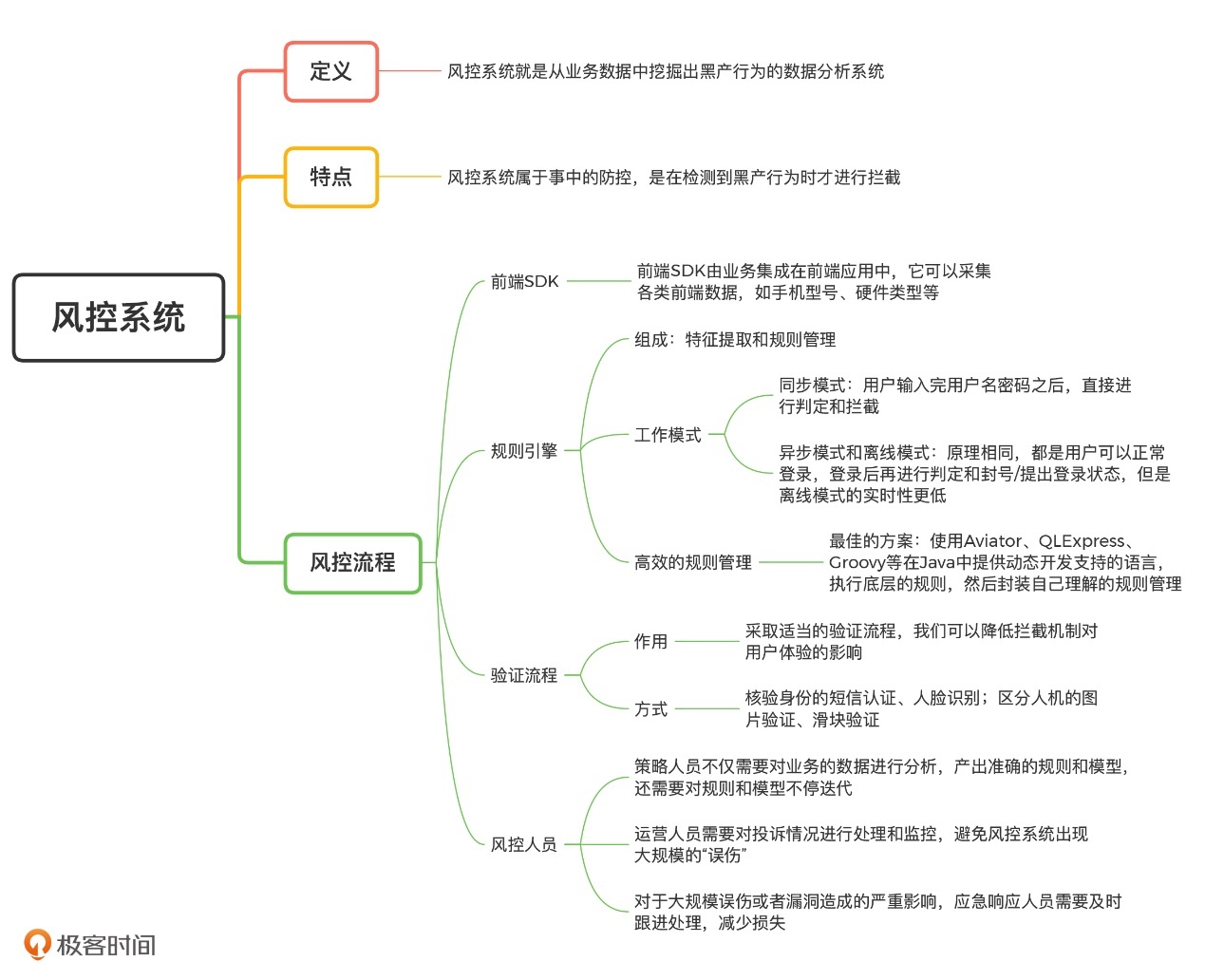
风控系统就是从业务数据中挖掘出黑产行为的数据分析系统。
总结来说:产品方案属于事前的防控,是从根本上提高黑产操作的成本;风控系统属于事中的防控,是在检测到黑产行为时才进行拦截。
目前,风控系统的整体框架已经基本成熟了,各个公司的风控系统也都大同小异。一般来说,一个完整的风控系统框架应当包括前端 SDK、规则引擎和验证流程。但是,一个完整的风控流程还需要人工进行数据分析、处理用户投诉、监控舆情,并采取应急响应机制。完整的风控流程如下图所示: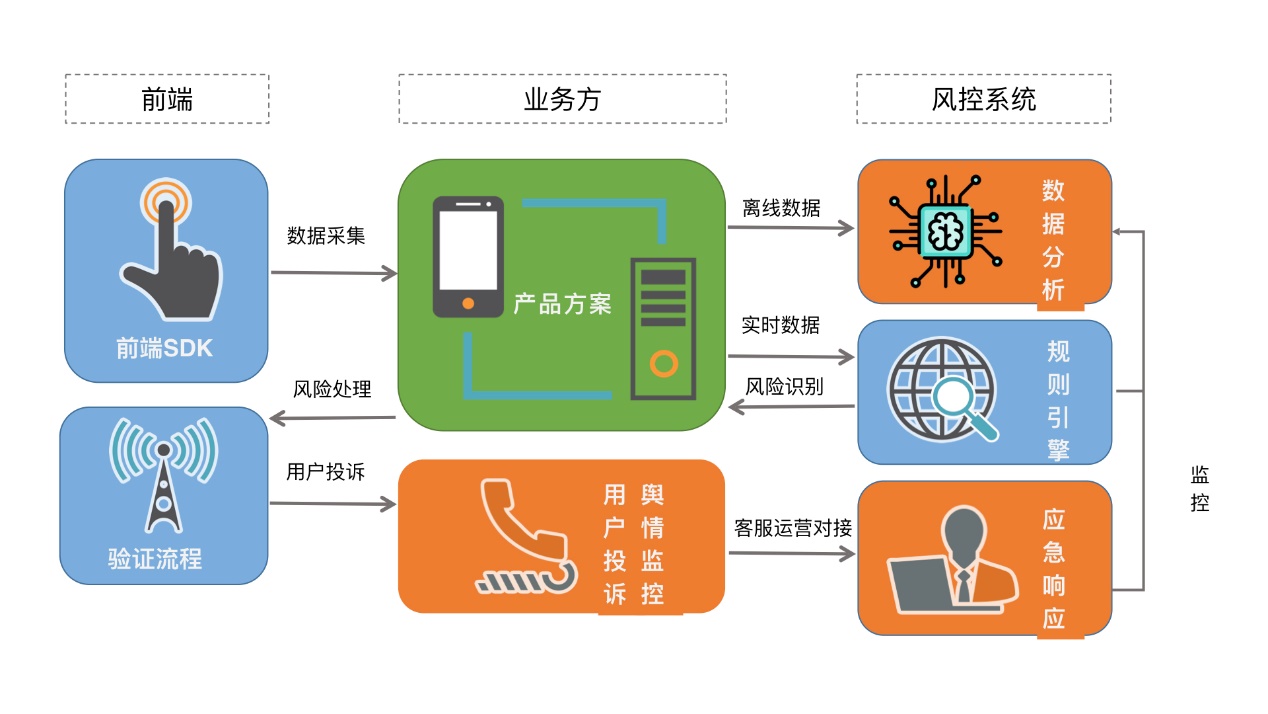
1.风控系统如何利用前端 SDK 采集数据?
想要在风控中做好数据分析,数据当然是越多越好。我们只有尽可能多地采集各类用户的数据,才能够更准确地识别黑产。各类用户数据包括用户身份信息、行为记录、设备类型、鼠标或者屏幕点击轨迹等。但是,业务在正常的开发过程中,一般不会采集和业务无关的数据(比如设备相关的信息)。为了解决这个问题,风控系统通常会提供一个前端 SDK。前端 SDK 由业务集成在前端应用中,它可以采集各类前端数据,如手机型号、硬件类型等。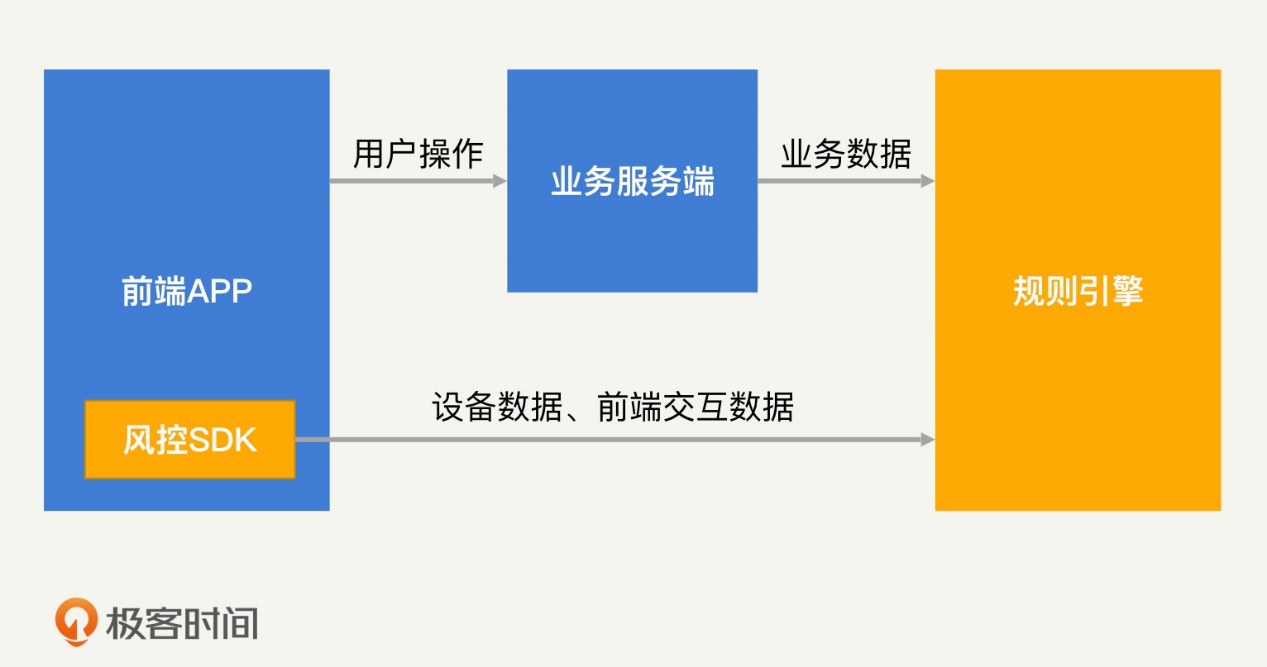
除此之外,前端 SDK 还会计算出一个唯一的设备指纹,通过这个设备指纹,我们就能够实现对设备行为的追踪。
(设备指纹是指可以用于唯一标识出该设备的设备特征或者独特的设备标识。)
设备指纹包括一些固有的、较难篡改的、唯一的设备标识。比如设备的硬件ID,像手机在生产过程中都会被赋予一个唯一的IMEI(International Mobile Equipment Identity)编号,用于唯一标识该台设备。像电脑的网卡,在生产过程中会被赋予唯一的MAC地址。这些设备唯一的标识符我们可以将其视为设备指纹。
2.规则引擎如何帮助风控系统识别黑产?
举个例子,想要从登录行为中识别出黑产,仅仅知道设备指纹是不够的,我们还需要知道,这个设备在最近一段时间内发起了多少次登录请求。这就是特征提取需要进行的工作了。经过特征提取得到特征之后,我们就需要制定规则对登录行为进行判定。比如说,我们可以定义,一个设备在 1 分钟内登录 5 次的行为属于异常行为,应当进行拦截。这样一来,当有新的登录行为发生时,通过规则引擎,我们就可以直接判定其是否为黑产。规则引擎的识别过程如下图:
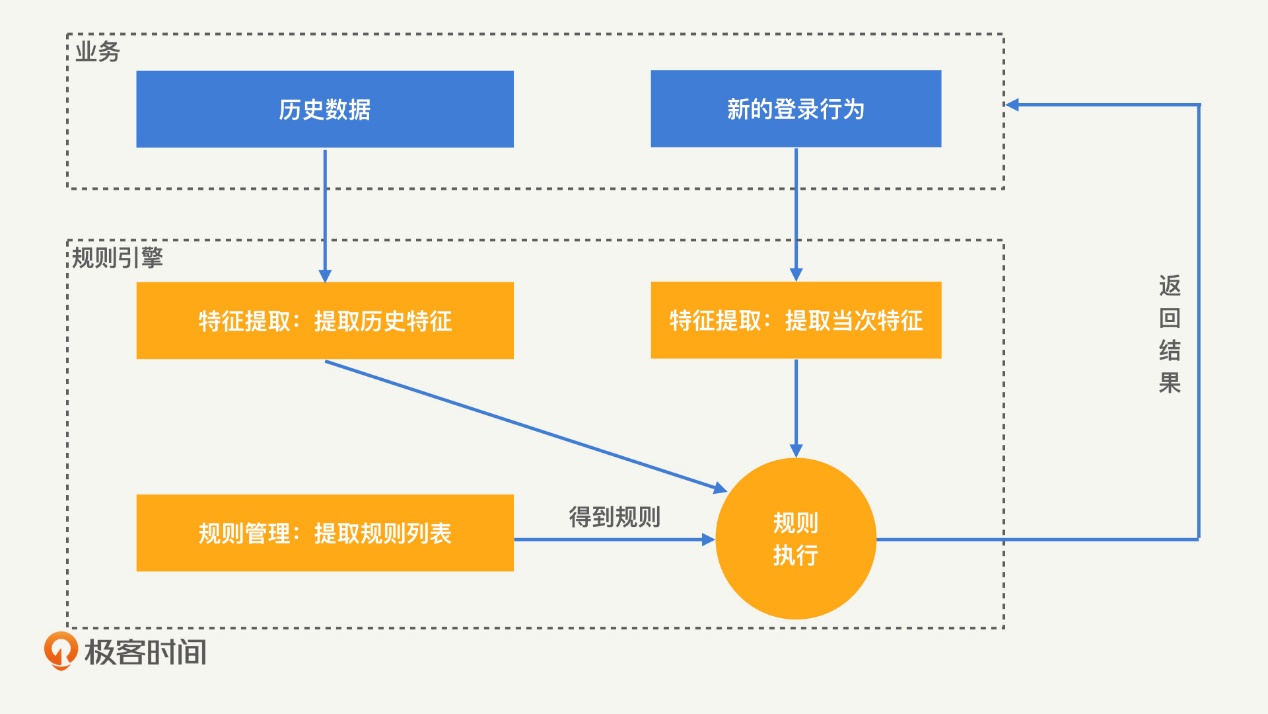
那么,应该如何做好一款规则引擎呢?我认为关键在两个方面:采用正确的工作模式、设计高效的规则管理功能。下面,我们就来具体看一下。
2.1 正确的工作模式
规则引擎可以分为同步、异步和离线三种模式。
下面,我就以登录场景为例,为你解释一下这三种模式的工作过程。
在同步模式下,用户输入完用户名密码之后,需要先经过规则引擎的判定,只有正常用户才能够正常登录,黑产则直接被拦截,不允许登录。
在异步模式下,用户一开始是可以正常登录的,登录后才交由规则引擎判定,如果最终确定是黑产,则会被封号或者踢出登录状态。
离线模式的效果和异步模式一致,不过异步模式通常会在几秒到几分钟的时间内完成判定和处罚,离线模式则需要几小时甚至一天的时间才能够完成判定。
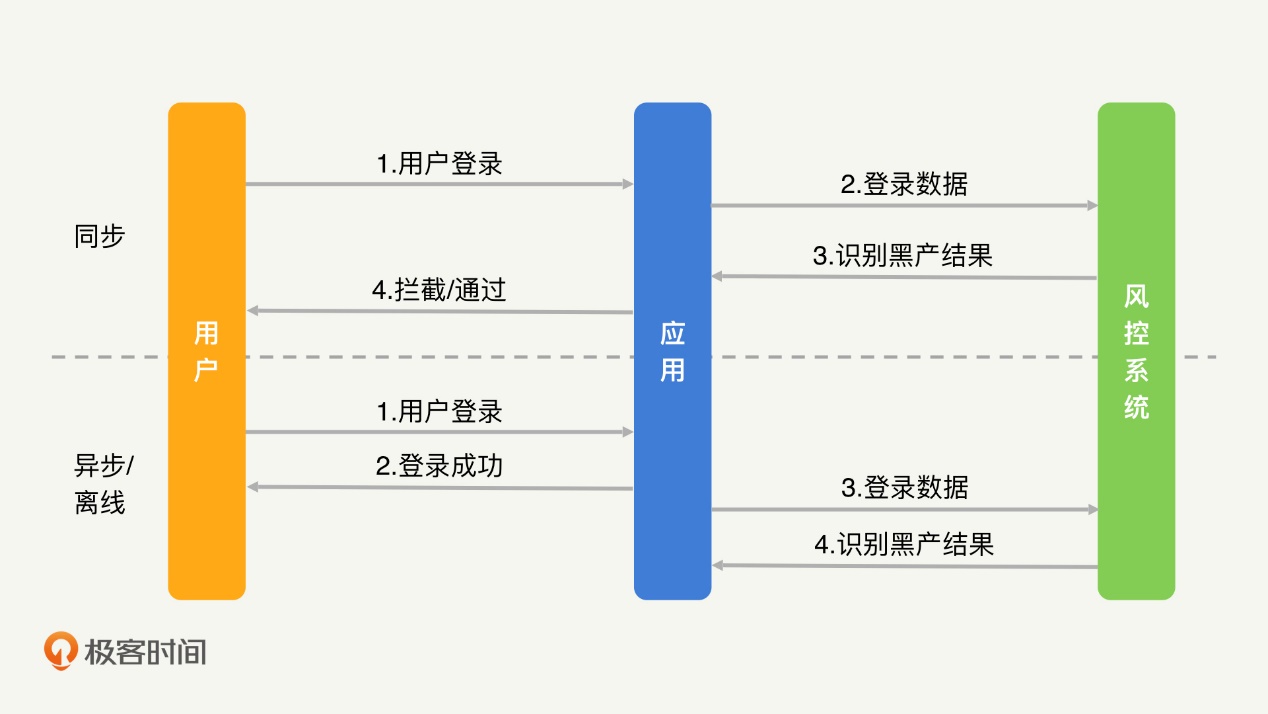
们知道,实时性越高、对黑产拦截得越及时,黑产所能够获得的收益也就越少。那是不是我们都采用同步模式就好了呢?当然不是。相比于同步模式,异步和离线模式在业务接受度和数据分析能力上都更优。下面,我们来具体分析一下。
同步模式需要侵入到业务的正常流程中,这对于业务来说,一方面会产生较高的接入改造成本,另一方面,也给业务的正常运行带来风险。因此,我们经常会遇到业务不接受同步模式的情况。
其次,实时性越高,我们获得到的信息就越少。以登录的场景为例,同步模式下的拦截行为发生在成功登录之前,所以,我们无法知道用户名密码是否正确。异步和离线是事后的分析,所以我们能够知道用户是否登录成功。显然,连续登录失败比连续登录成功更可疑。因此,用户是否登录成功这个信息,对于我们提升识别准确率会有很大的帮助。
因此,在大部分情况下,我更推荐使用异步或者离线模式,仅在部分没办法做事后的拦截和处罚的业务场景中,我们才会使用同步模式。
最后,即使是使用同步模式,我们也需要使用异步和离线模式做数据分析和规则验证,这样才能保障同步模式的判定结果不会出现太大的误伤。
因此,在大部分情况下,我更推荐使用异步或者离线模式,仅在部分没办法做事后的拦截和处罚的业务场景中,我们才会使用同步模式。
举个例子,在提现操作中,提现成功后,钱就已经从公司转移到黑产手里了,我们没有办法追回,因此我们必须采用同步模式,在提现操作前对黑产进行拦截。
2.2 高效的规则管理
如果你做过数据分析工作,一定知道同步、异步、离线其实都是数据分析工作中常见的模式,已经有很成熟的工具来为它们服务了,比如:通过 Redis 完成实时计算;通过 Flink 完成异步计算;通过 Hive 完成离线计算等。
但是,我认为特别“完美”的规则引擎还没有出现。因为规则管理有较高的复杂性和独特性。换一句话说就是,想要新建一条规则并执行是一件很容易的事情,但如何高效管理成百上千的规则,让风控人员和业务人员能够清晰地看到每个规则的效果、准确率和实际意义,是一个很有挑战性的工作。
就拿最出名的开源规则引擎Drools来说吧。Drools 定义了一套自有的 IF 匹配语言 DRL,并提供了基于Rete 算法的高效规则执行功能。然而,Drools 并没有提供十分高效的规则管理工具。
总结来说,规则引擎是风控系统的核心。想要做好一个规则引擎,我们需要思考清楚两件事情:第一,规则引擎以什么样的模式接入业务;第二,如何进行规则管理。
2.3 风控系统为什么需要经过验证流程才能拦截黑产?
规则引擎的判定结果永远存在“误伤”
为了解决这个问题,风控系统中加入了验证流程。采取适当的验证流程,我们可以降低拦截机制对用户体验的影响。所以,在上面的例子中,网站会使用滑块验证码来验证你是否是黑产。基于业务场景的不同,验证的方式还有很多,比如,核验身份的短信认证、人脸识别,区分人机的图片验证、滑块验证等。很多应用都会对存疑的用户和行为施加各种验证流程,来保障用户身份的真实可靠。所以,为了让风控系统成功落地,验证流程是我们不能忽视的一个环节。
2.4有哪些风控人员?
和 SIEM 一样,风控系统的成功运行离不开各类人员的持续投入。
风控人员一般分为策略人员、运营人员和应急响应人员。
下面,我就来说说他们是如何推动风控系统落地的。在规则引擎中,策略人员需要对业务的数据进行分析,产出准确的规则和模型。而且,随着和黑产的对抗升级,策略人员还需要对规则和模型不停迭代。
除了数据分析和规则迭代以外,规则引擎的“误伤”也必然会导致部分用户的不满和投诉。因此,运营人员需要对投诉情况进行处理和监控,避免风控系统出现大规模的“误伤”。同时,因为会有的黑产高调宣扬自己从业务中获利的成功经历,所以,运营人员还需要对黑产的言论和动向进行把控,来感知风险。
最后,对于大规模误伤或者漏洞造成的严重影响,应急响应人员需要及时跟进处理,来进一步减少业务的损失。
七、设备指纹
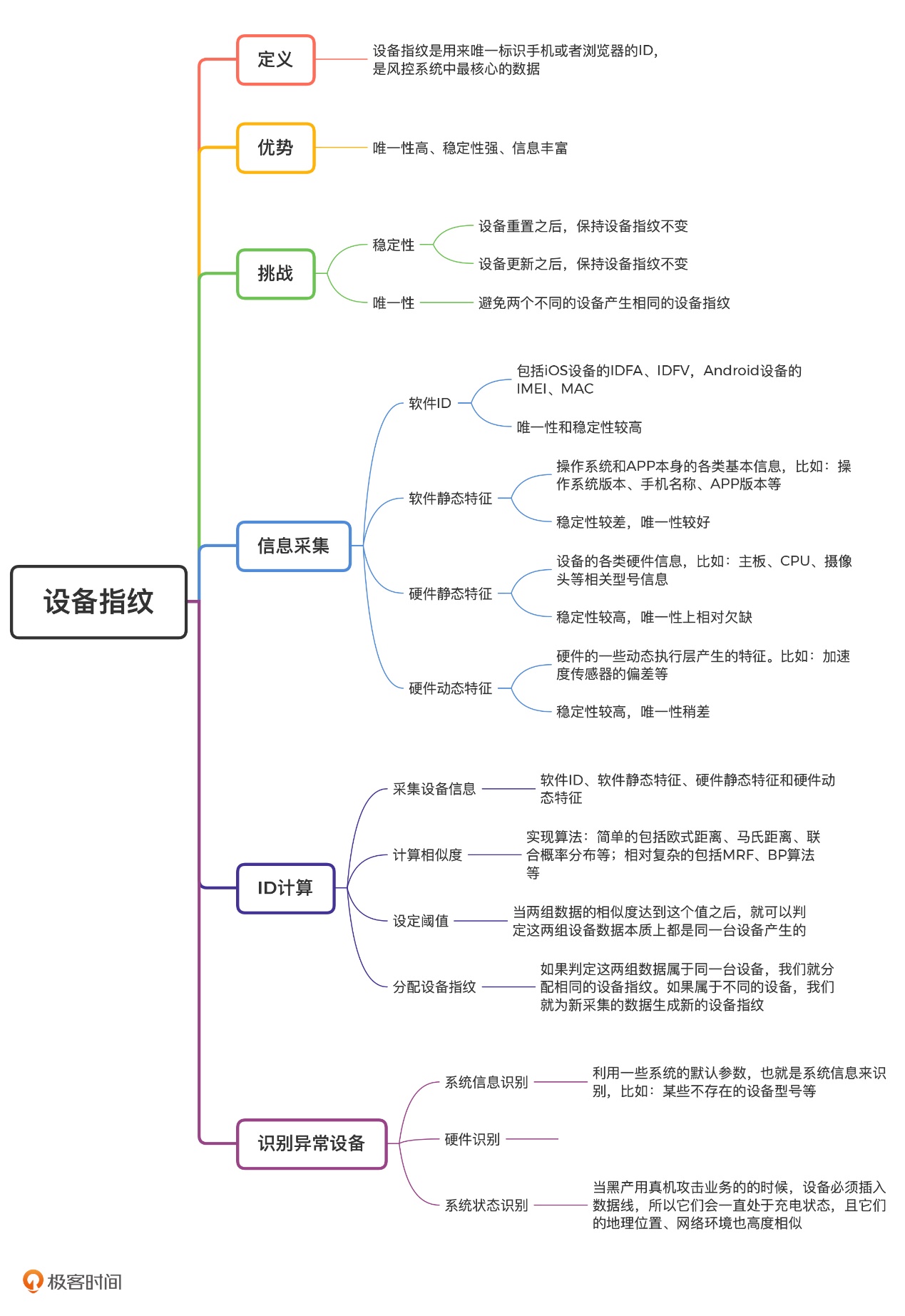
设备指纹的 ID 计算
因此,我们可以判定设备信息 A 和设备信息 B 实际上属于同一个设备,应该分配相同的设备指纹。
上面的判定过程进一步抽象的话,其实就是计算两组数据的相似度,相似度越高、差异度越低,就越有可能是同一个设备。
下面,我们就来看一下,实际工作中是如何利用相似度进行判定的。首先,新采集上来一组设备信息,我们要计算它和已有设备信息的相似度。可实现的算法有很多,简单的包括欧式距离、马氏距离、联合概率分布等,相对复杂的包括 MRF(马尔可夫随机场)、BP 算法(置信度传播算法)等。
设备指纹分配的流程图: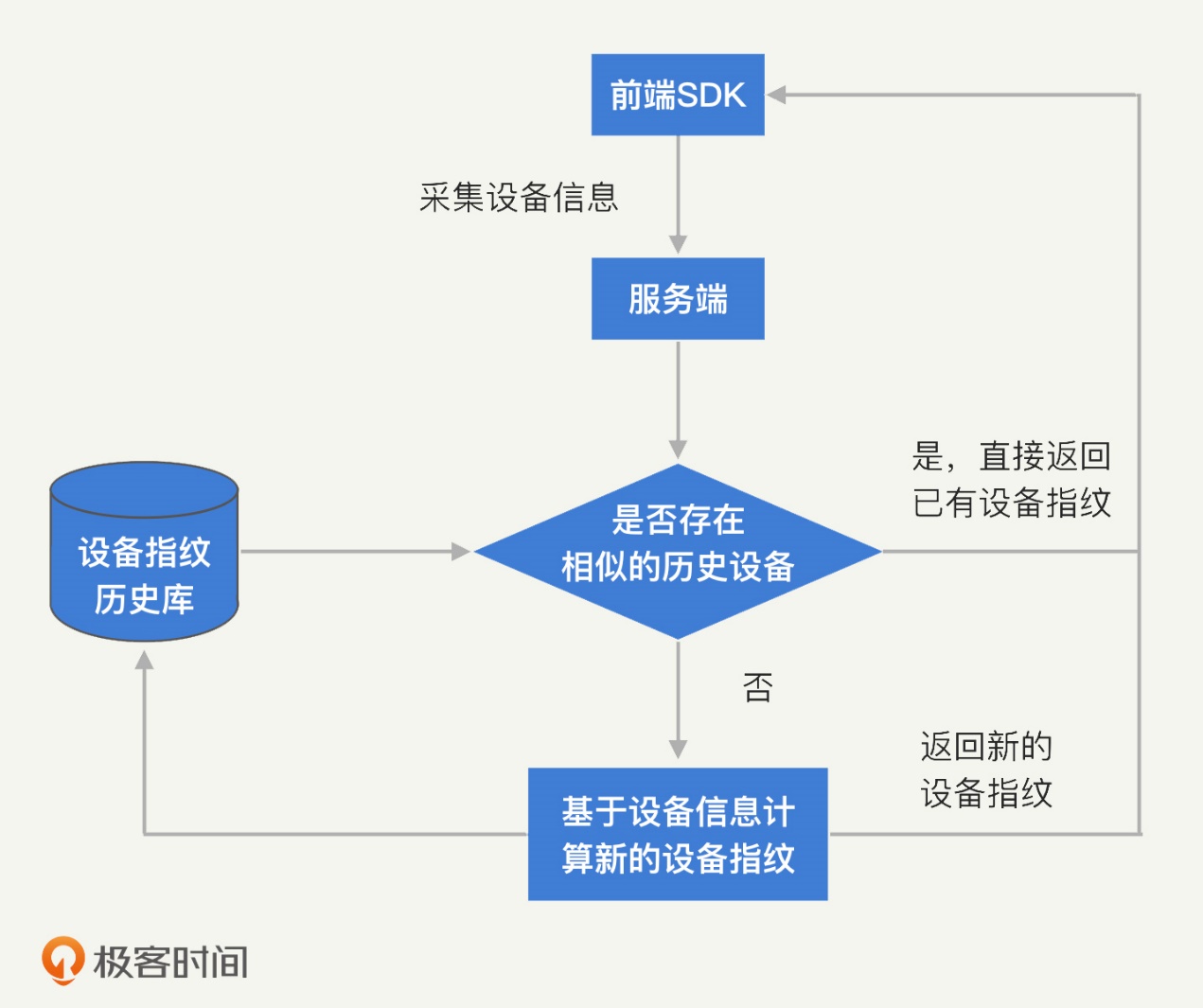

若有收获,就点个赞吧
0 人点赞
