1 打开示例数据和网络数据:use
示例数据为 STATA 帮助文件中所用的数据,其后辍名为.dta,如果在 STATA软件当前路径下,直接用 use 命令即可打开;如果不在当前路径下,则可以使用sysuse 命令打开。
从网络获取数据
. use http://www.stata-press.com/data/r9/nlswork //从网站获取数据,或者. webuse nlswork, clear //与前一命令等价,从 STATA 官方数据库获取数据
use 命令只能打开后辍名为“*.dta”格式的数据,.dta 格式以外的数据,STATA不能直接读取,需要从外部读入,最简单而直接的办法是复制和粘贴。
2 数据类型
STATA 通常把变量划分为三类:分别是数值型,字符型和日期型
1 数值变量

. compress //在不损害信息的基础上压缩,使数据占用空间尽可能小. replace a=32741 //直接变到 long 型,因为 int 型最大只能到 32740. gen double b=1 //直接生成双精度变量 b. recast double a //将 a 变成双精度变量 b. d //注意到 a 和 b 均为双精度型
2 字符串变量
字符串变量由字母或一些特殊的符号组成(如地名〈籍贯〉变量,迁出地,住址,职业等等)。字符串变量也可以由数字来组成,但数字在这里仅代表一些符号而不再是数字。字符串变量通常以引号“”注标,而且引号一般不被视同为字符的一部分,注意这里的引号必须是英文输入状态下的引号。
字符串最多可以达 244 个字符。一般用 str#来表示字符的多少,如 str20表示将有 20 个字符。一般三个中文字的姓名需要 6 个字符。
字符型示例
“String” “string” ” string” ”string ”
“” //特殊字符串,表示空字符,缺失值。
“ “ //注意与空字符串的区别,含有一个空格
”125.27” //”125.27”由于有双引号,将被视同为字符而非数值。
“$2,343.68” “I love you” “旺材是条狗”
注意前四个字符串均不相同,大小写是不一样的,有无空格及空格的位置不同,都表示不同的字符串。对于”125.27”这样的数值型的字符串,可以用 real()函数或者 destring 命令转化成数值型变量。
3 日期型变量
在 STATA 中,1960 年 1 月 1 日被认为是第 0 天,因此 1959 年 12 月 31 日为第-1 天,2001 年 1 月 25 日为 15000 天。对日期型变量的讨论将在后面的时间序列分析部分
1999 12 10
jan/10/2001
10jan2001
…
-15,000 —- 01dec1918
-31 —-01dec1959
…
-1 —- 31dec1959
0 —- 01jan1960
1 —— 02jan1960
4 缺失值
没有意义的计算结果显示为”.”
. display 2/0
另一种情况是,数据中含有缺失值,而 STATA 默认的缺失值也用“.”来表示。在有些数据文件中,缺失值不是用“.”或者空来表示的,而是用-9996 等
来表示,如果要将其全部替换为“.”,或者反之,将“.”替换为-9996,命令为:
. mvencode age,mv(-9996). mvdecode age,mv(-9996)
3 数据类型转化
任务:将 destring1, destring2 和 tostring 中的数据类型进行相互转化
1 字符型转化成数值型:destring
.destring, replace //全部转换为数值型,replace 表示将原来的变量(值)更新
.sum //注意到转换为数值型后,可以求五数概略了
*————————将字符型数据转换为数值型数据:去掉字符间的空格——————
实验:测试有点问题
gen d = "123"destring, replace
时间数据
*destring2 数据集中的 data 变量为字符型,且年月日间有空格,转移为数据型.webuse destring2, clear.des //注意到所有的变量均为字符型 str.list date //注意到 date 年月日之间均有空格
date
1. 1999 12 10
1. 2000 07 08
1. 1997 03 02
1. 1999 09 00
.destring date, replace //想把 date 转换成数值型,但失败了,系统提示说date contains non-numeric characters; no replace /由于含有非数值型字符(即空格),因此没有更新,也即转换命令没有执行。*/.destring date, replace ignore(“ ”) /忽略空格,然后转换,注意这里的" "中间有一个空格,不是""。/date: characters space removed; replaced as long //成功转换为 long 型.des //注意到 date 的 storage type 已变为 long.list date //注意到空格消失了
date
1. 19991210
1. 20000708
1. 19970302
/与 date 变量类似,变量 price 前面有美元符号,变量 percent 后有百分号,换为数值型时需要忽略这些非数值型字符。/
美元等其它符号
/与 date 变量类似,变量 price 前面有美元符号,变量 percent 后有百分号,换为数值型时需要忽略这些非数值型字符。/
.destring price percent, gen(price2 percent2) ignore(“$ ,%”).list //注意到 price2 前面的$号消失,percent2 后面的%号消失
2 数值型转化为字符型:tostring
.tostring year day, replace //将年和日转化为字符型
4 数据显示格式:format
/format 只控制数据的显示格式,并不改变内存中数据的大小。/
*注意到, stata 变量的格式为%14s,表示右对齐,共 14 个字符,%为固定用法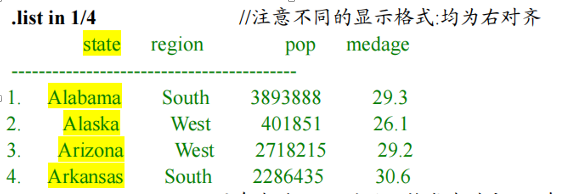
.format state %-14s // 该命令使 stata 的显示格式左对齐,14 前面多了个负号

.format pop %11.0gc /*pop 的显示格式为%11.0g,后面加上 c,则每三位数间用逗号分开,c 为 comma 的意思.*/
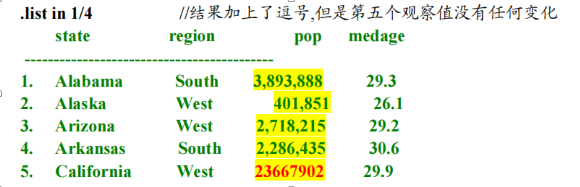
.gen id=_n //生成一个新变量 id,取值依次为 1,2,3.replace id=9842 in 3 //将 id 的第三个变量替换为 9842.list in 1/3

.format id %05.0f //对于编号,我们希望前面用零使得位数对齐.list in 1/3 //注意到通过在前面补零,所有的 id 都成了 5 位数。

5 在 STATA 中直接录入数据:input
1 菜单式操作
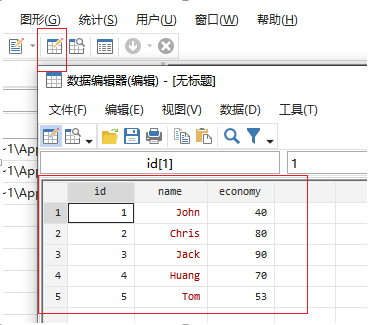
2 命令操作
操作:在 command 窗口中键入(注:前面的点号不必健入,每完成一行按回车键,黑体为命令,斜体为变量名或文件名):对于字符型变量,需要指明其为字符型
并指明最大的字符长度。
• clear //清空内存• input id str10 name economy //输入变量名,特别注意姓名前的 str10.• 1 John 40 //录入第一个学生的学号和成绩• 2 Chris 80 //录入第二个学生的学号和成绩• 3 Jack 90• 4 Huang 70• 5 Tom 53• end //录入数据结束• save economy //保存数据到当前路径,文件名为 economy
3 程序操作
(1)打开 do file editor,键入以下内容:
cd E:/学习/stataclear //清空内存input id str10 name economy //输入变量名,特别注意姓名前的 str10.1 John 40 //录入第一个学生的学号和成绩2 Chris 803 Jack 904 Huang 705 Tom 53end //录入数据结束save economy //保存数据到当前路径,文件名为 economy
(2)保存程序文件为 mydo
(3)点击 ,执行后得到数学成绩
6 导入导出其他格式数据
经常会遇到的情形是:我们有其他格式的数据,需要导入到 STATA 中进行分析,建议大家此时将其他格式数据复制到分析数据的文件目录下,然后直接用
STATA 的导入数据文件命令导入原始数据,用程序模式进行处理,然后导出处理结果。这样做的最大好处是:既不会破坏最原始的数据文件,又使我们的每一步数据处理和分析过程都有迹可循。
1 insheet 命令
注意切换到test.csv的目录下:
cd E:/学习/stata/test_learninsheet using test.csv, clear
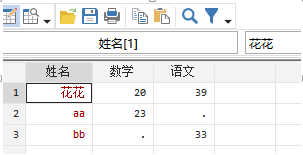
2 infile 命令
对于“3origin.txt”或“3origin.csv”,还可用 infile 命令导入 STATA,此时需要先指出变量名。尤其要注意,当变量为字符型时,要先指明。
infile id str10 name gender minority economy math using origin.csv, clear
3 infix 命令
还有一种标准化的数据,每个变量的位数是确定的,不足时,前面用 0 补齐,
114068
128052
029076
024390
如果遇到这种数据格式,需要对照数据说明导入数据,相应的命令为:
infix gender 1 minority 2 economy 3-4 math 5-6 using origin.csv, clear
4 outsheet 命令
与前述三个命令相反,有时我们需要将 STATA 数据导出为其他格式数据,比如文本格式或后缀为 acs 的格式:此时需要使用 outsheet 命令实现,该命令的
基本格式如下。
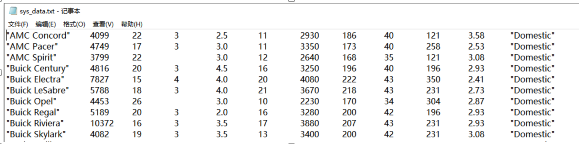
outsheet using sys_data.txtoutsheet using sys_data.asc
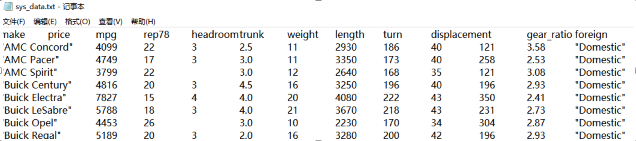
此时建立的文件 sys_data.txt 第一行为变量名,第 2~6 行为变量值。变量列间用Tab 键分隔。如果不希望在第一行存储变量名,则可以使用 nonames 选项。如果文件已经存在,则需要使用 replace 选项,相应的命令分别为。
//
outsheet using sys_data.asc, nonamesoutsheet using sys_data.asc, nonames replace
5 使用 transfer 软件
Transfer 软件专用于转换不同格式的数据文件,使用起来非常方便。只需要在 input File Type 栏中选择需要转化的原数据文件类型,然后定位打开需要转化的原数据文件。再选定输出文件类型,指定输出文件的存放位置和文件名。最后点击 transfer 按钮。数据便被转化。该软件可在 http://www.pinggu.org/bbs 上下载试用,不过做正式工作,建议采用正版软件。
6 标签数据:label
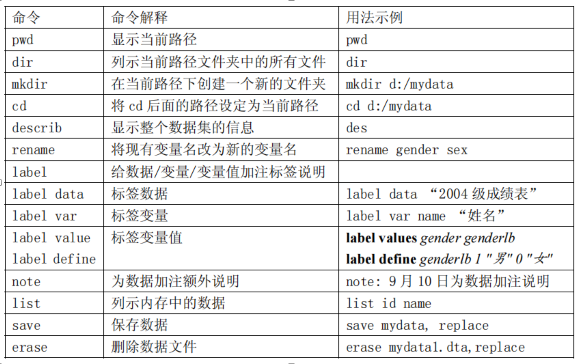
1 变量重命令:rename
2 标签文件:label data
/ 为避免时间太长,忘记变量的含义,我们可以用 label 命令来标记。该命令可以用来标记数据文件,如将文件取名为“2007 年秋 5632 班学习成绩单” /
label data “2021 econmy data”
在文件处理过程中加注说明,命令为
notesnote: 2021 econmy data
下一次打开数据,要查看创建和数据处理的说明时,直接键入
note
3 标签变量:label var
4 标签变量值:label define 和 label values
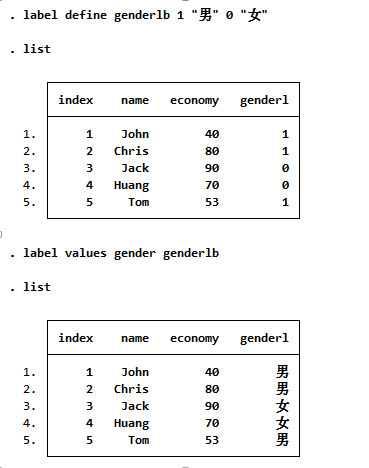
label define genderlb 1 "男" 0 "女"listlabel values gender genderlblist
5 标签增加与修改:add 和 modify
/ 定义完汉族和少数民族后发现还有些学生的民族是不知道的(原始值为 3),则/
label define minoritylb 3 ” 不知道”*然而结果窗口却显示出如下错误信息,label minoritylb already defined
因为 minoritylb 已经存在并被定义,我们需要加上选项,add
label define minoritylb 3 “不知道”, addlistlabel define minoritylb 3 “don’t know”, add
/_试图将“不知道”改为英文“don’t know”,再次显示错误 _invalid attempt to modify label 因为 3 已被定义,这次不是增加而是修改,所以选项为,modify*/
6 标签显示与删除:dir 和 drop
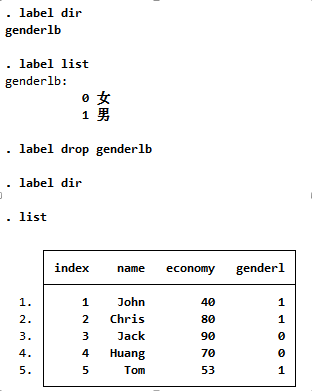
label dir //显示标签label list //显示标签的赋值含义listlabel drop genderlb //删除标签label dir //再显示标签list //注意到 genderlb 显示的是 0 1
7 保存和删除数据文件:save 和 erase
compress //压缩数据,使之在不损失任何信息的前提下占用空间最小
save mydata //保存数据,数据文件名为 mydata
*如果同一文件夹下已经存有 mydata.dta,而你又要再次执行 save mydata 时,
系统会出现提示
save mydatafile mydata.dta already exists*该提示表示数据已经存在,此时我们可以换名保存save mydata1*或者将原文件覆盖,方法是加上 replace 选项save mydata, replace*删除文件,eraseerase mydata1.dta*注意:删除文件时一定要带上后缀名。

若有收获,就点个赞吧
0 人点赞
