
1 列表字典集合过滤数据
列表
方法一:列表解析法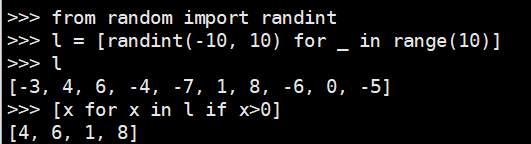
方法二:filter函数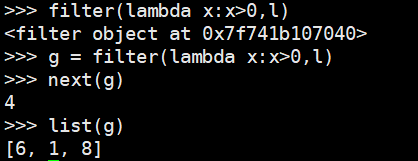
注意在python3中,将返回一个迭代器,next可以消耗迭代器元素。
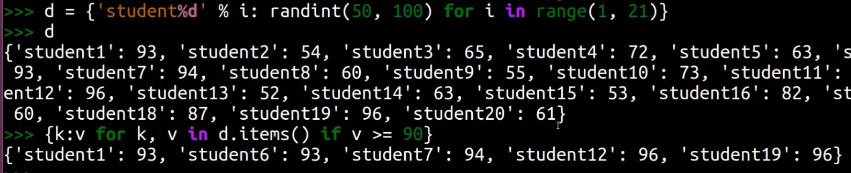
字典

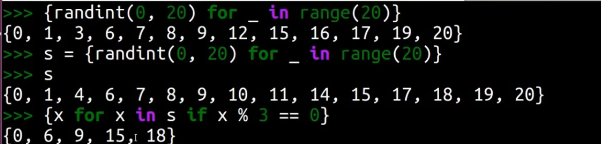
集合
2 如何为元组命名,提高程序可读性
由于元组要比字典节省空间很多,因此固定格式的文件通常用元组保存,但访问时,我们只能使用索引方式访问,大量索引降低了程序的可读性。为了可读性,需要进行转换。推荐方法二
方法一:定义数值常量或枚举类型

方法二:使用collections.namedtuple替代内置的tuple
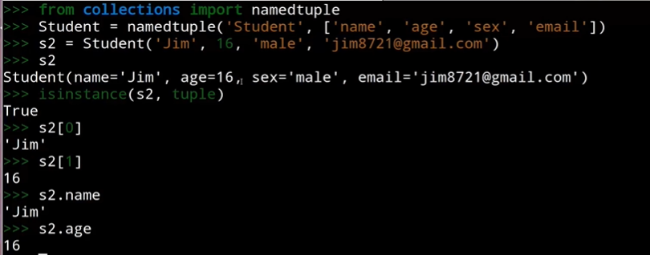
注意这里s2看起来像是类的对象,实际是元组,但是可以像访问对象一样访问其对应名称的值。
3 如何根据字典值得大小,对字典中得项进行排序
推荐方案2
例如:{“Liming”93,”lisiji”:22,”wangfei”:73},根据后面数字进行排名。
造数据:
from random import randintd = {k: randint(50,100) for k in 'abcdefg'}
方案1:将字典中得项转化为(值,键)元组,(列表解析或zip)
l = [(v,k) for k,v in d.items()] # 和这个等价 list(zip(d.values(), d.keys()))l # [(96, 'a'), (81, 'b'), (55, 'c'), (78, 'd'), (79, 'e'), (73, 'f'), (70, 'g')]
sorted(l, reverse=True) # [(96, 'a'), (81, 'b'), (79, 'e'), (78, 'd'), (73, 'f'), (70, 'g'), (55, 'c')]
方案2:传递sorted函数的key参数
sorted(d.items(), key=lambda item:item[1],reverse=True) #[('a', 96), ('b', 81), ('e', 79), ('d', 78), ('f', 73), ('g', 70), ('c', 55)]
加排序,注意不同的方式表达
list(enumerate(p, 1))#[(1, ('a', 96)),# (2, ('b', 81)),# (3, ('e', 79)),# (4, ('d', 78)),# (5, ('f', 73)),# (6, ('g', 70)),# (7, ('c', 55))]{k:(i,v) for i,(k,v) in enumerate(p, 1)}#{'a': (1, 96),# 'b': (2, 81),# 'e': (3, 79),# 'd': (4, 78),# 'f': (5, 73),# 'g': (6, 70),# 'c': (7, 55)}
4 如何统计序列中元素的频度
任务:例如统计出现次数最高的,比如统计英文单词数量。
建议使用下面的方案2
方案1:将序列转换为字典{元素:频度},根据值排序
data = [randint(0,20) for _ in range(40)]d = dict.fromkeys(data, 0) # 根据所有值,得到对应的key# {19: 0,# 4: 0,# 5: 0,# 3: 0,# 6: 0,# 0: 0,# 15: 0,# 8: 0,# 2: 0,# 18: 0,# 1: 0,# 9: 0,# 12: 0,# 7: 0,# 20: 0,# 17: 0,# 10: 0}
for x in data:d[x] +=1sorted(((v,k) for k,v in d.items()),reverse=True)[:3] # [(5, 6), (4, 15), (4, 3)] 这里内部使用元组,比list节省空间
import heapq# 也有heapq.nsmallest 函数可以使用heapq.nlargest(3,((v,k) for k,v in d.items())) # [(6, 5), (3, 4), (15, 4)]
方案2:使用标准库collections中的Counter对象
data = [randint(0,20) for _ in range(40)]from collections import Counterc = Counter(data)c.most_common(3) # [(6, 5), (3, 4), (15, 4)]
5 pickle 存取数据
from collections import dequeq = deque([],4)q.append(3)q.append(32)q.append(1)q #deque([3, 32, 1])import picklepickle.dump(q, open('save.pkl', 'wb')) # pickle必须以二进制q2 = pickle.load(open('save.pkl','rb'))q2 #deque([3, 32, 1])

若有收获,就点个赞吧
0 人点赞
