1 运算符 exp
STATA 共有四种运算,分别是代数运算、字符运算、关系运算和逻辑运算。
运算的优先序:!(或=),>,<,<=,>=,==,&,| 当忘记或者无法确定优先序的时候,最好用括号将优先序表达出来,在最里层括号中的表示式将被优先执行。
2 函数概览 function
函数只不过是一些编号的小程序,这些小程序会对数据按一定的规则进行处理,之后报告结果。实际上,谁也记不住这么多函数,因此,首先要学会查找函数的帮助,当记不住的时候,随时去查寻帮助。记住下面的命令才是最关键的。
. help function
Type of function See help
———————————————————+————————————-
Mathematical functions math functions
Probability distributions and
density functions density functions
Random-number functions random-number functions
String functions string functions
Programming functions programming functions
Date functions date functions
Time-series functions time-series functions
Matrix functions matrix functions
弹出来的对话框告诉我们,STATA 包括八类函数,分别是数学函数,分布函数,随机数函数,字符函数,程序函数,日期函数,时间序列函数和矩阵函数。
本章主要介绍数学函数和字符函数,其他函数将在后面相应的章节介绍。
常用函数一览表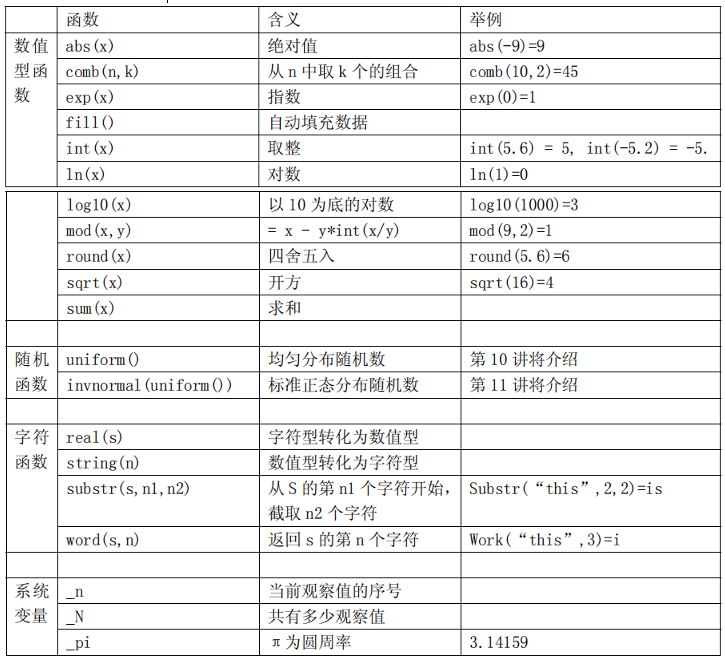
3 数学函数 math functions
1 三角函数,指数和对数函数
数学函数可以直接对数据进行运算,也可以对变量进行运算。
. di sqrt(4) //开方,输出 2. di sqrt(6+3) //先相加,再开方,输出 3. di abs(-100) //求绝对值,输出 100. di exp(1) //表示 e1//输出 2.7182818. di ln(exp(2)) //先求 e2,再取对数,得到 2. di pi //pi 为圆周率,得到 3.1415927. di cos(pi) //pi 的余弦值,得到-1
数学函数可以直接对数据进行运算,也可以对变量进行运算。
对变量的操作:
clearset obs 5 //设定 5 个观察值gen x=_n //生成新变量 x,取值为 1,2,3,4,5gen y1=exp(x) //取指数gen y2=ln(x) //取对数gen y3=sin(exp(x) ) +cos(ln(x)) //取对数l //显示刚生成的数据
2 取整和四舍五入
取整
. di int(3.49) //int()取整,不论后面的小数是什么,只取小数点前的数值. di int(3.51) //输出 3. di int(-3.49) //输出-3. di int(-3.51) //输出-3
四舍五入
. di round(3.49) //round()取整,四舍五入,结果为 3. di round(3.51) //四舍五入,结果为 4. di round(-3.49) //四舍五入,结果为-3. di round(-3.51) //四舍五入到个位数,结果为-4. di round(3.345,.1) //四舍五入到十分位,结果为 3.3. di round(3.351,.1) //四舍五入到十分位,结果为 3.4. di round(3.345,.01) //四舍五入到百分位,结果为 3.35. di round(3.351,.01) //四舍五入到百分位,结果为 3.35. di round(335.1,10) //四舍五入到十位,结果为 340
对变量的操作
. sysuse auto, clear. gen nprice=price/10000 //将价格变到以万为单位. gen nprice2=round(nprice,0.01) //四舍五入到百分位. list nprice* //比较结果
3 求和及求均值 gen 和 egen
clearset obs 5gen x=_n //生成新变量 x, x 的取值从 1 到 5gen y=sum(x) //求列累积和egen z=sum(x) //求列总和,注意比较 y 和 Z 的不同egen r=rsum(x y z) //求 x+y+z 总和egen havg = rowmean(x y z) //求 havg=(a+b+c)/3egen hsd = rowsd(x y z) //求 a、b 和 c 的方差egen rmin = rowmin(x y z) //求 x y z 这三个变量的最小值egen rmax = rowmax(x y z) //求 x y z 这三个变量的最大值list //注意比较 y 和 z 的不同。egen avgx=mean(x) //求列均值egen medx=median(x) //求列中值egen stdx = std(x) //求变异系数 cvi=(xi-mx)/s,注意 s=Σ(xi-mx)2/(n-1)replace y=3 in 3egen byte dxy = diff(x y) //当 x 与 y 相等时,differ 取 0,若不相等为 1
更多关于 egen 命令的用法将参考帮助:help egen
4 其他
sysuse auto, clearegen rmpg = rank(mpg) //求 mpg 的次序sort rmpglist mpg rmpg //列示结果egen highrep78 = anyvalue(rep78), v(3/5) /若 rep78 不为 3、4 或 5, 则为缺失值/list rep78 highrep78clearinput a b1 00 01 10 10 01 .. 0endegen ab=group(a b) /按 a 和 b 来进行交叉分组,a=0,b=0 为第一组,…,a=1,b=1 为第四组,缺失值不参与分组/egen ab2=group(a b),missing //将缺失的组当作另外的一组l //显示分组结果

clearset obs 100 //设定 100 个观察值gen age=_n //生成一个假设的年龄变量 age,依次取 1,2,…,100recode age (min/30=1) (30/60=2) (60/max=3),gen(agegrp)/生成新的分组变量 agegrp,当年龄 age 在 30 及以下时取值为 1,30 到 60 为 2,60 以上为 3,感觉操作也是太简单了/
4 字符函数 string functions
任务:将美国汽车数据中汽车商标变量值简化为取前三个字母,得到一个新的变量 make3
sysuse auto, cleargen str3 make3=substr(make,1,3) //取变量 make 的前三个字符赋给 make3list make*
任务:下表的数据是一个多选题,请把这道多选题转化为四个单选题,例如变量a 表示“你今天早餐吃的是:1 稀饭 2 馒头 3 大饼 4 豆腐脑”。变量 a 不容易处理,可以用以下命令转化为四个 0-1 变量,分别为 na1=是否吃稀饭,na2=是
否吃馒头…
gen na1=strpos(a, "1")!=0 /*strops(s1,s2)返回字符 s2 在 s1 中的位置,如果在 s1 中找不到 s2,则返回 0。上述命令是实际上有两步,先得 0 或非零,然后判断转化为 0-1。gen na2=strpos(a, "2")!=0gen na3=strpos(a, "3")!=0gen na4=strpos(a, "4")!=0

di word(“this is a dog”,4) //显示第四个字母 dog
5 分类操作 by
任务:下列数据为家庭成员数据 family.dta,其中 hhid 为家庭编码,age 为家庭成员的年龄。将下表数据复制到 STATA,然后另存为 family.dta
要求:
(1)生成一个新变量 hhsize,该变量表示共有多少个家庭成员。
(2)给每个家庭成员一个编码 id。如第一个家庭的第一个成员编码为 11;
(3)按家庭生成一个全家成员平均年龄值 mage。
(4)对每个家庭,分别按年龄大小排序,然后生成一个家庭成员代码,即家庭内年龄最小的成员代码为 1,年龄最大的家庭成员,代码为 nid。
最后需要生成的数据集如下: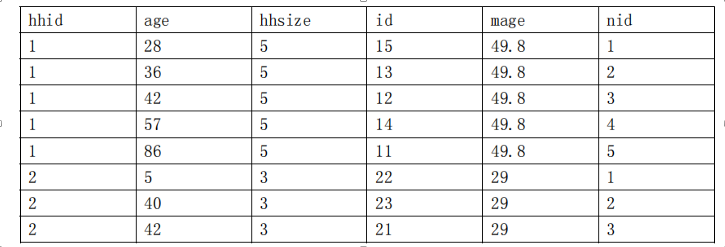
请自己先思考,再参考如下操作 :
将上表数据复制粘贴到 STATA 数据编辑器,然后执行下面的命令
use family, clearby hhid,sort :gen hhsize=_N //得到家庭规模 hhsizeby hhid,sort :gen id=_n+hhid*10 //为家庭成员编码by hhid,sort: egen mage=mean(age) //求平均年龄sort hhid age //按户排序,在每个户内按年龄大小排序by hhid: gen nid=_n //在户内按年龄大小为家庭成员编码use family, clearbysort hhid (age): gen nid1=_n //括号中的变量 age 只排序,不参于分组。bysort hhid age: gen nid2=_n // hhid 和 ag e 都既用来参与排序也分组list //比较上面两个命令得到的不同结果webuse stan2, clearexpand 2 if transplant //将 transplant==1 的观察值再复制一个sort idby id: generate byte posttran = (_n==2) /*生成一个新变量 posttran,使得 对同一个人,第一个观察值取 0,第 二个观察值取 1*/by id: generate t1 = stime if _n==_N /*生成新变量 t1,使得在同一个 id 下, 对第二期取值为 stime,否则为“.”gsort –id

若有收获,就点个赞吧
0 人点赞
