1 掌握命令语句的格式
[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]
注:[ ]表示可有可无的项,显然只有 command 是必不可少的,下面结合例子分
项来讲解命令的各个组成部分。
2 命令 command
[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]
. cd d:/stata9
. use auto, clear //打开美国汽车数据文件 auto.dta,后面的 clear 表示先清除内
存中可能存在的数据集
. summarize /很多命令可单独使用,单独使用时,一般是对所有变量进
行操作,等价于后面加上代表所有变量的_all。 /
. summarize _all //注意到该命令输出结果与上一个命令完全一样
. sum //与前一命令等价,sum 为 summarize 的略写
. su // su 是 summarize 的最简化略写,不能再简化为 s
. s //简写前提是不引起混淆。执行这个命令将出现错误信息
unrecognized command: s
3 变量 varlist
[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]
varlist 表示一个变量,或者多个变量,多个变量之间用空格隔开。
. cd d:/stata17. use auto, clear. sum price //求价格的观察值个数,平均值,方差,最小值和最大值. su p //变量和命令均可略写,注意到两个结果完全一样. su t //分数据中有两个变量的开首字母为 t(trunk 和 turn),所以STATA 认为 t 为模糊的省略。. sum tr tu //求 trunk 和 turn 变量的五数概略统计. su t //等价于前一命令,以 t 开首的所有变量可用 t来表示。
4 分类操作 by varlist
by foreign: sum price weight //分别计算国产车和进口车的价格和重量
但如果执行下面两个命令,将出现错误*/
. sort price //按价格从低到高重新排序. by foreign: sum price weight*not sorted/ 系统提示没有排序,这是因为 by varlist 在执行时要求内存中的数据是按照by 后面的变量排序的。当我们用 sort price 重新排序后,就打乱了原来按照foreign 的排序,所以出现了错误提示。更正的办法是:/. sort foreign //按国产车和进口车排序. by foreign: sum price weight*更简略的方式是把两个命令用一个组合命令来写。. by foreign, sort: sum price weight//如果不想从小到大排序,而是从大到小排序,其命令为 gsort,后面有 ”-“。. sort - price //按价格从高到低排序. sort foreign -price /先把国产车都排在前,进口车排在后面,然后在国产车内再按价格从大小到排序,在进口车内部,也按从大到小排序/
5 赋值及运算=exp
该选项主要用于给新变量赋值或替换原变量的值
. cd d:/stata9. use auto, clear. gen nprice=price+10 //生成新变量 nprice,其值为 price+10. list price nprice //比较一下两个变量的取值/*上面的命令 generate(略写为 gen) 生成一个新的变量,新变量的变量名为nprice,新的价格在原价格的基础上均增加了 10 元。. replace nprice=nprice-10 /命令 replace 则直接改变原变量的赋值,nprice 调减后与 price 变量取值相等/. list price nprice //再比较一下两个变量,相等。
6 条件表达式 if exp
[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]
例:若只想查看国产车的品牌和价格,则加入筛选条件 if foreign==0 */
. cd d:/stata9. use auto, clear. list price if foreign==0
*只查看价格超过 1 万元的进口车(同时满足两个条件),则
. list price if foreign1 & price>10000
*查看价格超过 1 万元或者进口车(两个条件任满足一个)
. list price if foreign==1 | price>10000
*分类型查看价格超过 1 万元的汽车的品牌和价格
. by foreign, sort: list make price if price>10000
7 范围筛选 in range
取前5个的平均值
.sort x.sum x in 1/5
注意“1/5”中,斜杠不是除号,而是从1到5 的意思,即 1,2,3,4,5。
8 加权 weight
[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]
实例:对分数求平均值,需要加权求解: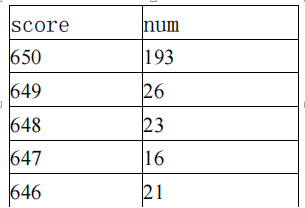
. sum score [weight=num] /加权计算,比较该结果与 sum score 的区别,实际上,不用权重选项时,相当于权重相等。/. sum score [w=n] //w 为 weight 的略写,n 为 num 的简写,两命令等价
9 其他可选项,options
[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options]
. sum score, detail. sum score, d //d 为 detail 的略写,两个命令完全等价
注意,结果中显示了 1%,5%等分位数,意思是把变量从小到大排序,第 1%位置处的取值是多少,第 10%的位置上的取值是多少。显然,50%位置处的取值是中位数。此外,加了 detail 选项后,还得到最小的前 5 个数,最大的 5 个数,以及峰度和偏度等。
*再如,list 命令也有一些可选项
. cd d:/stata9. use auto, clear. list price in 1/30, sep(10) //每 10 个观察值之间加一横线. list price in 10/30, sep(2) //每 2 个观察值之间加一横线. list price, nohead //不要表头

若有收获,就点个赞吧
0 人点赞
