Unicode 和 UTF-8
Unicode 是一个字符集,任何一个其中的字符在计算机中都最多可以用四个字节来表示,称为码点。
那么一个字符在计算机中真的要按四个字节(UTF-32)来存储吗?
答案是否定的,一方面每个字符都按四字节来存储非常浪费空间,另一方面这与c语言不兼容,在c语言中0字节表示字符串的结尾,库函数strlen等函数依赖这一点,如果按UTF-32存储,其中有很多0字节并不表示字符串结尾。
UTF-8是编码规则,可以通过这个规则将Unicode字符集中任一字符对应的字节转换为另一个字节序列。UTF-8只是编码规则中的一种,其它的编码规则还有UTF-16,UTF-32等。
单字节字符、多字节字符、宽字符
C语言里字符有这么几种:单字节字符、多字节字符、宽字符。一个char变量可以恰好存储一个单字节字符,ASCII字符集里的字符刚好。
多字节字符和宽字符是为了应付那些非ASCII字符集的,比如汉字、数学符号、音乐乐谱符号。用单字符读取函数(scanf,getchar之类的)不可能得到超过ASCII码的数值。
程序的存储
// UTF-8int main() {int a = '中'; // 14989485}
// GBKint main() {int a = '中'; // 54992}
看上面这段代码,我们在 ide 上编写完成后,计算机会将这个源文件存在磁盘上(main.c)这个存储的过程就需要编码,通常我们设置的文件编码是 UTF-8,在编码完成后源文件变成了纯的二进制文件,所以这个 ‘中’ 就会以 ‘中’ 的 UTF-8 编码存储,也就是 14989485,如果文件编码是 GBK 那么就是 54992。
上面讲的是程序员编写完成之后存储到硬盘上的编码,现在我们讲编译器读取硬盘上源文件时的编码,编译器会有一个默认的编码格式,比如 msvc 的 GBK,gcc 的 UTF-8 ,当编译器读取时会按照这个编码去读取进行编译,如果两个编码不一致那么就会报错,因为编译器不按指定编码解读,如果出现 ascll 码之外的字符,就会不认识从而破坏语法结构,导致出错。
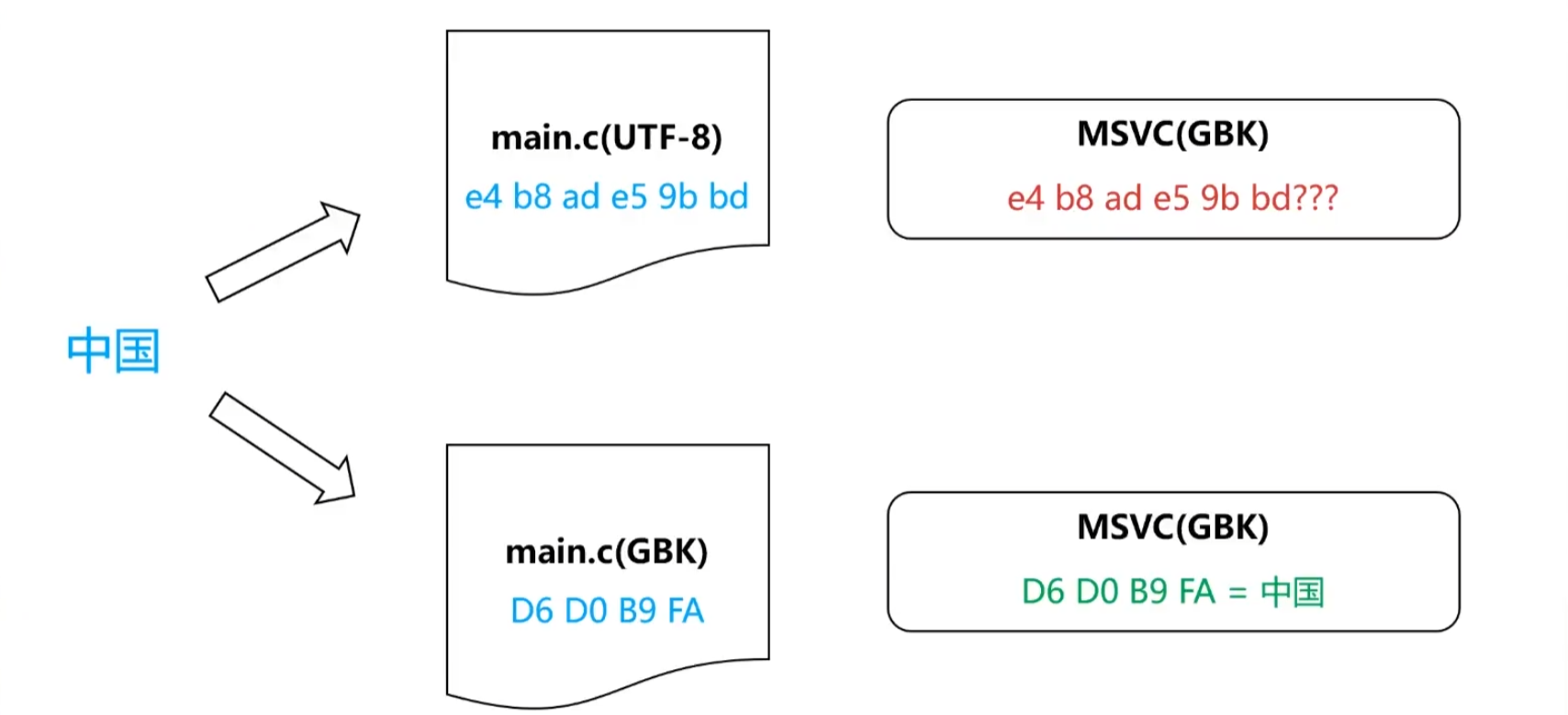
int main() {int b = L'中'; // 20013}
但是当我们使用了宽字符,C 编译器读取时就是将读到的数据按照编译器设置的编码类型去解读,然后转换成 Unicode 的码点,在程序运行时存入变量 b 中。
程序的运行
上面提到在程序运行时存入变量 b 中,当我们在编写程序时,比如赋值一个变量,数据会有几次变化:
1、我们书写在 ide 界面上的字符 ‘中’
2、 按下保存键,’中’ 按照文件存储的编码设置写入磁盘,也就是 E4 B8 AD
3、编译器读取到 E4 B8 AD ,按照编译器的编码去解码,然后编译运行
记住当程序运行时,值才会存储在变量中,在此之前对于计算机而言只是一堆字符串,所以程序编译后的文件 ‘中’ 变成码点,运行时存进变量里,但是源代码存储的时候它还是 ‘中’。
宽字符字面量
int main() {wchar_t b = L'\u4E2D'; // 20013}// typedef unsigned short wchar_t;
L 负责告诉接下来的字符是宽字符,告诉编译器将后面的字符转义成 Unicode 的码点。
多字节字符字面量
像 ‘龙’ 或者 ‘xyz’ 这种单引号内有多字节(按照源字符集)且无前缀的东西叫“多字符字面量”
单引号中至少一个ASCII码字符,至多4个ASCII字符(或者至多两个中文字符)。实际上,一个ASCII码字符认为是1个字节,一个中文字符认为是2个字节。一个单引号中所有字符的字节数应该大于0不超过4。
多个字符字面量也被是被为int类型,其值可以看作其中几个字符的二进制串的拼接
int main() {int a = 'abc';}
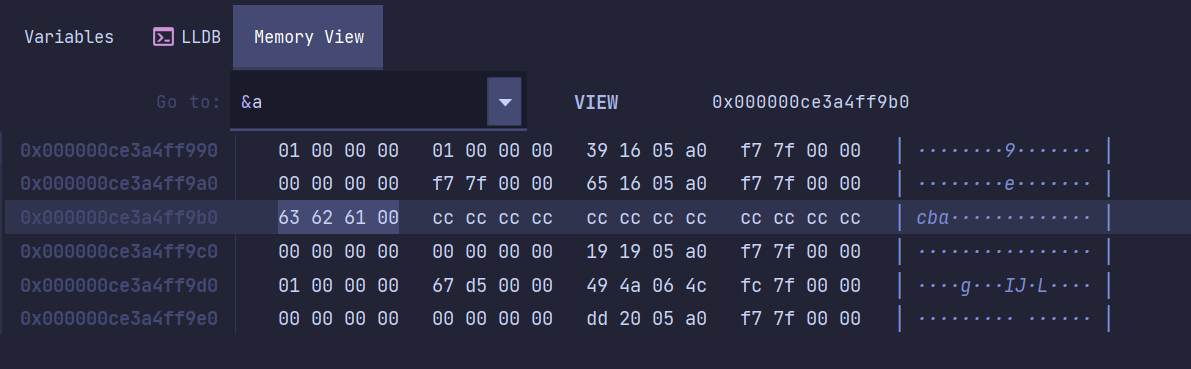
如果超出 4 个字节,msvc 会报错,gcc 则会截断
int main() {long long a = 'abcdd';}
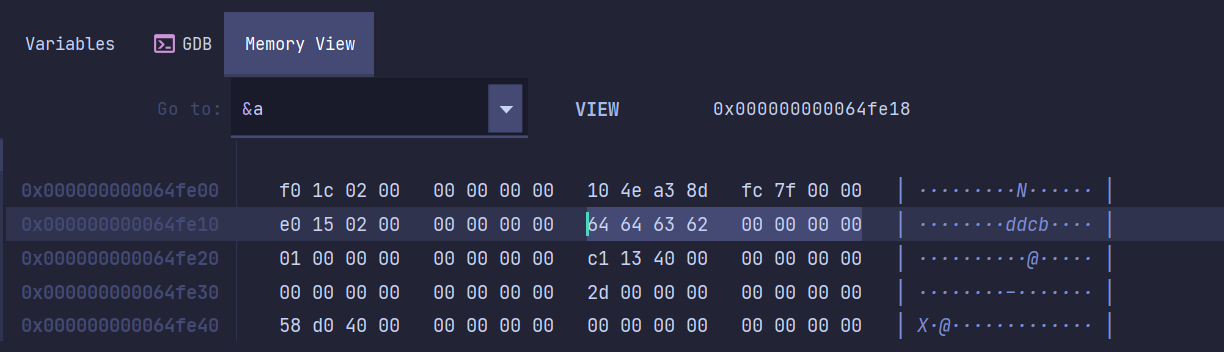
多字符字面量的类型是 int ,如果单引号中字符不足4个字节,则会在高位补0。字符字面量还是多字符字面量实际上都当作整数使用,整数的一些规则都适用于字符型字面量。更确切地说,并不存在字符类型,即使是char也是整数类型。
MSVC 的实现是组成多字符字面量的字节序列按大端序成为结果 int 的字节,但是存入变量的时候又变成了小端序进行存储。
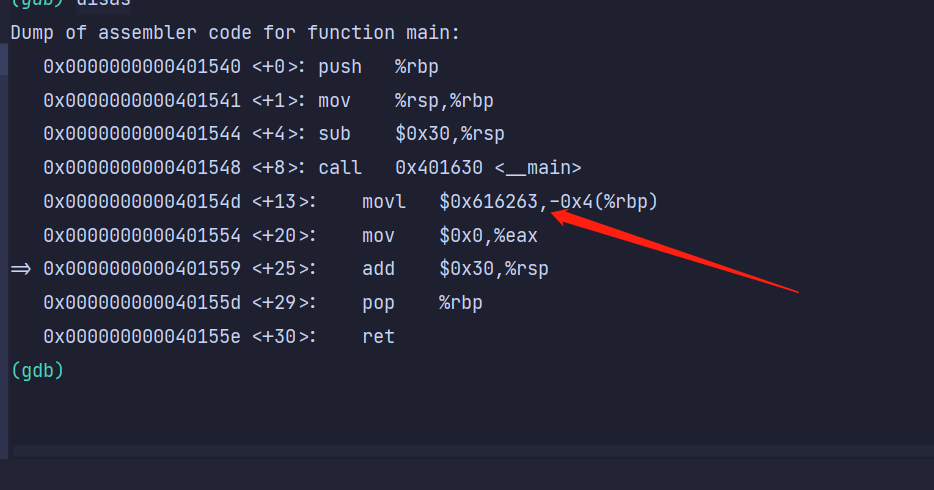
只是对于这些字符,我们通常不关心它的整数值而是使用它的字符来表示一些有意义的文本数据。

若有收获,就点个赞吧
0 人点赞
