动态内存-malloc,free
先看怎么使用:
double* ptd;ptd = (double*)malloc(30 * sizeof(double));free(ptd);
malloc 函数接受一个整数作为参数,代表分配的字节数,返回分配内存第一个字节的地址,如果 malloc 函数分配失败那么就会返回空指针。
malloc 返回的地址默认为 void* 类型可以加上强制类型转换来变成我们想要的指针类型。
ptd[1] 可以使用 ptd 指向内存的下一个内存。
free 把 ptd 指向的内存释放掉,可以理解为 malloc 和 free 管理着一个块内存池。
calloc
calloc 接受两个参数,一个是 count 另一个是 size,它们乘起来就是 malloc 的参数,calloc 分配的内存会自动清零。
realloc
void* realloc (void* ptr, size_t size);
realloc() 对 ptr 指向的内存重新分配 size 大小的空间,size 可比原来的大或者小,还可以不变。当 malloc()、calloc() 分配的内存空间不够用时,就可以用 realloc() 来调整已分配的内存。
如果 ptr 为 NULL,它的效果和 malloc() 相同,即分配 size 字节的内存空间。
如果 size 的值为 0,那么 ptr 指向的内存空间就会被释放,但是由于没有开辟新的内存空间,所以会返回空指针;类似于调用 free()。
指针 ptr 必须是在动态内存空间分配成功的指针,形如如下的指针是不可以的:int *i; int a[2];会导致运行时错误,可以简单的这样记忆:用 malloc()、calloc()、realloc() 分配成功的指针才能被 realloc() 函数接受。
成功分配内存后 ptr 将被系统回收,一定不可再对 ptr 指针做任何操作,包括 free();相反的,可以对 realloc() 函数的返回值进行正常操作。
如果是扩大内存操作会把 ptr 指向的内存中的数据复制到新地址(新地址也可能会和原地址相同,但依旧不能对原指针进行任何操作,如果是缩小内存操作,原始据会被复制并截取新长度。
分配成功返回新的内存地址,可能与 ptr 相同,也可能不同;失败则返回 NULL。如果分配失败,ptr 指向的内存不会被释放,它的内容也不会改变,依然可以正常使用。
程序运行前
在 Linux 环境下,可以通过 size 命令查看一个二进制文件在运行前的内存分区,运行前的二进制可以分为三个区
代码区,text
数据区,data(静态、全局数据)
未初始化区数据区:bss

程序运行后
程序开始运行会多出两块内存,栈区和堆区
内存管理
每个应用程序之间的内存是相互独立的,每个程序所拥有的内存是分区进行管理的。在计算机系统中,运行程序 A 将会在内存中开辟程序 A 的内存区域 1,运行程序 B 将会在内存中开辟程序 B 的内存区域 2,内存区域 1 与内存区域 2 之间逻辑分隔。
在程序 A 开辟的内存区域 1 会被分为几个区域,这就是内存四区,内存四区分为栈区、堆区、数据区与代码区。
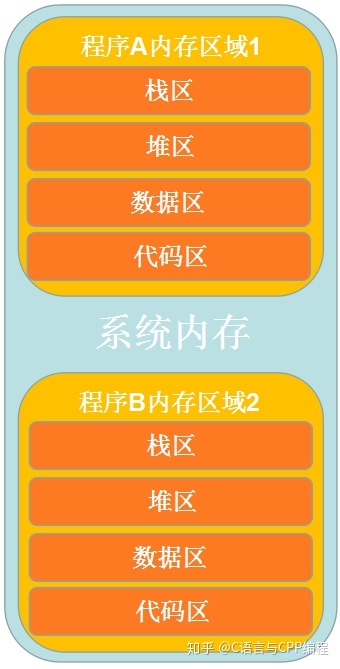
栈区指的是存储一些临时变量的区域,临时变量包括了局部变量、返回值、参数、返回地址等,当这些变量超出了当前作用域时将会自动弹出。该栈的最大存储是有大小的,该值固定,超过该大小将会造成栈溢出。
堆区指的是一个比较大的内存空间,主要用于对动态内存的分配;在程序开发中一般是开发人员进行分配与释放,若在程序结束时都未释放,系统将会自动进行回收。
数据区指的是主要存放全局变量、常量和静态变量的区域,数据区又可以进行划分,分为全局区与静态区。全局变量与静态变量将会存放至该区域。
代码区就比较好理解了,主要是存储可执行代码,该区域的属性是只读的。
栈
栈区的大小通常都是固定大小的,栈区是函数调用栈,自动变量跟随函数一起存储在函数调用栈中,函数定义时存储在于代码区。
栈通常是以调用栈(call stack)的方式对当前正在执行的函数的各种信息(返回地址、栈帧的基地址等)以及函数使用的局部变量进行记录,实现很大程度上取决于 CPU 指令集。
int g() {f()'};int f() {};int main(){g();};
首先会将 main 的运行环境(返回值、参数、返回地址)以及函数内部的局部变量压入栈,这些空间都是静态分配的,由编译器分配而且栈的大小是有限的
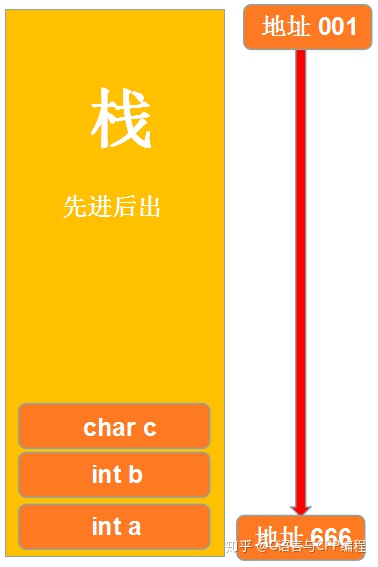
首先被占用的地址将会是最大的
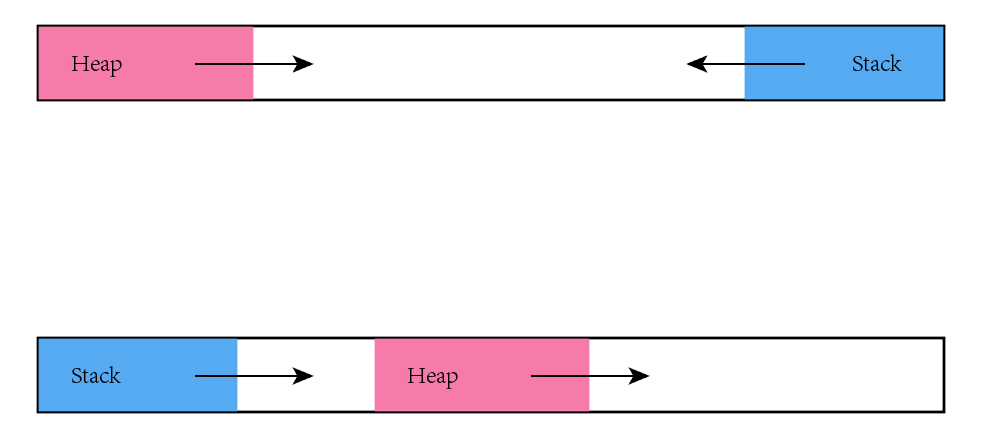
这是历史原因导致的,最大化利用内存
堆
栈是一种数据结构,所有语言的函数调用都是通过压栈来调用的,堆不是一种数据结构,堆是一种存储空间
数据区
数据区又分为,数据区可以分成两部分,未初始化的静态全局(bss)和初始化的静态全局(data),在已初始化的静态全局变量区,还有一个区域叫常量区(文字常量区)。
全局变量和静态变量的存储
常量区 — 常量字符串,以及 const 全局变量
char *p3 = "123456"; //"123456/0"在常量区,p3在栈上。strcpy(p1, "123456"); //123456/0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。
代码区
存储 CPU 执行的机器指令,通常代码区是共享的只读的,其他程序可以调用它。未压入栈的函数定义,函数名存储在代码区,函数指针就指向这些内存。
关于内存泄漏
一般程序运行之后操作系统会自动回收程序申请的内存,但是考虑到有的程序一旦开启会隔很久才会关闭这就需要考虑到内存泄漏的问题
free(p);p = NULL;
使用了 free 释放了内存,并且将 p 赋值 NULL,这点需要主要,不能使指针指向未知的地址,要置于 NULL;否则在之后的开发者会误以为是个正常的指针,就有可能再通过指针去访问一些操作,但是在这时该指针已经无用,指向的内存也不知此时被如何使用。
NULL
宏中定义了 #define NULL ((void*)0) ,访问0会失败,是因为0这个东西你不能读写。所以才会有上面代码,NULL 其实就是 0 ,系统规定 0 内存地址无法操作。
函数调用
int main () {int c = fun(a,b);}int func(int a, int b) {return a + b;}
当程序运行到 fun 函数调用时候,我们从 CPU 的角度去思考,指令地址寄存器是一条一条指令来读数据的,程序执行 fun 函数相当于指令地址寄存器取的地址跳转到相应指令的位置。
这就说明我们调用一个函数首先压入栈的就是函数的返回地址,代表代码指令区跳转之前的地址。随后就要压入 a 和 b 的值(压入顺序都可)。之后压入的就是函数内的自动变量。最后就是 a + b ,将这个表达式在寄存器中计算出来之后的结果压入栈然后更新至上下文(即主调函数的 c 值)更新完之后首先出栈。之后将其他栈中数据出栈。
函数返回地址
函数参数
函数临时变量
保存的上下文

若有收获,就点个赞吧
0 人点赞
