错误处理
错误代码 errno,该错误代码是全局变量,表示在函数调用期间发生了错误。您可以在 errno.h 头文件中找到各种各样的错误代码。开发人员应该在程序初始化时,把 errno 设置为 0,这是一种良好的编程习惯。0 值表示程序中没有错误。
在发生错误时,大多数的 C 或 UNIX 函数调用返回 1 或 NULL,同时会设置一个错误代码 errno。
perror() 函数显示您传给它的字符串,后跟一个冒号、一个空格和当前 errno 值的文本表示形式。strerror() 函数,返回一个指针,指针指向当前 errno 值的文本表示形式。
char * strerror(int errno); 使用方法,fprintf(stderr, "%s", strerror(errno));
文件流指针
打开一个文件需要,将它从磁盘放到内存中,这个时候就会返回一个指针,这个指针所指向的东西(结构体)含有了打开文件的所有信息。我们可以通过这个指针对打开的文件进行操作。
我们大部分情况不需要知道 FILE 结构体到底有什么属性,因为库文件中的函数会接受 FILE 指针来内部读取这个结构体,大部分 IO 库中的函数都接受 FILE 指针。
FILE *fp;表示fp是指向FILE结构的指针变量,通过fp 即可找存放某个文件信息的结构变量,然后按结构变量提供的信息找到该文件,实施对文件的操作。习惯上也笼统地把fp称为指向一个文件的指针。
FILE
C 语言没有定义 FILE 宏是什么,只规定必须要有这个宏,具体实现交给不同环境下的编译器来实现,这是因为每个操作系统实现的文件系统都是不一样的。
I/O 流为 FILE 对象所代表,只能通过 FILE* 类型指针访问及操作。每个流与外部物理设备(文件、标准输入流、打印机、序列端口等)关联。
FILE就是一个结构体,FILE* 就是一个指针。这个结构体的内容在不同的编译环境下是不同的(即使是同一个操作系统的不同编译器,可能也是不同的)。这个结构体具体包括什么东西,只取决于你的编译器的标准库是如何设计的,足以保有控制 C I/O 流所需的全部信息。
在 Windows 里,open一个文件的真正 AP I是 CreateFile,在Linux里可以认为是 open ,因为访问文件是一个与底层相关的操作,所以不同操作系统对文件操作的具体定义可能是完全不同的。C语言标准库就是在这种不同的定义之上,完成一套封装,实现统一接口访问。
fopen
FILE * file = fopen("filename", "r");
fopen 是库函数,是在系统函数 open 的基础上进行封装的。
第二个参数为 mode 选择对文件操作的模式,如果没找到文件则会返回一个 NULL,因为 fopen 占用系统资源使用完之后记得调用 fclose。
- r 只读,没有文件就报错,错误可以用 perror 打印出来
- r+ 可读可写,没有文件就报错,错误可以用 perror 打印出来
- w 只写,清空文件,没有文件就创建文件
- w+ 可读可写,清空文件,没有文件就创建文件
- a 追加,没有文件就创建文件
- a+ 和 a 没有区别
对于程序中的中文文件名,例如 fopen(“data/三国.txt”) ,在 window 系统下虽然程序中是 utf-8 编码,但是传递给 fopen 的时候,fopen 会使用 GBK 编码。解决办法是设置 setlocale 为 utf-8.
fopen 中第一个参数的相对路径,如果在 vs 中进行调试,相对的是工程文件,如果是直接运行可执行文件,那么则相对该可执行文件。
文本文件和二进制文件
打开文本文件只需要文本编辑器即可,而打开二进制文件需要根据每种不同的后缀来选择特殊工具打开,例如打开图片和可执行程序使用的工具就不一样。
文本和二进制模式
在 fopen 第二个参数的字符串后面加 ‘b’ 就是二进制没事,文本模式和二进制模式的区别在于:
文本模式下,你写进去、读出来的,和实际存储的数据,两者不一定相同
二进制模式下,你写进去、读出来的,和实际存储的数据,两者一定相同
文本模式和二进制模式读取写入文件时,差别主要是在回车换行的处理上,而且不同系统对回车换行的处理不一致。以文本模式打开时 \r\n 会转化为 \n,写入时 \n 会转化为 \r\n。
文本模式并不一定仅仅处理换行,某些系统里的可能会忽略你在行尾写入的空格,也有些系统只保存可见字符和回车换行制表等少数控制字符。更有甚者,一些古老的系统中,文本文件、二进制文件完全就是两种不同的东西,用错误的打开方式根本没法打开。
在C语言中,将 \n 存入文件
- window: 0d 0a
- unix: 0d
如果不存到文件中,不会变。如果从文件中提取
- windows: 0d 0a -> \n
- unix : 0d -> \n
IO 流
IO 流一般从文件获取,但是 C 语言内置了三个 IO 流,标准输入,标准输出,标准错误流。这三个流实际上是文件流指针,在程序开始会打开三个设备文件(标准输入文件,标准输出文件,标准错误文件),指向这三个文件的文件流即是三个 IO 流。
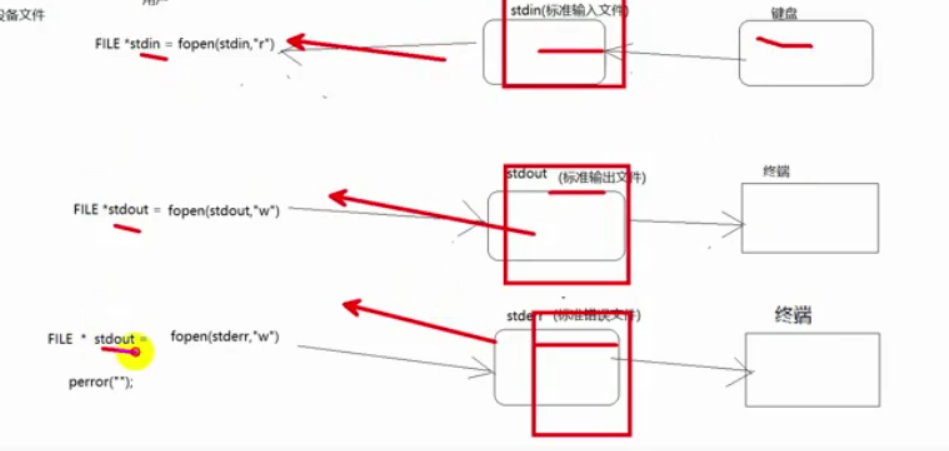
标准输入文件由键盘写入,但是它的文件流是一个只读文件,意味着我们只可以通过键盘来输入到标准输入文件。同理错误流和输出流是只写流。
缓冲区
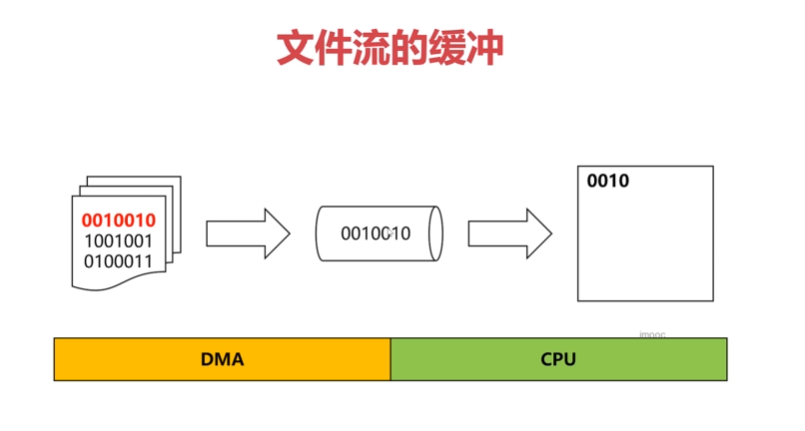
缓冲区实际上是为了减少 CPU 的占用,对硬盘数据的读写比对内存数据的读写效率要低得多,因此有专门的硬件来进行 IO 例如 DMA。
如果没有缓冲,CPU 一个个字符去读取到内存中,然后读取下一个字符,效率极其低下,只有 CPU 去参与。当有缓冲的时候 DMA 将文件读取到缓冲区(内存的某个部分),然后由 CPU 从缓冲区读取数据。
我们可以手动设置缓冲区的大小,setbuf 函数接受一个 FILE 和 char ,表明要和文件流保持同一生命周期的内存。我们需要单独创建一块内存,然后将指针传入函数的第二个参数,作为缓冲区大小。如果传入一个 NULL 代表关闭文件流的缓冲区。
即使是像 fgetc 这样只读一个字节的函数,程序仍然会将缓冲区按照规则填充
FILE* file = fopen("./abc.txt", "r");char b[1024] = { 0 };setvbuf(file, b, _IOLBF, 1024);if (file == NULL) {perror("hyb");system("pause");return 123;}char c = fgetc(file);puts(b);printf("%c", c);// 111111111111// 1
setvbuf
setvbuf 接受 FILE 指针,缓冲区指针,还有第三个 mode 参数来设置缓冲的模式按行缓冲还是全量缓冲或者关闭缓冲。第四个参数为设置缓冲区的大小。
setbuf虽然可以修改缓冲区的大小,但因为没有传缓冲区的大小进去,所以系统并不知道你开辟了多大,都会按照 BUF_SIZE 去使用。所以改不了。因为无法知道指针指向的内存有多大,setbuf 只是重新开辟了默认大小的内存空间。
缓冲区和文件流是同生命周期的,注意缓冲区的存在时间一定要比文件流的存在时间长。main 函数并不是程序执行的第一行代码,因此 main 函数中声明缓冲区不是很好的选择,可以在全局作用域声明,或者使用 malloc 来开辟内存。
清空缓冲区
普通文件有三种方法刷新
fflush 函数参数是 FILE 指针,来清空缓冲区。
缓冲区满
程序正常关闭
#include<stdio.h>int main(){printf("hello");while(1);return 0;}
在Windows平台下,在程序没结束,也没有强制刷新缓冲区,也没有遇到输入操作,输出缓冲区也未满,也没有遇到换行符的情况下,仍然输出了hello。Windows 下的标准输出没有缓冲区,Linux 有。标准输入不可以用 fflush 刷新。
有的实现在遇到输入的时候,也会进行刷新。
读写文件
打开文件后需要对文件进行读写,大概分为下面四类函数来读写
按字符读取:fgetc 和 fputc
按行读取:fgets 和 fputs
按格式读取:fprintf 和 fscanf
按块读取: fread 和 fwrite
在文件内部有一个位置指针,用来指向当前读写到的位置,也就是读写到第几个字节。在文件打开时,该指针总是指向文件的第一个字节。使用 fgetc 函数后,该指针会向后移动一个字节,所以可以连续多次使用 fgetc 读取多个字符。
注意:这个文件内部的位置指针与C语言中的指针不是一回事。位置指针仅仅是一个标志,表示文件读写到的位置,也就是读写到第几个字节,它不表示地址。文件每读写一次,位置指针就会移动一次,它不需要你在程序中定义和赋值,而是由系统自动设置,对用户是透明的。
如果在一个程序中需要多次对同一个文件流指针进行读取操作,那么就需要考虑光标的位置了,可以使用 fseek(file, 0, SEEK_SET); 来重置光标。
fgetc 和 fputc
putchar 和 getchar 指向控制台写入,读取一个字符,原型是 int putchar(int ch) ,成功则返回读取或者写入的字符,如果失败则返回 EOF 。
fgetc 和 fputc 指向指定流中写入字符。
fgets 和 fputs
putchar 和 getchar 用来操作一个字符,fgets 和 fputs 用来操作一行字符。gets 函数在多个标准中已经被移除,使用 gets_s 函数,新函数多了一个大小的参数,fputs 不写入 ‘\0’ 字符。
调用 gets 会从标准输入开始读,读到换行符为止,将读取到的内容存到缓冲区当中,gets 读取内容的大小无法进行规定,导致缓冲区的大小不好设置,过大和过小都不合适。
gets 和 gets_s 都接受一个指针,代表缓冲区,gets_s 会额外接受一个 size 代表一次性最多读取的次数。puts 函数代表输出一行。
还有 fgets 和 fputs 和之前的 f 函数一致。puts 函数返回一个非负值为字符串长度(包括末尾的 \0),如果发生错误则返回 EOF。
这些函数只使用于文本内容的读取。
fprintf 和 fscanf
fprintf ,sprintf 和 printf 都是组包区别在于,组好的字符串发送到哪里。fscanf 同理
fread 和 fwrite
文本模式是我们给二进制数据加上的可读性,如果想要随便读取字节可以用 fread 和 fwrite 函数。
char buffer[32];size_t bytes_read = fread(buffer, sizeof(char), 32, stdin);
先开辟一块内存,但是只传入指针不知道多大的空间,所以需要传入大小,函数返回的值代表写入缓冲区的块数目。size 是每次读取的字节数
fwrite(buffer, sizeof(char), bytes_read, stdin);
feof
如果文件不是纯文本文件(是二进制文件),那么我们不能使用 EOF 来判断是否为文件末尾,当设置了与流关联的文件结束标识符时,该函数返回一个非零值,否则返回零。
fseek,rewind,ftell
int fseek(FILE *stream, long int offset, int whence)
设置流 stream 的文件位置为给定的偏移,whence 有三个选项
SEEK_SET 文件的开头
SEEK_CUR 文件指针的当前位置
SEEK_END 文件的末尾
如果成功,则该函数返回零,否则返回非零值。
rewind 将文件位置为给定流 stream 的文件的开头。ftell 返回给定流 stream 的当前文件位置。

若有收获,就点个赞吧
0 人点赞
