概念
假设我们有两个 int 类型的数据,我们使用16进制表示这两个数,0x12345678和0x11223344。采用以下方式存储这个两个数字:

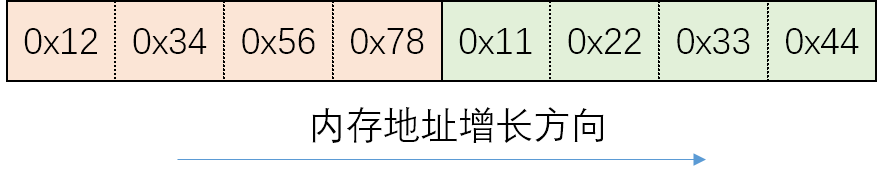
可以看出下面的方法符合我们的阅读顺序称为大端(Big endian)字节序,上面的称为小段(little endian)”字节序,不同的 CPU 有不同的实现。
值的低位存到低地址称为小端
网络字节序
前面的大端和小端都是在说计算机自己,也被称作主机字节序,TCP/IP 规定使用“大端”字节序为网络字节序,其他不使用大端的计算机发送数据的时候必须要将自己的主机字节序转换为网络字节序(即“大端”字节序),接收到的数据再转换为自己的主机字节序。这样就与CPU、操作系统无关了,实现了网络通信的标准化。
UTF-8、UTF-16、UTF-32
UTF-8 是单字节不需要考虑这个问题,但是 UTF-16 和 UTF-32 分别使用2个字节和4个字节编码Unicode字符,一旦某个值用多个字节表示,就必须要考虑存储的顺序了。于是,采用了最简单粗暴的方式,给文件头部写几个字符,用来表示是大端呢还是小端。
头部的字符 编码 字节序 FF FE UTF-16/UCS-2 Little endian FE FF UTF-16/UCS-2 Big endian FF FE 00 00 UTF-32/UCS-4 Little endian 00 00 FE FF UTF-32/UCS-4 Big-endian
这里不得不提一下UTF-8啊,明明人家是单个字节的,不存在什么字节序的问题。微软为了统一UTF-X,硬生生给他的头部也加了几个字符!是的,这几个字符就是BOM(Byte Order Mark),这就是Windows下的UTF-8。
相信很多人都被UTF-8的BOM给坑过,多了这个BOM的UTF-8文件,会导致很多问题啊。比如,写的Shell脚本,内容为#!/usr/bin/env bash,在UTF-8有BOM和UTF-8无BOM的编码下,对应的16进制为:
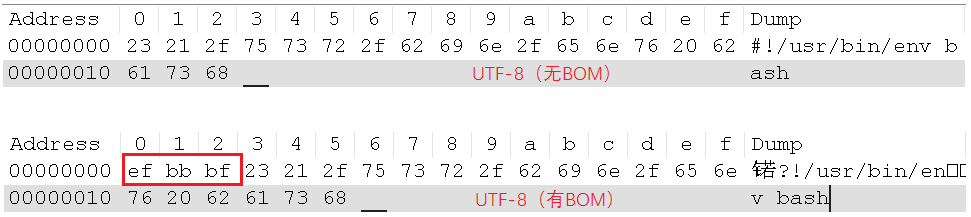
所以,有BOM的话,Shell解释器就报错啦。原因在于,解释器希望遇到#!/usr/bin/env bash,而使用UTF-8有BOM进行编码的内容会多了3个字节的EF BB BF。
对于UTF-8和UTF-8无BOM两种编码格式,我们更多的使用UTF-8无BOM。
意义
大端和小端有其各自的优势。我们知道计算机正常的内存增长方式是从低到高(当然栈不是),取数据方式是从基址根据偏移找到他们的位置。
从他们的存储方式可以看出,大端存储因为第一个字节就是高位,从而很容易知道它是正数还是负数,对于一些数值判断会很迅速。(所以用于网络)
而小端存储 第一个字节是它的低位,符号位在最后一个字节,这样在做数值四则运算时从低位每次取出相应字节运算,最后直到高位,并且最终把符号位刷新,这样的运算方式会更高效。由于整数通过补码计算所以加减法计算方法一致,符号位可以最后考虑(所以用于主机内部计算)
位运算和字节序
字节序是数据在内存中存储的方式, 当值被读取到处理器中时,不管字节顺序如何,移位指令都是对处理器寄存器中的值进行操作。因此,从内存加载到处理器相当于转换到大端,然后进行移位操作,然后新值被存储回内存,这个时候小端序再次起作用。
但是对于某些 cpu 而言是对大小端敏感的,对大小端进行位移是会有不同的结果的,可以在宏里写一个值来判断
#ifdef __BIG_ENDIAN__#define VEC_SLD(va, vb, shift) vec_sld(va, vb, shift)#else#define VEC_SLD(va, vb, shift) vec_sld(vb, va, 16 - (shift))#endif
小结
对于现代计算机意义不大,确定一种比选择一种更重要。

若有收获,就点个赞吧
0 人点赞
