分支预测
现代 CPU 的流水线功能使得一个指令为执行完的时候就开始执行下一条指令,但是如果遇到分支,流水线就会停止。在遇到分支的时候 CPU 会进行预测,预测正确则继续执行,预测错误则回到分支重新执行。
// 优化前#include <iostream>#include <vector>#include <algorithm>#include <random>#include <chrono>constexpr size_t COUNT = 4 * 1024 * 1024;int main () {std::default_random_engine e;std::uniform_real_distribution<double> u(0.0, 1.0);std::vector<double> vector(COUNT);std::generate(vector.begin(), vector.end(), [&e, &u]() {return u(e);});auto start_time = std::chrono::high_resolution_clock::now();double res = 0;for (int i = 0; i < COUNT; ++i) {if (vector[i] > 0.5) {res += vector[i];}}auto finish_time = std::chrono::high_resolution_clock::now();std::clog<< "sum:"<< std::chrono::duration_cast<std::chrono::microseconds>(finish_time - start_time).count()<< "us"<< std::endl;return 0;}// sum:38001us
遇到分支 vector[i] > 0.5 ,在 CPU 判断一个数字大于 0.5 之后,它会预测下一个数字也是大于 0.5 的。争对这个分支预测我们可以在创建完 vector 之后进行一次排序 std::sort(vector.begin(), vector.end()); 这样分支预测大部分时间都是正确的,除了在某个点上会错误。这样优化后的执行时间是 sum:14008us。
看出分支预测失败时对性能影响很大,我们尽量让分支预测成功,一种做法是让符合分支的和不符合分支的数分开放。实际编程要时刻注意数据和分支的对应,不要一次性去处理数据(sort)。毕竟 sort 对性能的开销也很大。
std::sort(vector.begin(), vector.end()); 可以用 std::partition(vector.begin(), vector.end(), [](double x) {return x < 0.5;}); 代替。
或者我们可以尽量避开分支 res += vector[i] > 0.5 ? vector[i] : 0; 代替分支。
如果一个分支的条件很少见 vector[i] > 0.99 我们可以加上 if (vector[i] > 0.99) [[unlikely]] {}(c++20) 来告诉编译器分支预测的概率。或者使用 __glibc_unlikely(vector[i] > 0.99) 牺牲可以移植性去提升性能。
内存访问
读取主存内存的时间往往是时钟周期的几百倍,意味着 CPU 在读取内存的 CPU 周期中,CPU 的控制单元会空闲几百个时钟周期。内存读取的特性,开销很大,批量读取(通常一次会读 64 个 字节)。
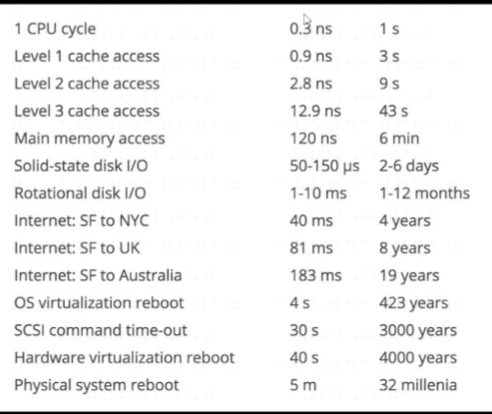
优化方法是,顺序访问优于随机访问,因为批量读取的特性,主存内存读取之后会将批量读取到的内容放到高速缓存中。
#include <iostream>#include <vector>#include <algorithm>#include <random>#include <chrono>constexpr size_t COUNT = 4 * 1024 * 1024;int main () {std::default_random_engine e;std::uniform_real_distribution<double> u(0.0, 0.99);std::vector<double> vector(COUNT);std::generate(vector.begin(), vector.end(), [&e, &u]() {return u(e);});std::vector<int> indexes(COUNT);std::iota(indexes.begin(), indexes.end(), 0);auto start_time = std::chrono::high_resolution_clock::now();double res = 0;for (int i = 0; i < COUNT; ++i) {res += vector[indexes[i]];}auto finish_time = std::chrono::high_resolution_clock::now();std::clog<< "sum:"<< res<< std::endl<< std::chrono::duration_cast<std::chrono::microseconds>(finish_time - start_time).count()<< "us"<< std::endl;return 0;}// 16999us
如果在 indexes 后 std::random_shuffle(indexes.begin(), indexes.end()); 那么最后相加时间会是 33969us 。
我们可以尽量使用同一块内存去读写,这样效率更高。

若有收获,就点个赞吧
0 人点赞
