分表
分表是将一个大表按照一定的规则分解成多张具有独立存储空间的实体表,每个表都对应三个文件,MYD数据文件,MYI索引文件,frm表结构文件,这些表可以分布在同一快磁盘上,也可以在不同的机器上,App读写的时候,按照事先定义好的规则得到对应的表明,然后去操作它
将单个数据库表进行拆分,拆分成多个数据表,然后用户访问的时候根据一定的算法(HASH,或者求余,取模)的方法,让用户访问不同的表,这样数据分散性能到多个数据表中,减少了单个数据表的访问压力,提升了数据库访问性能,分表的目的就在于此,减少数据库的负担,缩短查询时间
分表分为垂直切分和水平切人
垂直切分
按照数据表列的拆分,将一张表分为多张表,通常是按照以下原则进行拆分,把不常用的字段单独放在一个表,将test,blob,等大字段拆分出来,放在附表里
经常组合的列放在一个表里,垂直拆分一般是数据库表设计之初就执行的步骤,查询用ioin关联
水平拆分
是指将数据表的行拆分,将一个表数据,拆分为多张表来保存,水平拆分原则,通常是Hash,取模等方式来进行表的拆分,比如数据又200万数据,拆分两个表,一张表之后100万数据,
通过ID取模的方式分散在两个表中,然后删除更新,查询都是通过取模的方式来查询,当然也可以根据业务逻辑来拆分表,比如年份,那查询的时候就必须要选择年,才能查询。
利用merge引擎,分表
有个问题就是增加修改字段,分表动了之后,主表就消失了或者隐藏了,对应不上,需要删除主表,重新建主表,创建关联关系
DROP TABLE tb_action;create table tb_action(`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`name` varchar(50) NOT NULL DEFAULT '',`cid` int(10) NOT NULL DEFAULT '0',`action` varchar(50) NOT NULL DEFAULT '',`add` varchar(255) NOT NULL DEFAULT '',PRIMARY KEY (`id`))engine=merge union=(tb_action1,tb_action2) insert_method=last charset=utf8;
Mrg_Mylsam就是merge存储引擎,是一组Mylsam的组合,也就是说,他将Mylsam引擎的多个表聚合起来,但是他的内部没有数据,真正的数据依然在mylsam引擎的表中,但是可以进行查询,删除更新等操作
可以直接从数据表里面操作,也可以直接在merge表中,删除merge表,不会影响实际数据
只有mylsam引擎的原表才可以利用merge存储引擎实现分表
merge分表,分为主表和子表,主表类似于一个壳子,逻辑上封装了子类,实际上数据都是存储在子表中,我们可以通过主表插入,查询数据,如果清楚分表规则,可以直接操作子表
1.首先一个mylsam引擎的数据表,添加数据
2.创建分表,注意,子表和主表的字段定义要一致,包括数据类型,长度等等,
createtable tb_member1 likemember;
3.创建主表,注意当分表完成后,所有的操作都是对主表操作,虽然主表不存储数据
create table tb_action(
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL DEFAULT '',
`cid` int(10) NOT NULL DEFAULT '0',
`action` varchar(50) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
)engine=merge union=(tb_action1,tb_action2) insert_method=last charset=utf8;
在上面创建主表时,指定的“insert_method=last”有三个可选参数,分别是:last:表示插入到最后一张表里面;first:表示插入到第一张表里面;NO:表示该表不能做任何写入操作,只作为查询使用
现在主表跟分表就确定的关系
4.将数据分别移入分表
insert into tb_action1(id,name,cid,action) select id,name,cid,action from action where id%2=0;
insert into tb_action2(id,name,cid,action) select id,name,cid,action from action where id%2=1;
此刻数据都已经添加进分表,主表内什么都没有,虽然可以看到数据,但只是一个空壳,没有数据文件
对数据的处理
添加
因为insert_method 参数的关系,只能给其中一个分表添加数据,对主表进行操作
INSERT into tb_action(name,cid,action) VALUES('你愁啥','2','宠你咋地');
当然也可以根据规则对分表直接操作,不过因为都是主键自增,添加后主键会重复,查询修改操作就会失真,可以定义一个主键表,每次添加数据先添加主键表,获取id,再根据规则添加到对应的分表中去,还有一种是添加完主键表,给分表设置触发器,自动拉去主键表id,没仔细看
查询修改删除
都可以直接对主表进行操作,最后都会自动转变为修改分表
UPDATE tb_action set name='你变了' where id=4;
分区
分区跟分表相似,都是按照规则分表,不同于分表将大表分解成若干个独立的实体表,而分区是将数据分段划分在多个位置存储,分区后还是一个表,但是数据散列到多个位置,数据操作的时候还是表名字,db自动会处理分区数据
也是分为两种形式垂直跟水平
水平分区
就是对表的行进行分区,所有的列在每个数据分区中都有,表的特性得到保持,比如id大于1万的在一起,1万至2万的在一起等等
垂直分区
这种事通过减少表的宽度,使得某一些数据列划分到特定的分区,每个分区都包含其中列的数据行,比如大的text,blob,划分到其他分区,提高访问效率
不过这种基本不用,没怎么介绍,还需要VP存储引擎支持。还不如直接分成两个表了呢
查看是否支持分区
SHOW VARIABLES LIKE'%partition%';
如果事YES 就支持
mysql版本5.6以上用其他命令
show plugins;
其中status列为 ACTIVE 就表示可以
添加分区
1.建表的时候直接创建分区
create table user(
id int not null auto_increment,
name varchar(30) not null default '',
sex int(1) not null default '0',
primary key(id)
)default charset=utf8 auto_increment=1
partition by range(id)(
partition p0 values less than (3),
partition p1 values less than (6),
partition p2 values less than (9),
partition p3 values less than (12),
partition p4 values less than maxvalue
);
2.在已有表上添加分区
ALTER TABLE action
PARTITION BY RANGE(id)(
PARTITION p0 VALUES LESS THAN (400),
PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (1500),
PARTITION p3 VALUES LESS THAN maxvalue
);
3.已经存在分区的表上添加分区
-- 按照id值给定的分区,一般直接添加就可以
ALTER TABLE ccc
ADD PARTITION (
PARTITION p2 VALUES LESS THAN (20)
)
4.但是有一个最大值之后包含所有的分区(maxvalue),没办法继续分,只能拆分
alter table action reorganize partition p3 into (partition p03 values less than (2000),partition p4 values less than maxvalue );
分区的算法
取余:Key,hash
-- 根据id分为5个分区
partition by key (id) partitions 5
-- 根据日期分为12个区
partition by hash (month(date)) partitions 12;
条件:List,range
-- 按照列出值分区
partition by list(
partition name1 values in(1,3,5),
partition name2 values in(2,4,6),
)
-- 根据给定值分区
partition p0 values less than(20),
partition p1 values less than(40),
查看分区信息
通过select information_schema.partitions 来查看信息
select partition_name part,partition_expression expr,partition_description descr,table_rows from information_schema.partitions where table_schema = schema() and table_name='表名称';
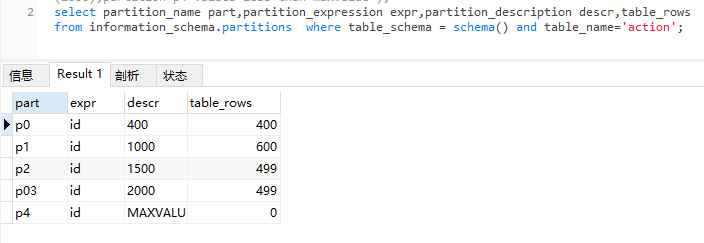
通过建表语句查看
show create table action;
合并分区
alter table user reorganize partition p0,p1,p2,p3 into(partition p02 values less than (12));
删除分区
-- 分区删除后,数据也将被删除,确定好
alter table user drop partition p02;
什么时候用分区:
一张表的查询速度已经慢到影响使用,sql已经经过优化,数据量大,表中数据事分段的,堆数据的操作往往之涉及一部分表数据,而不是全部数据,侧重点是突破磁盘的读写能力
什么时候用分表:
一张表的查询速度已经慢到影响使用,sql已经经过优化,数据量大,频繁的插入或者联合查询时,速度变慢,侧重点是存取数据,提高并发
分片(类似分库)
分片是把数据横向扩展(Scale Out)到多个物理节点上的一种有效方法,其主要目的是为突破单节点数据库服务器的I/O能力限制,解决数据库扩展性问题,Shard 这个词意思是“碎片”,如果将一个数据库当作一块大玻璃,将这块玻璃打碎,那么每一小块都称为数据库碎片,将整个数据库打碎的过程就叫做分片,
形式上分片可以简单定义为将大数据库分布到多个物理节点上的一个分区方案,每个分区包含数据库的某一部分称为一个片,分区的方式可以是任意的,并不局限于水平跟垂直。一个分片上可以包含多个表的内容甚至可以包含多个数据库实例中的内容,每个分片被放置在一个数据库服务器上,一个数据库服务器可以处理一个或多个分片的数据,系统中需要有服务器进行查询路由转发,负责将查询转发到包含该查询所访问数据的分片或者分片集合节点上去执行。
mysql的扩展方案包含 Scale Out和Scale Up两种
Scale Out (横向扩展):
是指应用可以在数据水平方向上扩展,一般对数据中心的应用而言,指的是当添加更多的机器时,应用仍然可以很好的利用这些机器的资源来提升自己的效率,从而达到很好的扩展性
Scale Up (纵向扩展):
是指应用可以在垂直方向上扩展,一般对单台机器而言,Scale Up指的是当某个计算节点(机器)添加更多的CPU,存储设备,使用更大内存时,应用可以很充分的利用这些资源来提升自己的效率从而达到更好的扩展性
分片策略包括垂直切片和水平切片
垂直(纵向)切片:
按功能模块拆分,以解决表与表之间的io竞争,这个方式每个片区之间的表结构不同,比如企业物料属性,可以按照基本属性,销售属性,采购属性等等,进行垂直拆分
水平(横向)切片:
将一个表的数据进行分片保存到不同的数据库中,来解决单表中数据量增长出现的压力,这些片区之间的表结构都相等,比如电商订单表,数据量过大,按照年度,季度水平拆分
分库
分表能够解决单表数据量过大带来的查询效率下降的问题,但是缺无法给数据库的并发处理能力带来质的提升,面对高并发的读写访问,当数据库master服务器无法承载写操作压力时,不管如何扩展slave服务器,此刻都没有意义了,因此必须换一种思路,对数据库进行拆分,从而提高数据库写入能力,这就是所谓的分库,
和分表策略相似,分库可以采用通过一个关键字取模的方法,来对数据访问进行路由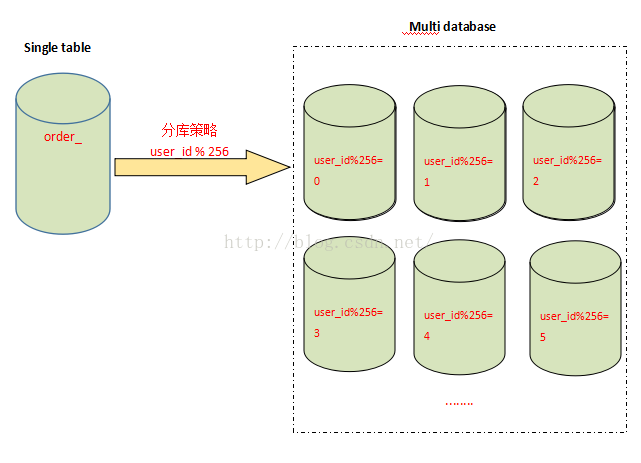

若有收获,就点个赞吧
0 人点赞
