有些博客很好,记录一下: https://www.cnblogs.com/codeAB/p/10283304.html
官网:https://www.elastic.co
本质
搜索系统完成的最重要工作就是“确定输入和仓库内数据的相关性”,围绕确定相关性找个主题,衍生了倒排索引,前缀树,相关性排序算法,随着数据量的增大,又引入了分布式通信,分布式存储等内容,分布式的引入又要解决一致性,可靠性等问题,但是万变不离其宗,搜索系统永远要有:数据索引和打分机制
数据索引提供了一个搜索数据的基础,打分机制确定了你搜索到的内容是应当保留还是抛弃
再加上一个原始数据的爬取程序,所谓仓库内数据的来源,一个微型百度的思路就出来了
介绍
es全称是elasticsearch ,是一个基于Lucenc(全文搜索技术,搜索引擎库)的搜索服务器,它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,会提供一个API使用接口。使用JAVA开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎,高扩展,高实时
一个分布式的实时文档存储,每个字段都可以被索引和搜索
like的搜索只能是模糊搜索,ES的搜索可以搜索相关的信息,比如李白,可以查出李白的诗词,比如商城的搜索联想功能,
lucene与es的关系
lucene只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务架构框架搭建起来的应用
好比lucene是类似发动机,而搜索引擎(es,solr)就是汽车
目前市面上流行的搜索引擎软件,主流的就两款,es和solr,这两款都是基于lucene搭建的,可以独立部署启动的搜索引擎服务软件,由于内核相同,所以两种除了服务器安装,部署管理,集群以外,对数数据的操作修改,添加,保存,查询,都十分相似,
从实际企业使用情况开看,es的市场份额逐步在取代solr,国内,百度,新浪,京东都是用es。国外的维基百科,github,也都是es
确定输入和仓库内数据的相关性
当我们搜索云计算技术,在库内有两个结果,一个《云计算技术是什么》和《云计算应用》,确定哪个更加匹配,确定匹配读是一个数学计算问题,只需要知道输入文档的tern(词)在一个结果中出现的频率,再去对应这个term在所有文档中的频率即可,公式是:
TF就是term frequency词频,IDF就是inverse document frequency 逆文本频率,而TF-IDF就是他们二者的乘积,值越高其内容相关性越高,基于的原则是字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着他在语料库中出现的频率成反比下降,TF-IDF是计算某个term与一个文档的相关度,
ES5后使用BM25算法,BM25是对TF-IDF的优化,主要是对于TF的增长情况给予了限制,目的是优化多节点评分精确度问题,其他更有效的方案有向量检索,不过其基础也是TF-IDF值,
当然搜索引擎的排序可不单单依靠TF-IDF,还要考虑字段权重(标题出现的词权重高),网站排名,内容权威性(有涉及PageRank算法)等,所以排序简单可以分为召回,粗排,精排和重拍阶段,
使用场景
为用户提供按关键字查询的全文搜索功能,
实现企业海量数据的处理分析的解决方案,
日志数据分析,实时数据分析
ELK日志系统(Logstash负责收集、解析数据,Elasticsearch负责存储、检索数据,Kibana提供可视化功能)Log的集中式管理问题
倒叙排序
将文档进行分词,形成词条和id的对应关系即为反向索引,已唐诗为例,
所处包含“前”的诗句
正向索引: 由《静夜思》—>床前明月光 —>“前”字
反向索引:“前”字 —->床前明月光 —->《静夜思》
反向索引的实现就是对诗句进行分词,分成单个的词,由词推据,即为反向索引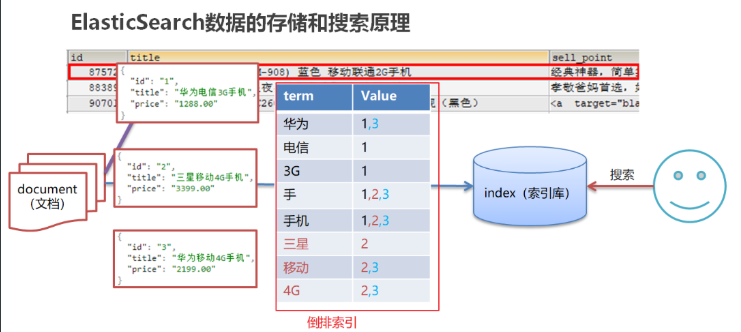
特点
1.天然分片,天然集群
es把数据分成多个shard,多个shard可以组成一份完整的数据,这些shard可以分布在集群中的各个机器节点中,随着数据的不断增加,集群可以增加多个分片,把多个分片放到多个机子上,已达负载均衡,横向扩展,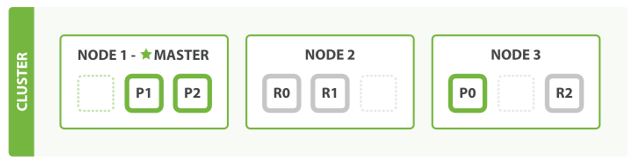
在实际运算过程中,每个查询任务提交到某一个节点,该节点必须负责将数据进行整理汇总,再返回客户端,也就是一个简单的节点进行Map计算,在一个固定的节点上进行reduces得到最终结果向客户端返回
这种集群分片的机制造就了es强大的数据容量及运算扩展性,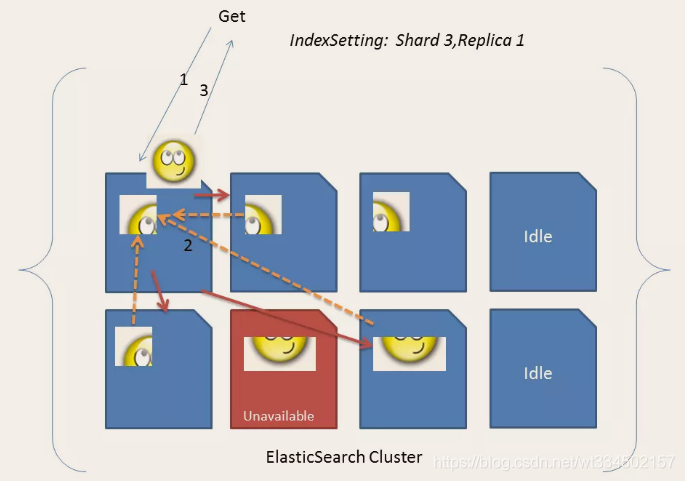
2.天然索引
es所有数据都是默认进行索引的,这点和MYSQL正好相反,mysql是默认不加索引,要加索引必须特别说明,es只有不加索引才需要说明
而es使用的是倒排序和mysql 的B+Tree索引不同
shard
跟mysql的分表类似,根据id取余,数据分别存在固定的表中,这个结构,在es中被称为主分片(shards)
因为es是天生分布式的,这些横向扩展的分表都不存在一台机器上,有三个主分片,es集群就自动找3台node(节点)存上,当然也不会出现数据重复出现的现象,一个Document(文档)是不可能再进行拆分的了
还有一种分片叫做副本分片(replica-shard/replicas),就像是mysql做了分表,还做了主从同步,ES的副本分片也是只读的,冗余的,ES也会自动保证主分片和对应的副本分片存在在不同的机器node上,以免主备一起出事,
对于无法正常分配主,从分片的情况下,集群会以red,yellow状态进行回应
term
trem就是组成一个句子的最小单元,也是能被搜索到的最小单元,怎么定义最小单元:“中文和A BC”如何定义最小单元取决于你对句子的切分方式,按照空格切 tern:“中文和A”“BC”,如果每个单独字符都要切,哪tern:“中”“文”“和”“A”“B”“C”,
可见term是什么,决定于如何切词具体的切词方法是由分词器设置来决定的,有的方法是看到空格就要切一刀,虽然简单粗暴,但是客户也能接收(比如英文单词本身就是用空格切分的,)但是中文的切分方案就要复杂很多了,我如何知道“中文”两字是一个独立的词呢,现在是基于字典和统计学的语言模型,比如mmseg,需要内置一个词库
倒排索引就是将句子分词成为tern,然后统计每次term的出现位置,记录下来,形成倒排索引
ES分词步骤,
将原始的输入文本语句切分为term形式的工作,就是分词,这个是analyzer内组件和对应功能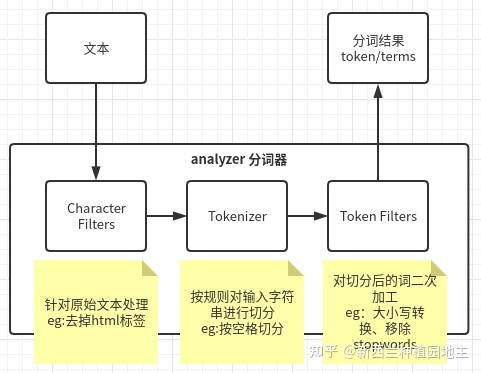
整个分词器就像流水线一样,analyzer内包含Character Filters、Tokenizer、Token Filters 三个部分,term代表的是被切分的最小可搜索语句本身,而token不止包含term,还包含关于这个term的出现位置等信息,
所以当自定义一个自己的analyzer时,是可以自由组合其内部的这三个结构的,比如你不要按照空格分隔,修改为其他的,修改tokenizer的类型就行了,
segment
是来自lucene的概念,可以把segment理解为倒叙索引的具体实现,
有一个特性,就是不变性,也就是你修改了数据之后,对应的term-docid都不会删除或改变,而是加一条你输入的最新数据,同时也会在segmentname,del文件中新增一条删除数据,
好处就是避免了并发问题,提高了插入效率,可以尽情使用顺序写,
但是问题就是数据体积会无限制增大,而且包含一堆无效数据的segment,在搜索上性能肯定有性能问题,因为写数据方便了,每次搜索完成后还得去del文件中,过滤一遍不用的数据
解决思路:
是对segment进行分治,segment并不是一个文件,而是随着写入可能逐渐会生成多个文件,lucene再后面会将这些较小的,可能包含删除数据的segment逐渐合并为更大的,更干净的segment文件,同时删除del文件,(ES会定时干找个是,不会打断搜索和插入)
segment只是一个对内容的倒叙排序索引,系统中可能需要多个字段进行搜索,多个字段,都需要保存相应的倒排索引结果,为了区分开,使用index来作为业务划分并保存一些配置,Mapping记录index都有那些field和对应的类型信息,结构定下来了,往里里面插入 Document数据(json)就行
GET ${index_name}result:{"${index_name}" : {"aliases" : { },"mappings" : {"properties" : {"price" : {"type" : "long"},"t_from" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}},"settings" : {"index" : {"creation_date" : "1631002400390","number_of_shards" : "1","number_of_replicas" : "1","uuid" : "OD5G27oPQVejh1HJH5ZkgQ","version" : {"created" : "7060099"},"provided_name" : "test_name"}}}}
总结说 Engine。index 本身存储了创建索引时的设置以及版本号,是否是主分片,路由信息等,Mapping可以理解为保存了元数据以及类型映射关系的map结构,document是具有父子结构的map,保存了key=>value值
Mapping一旦创建,可以新增字段,但是不能直接修改,因为修改势必会带来部分数据的重新索引,比如之前是字符串,现在改为日期了,之前索引的数据就没法用了,处理这个问题需要利用官方的别名0停机方案
ES节点类型和关系
- 协调节点 Coordinating Node :接收并转发到正确的node上的节点,比如创建新索引的请求会被路由master节点,查找的请求会根据ID hash 到存储数据的节点
- 主节点(master node):维护集群状态包括:节点,分片,数据迁移,向所有其他节点通知集群状态变更,因为每个节点都应该知道集群中所有数据的状态,ES实际工作的主节点只有一个,其他都是以影子主的形式存在
- 可选主节点 Master Eligible Node:有资格成为master的节点,具体选主方式非常诡异,node id 小的具有更高的优先权,也可以改为zk的选举机制,master节点和其他节点的保活方式是互ping,有问题,就准备选举新的master
- 数据节点 data node:保存主从分片数据的节点,一切工作都为了管理数据,
ES写入数据的步骤
两个概念需要注意 master node和primary shard 是完全不同的意义,
master node 是主节点,是保存管理集群状态的服务
primary shard 是主分片,是数据的一部分
从集群角度(ES层面):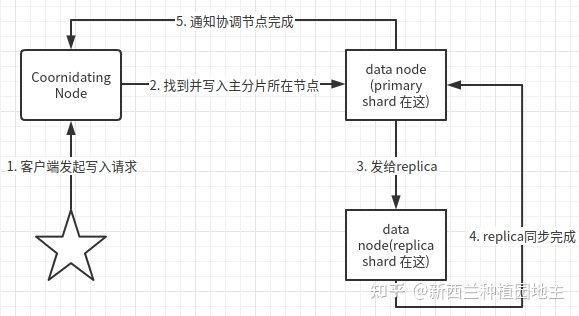
- 客户端发起写入请求
- 协调节点将请求定位给到主分片坐在node
- 主分片执行后,发送数据同步请求给其他replica shard(复制分片)所在node
- 等待大部分replica 所在node同步完成并返回
- primary shard 所在node 详情协调节点写入完成
在第二步的时候,发现index,不存在时,需要转到master,master会发起索引结构写入并负责通知其他所有节点集群状态变更,再有就是 第三步,发给 replica有的节点失败时,也会通知master,
节点内部角度写入: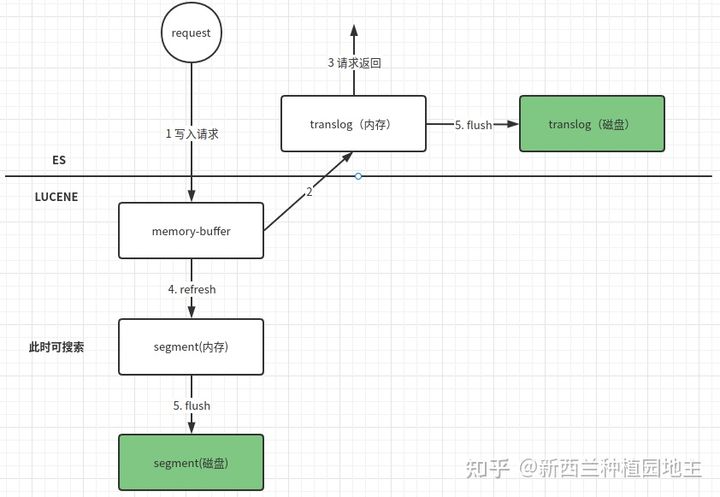
translog和innoDB的redo log 意义类似,可以保证数据可靠性(可选同步或者异步),断电灰度需要依靠translog,123步骤操作返回后,需要ES定时调用refresh将licene内存中的数据生成内存segment,此时数据就可以被搜索到了,但是还没落盘,当五分钟或者translog文件大于512兆,会执行flush操作,操作完成后,segment和translog都会落盘
另外,针对更新字段可能发生的版本冲突的问题,ES采用versionMap,同时保存多个版本的全量doc数据并记录版本号,加锁,进行原子的删除+新增操作后后释放锁,
为什么先写入luncene内存
ES采用先写lucene内存再写transolg的方式,是因为如果先写日志,再写lucene就要解决日志写入成功,但是Lucene写入不成功的问题,因为lucene需要进行分词,而且lucene内存写入即返回成功,这样避免了回滚成本
refresh 是将不可搜索的内存数据转化为内存segment,
flush 是将内存中的segment和translog存储到磁盘上
从集群获取数据的步骤
获取数据分两种,一种是根据docID直接获取,第二种是对数据进行search(搜索)
search通常分为Query和Fetch两阶段进行,并由多种状态,默认是query-thten-fetch,即:query得到数据的docID,之后利用docID去Fetch对应节点Document数据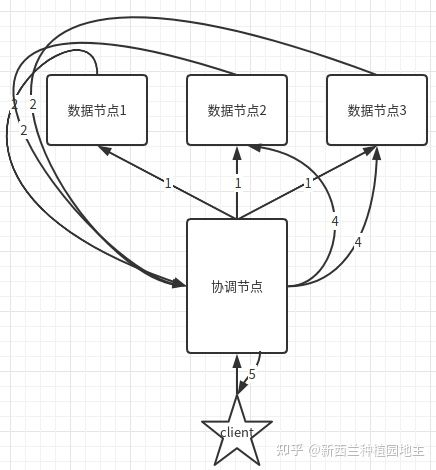
- 客户端向调节节点请求搜索top N条数据,协调节点进入第一阶段,将查询请求转发给其他节点
- 收到Query请求的节点在内部查询并打基础分排序,向调节节点返回M条
- 协调节点收到相应列表(包含docID/排序字段),进行rescore重新打分,综合排序,并获得N个dicID
- 协调节点进入第二阶段,根据这些排序后的docID向集群对应节点发起获取N个document
- 协调节点获得返回的N条Document 并返回客户端
基本名词
index : es里的index,相当于一个数据库
type : 相当于库里的表
id : 唯一,相当于主键
node :节点是es的实例,一台机器可以运行多个实例,但是同一台机器上的实例在配置文件中要确保http和TCP端口不同
cluster :代表一个集群,集群中有多个节点,其中有一个会被选为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的,
shards :代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处可以把一个大的索引分为多个,分到不同的节点上,构成分布式搜索,分片的数量只能在索引创建前指定,并且索引创建后不能更改改
replicas:代表索引副本,es可以设置多个索引的副本,副本的作用,一是提高形同的容错率,当某个节点,某个分片损坏时,恢复使用,二是,提高es的查询效率,es会自动对搜索进行负载均衡,
mapping,关系映射,类似数据库字段类型声明

若有收获,就点个赞吧
0 人点赞
