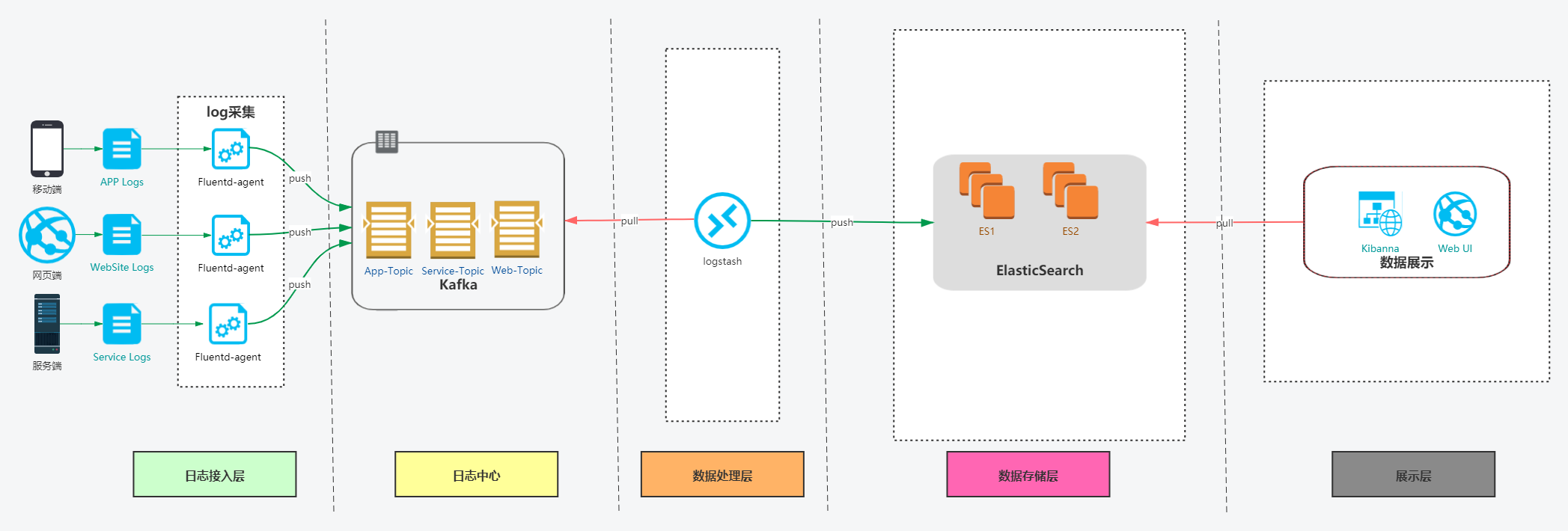
ES
1.部署环境准备
系统:CentOS Linux release 7.8.2003
IP:192.168.88.11,192.168.88.12,192.168.88.13
网络:确保内网可以相互通信,注意防火墙配置
安装目录:/data/
内核参数设置,需要加大系统的句柄数量和mmap值
ulimit -n 65535sysctl -w vm.max_map_count=262144
否则ES启动的时候会报错
永久配置
在/etc/security/limits.conf添加
vim /etc/security/limits.confes - nofile 65535
在/etc/sysctl.conf添加
vim /etc/sysctl.confvm.max_map_count=262144sysctl -p
2.下载安装包
下载elasticsearch,有basic和oss等不同的包,这里是oss(不包含x-pack),
链接:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-oss-7.10.0-linux-x86_64.tar.gz
**
3.单机测试
解压安装包
cd /datatar xf elasticsearch-oss-7.10.0-linux-x86_64.tar.gz
进入文件夹
cd elasticsearch-7.10.0/
elasticsearch已经自带jdk环境了
默认elasticsearch是不让用root用户运行的,直接启动就会报错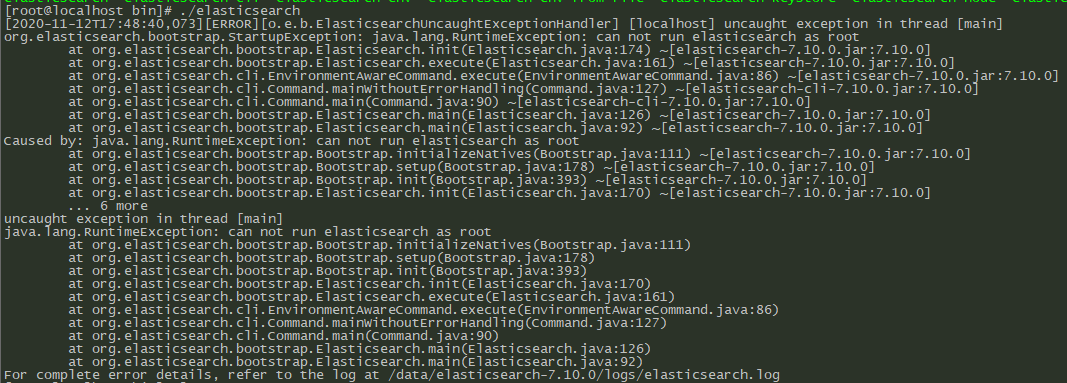
先创建启动elasticsearch的用户,这里我用的是es用户
useradd es -M -s /sbin/nologin
将elasticsearch目录的权限赋给es用户
chown -R es:es /data/elasticsearch-7.10.0
用新加好的es用户启动elasticsearch试试
sudo -u es /data/elasticsearch-7.10.0/bin/elasticsearch
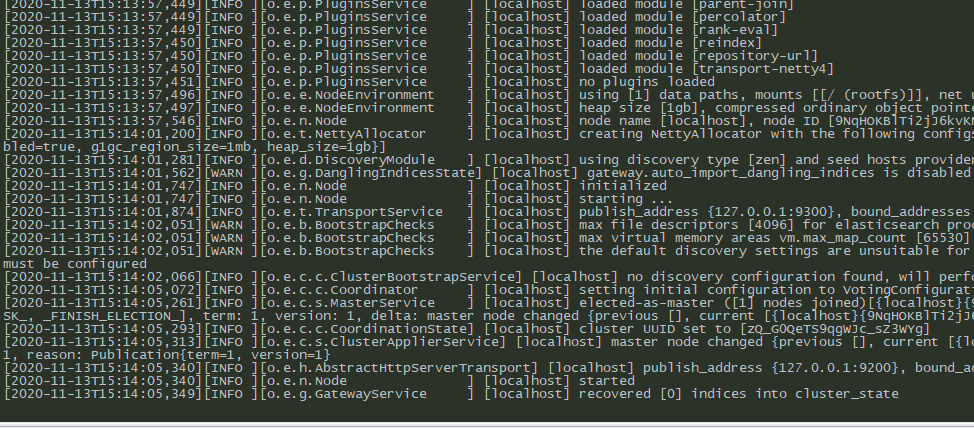
4.集群配置
没有报错就是启动成功了,然后就是配置集群
基本需要配置如下参数
#集群名称cluster.name: test#数据和日志目录我都没有设置,生成环境有需要可以指定目录node.name,这里我直接填的是本机的ip,(其它节点填自己的IP或者主机名就好)#绑定的hosts,我这里设置0.0.0.0,监听所有地址;network.host: 0.0.0.0#配置初始节点的hosts,如果不加端口,那就用默认端口discovery.seed_hosts: ["192.168.88.11", "192.168.88.12","192.168.88.13"]#因为是全新的集群,需要手动设置初始化master节点,集群形成完毕之后,这个参数就可以从配置文件里面去掉(其余节点无需配置)cluster.initial_master_nodes: ["192.168.88.11"]
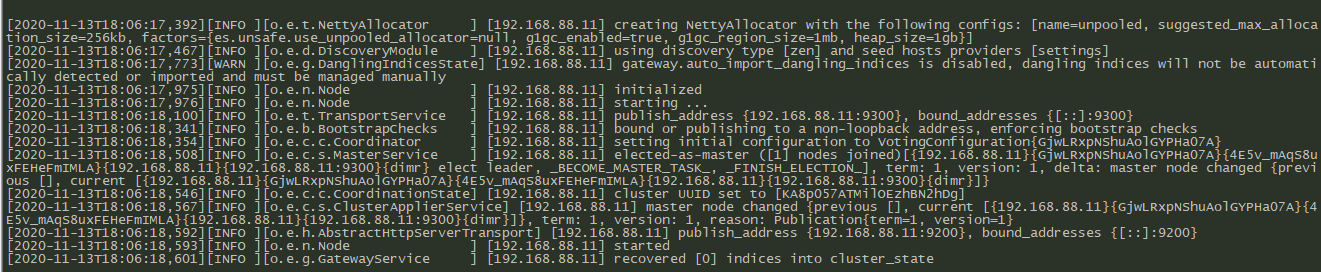
5.从节点启动
其它node启动,重复以上所有步骤
,把配置项中的node.name换成自己的ip或者主机名称然后启动就好,这里不再赘述
192.168.88.12节点启动成功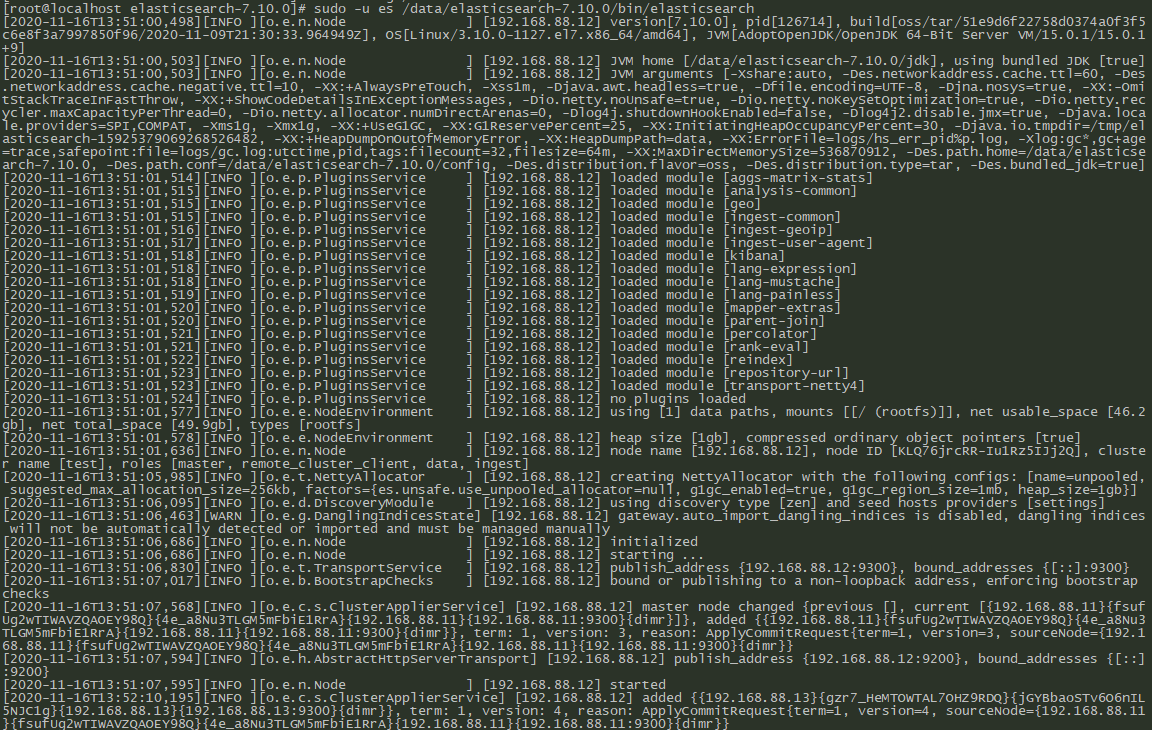
192.168.88.13节点启动成功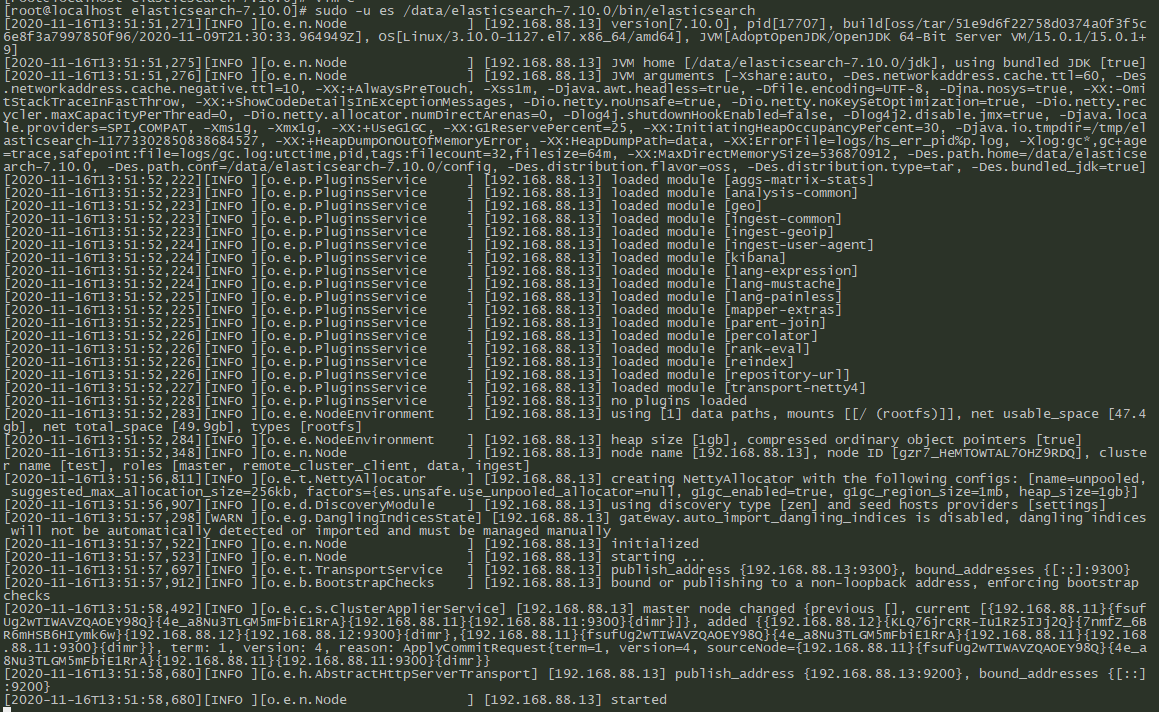
启动完成后主节点也会有日志显示节点加入成功
6.可视化工具安装
Cerebro
https://github.com/lmenezes/cerebro/releases
这里我用的是cerebro, 部署在192.168.88.11
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.2/cerebro-0.9.2.tgz
然后解压,进去运行就好了
如果有常用的es集群地址,可以在application.conf下配置
vim /data/cerebro-0.9.2/conf/application.conf
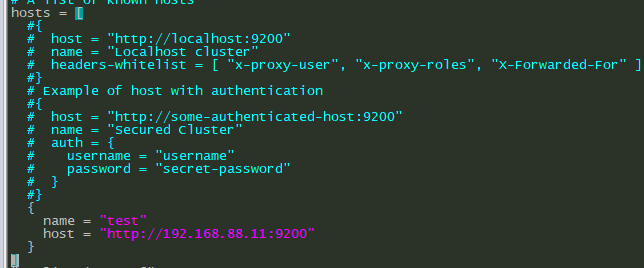
然后启动
访问http://192.168.88.11:9000
点test名称连接集群,已经可以看到我们的3个节点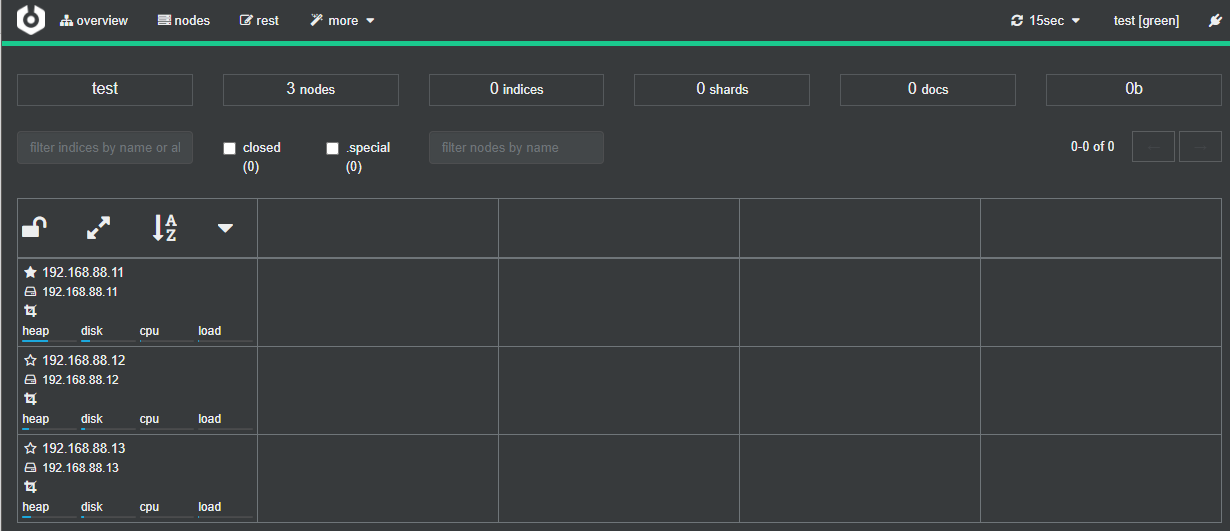
点其它菜单,可以看到集群的其它信息,这里不做过多的介绍,剩下的自己摸索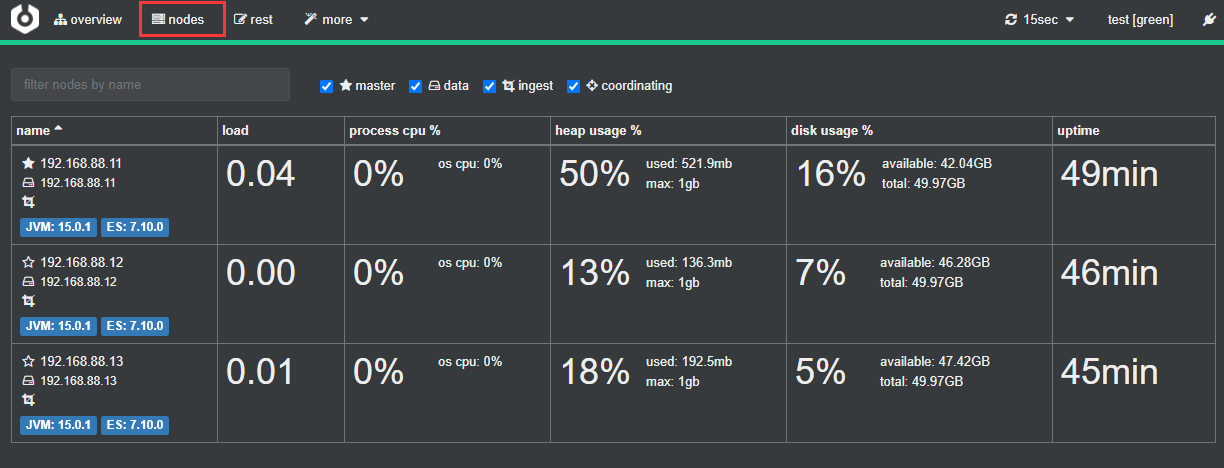
ES集群搭建到此结束
参考文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/index.html
7.X版本重大更新:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/breaking-changes-7.0.html
Kafka+Zooper
1.kafka环境准备
系统:CentOS Linux release 7.8.2003Ip:192.168.88.11,192.168.88.12,192.168.88.13安装目录:/data/
下载
https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.6.0/kafka_2.13-2.6.0.tgz
2.zookeeper配置
2.1 zookeeper配置启动,下面简称zk
由于kafka依赖ZooKeeper,先要安装好zookeeper,kafka压缩包里已经附带zookeeper了,我们配置一下,启动就好,线上不建议单机部署,zk,这里也搭建的是集群模式,最好也是3(奇数)台,防止脑裂。搭建可以参考:https://zookeeper.apache.org/doc/current/zookeeperStarted.html
2.2 解压安装包
cd /datatar xf kafka_2.13-2.6.0.tgzcd /data/kafka_2.13-2.6.0
2.3 编辑zookeeper配置文件,修改或者添加如下配置
vim config/zookeeper.properties#clientPort端口设置clientPort=2181#maxClientCnxns客户端并发数量,0代表不限制maxClientCnxns=0#admin.enableServer默认是启动的,这里我们关闭,或者在其中一台上启用就好admin.enableServer=false#tickTime超时时间,单位毫秒tickTime =2000#initLimit集群中的follower服务器(F)与leader服务器(L)之间 初始连接 时能容忍的最多心跳数initLimit=10#syncLimit Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是10*2000=20秒syncLimit=5#dataDir 快照日志的存储路径dataDir=/data/zookeeper/#dataLogDir 事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多dataLogDir=/data/logs/zookeeper#server.n 这个n是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里server.1=192.168.88.11:2888:3888server.2=192.168.88.12:2888:3888server.3=192.168.88.13:2888:3888
2.4 创建目录
#以上配置3台机器都需要执行一遍mkdir /data/zookeeper/mkdir /data/logs/zookeeper
2.5 配置myid文件
在192.168.88.11上
echo 1 >/data/zookeeper/myid
在192.168.88.12上
echo 2 >/data/zookeeper/myid
在192.168.88.13上
echo 3 >/data/zookeeper/myid
2.6 启动zk
cd /data/kafka_2.13-2.6.0./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
启动正常,但是有错误日志显示找不到sever.2和server.3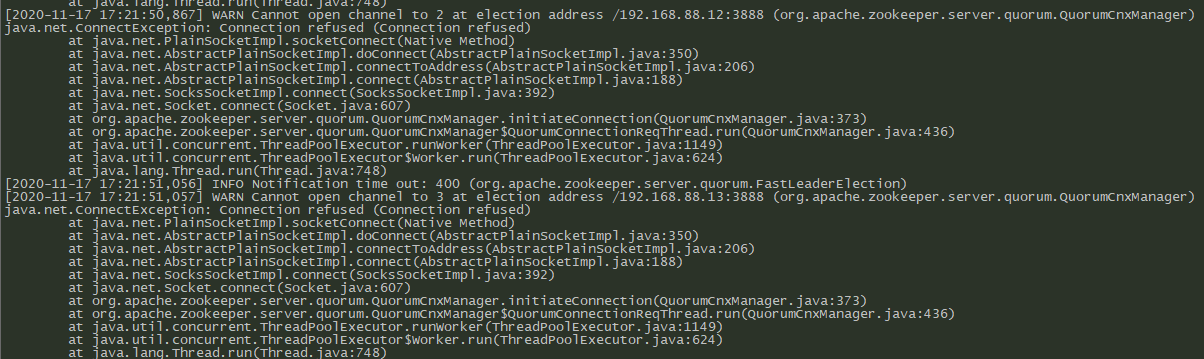
然后再启动192.168.88.12和192.168.88.13上的zk,启动都是正常的
2.7 连接zookeeper
启动完毕后可以用kafka安装目录bin目录下的zookeeper-shell.sh连接zk测试是否正常
cd /data/kafka_2.13-2.6.0/bin./zookeeper-shell.sh 127.0.0.1:2181
2.8 测试
ls /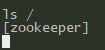
然后新建一个节点
create /test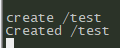
再ls /查看一下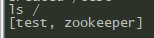
可以看到多了一个test节点,那么再去其它节点查看是否数据同步了
其它节点同样可以看到新建的/test节点,那么zk集群就算建好了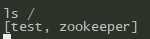
3.Kafka配置
3.1 kafka配置文件路径
cat /data/kafka_2.12-2.5.0/config/server.properties
3.2 配置修改及解释
我这里配置的主要有以下选项,更多参数请参考官方文档:
http://kafka.apache.org/documentation/#configuration
#当前机器在集群中的唯一标识,和zookeeper的myid性质一样,其余两台分别配置1和2broker.id=0#主机名为空表示绑定到默认接口,这里建议使用域名代替ip,将来如果迁移集群也不用动配置文件,还有如果写死了内网ip,那么通过外网IP是没有办法访问集群的,用域名一劳永逸,listeners和advertised.listeners是不允许绑定0.0.0.0这个地址的,listeners=PLAINTEXT://node1.kafka:9092#执行网络操作的线程数num.network.threads=3#指定 io 操作的线程数num.io.threads=8# socket的发送缓冲区(SO_SNDBUF)socket.send.buffer.bytes=1048576# socket的接收缓冲区 (SO_RCVBUF)socket.receive.buffer.bytes=1048576# socket请求的最大字节数。为了防止内存溢出,message.max.bytes必然要小于socket.request.max.bytes=104857600#消息数据存放目录,多个目录使用逗号分割log.dirs=/data/logs/kafka# 每个topic的默认分区个数,更多的partition会产生更多的segment filenum.partitions=3# 每个数据目录用于在启动时进行日志恢复和在关闭时进行刷新的线程数,默认值为: 1num.recovery.threads.per.data.dir1# offset topic的replicas数量(设置更高以确保可用性)。在集群大小满足此复制因子要求之前(例如set为3,而broker不足3个),内部topic创建将失败offsets.topic.replication.factor=1# 事务主题的复制因子(设置更高以确保可用性)。 内部主题创建将失败,直到群集大小满足此复制因素要求transaction.state.log.replication.factor=1# 覆盖事务主题的min.insync.replicas配置,在min.insync.replicas中,replicas数量为1,该参数将默认replicas定义为2transaction.state.log.min.isr=2# 更新记录起始偏移量的持续记录的频率,官方建议不要动这个参数log.flush.interval.messages=10000# 更新记录起始偏移量的持续记录的频率(时间/毫秒)log.flush.interval.ms=1000# 默认消息的最大持久化时间,168小时,7天log.retention.hours=168#这个参数是:因为kafka的消息是以追加的形式落地到文件,当超过这个值的时候,kafka会新起一个文件log.segment.bytes=1073741824#每隔300000毫秒去检查上面配置的log失效时间(log.retention.hours=168 ),到目录查看是否有过期的消息如果有,删除log.retention.check.interval.ms=300000#是否启用log压缩,一般不用启用,启用的话可以提高性能log.cleaner.enable=true#设置zookeeper的连接端口zookeeper.connect=192.168.88.11:2181,192.168.88.12:2181,192.168.88.13:2181/kafkazookeeper.connection.timeout.ms=18000group.initial.rebalance.delay.ms=0
然后启动就好了
3.3 Kafka可视化软件
然后kafka我们也需要装一个监控软件
Kafka-eagle
下载地址:https://codeload.github.com/smartloli/kafka-eagle-bin/tar.gz/v2.0.3
解压
tar xf kafka-eagle-bin-2.0.3.tar.gzcd /data/kafka-eagle-bin-2.0.3tar xf kafka-eagle-web-2.0.3-bin.tar.gz
3.4 修改配置文件
#修改这两行的内容即可vim conf/system-config.propertieskafka.eagle.zk.cluster.alias=test-kafkatest-kafka.zk.list=192.168.88.11:2181,192.168.88.12:2181,192.168.88.13:2181/kafka
3.5 开启JMX
记得kafka开启jmx,开启的话在这个脚本
vim /data/kafka_2.13-2.6.0/ bin/kafka-server-start.shKAFKA_HEAP_OPTS下面加入export JMX_PORT=9999 # 然后重启即可./bin/ke.sh start
3.6 kafka可视化界面
注意:jmx远程调用会返回一个主机以host_name映射的ip,如果你的hostname解析的不是内网IP,有可能会返回“create has error,msg is java.rmi.ConnectException cannot be cast to javax.management.remote.JMXConnector”
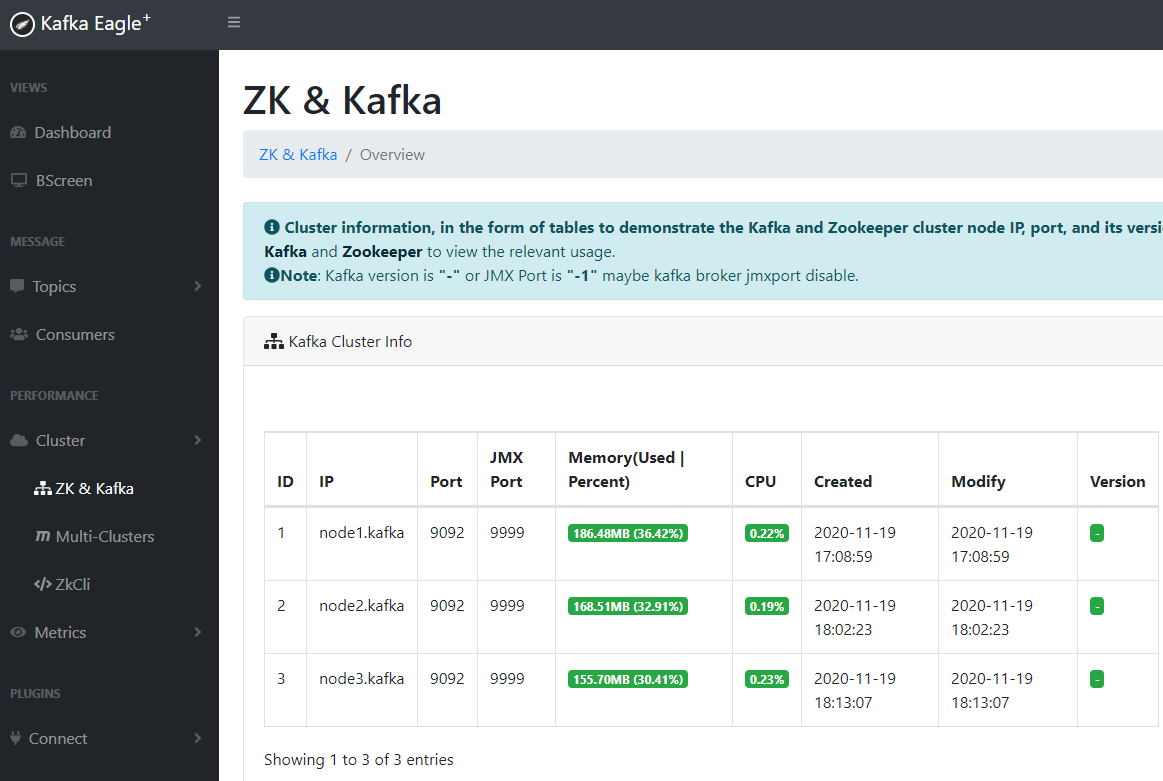
访问192.168.88.11:8048
用户名/密码:admin/123456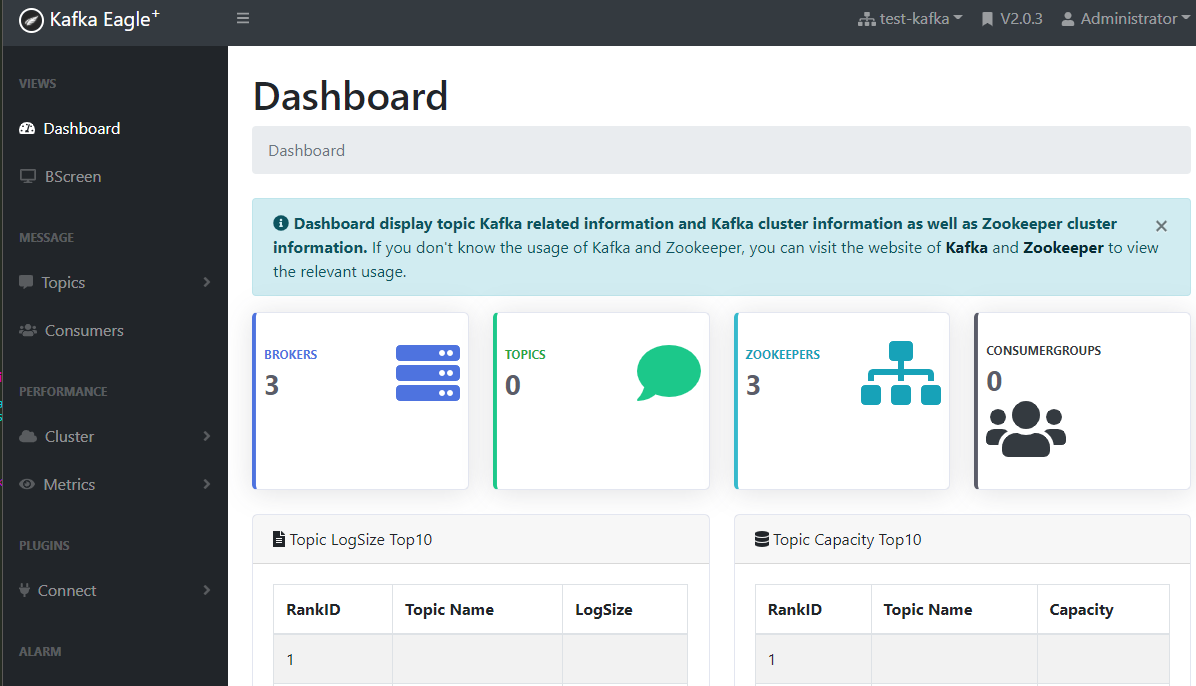
常用命令
查看topic列表./kafka-topics.sh --zookeeper localhost:2181/kafka –list查看topic详情./kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic nginx-access-log查询看topic内容./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic nginx-access-log --from-beginning
td-agent安装
参照官网教程:
https://docs.fluentd.org/installation
1.脚本一键安装
执行完没有报错即安装完毕
# td-agent 4$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent4.sh | sh# td-agent 3$ curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh | sh
2.配置td-agent
配置文件在/etc/td-agent/目录下
mv td-agent.conf td-agent.conf.bak
备份一下原始配置,接下来以收集nginx日志为例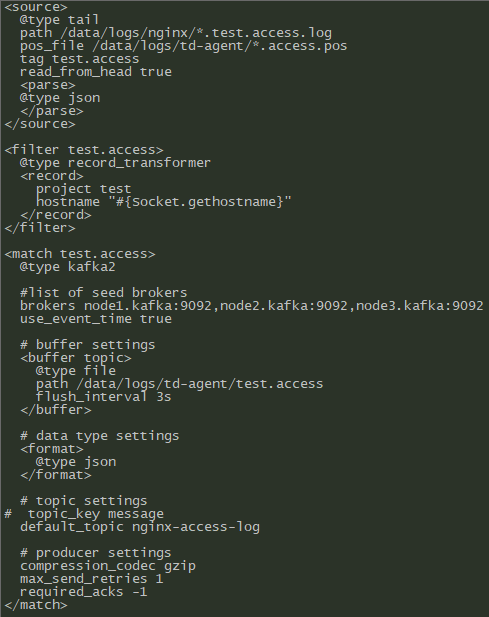
2.1.配置详解
配置文件主要由以下指令组成:1. Source设置输入来源2. Match设置输出目的地3. Filter过滤器,处理管道,可以改写流程中的数据4. System全局配置,比如收集器的日志输出目录,级别等5. @include引入其它配置文件本文中用到的配置:<system>log_level trace</system><source>#每个source指令必须要有输入插件的类型,详见https://docs.fluentd.org/input@type tail#日志路径,只可以指定多个路径,以逗号分隔,支持通配符.path /data/logs/nginx/*.access.log#记录日志文件最后读取的位置.pos_file /data/logs/td-agent/*.access.pos#收集事件的标签,可以为通配符.tag test.accessread_from_head true#日志格式,必填<parse>#解析类型@type json</parse></source>#过滤器<filter test.access>#使用的过滤器插件类型@type record_transformer#recode指令,内部使用键值对<record>#project,这个属于自定义字段project test#主机的hostnamehostname "#{Socket.gethostname}"</record></filter>#输出配置项<match test.access>#输出类型,参考官方文档https://docs.fluentd.org/output/kafka@type kafka2#kafka服务器brokers列表brokers node1.kafka:9092,node2.kafka:9092,node3.kafka:9092#发送消息的最大字节大小,如果发送的数据大于kafka配置的接收值大小,那么消息就会发送失败max_send_limit_bytes 1048576#将收集器事件事件设置为kafka的createtimeuse_event_time true# buffer settings# 缓冲区设置<buffer topic>@type file#缓冲区块存储的路径,如果填'*'则为随机字符,必填path /data/logs/td-agent/test.access#刷新间隔flush_interval 3s</buffer># data type settings#扩展和重新定义输出的格式<format>@type json</format># topic settings# topic_key message# topic名称default_topic nginx-access-log# producer settings# 压缩消息compression_codec gzip# 重试发送次数max_send_retries 1# 和kafka发送数据的健壮性有关,详细了解搜索kafka的request.required.acksrequired_acks -1</match>
3.启动
配置了以上内容启动即可,
systemctl start td-agent
4. 进kafka web查看
然后kafka eagle监控里可以看到数据已经进来了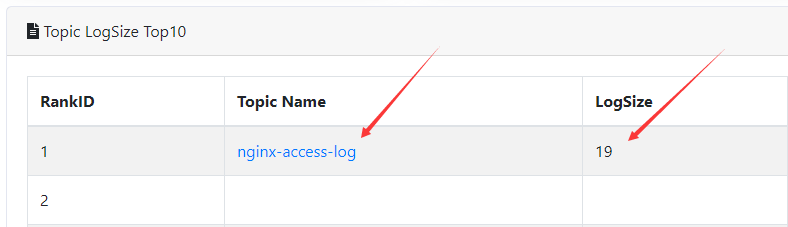
Td-agent完成
**
logstash安装
1.Logstash安装和下载
https://artifacts.elastic.co/downloads/logstash/logstash-7.10.0-linux-x86_64.tar.gz
2.安装配置
cd /data/logstash-7.10.0/config#新建配置文件vim nginx-access-log.confinput {kafka {bootstrap_servers => "node1.kafka:9092,node2.kafka:9092,node2.kafka:9092"topics => ["nginx-access-log"]consumer_threads => 4codec => "json"}}output {elasticsearch {hosts =>["192.168.88.11:9200","192.168.88.12:9200","192.168.88.13:9200"]index => "nginx-access-log-%{+YYYY.MM.dd}"# sniffing => true#字段映射模版template => "/data/logstash7.10.0/template/nginx-access-log.json"template_name => "nginx-access-log"template_overwrite => true}}#新建字段映射模版mkdir template/vim nginx-access-log.json{"template":"nginx-access-log-*","settings":{"index.refresh_interval":"10s","number_of_shards":"3","number_of_replicas":"0"},"mappings": {"properties": {"@timestamp": {"type": "date"},"@version": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"hostname": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_body_size": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_host": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_referer": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_remote_addr": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_request": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_request_time": {"type": "double","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_status": {"type": "long","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_ua": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_uri": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"http_x_forward_for": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"project": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"time_local": {"type": "date"},"upsteam_status": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"upstream_addr": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"upstream_cache_status": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"upstream_response_time": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}
3. 启动
./bin/logstash -f config/nginx-access-log.conf --path.data=/data/logs/logstash/nginx-access-log
启动没有报错,es展示工具显示已经有了数据,索引已经生成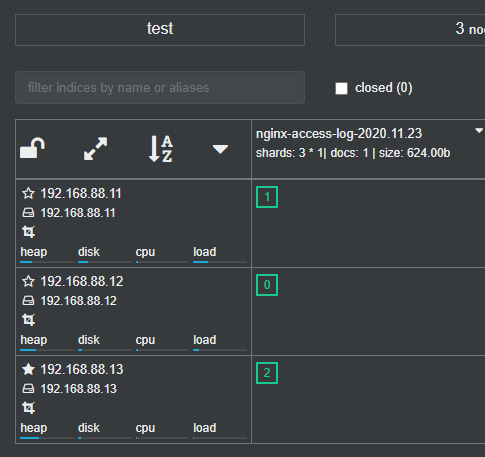
kibana安装
1.安装下载:
# 一定要下载oss版本的,因为之前安装的es就是oss版本的https://artifacts.elastic.co/downloads/kibana/kibana-oss-7.10.0-linux-x86_64.tar.gz
2.配置
cd /data/kibana-7.10.0-linux-x86_64/config/#添加server.host: "0.0.0.0"elasticsearch.hosts: ["http://192.168.88.11:9200","http://192.168.88.12:9200","http://192.168.88.11:9300"]
3.启动
/data/kibana-7.10.0-linux-x86_64/bin/kibana
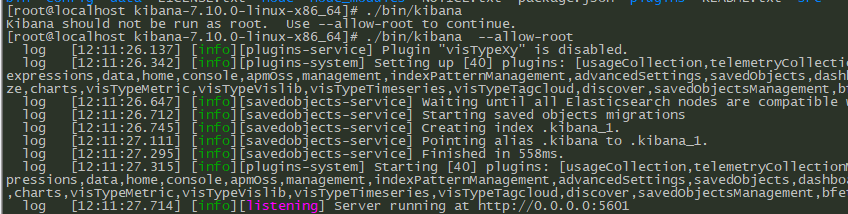
4.web配置
打开http://192.168.88.11
点explore on my own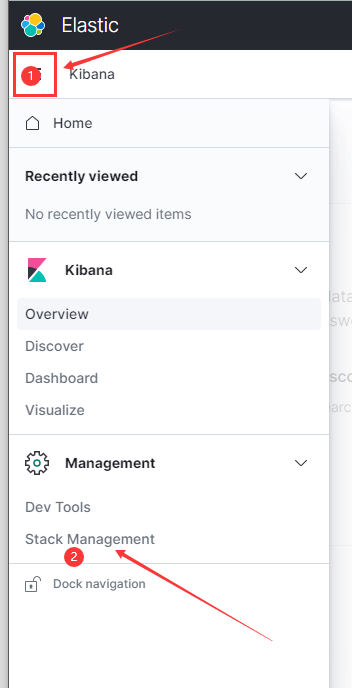
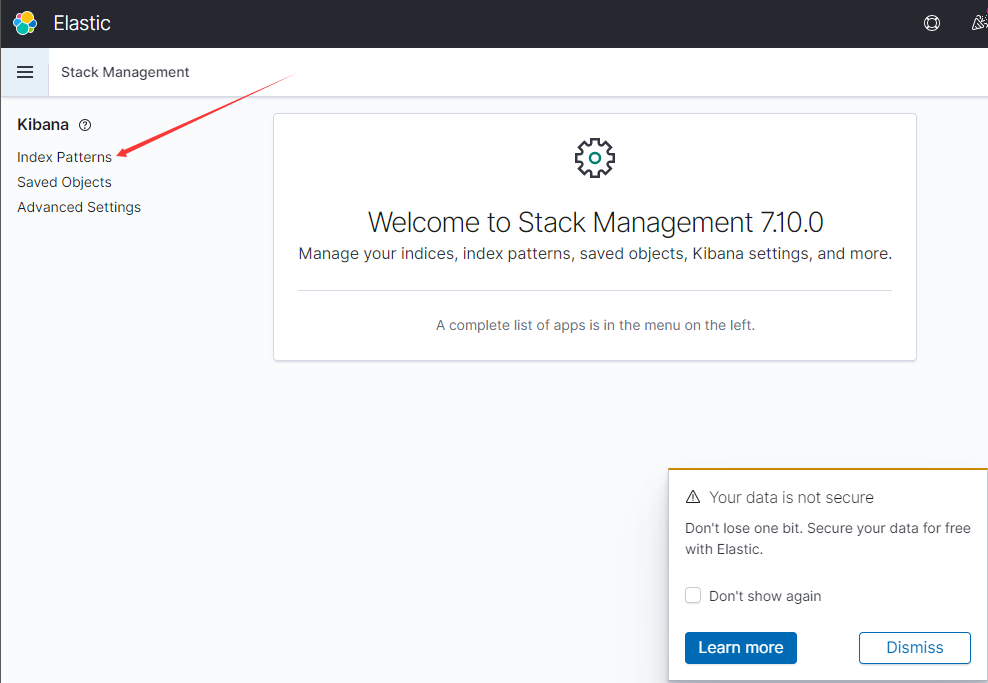
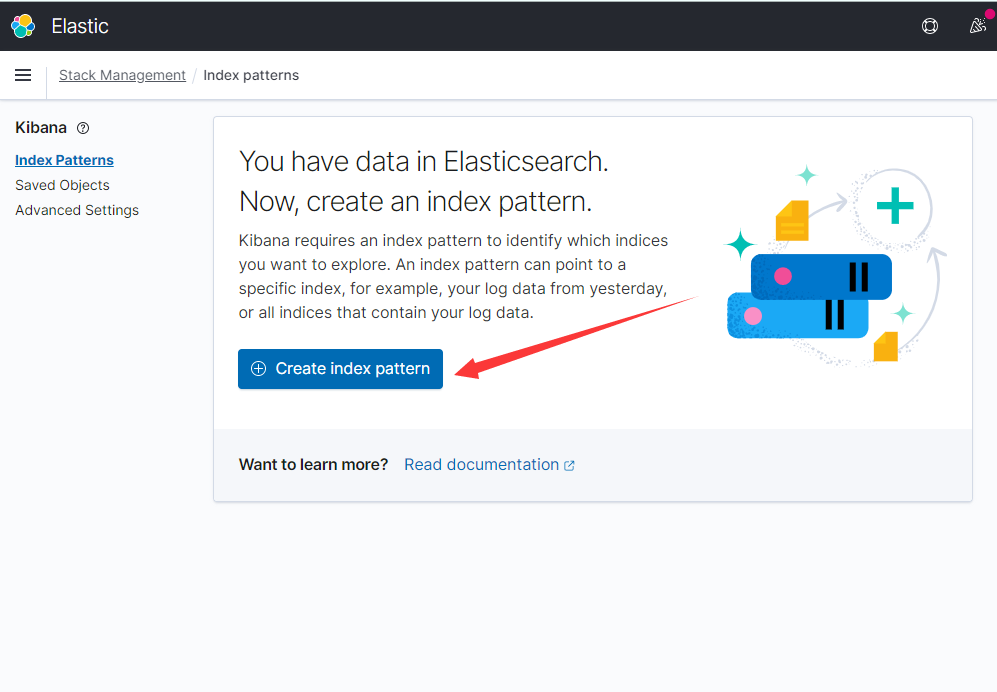
我们在es中已经有数据,创建一个索引模式即可查看数据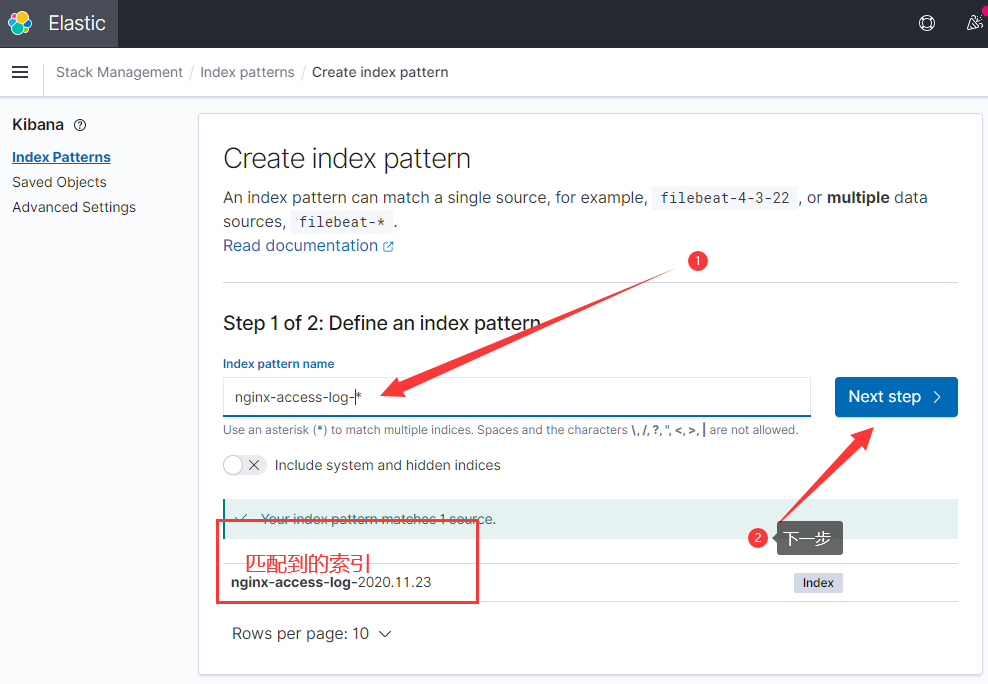
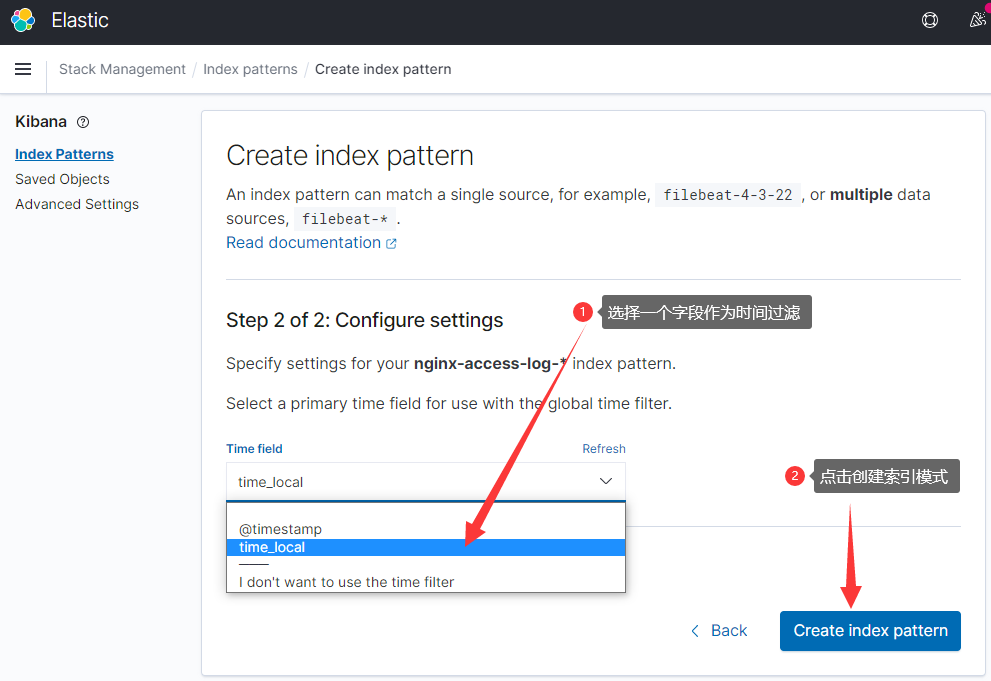
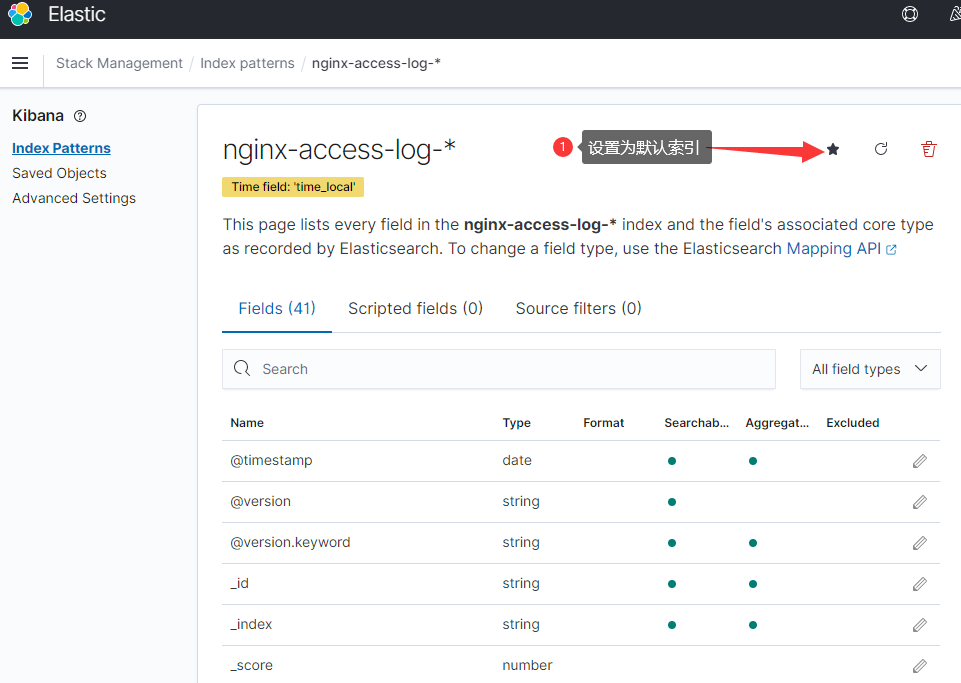
选择左侧面板的discover,访问一下(http://192.168.88.14)测试页面,最新的3条日志就展示在面板上了
**

若有收获,就点个赞吧
0 人点赞
