1 子查询
1.1 概念
- 出现在其他语句内部的select语句,称为子查询或内查询。 而内部嵌套其他select语句的查询,称为主查询或外查询。
1.2 分类
- 按照子查询出现的位置:
- select后面:仅仅支持标量子查询。
- from后面:支持表子查询。
- where或having后面:支持标量子查询或列子查询,行子查询。
- exists后面(又称为相关子查询):支持表子查询。
- 按结果集的行列数不同:
- 标量子查询(结果集只有一行一列)
- 列子查询(结果集只有一列多行)
- 行子查询(结果集有一行多列)
- 表子查询(结果集,一般为多行多列)
1.3 where或having后面
1.3.1 特点
- ①子查询放在小括号内。
- ②子查询一般放在条件的右侧。
- ③标量子查询,一般搭配单行操作符使用(>、<、>=、<=、<>)。
- ④列子查询,一般搭配多行操作符使用(in、any/some、all)。
1.3.2 标量子查询
- 查询谁的工资比Abel高。
SELECTlast_nameFROMemployeesWHEREsalary > ( SELECT salary FROM employees WHERE last_name = 'Abel' );
- 返回job_id和141号员工相同,salary比143号员工多的员工姓名、job_id和工资。
SELECTlast_name,job_id,salaryFROMemployeesWHEREjob_id = ( SELECT job_id FROM employees WHERE employee_id = 141 )AND salary > ( SELECT salary FROM employees WHERE employee_id = 143 );
- 返回公司工资最少的员工的last_name、job_id和salary。
SELECTlast_name,job_id,salaryFROMemployeesWHEREsalary = ( SELECT min( salary ) FROM employees );
- 查询最低工资大于50号部门最低工资的部门id和其最低工资。
SELECTdepartment_id,MIN( salary )FROMemployeesGROUP BYdepartment_idHAVINGmin( salary ) > ( SELECT min( salary ) FROM employees WHERE department_id = 50 );
1.3.3 列子查询
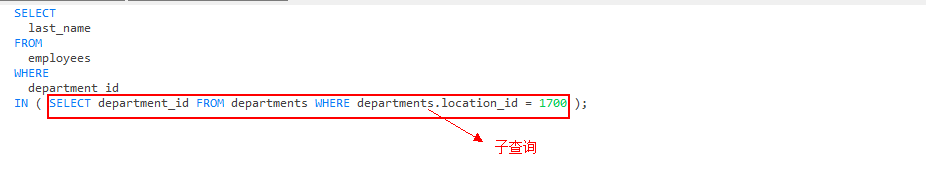
- 返回location_id是1400或1700的部门中的所有员工姓名。
SELECTlast_nameFROMemployeesWHEREdepartment_id IN ( SELECT DISTINCT department_id FROM departments WHERE location_id IN ( 1400, 1700 ) );
- 返回其它工种中比job_id为’IT_PROG’工种任一工资低的员工的员工号、姓名、job_id以及salary。
SELECTemployee_id,last_name,job_id,salaryFROMemployeesWHEREsalary < ANY ( SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG' ) and job_id != 'IT_PROG';
- 返回其它工种中比job_id为’IT_PROG’工种所有工资低的员工的员工号、姓名、job_id以及salary。
SELECTemployee_id,last_name,job_id,salaryFROMemployeesWHEREsalary < ALL ( SELECT DISTINCT salary FROM employees WHERE job_id = 'IT_PROG' ) and job_id != 'IT_PROG';
1.3.4 行子查询(用的较少)
- 查询员工编号最小并且工资最高的员工信息。
SELECT * FROM employeesWHERE ( salary, employee_id ) = (( SELECT max( salary ) FROM employees ),( SELECT min( employee_id ) FROM employees ));
1.4 select后面
- 查询每个部门的员工个数。
SELECT d.*,( SELECT count(*) FROM employees e WHERE e.department_id = d.department_id ) as '员工个数'FROMdepartments d;
1.5 from后面
- 查询每个部门的平均工资的工资等级。
SELECTtemp.department_id,jg.grade_levelFROM( SELECT department_id AS department_id, avg( salary ) AS `avg` FROM employees GROUP BY department_id ) tempINNER JOIN ( SELECT grade_level, highest_sal, lowest_sal FROM job_grades ) jg ON temp.avg BETWEEN jg.lowest_salAND jg.highest_sal;
1.6 exists后面
- 语法:
exists(完成的查询语句)结果:0或1
- 查询有员工的部门名。
SELECTdepartment_nameFROMdepartments dWHEREEXISTS ( SELECT * FROM employees e WHERE d.department_id = e.department_id );
2 分页查询
- 语法:
SELECT 查询列表FROM 表 [join type] JOIN 表2ON 连接条件WHERE 筛选条件GROUP BY 分组字段HAVING 分组筛选条件ORDER BY 排序字段LIMIT 起始索引(从0开始),每页显示条数。
- 示例:查询前5条员工信息。
SELECT*FROMemployeesLIMIT 0,5;
3 union联合查询
3.1 概念
- 将多条查询语句的结果合并成一个结果。
3.2 语法
查询语句1UNION查询语句2……;
3.3 应用示例
- 查询部门编号>90或邮箱包含a的员工信息。
SELECT * FROM employees WHERE last_name LIKE '%a%'UNIONSELECT * FROM employees WHERE department_id > 90 ;
3.4 特点
- ①要求多条查询语句的查询列数是一致的。
- ②要求多条查询语句的每一列的类型和顺序最好是一致的。
- ③union关键字默认是去重,如果使用union all,可以包含重复项。

若有收获,就点个赞吧
0 人点赞
