1 Logstash学习
1.1 Logstash是什么?
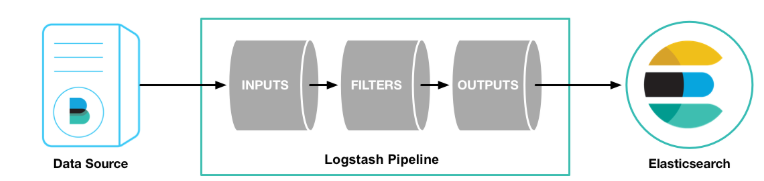
- Logstash是一个数据抽取工具,将数据从一个地方转移到另一个地方。
- Logstash值所以功能强大和流行,还和其丰富的过滤器插件是分不开的,过滤器提供的并不单单是过滤的功能,还可以对进入过滤器的原始数据进行复杂的逻辑处理,甚至添加独特的事件到后续流程中。
- Logstash配置文件有三个部分组成,其中input、output部分是必须配置,filter部分是可选配置,而filter就是过滤器插件,可以在这部分实现各种日志过滤功能。
1.2 配置文件
input{# 输入插件}filter{# 过滤匹配插件}output{# 输出插件}
1.3 启动操作
- 启动命令(Windows下):表示输入源是控制台,输出源是控制台
logstash.bat -e 'input{stdin{}} output{stdout{}}'
- 启动命令(Windows下):将配置写入到配置文件中
- Logstash/conf目录下新建test1.conf
input {stdin {}}output {stdout {codec=>rubydebug}}
- 启动:
logstash.bat -f ../config/test1.conf
1.4 Logstash输入插件(input)
1.4.1 官网说明
- 官网。
1.4.2 标注输入(stdin)
input{stdin{}}output{stdout {codec=>rubydebug}}
1.4.3 读取文件(file)
- Logstash使用一个名为filewatch的ruby gem库来监听文件变化,并通过一个叫sincedb的数据库文件来记录被监听的日志文件的读取进度(时间戳),这个sincedb数据文件的默认路径在
<path.data>/plugins/inputs/file下面,文件名类似于.sincedb_123456,而<path.data>表示logstash插件存储目录,默认是LOGSTASH_HOME/data。
input {file {path => ["/var/*/*"]start_position => "beginning"}}output {stdout{codec=>rubydebug}}
默认情况下,Logstash会从文件的结束位置开始读取数据,也就是说Logstash进程会以类似tail -f命令的形式逐行获取数据。
1.4.4 读取TCP网络
input {tcp {port => "1234"}}filter {grok {match => { "message" => "%{SYSLOGLINE}" }}}output {stdout{codec=>rubydebug}}
1.5 Logstash过滤器插件(filter)
1.5.1 官网说明
- 官网。
1.5.2 Grok正则捕获
- Grok是一个非常强大的Logstash Filter插件,它可以通过正则解析任意文本,将非结构化的日志数据弄成结构化以方便查询,它是目前Logstash中解析非结构化日志数据的最好方式。
- Grok的语法规则是:
%{语法:语义}
- 假设输入的内容如下:
172.16.213.132 [07/Feb/2019:16:24:19 +0800] "GET / HTTP/1.1" 403 5039
%{IP:clientip}匹配默认获取的结果为:clientip: 172.16.213.132。 %{HTTPDATE:timestamp}匹配模式将获得的结果为:timestamp: 07/Feb/2018:16:24:19 +0800。 %{QS:referrer}匹配模式将获得的结果为:referrer: “GET / HTTP/1.1”。
- 下面是一组组合匹配默认,可以获取上面输入的内容:
%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}
- 通过上面的这个组合匹配模式,我们将输入的内容分为了5个部分,即5个字段,将输入内容分割为不同的数据字段,这对于日后解析和查询日志数据非常重要,这也是使用Grok的目的。
input{stdin{}}filter{grok{match => ["message","%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}"]}}output{stdout{codec => "rubydebug"}}
1.5.3 Date时间处理
- Date是阿金是对于排序时间和回填就数据尤其重要,它可以用来转换日志记录中的时间字段,变成Logstatsh::Timestamp对象,然后转存到@Timestamp字段里面。
filter {grok {match => ["message", "%{HTTPDATE:timestamp}"]}date {match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]}}
1.5.4 Mutate数据修改
 gsub:gsub可以通过正则表达式替换字段中匹配到的值,只对字符串有效。
gsub:gsub可以通过正则表达式替换字段中匹配到的值,只对字符串有效。
filter {mutate {gsub => ["filed_name_1", "/" , "_"]}}
 split:split可以通过指定的分隔符分割字段中的字符串为数组。
split:split可以通过指定的分隔符分割字段中的字符串为数组。
filter {mutate {split => ["filed_name_2", "|"]}}
 rename:可以实现重命名某个字段的功能。
rename:可以实现重命名某个字段的功能。
filter {mutate {rename => { "old_field" => "new_field" }}}
 remove_field:可以实现删除某个字段的功能。
remove_field:可以实现删除某个字段的功能。
filter {mutate {remove_field => ["timestamp"]}}
 geoip:地址查询归类。
geoip:地址查询归类。
filter {geoip {source => "ip_field"}}
- 示例:
input {stdin {}}filter {grok {match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }remove_field => [ "message" ]}date {match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]}mutate {convert => [ "response","float" ]rename => { "response" => "response_new" }gsub => ["referrer","\"",""]split => ["clientip", "."]}}output {stdout {codec => "rubydebug"}}
1.6 Logstash输出插件(output)
1.6.1 官网说明
- 官网。
1.6.2 概述
- output是Logstash的最后阶段,一个事件可以经过多个输出,而一旦所有输出处理完成,整个事件就执行完成。一些常用的输出包括:
- file:表示将日志数据写入磁盘上的文件。
- elasticsearch:表示将日志数据发送给ElasticSearch。ElasticSearch可以高效方便和易于查询的保存数据。
1.6.3 输出到标准输出(stdout)
output {stdout {codec => rubydebug}}
1.6.4 保存到文件(file)
output {file {path => "/data/log/%{+yyyy-MM-dd}/%{host}_%{+HH}.log"}}
1.6.5 输出到ElasticSearch
output {elasticsearch {host => ["192.168.1.1:9200","172.16.213.77:9200"]index => "logstash-%{+YYYY.MM.dd}"}}
- host:是一个数组类型的值,后面跟的值是elasticsearch节点的地址与端口,默认端口是9200。可添加多个地址。
- index:写入elasticsearch的索引的名称,这里可以使用变量。Logstash提供了%{+YYYY.MM.dd}这种写法。在语法解析的时候,看到以+ 号开头的,就会自动认为后面是时间格式,尝试用时间格式来解析后续字符串。这种以天为单位分割的写法,可以很容易的删除老的数据或者搜索指定时间范围内的数据。此外,注意索引名中不能有大写字母。
- manage_template:用来设置是否开启logstash自动管理模板功能,如果设置为false将关闭自动管理模板功能。如果我们自定义了模板,那么应该设置为false。
- template_name:这个配置项用来设置在Elasticsearch中模板的名称。
1.7 综合案例
input {file {path => ["D:/ES/logstash-7.3.0/nginx.log"]start_position => "beginning"}}filter {grok {match => { "message" => "%{IP:clientip}\ \[%{HTTPDATE:timestamp}\]\ %{QS:referrer}\ %{NUMBER:response}\ %{NUMBER:bytes}" }remove_field => [ "message" ]}date {match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]}mutate {rename => { "response" => "response_new" }convert => [ "response","float" ]gsub => ["referrer","\"",""]remove_field => ["timestamp"]split => ["clientip", "."]}}output {stdout {codec => "rubydebug"}elasticsearch {host => ["localhost:9200"]index => "logstash-%{+YYYY.MM.dd}"}}
2 集群部署
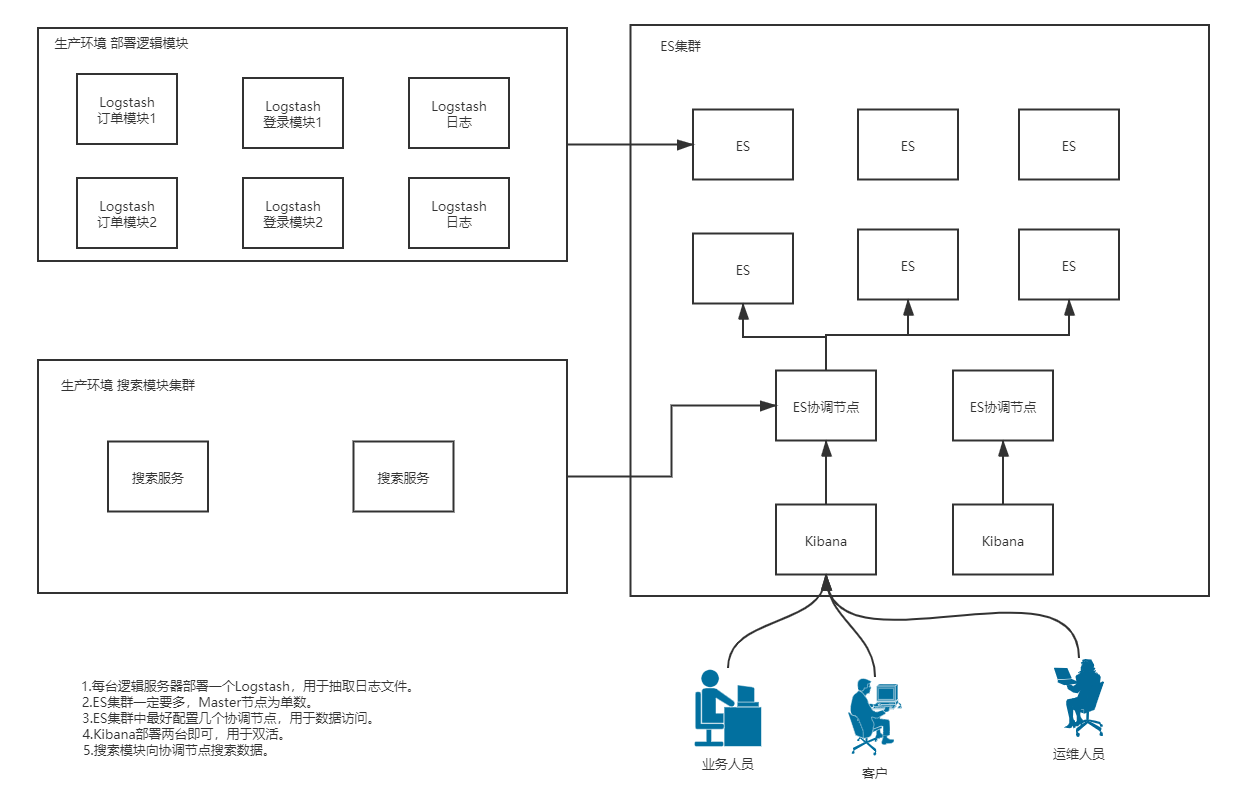
2.1 集群部署图
2.2 节点的三个角色
- 主节点:Master节点主要用于集群的管理及索引,比如新增节点、分配分片、新增和删除索引等。
- 数据节点:数据节点上保存了数据分片,它负责索引和搜索的操作。
- 客户端节点:客户端节点仅作为请求客户端存在,客户端节点的作用也作为负责均衡器,客户端节点不保存数据,只是将请求均衡发送到其他的节点。
- 通过下面的参数来配置节点的功能:
node.master: true/fase; #是否允许为主结点node.data: true/fase;#允许存储数据作为数据结点node.ingest: true/fase;#是否允许成为协调节点
- 四种组合方式:
master=true,data=true:即是主结点又是数据结点master=false,data=true:仅是数据结点master=true,data=false:仅是主结点,不存储数据master=false,data=false:即不是主结点也不是数据结点,此时可设置ingest为true表示它是一个客户端。
3 附录
3.1 Grok内置类型
USER %{USERNAME}INT (?:[+-]?(?:[0-9]+))BASE10NUM (?<![0-9.+-])(?>[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))NUMBER (?:%{BASE10NUM})BASE16NUM (?<![0-9A-Fa-f])(?:[+-]?(?:0x)?(?:[0-9A-Fa-f]+))BASE16FLOAT \b(?<![0-9A-Fa-f.])(?:[+-]?(?:0x)?(?:(?:[0-9A-Fa-f]+(?:\.[0-9A-Fa-f]*)?)|(?:\.[0-9A-Fa-f]+)))\bPOSINT \b(?:[1-9][0-9]*)\bNONNEGINT \b(?:[0-9]+)\bWORD \b\w+\bNOTSPACE \S+SPACE \s*DATA .*?GREEDYDATA .*QUOTEDSTRING (?>(?<!\\)(?>"(?>\\.|[^\\"]+)+"|""|(?>'(?>\\.|[^\\']+)+')|''|(?>`(?>\\.|[^\\`]+)+`)|``))UUID [A-Fa-f0-9]{8}-(?:[A-Fa-f0-9]{4}-){3}[A-Fa-f0-9]{12}# NetworkingMAC (?:%{CISCOMAC}|%{WINDOWSMAC}|%{COMMONMAC})CISCOMAC (?:(?:[A-Fa-f0-9]{4}\.){2}[A-Fa-f0-9]{4})WINDOWSMAC (?:(?:[A-Fa-f0-9]{2}-){5}[A-Fa-f0-9]{2})COMMONMAC (?:(?:[A-Fa-f0-9]{2}:){5}[A-Fa-f0-9]{2})IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)?IPV4 (?<![0-9])(?:(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2}))(?![0-9])IP (?:%{IPV6}|%{IPV4})HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b)HOST %{HOSTNAME}IPORHOST (?:%{HOSTNAME}|%{IP})HOSTPORT %{IPORHOST}:%{POSINT}# pathsPATH (?:%{UNIXPATH}|%{WINPATH})UNIXPATH (?>/(?>[\w_%!$@:.,-]+|\\.)*)+TTY (?:/dev/(pts|tty([pq])?)(\w+)?/?(?:[0-9]+))WINPATH (?>[A-Za-z]+:|\\)(?:\\[^\\?*]*)+URIPROTO [A-Za-z]+(\+[A-Za-z+]+)?URIHOST %{IPORHOST}(?::%{POSINT:port})?# uripath comes loosely from RFC1738, but mostly from what Firefox# doesn't turn into %XXURIPATH (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%_\-]*)+#URIPARAM \?(?:[A-Za-z0-9]+(?:=(?:[^&]*))?(?:&(?:[A-Za-z0-9]+(?:=(?:[^&]*))?)?)*)?URIPARAM \?[A-Za-z0-9$.+!*'|(){},~@#%&/=:;_?\-\[\]]*URIPATHPARAM %{URIPATH}(?:%{URIPARAM})?URI %{URIPROTO}://(?:%{USER}(?::[^@]*)?@)?(?:%{URIHOST})?(?:%{URIPATHPARAM})?# Months: January, Feb, 3, 03, 12, DecemberMONTH \b(?:Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|Nov(?:ember)?|Dec(?:ember)?)\bMONTHNUM (?:0?[1-9]|1[0-2])MONTHNUM2 (?:0[1-9]|1[0-2])MONTHDAY (?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9])# Days: Monday, Tue, Thu, etc...DAY (?:Mon(?:day)?|Tue(?:sday)?|Wed(?:nesday)?|Thu(?:rsday)?|Fri(?:day)?|Sat(?:urday)?|Sun(?:day)?)# Years?YEAR (?>\d\d){1,2}HOUR (?:2[0123]|[01]?[0-9])MINUTE (?:[0-5][0-9])# '60' is a leap second in most time standards and thus is valid.SECOND (?:(?:[0-5]?[0-9]|60)(?:[:.,][0-9]+)?)TIME (?!<[0-9])%{HOUR}:%{MINUTE}(?::%{SECOND})(?![0-9])# datestamp is YYYY/MM/DD-HH:MM:SS.UUUU (or something like it)DATE_US %{MONTHNUM}[/-]%{MONTHDAY}[/-]%{YEAR}DATE_EU %{MONTHDAY}[./-]%{MONTHNUM}[./-]%{YEAR}ISO8601_TIMEZONE (?:Z|[+-]%{HOUR}(?::?%{MINUTE}))ISO8601_SECOND (?:%{SECOND}|60)TIMESTAMP_ISO8601 %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?DATE %{DATE_US}|%{DATE_EU}DATESTAMP %{DATE}[- ]%{TIME}TZ (?:[PMCE][SD]T|UTC)DATESTAMP_RFC822 %{DAY} %{MONTH} %{MONTHDAY} %{YEAR} %{TIME} %{TZ}DATESTAMP_RFC2822 %{DAY}, %{MONTHDAY} %{MONTH} %{YEAR} %{TIME} %{ISO8601_TIMEZONE}DATESTAMP_OTHER %{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{TZ} %{YEAR}DATESTAMP_EVENTLOG %{YEAR}%{MONTHNUM2}%{MONTHDAY}%{HOUR}%{MINUTE}%{SECOND}# Syslog Dates: Month Day HH:MM:SSSYSLOGTIMESTAMP %{MONTH} +%{MONTHDAY} %{TIME}PROG (?:[\w._/%-]+)SYSLOGPROG %{PROG:program}(?:\[%{POSINT:pid}\])?SYSLOGHOST %{IPORHOST}SYSLOGFACILITY <%{NONNEGINT:facility}.%{NONNEGINT:priority}>HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT}# ShortcutsQS %{QUOTEDSTRING}# Log formatsSYSLOGBASE %{SYSLOGTIMESTAMP:timestamp} (?:%{SYSLOGFACILITY} )?%{SYSLOGHOST:logsource} %{SYSLOGPROG}:COMMONAPACHELOG %{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)COMBINEDAPACHELOG %{COMMONAPACHELOG} %{QS:referrer} %{QS:agent}# Log LevelsLOGLEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)
4 ELK用于分析日志
4.1 logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?><configuration><!--定义日志文件的存储地址,使用绝对路径--><property name="LOG_HOME" value="d:/logs"/><!-- Console 输出设置 --><appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><encoder><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern><charset>utf8</charset></encoder></appender><!-- 按照每天生成日志文件 --><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!--日志文件输出的文件名--><fileNamePattern>${LOG_HOME}/log-%d{yyyy-MM-dd}.log</fileNamePattern></rollingPolicy><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 异步输出 --><appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender"><!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 --><discardingThreshold>0</discardingThreshold><!-- 更改默认的队列的深度,该值会影响性能.默认值为256 --><queueSize>512</queueSize><!-- 添加附加的appender,最多只能添加一个 --><appender-ref ref="FILE"/></appender><logger name="org.apache.ibatis.cache.decorators.LoggingCache" level="DEBUG" additivity="false"><appender-ref ref="CONSOLE"/></logger><logger name="org.springframework.boot" level="DEBUG"/><root level="info"><!--<appender-ref ref="ASYNC"/>--><appender-ref ref="FILE"/><appender-ref ref="CONSOLE"/></root></configuration>
4.2 逻辑程序块输出日志
- 示例:
package com.sunxiaping.elk;import org.junit.jupiter.api.Test;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.boot.test.context.SpringBootTest;import java.util.Random;@SpringBootTestpublic class TestLog {private static final Logger LOGGER = LoggerFactory.getLogger(TestLog.class);@Testpublic void test() {Random random = new Random();while (true) {int userId = random.nextInt(10);LOGGER.info("userId:{},send:{}", userId, "hello world.I am " + userId);try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}}}
4.3 Logstash收集日志到ES中
- logstash.conf
input {file {path => ["D:/logs/log-x.log"]start_position => "beginning"}}filter {grok {match => { "message" => "%{DATA:datetime}\ \[%{DATA:thread}\]\ %{DATA:level}\ \ %{DATA:class} - %{GREEDYDATA:logger}" }remove_field => [ "message" ]}date {match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]}if "_grokparsefailure" in [tags] {drop { }}}output {elasticsearch {hosts => ["127.0.0.1:9200"]index => "logstash-%{+YYYY.MM.dd}"}}
- 启动Logstash:
logstash.bat -f ../config/logstash.conf

若有收获,就点个赞吧
0 人点赞
