课件
介绍 UML 类图有关的内容
什么是类?
类、对象和它们之间的关系是面向对象技术中最基本的元素,类图技术是OO方法的核心,类、图标和它们之间的关系就组成了一个类图。其中,类是以下特征的对象的集合:
- 相同性质(attributes)——即属性
- 相同行为(operations)——即操作
- 相同的对象关系——与外界其他对象、彼此之间存在同样的关系
- 相同语义(”semantics”)——即含义相同
我们可以把类看成是一个大口袋,每一个类/口袋中装的都是从属于这一个类的所有对象元素的一个集合,这些对象的相同点就是上述特征。
类图描述的是类和类之间的静态的关系,它和数据模型不同的是它不仅显示了信息的结构,也包含了系统的行为。例如,在下面的这个图中建模的就是雇员这样一个类的对象的行为: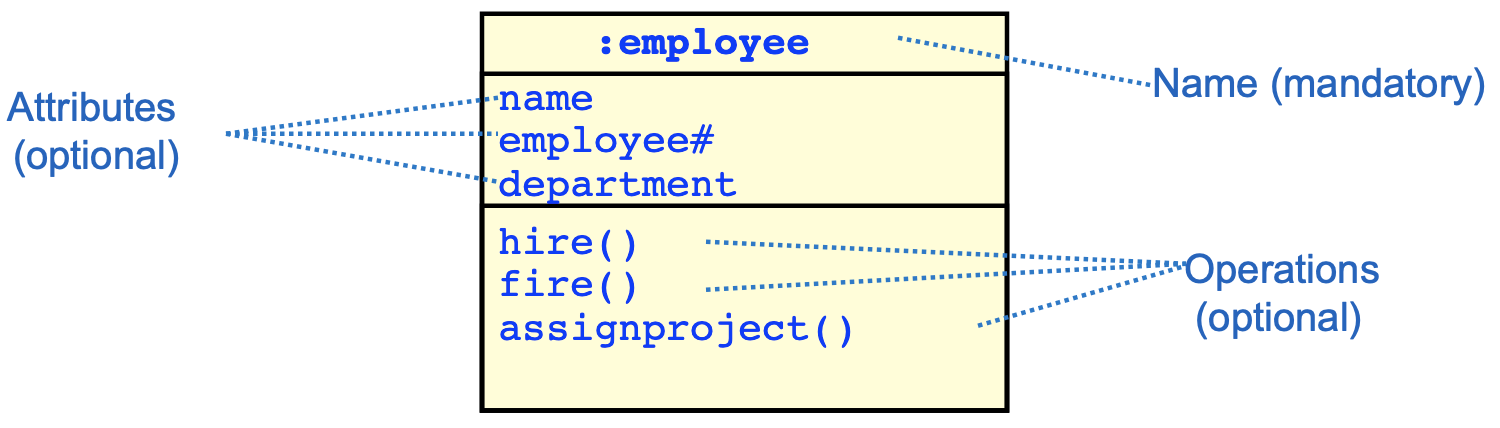
每一个雇员我们都关注他的姓名、员工号、所属的部门,而关于雇员我们相关的服务包括受雇、解雇、项目的任务分配,所以通过这个模型我们就知道,在当前的这个问题上下文中,我们关注的是这个类对象的哪些方面的性质和行为,它将和其它的外部对象发生什么样的交互关系。
什么是对象?
另外一个核心的概念就是对象,对象是类的实例,其表示方法和类、图标差不多:
但对象名的定义是要包括具体的这个实例的名字,而它的属性定义要包括属性的具体取值,两个不同的对象可以有相同的属性取值,就好比现实生活中会碰到相同名字的人,住在相同地址的人一样,这些都是他们属性取值相同,但身份不同。
对象与其他对象在现实世界中有着各种各样的关联关系。例如:Fred_Bloggs:employee 对象与 KillerApp:project 对象相关联,被分配到 KillerApp 项目中。但在定义这些对象的关系时是要在类的层面上去定义的,因为我们要定义可重用的对象之间的关系,而不仅仅是考虑具体的问题。
在对象定义过程中,要注意将对象属性划归到合适的类。例如:不要将经理姓名和员工编号同时定义为project类的属性。属性定义中最重要的一点是封装,即属性应该是这个对象私有的一个信息单元,外部对象要访问这个属性是需要访问该对象对外提供的服务。因此,应该把经理、员工这两者分别定义到经理、员工对象中,然后在project中只用唯一一个ID去引用经理,如此一来才能保证数据封装的完整性。
类属性定义
属性定义是类定义的主要方面之一,在为类选取属性的时候要考虑的是通过这些定义的属性,我们能够描述并区分该类对象,只把系统感兴趣的那些特征放在类的属性定义中,根据图的详细程度每条属性可以包括可见性、名称、类型、多样性、初值和约束。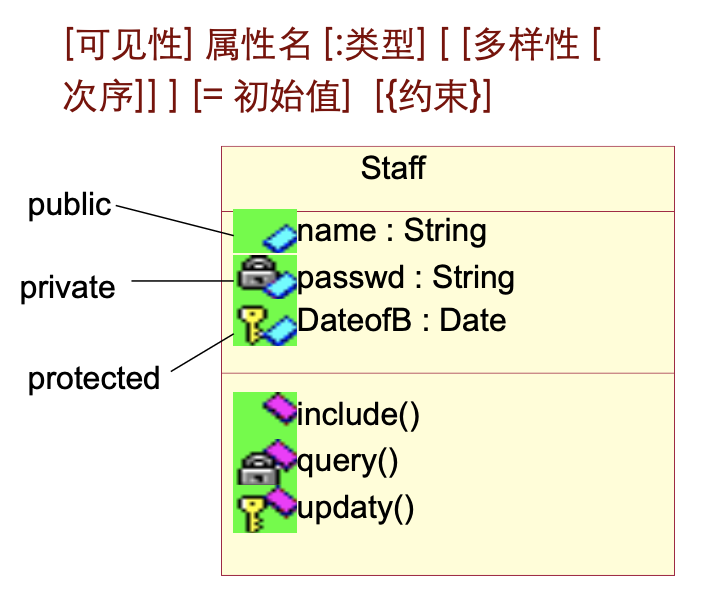
属性的可见性主要分为四类,即
- 公有属性:所有都可以访问的属性,在建模过程中应该尽量避免使用公有属性,因为它破坏了数据封装的原则,而尽量多用私有属性;
- 私有属性:是那些只能自己访问的信息对象;
- 受保护的属性:是指只有它的直接的子类对象可以访问的那些属性;
- 可见性:对同包的对象,同一个Package内的对象可见;
下图是属性声明的例子,公有属性用加号来标志,私有属性用减号来标志,受保护的属性用 # 号来表示,可见性用飘线来表示,在一个属性定义的最后加上0..1标志时表示这个属性有可能取空值:
类关系
在应用系统中的对象并非遗世独立的,对象之间存在着千丝万缕的联系,我们用类关系来建模对象之间的关系。
UML中,关注以下几种类型的关系:
- 关联关系 Association
- 聚合与组合关系 Aggregation and Composition:是关联关系的特例,表达整体部分关联
- 泛化关系 Generalization:即继承关系,是类与类之间的一种层次关系
- 依赖关系 Dependency:彼此使用服务的这样的一种关系
- 实现关系 Realization:指具体类对抽象接口的实现
依赖关系、实现关系在建模中是比较直观的,且运用场景也比较特殊,所以我们主要考虑的是关联关系和泛化关系、以及关联关系的特例。
下面是类图描述类和他们之间关系的实例:
关联关系
关联关系的种类
按照关联关系所连接的类的数量,我们将类之间的关联分为三类:
- 自返关联 reflexive association:又称递归关联(recursive association),它的特殊性在于是一个类与本身发生的关联关系,即同一个类的两个对象间的联系。虽然只有一个被关联的类,但却有两个关联端,每个关联端在这个关系中所扮演的角色是不同的;
- 二元关联 binary association:是我们最常见的类与类之间的关联关系。它表达的是在两个类之间发生的关联;
- N元关联 n-ary association:是在3个或3个以上类之间的关联。在N元关联中它的多样性的定义也是不同的,下面举例说明。
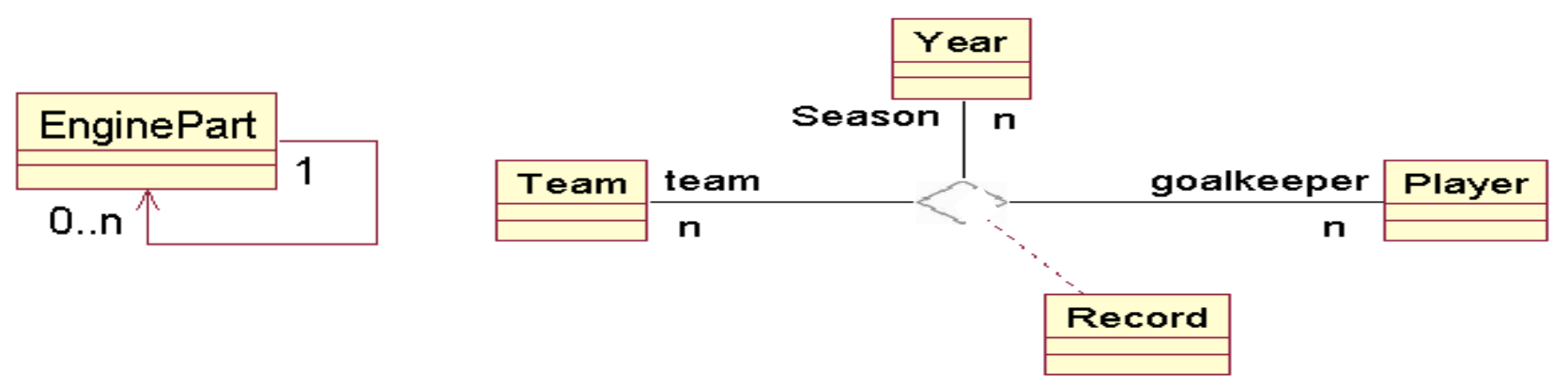
关联关系的“多样性/维度”
在关联关系中,多样性有时候也叫维度,它实际上是在试图约束在关联关系中对象的数量,是一种定义业务逻辑的方法。

关联关系图例
N元关联中,类的多样性定义的意义是在其他N-1个实例的值确定的情况下,关联实例它允许的元素个数。
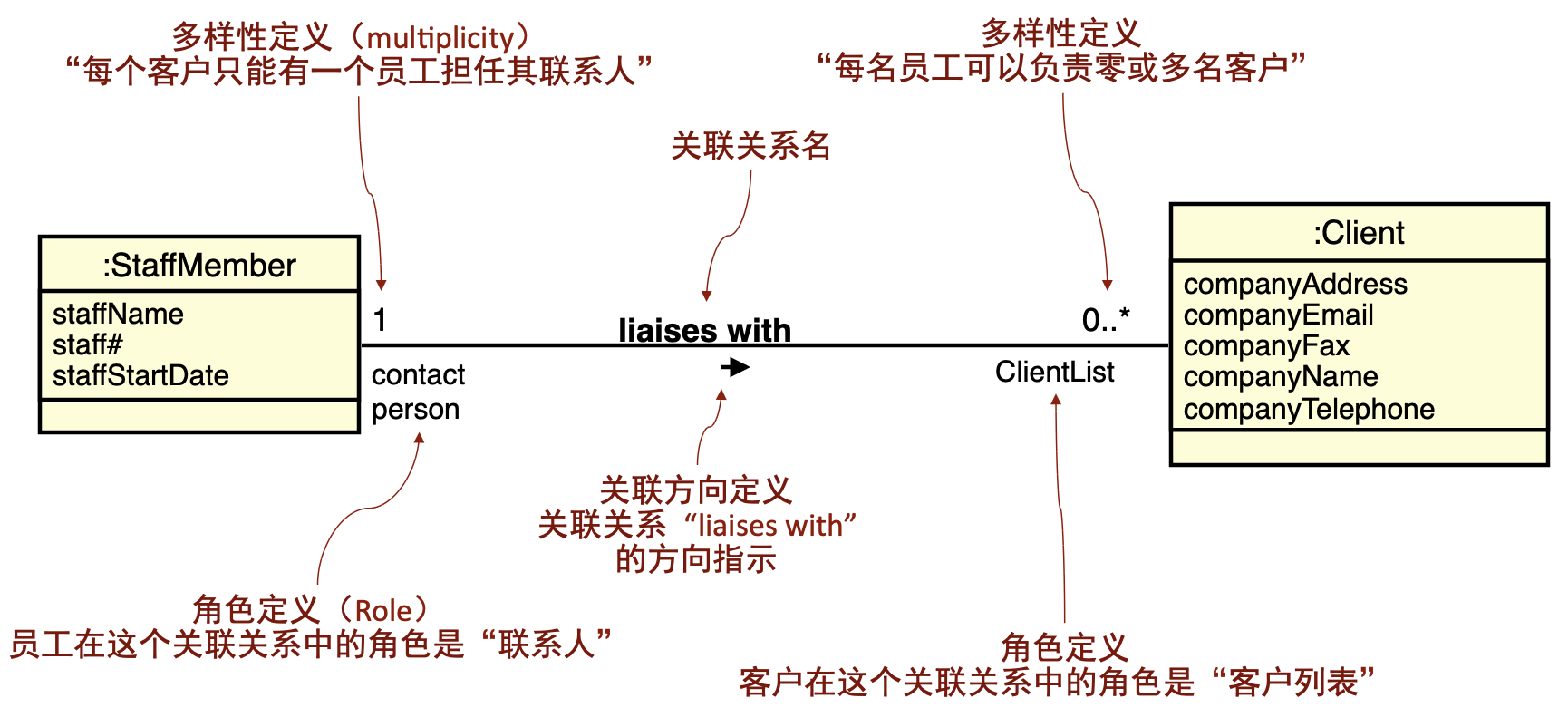
关联是模型元素间的一种语义关系,是对具有共同结构特征、行为特征、关系和语义的链的描述,在类图中关联用一条把类连接在一起的实线来表示。
关联至少有两个关联端,每个关联端连接到一个类,关联可以有方向,有方向的关联类称为单向关联,没方向的称为双问关联,通过给关联加上关联名,可以描述关联的作用是什么,关联的名字通常是用动词来表示的。关联时命名原则是要看这个命名是否有助于我们理解模型。
除了以上基本元素外,还有关联多样性的定义,以及类在这个关联关系中所处的角色定义。需要注意的是通过模型驱动的,从模型到源代码转换的过程中,对源代码有影响的部分是角色的定义和关联的方向,也就是说,当一个单向的关联并且有角色定义时,我们会在生成的代码中声明相应类的属性。
关联类
关联本身也是有一些性质,我们通过关联类来进一步描述关联的属性、操作以及其他的信息。关联类通过一条虚线和关联的实现相联系,保存关联关系本身的这些信息。
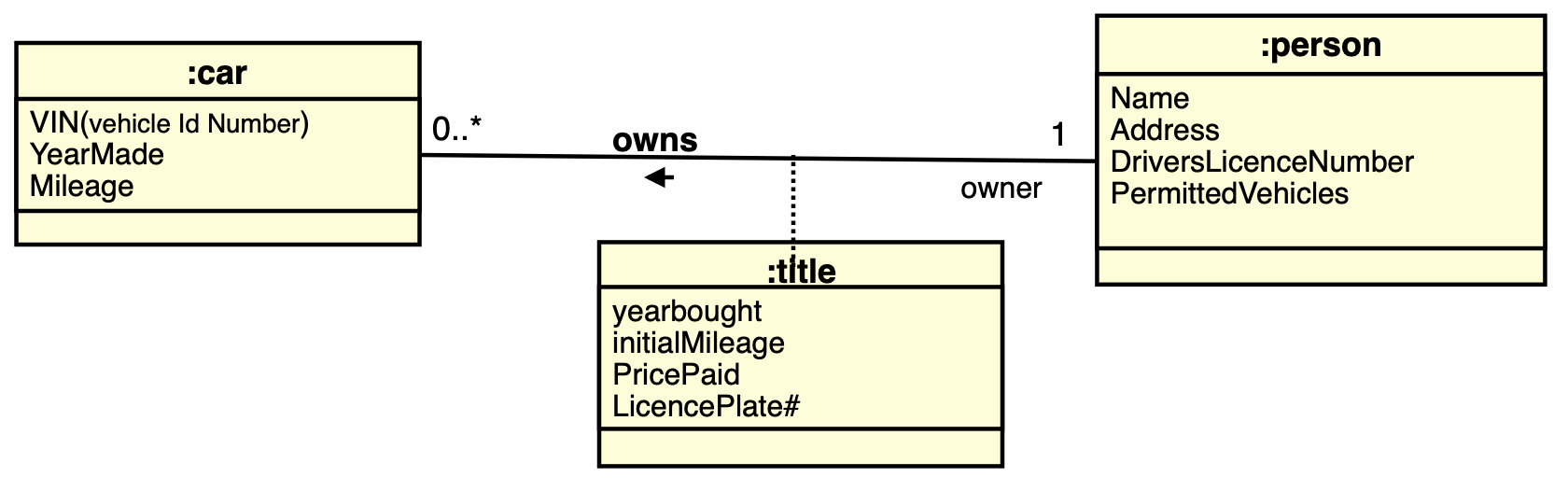
比如,如图,”title〞 类的对象中存储的是车主和车辆之间所属关系有关的信息,包括哪一年购买、购买时的里程数、当时付的钱、新注册的号牌。
当我们采用工具基于模型生成代码的时候,关联类也生成对应的源代码:
限定关联 Qualifier
在关联端紧靠源类图标处可以有限定符(Qualifier)。带有限定符的关联称为限定关联(Qualified Association)。
在进行关联建模的时候,一个良构的关联的定义是一对多的关联多样性,为了确保把多样性从N降为一,我们就引入了一个特殊的建模元素叫做限定符,通过引入限定符,我们可以把原本是N对N的这样的关联关系降为一对N,这样的话,如果做查询操作返回的对象会是一个而不是一个对象集合。通过多样性我们可以判断对象设计的好坏,如果一个应用系统需要根据关键字对一个数据集做查询操作的话,我们会往往会用到限定关联来降解多样性。
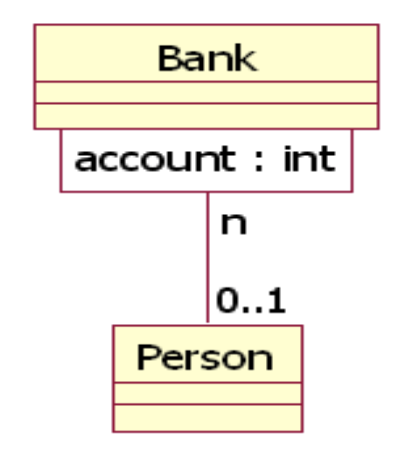

图上的就是一个限定符的例子,在没有加入限定符之前,银行帐户和用户之间是一个多对多的关系,但我们通过加入了帐户这个限定符的时候,每一个帐户它一定是对应零或者一个用户的。限定符是关联的一个属性,它的作用就是给关联一端的一个对象加上一个限定值,确保另一端的对象是一个对象。限定符并不是一个自由变量,每当一个新的关联链被创建的时候,它的限定的变量值都是已经预先定义好的,所以不需要给限定符指定初始值。
聚合 (Aggregation)与组合 (Composition) 关系
表达整体与部分关系的是聚合与组合关系,是关联关系的一个特例。聚合关系用于表达一个整体对象与其成员对象之间的关系,其中代表部分事务的对象是可以属于多个聚合对象的,即可以在多个整体对象间共享,还可以随时改变其所从属的那个整体对象,部分对象与整体对象的生存周期无关,一旦删除了它的一个聚合对象,该部分对象任然能够独立存在。
组合关系是聚合关系的一个特例,用于表达一个整体对象与其组成部分之间的关系。当整体对象不存在时,部分类的对象也不存在,反之亦然。整体类对象撤销之前要负责把它全部的部分类对象撤销,也就是说,代表整体事物的组合对象要负责创建和删除代表部分对象的那个成员,代表部分对象的这个事物只能从属一个整体对象,一旦删除了整体,部分也随之消亡。
确定了类的行为和属性后,应该是比较容易区分聚合与组合关系的。比如一个窗口和它附属的按钮,应该定义为组合关系,因为二者具有相同的生命周期,一个的破坏会导致另一个的消亡。反之,一个由同类元素组成的集合和其个体元素间应该是聚合关系,因为元素的创建、消亡并不完全同步。
生成代码时,需要为组合关系的类考虑同步问题,而聚合关系则不需要。
聚合关系,其实例之间存在传递关系,是一个偏序关系。聚合关系与组合关系的区别在于聚合关系的实例是不能形成环的。运用聚合和组合能简化对象的定义,更好的支持软件重用。
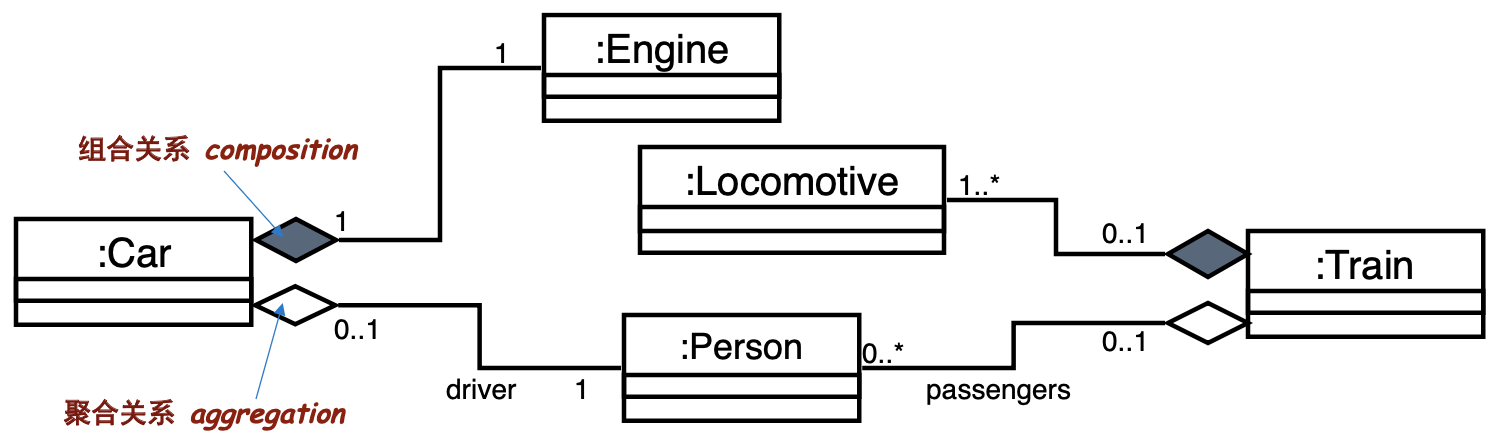
举例,上图中将汽车和它的引擎定义为组合关系,因为这两者生存周期有很强的绑定,而车与它的乘客之间则是聚合关系。
继承/泛化(Inheritance/Generalization)
在面向对象的设计中,我们对继承关系寄予厚望,希望通过子类继承父类的属性、关联和操作来实现重用,支持抽象,而子类在继承的过程中,当发现有特殊的情况要处理的时候,也可以覆盖继承得来的那些属性和操作。
比如在下图中,行政员工和专业设计人员他的奖金的计算方式可以是不同的,在员工类中可以把相应的无法具体化的这部分内容定义为抽象的,甚至可以把整个类定义为抽象类,那么我们就不再会为它直接创建实例对象,这种情况下现有的子类将覆盖这个抽象类的所有对象,形成一个全集、完全的覆盖。
继承/泛化关系的定义
继承关系的定义主要通过学习当前领域的分类学知识,以及常识上事物的分类方法来获得。继承/泛化关系建模的意义在于系统环境发生变化时便于添加新的子类,来处理新发生的特殊情况。
继承/泛化关系建模有两种方式:
- 自顶向下:将某个类分割为属性和操作不同的子类,或者发现关联关系定义的是分类关系“kind of”
- 自底向上:为现有的多个具有公共属性及方法的类,定义一个抽象的父类
这两种方式在现实中都会发生,可根据实际情况灵活掌握。关键在于类和属性的操作是否有特性或者共性。
自顶向下定义继承关系
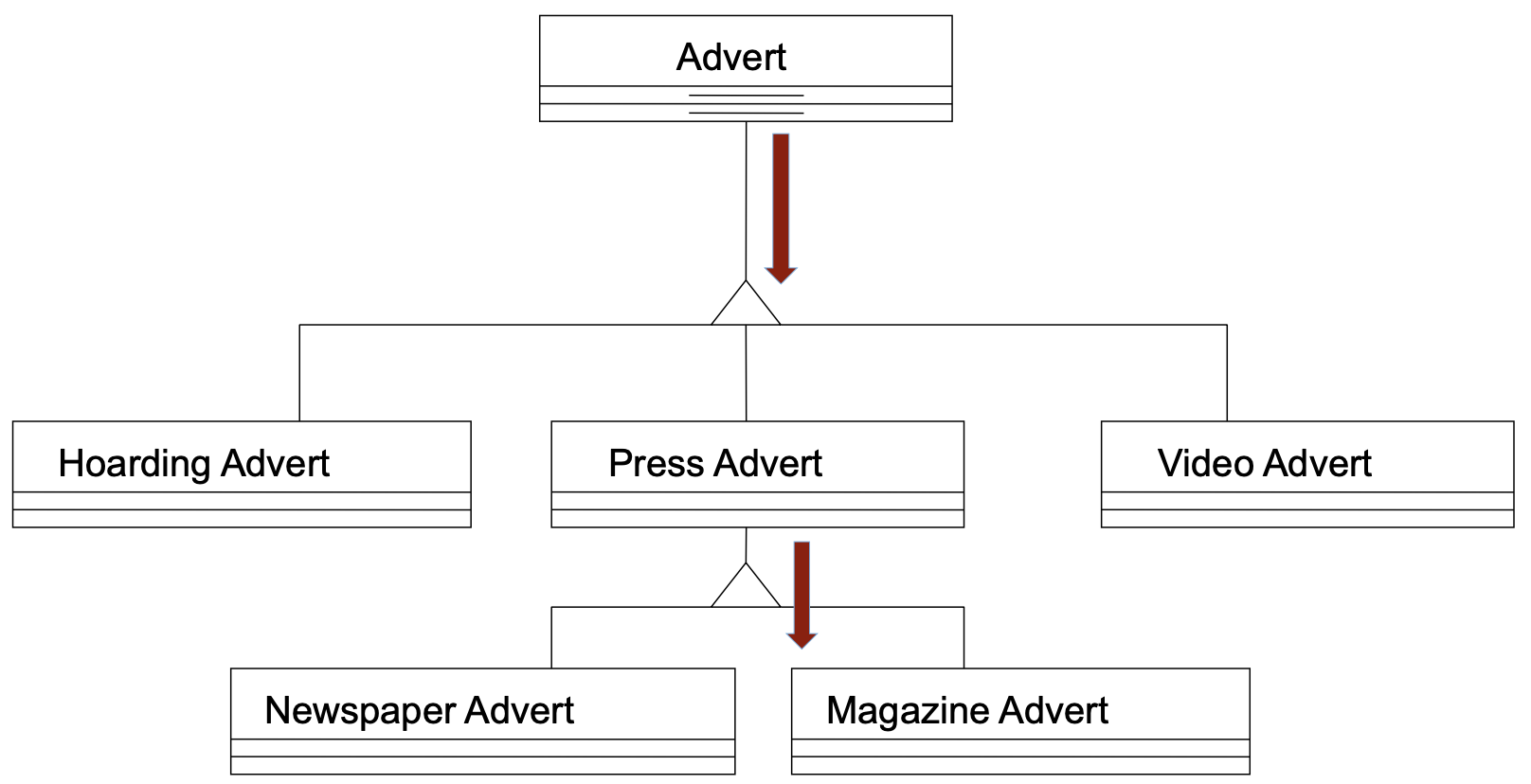
上图是自顶向下定义继承关系的例子,这里处理的是一个广告公司的系统, 它的主营业务是为媒体制作各种类型的广告,这些广告天然的具有一个分类体系,包括报纸的广告、杂志的广告、街头的广告、广告短片等等。按这种天然的分类体系,我们建立了一个分类框架,如图所示,获得了一个自顶向下的继承的层级关系。
自底向上定义继承关系

如图,在我们建模的领域里,书籍和唱片它们都有一些属性和操作的定义,而对比二者的属性和操作我们发现了公共的属性以及公共的操作,那么对它进行抽象就得到了一个公共的父类: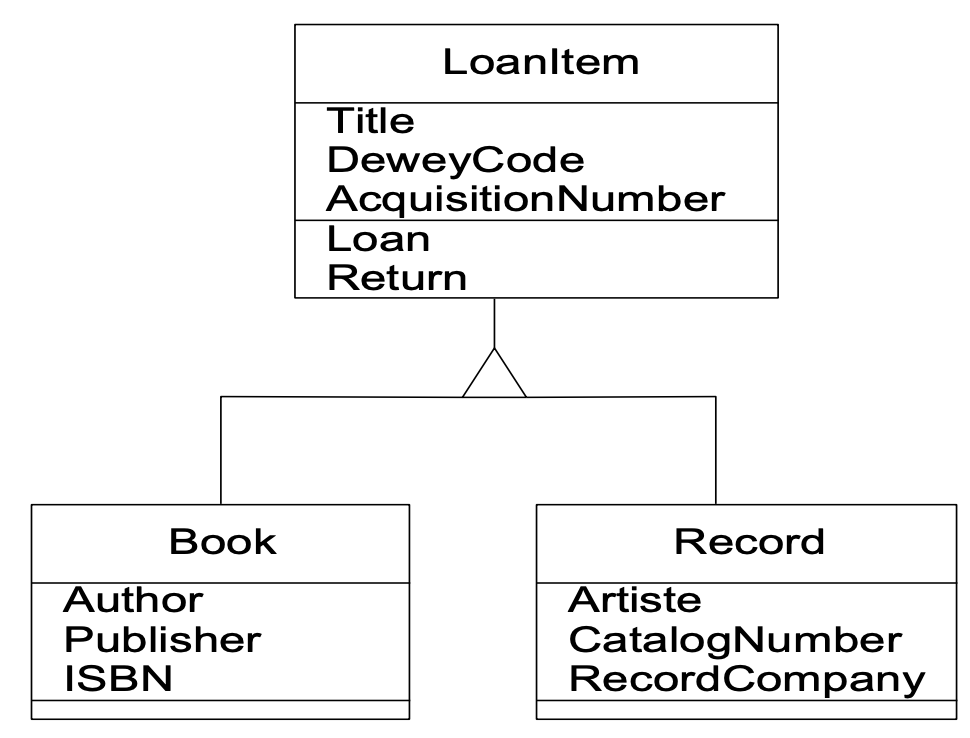
就是可以出借的单元,将这二者的名字、杜威码和获取编号以及外借和归还的操作进行抽象,定义它们的公共父类,再把二者不同的属性放在各自的子类定义当中,完成子继承关系的重组。
类图建模图例
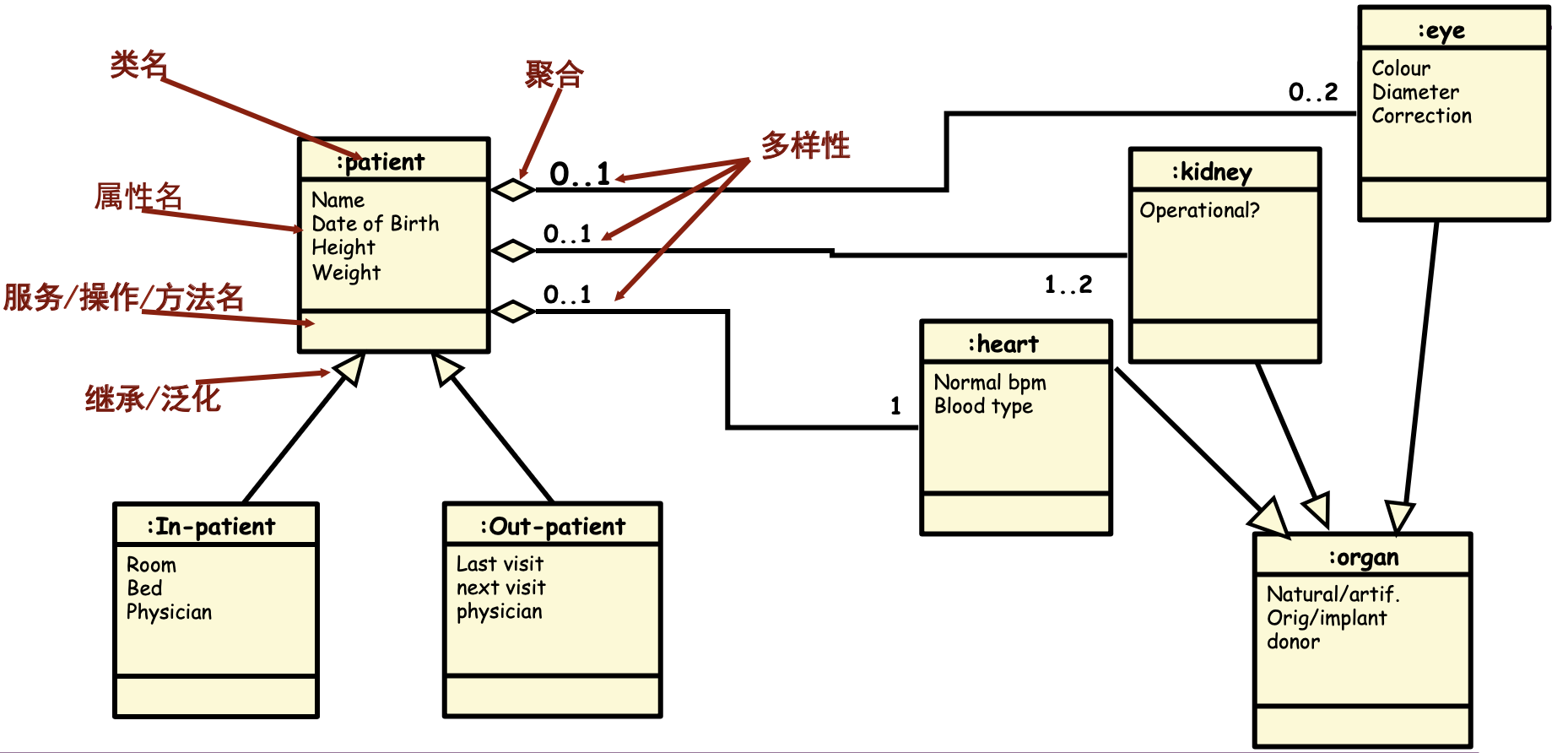
总结一下,在类图建模的过程中,要识别类、定义类的名字、定义属性的名字、定义这个类的操作,建立类和类之间的继承关系、组合关系、聚合关系,并定义这些关联关系的多样性、方向和名字,这样我们就完成了一个基本的类图建模的过程。
类图的抽象层次
在软件开发的不同阶段,都会使用到类图,而类图它的抽象层次可分为三个层次:
- 概念类:早期的分析阶段的概念类
- 设计说明类:设计阶段的说明类
- 实现类:实现阶段的实现类

这三种层次的类图,它内部包含的信息的丰富程度,以及变量定义的准确程度是不一样的。概念类更多的是把类实体定义出来,设计说明阶段要把类的属性及其相应的行为、代表它行为的这些操作定义出来,在实现类中类图和我们的代码实现基本对应,此时类型已经定义出来了,参数的具体的类型也要和程序设计语言相对应。
总结建立类图的步骤
建立类图的步骤包括:
- 研究分析问题领域,确定系统的需求。
- 发现对象与类,明确它们的含义和责任,确定类的属性和操作。
- 发现类之间的关系。把类之间的关系用关联、泛化、聚集、组合、依赖等关系表达出来。
- 设计类与关系。调整和细化已得到的类和类之间的关系,解决诸如命名冲突、功能重复等问题。
- 绘制类图并编制相应的说明。
类图建模风格
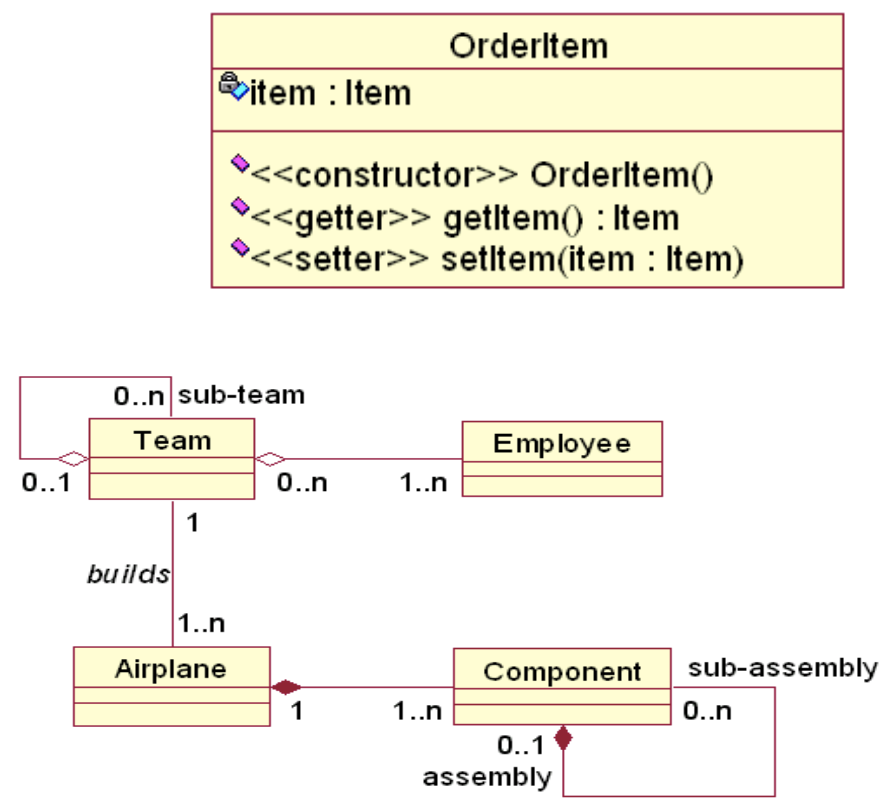
类图建模风格的建议:
- 属性名和类型应该一致。
- 不要对有关联类的关联命名,因为关联类本身的名字就是用于描述该关联的。
- 静态操作/属性要在实例操作/属性之前列出。
- 以可见性降低的次序列出操作/属性。
- 避免已被语言的命名规范所隐含的版型。
- 总是指明多样性。
- 不要对每个依赖关系都建模。
- 将子类放在超类的下方。
- 小心基于数据的继承。
- 按惯例是把整体画在部分的左边。

若有收获,就点个赞吧
1 人点赞
