5.1 语音合成 Speech Synthesis (TTS)
点击查看【bilibili】
语音合成 TTS:即输入文字,输出语音

5.2 有 End-to-End 硬 train 一发前的 TTS
在有 End-to-End 硬 train 一发之前,语音合成是怎么做的?
5.2.1 Deep Voice
Deep Voice 是百度在 17 年提出的,是最接近 end-to-end 硬 train 一发的方法,但其第一版还不是 end-to-end 硬 train 的,里面的每个模型是分开训练的。但到了第三版就变成 end-to-end 了
Deep Voice 是将 4 个基于深度学习的 model 串起来:
- Grapheme-to-phoneme model:输入:一串文字;输出:一串音素
- Duration Prediction model:输入:一串音素;输出:每个音素的发音时长
- Fundamental Frequency Prediction model:输入:一串音素;输出:每个音素对应的声带振动频率(音高)
- Audio Synthesis model:输入:一串音素、每个音素的发音时长、每个音素的声带振动频率;输出:一段合成的语音

5.3 Tacotron:End-to-End 的 TTS
硬 train 一发的时代
Tacotron 之前就已经有一些 end-to-end 的 TTS 的尝试,对比如下表所示:
| End-to-End TTS model | 描述 |
|---|---|
| First Step Towards End-to-end Parametric TTS | - 输入:phoneme 音素,相比 character 更容易一些,因为更接近声音 - 输出:acoustic features,要丢到名为 STRAIGHT 的 vocoder 中才能合成出处语音讯号 |
| Char2wav | - 输入:character 字母 - 输出:acoustic features,要丢到名为 SampleRNN 的 vocoder 中才能合成出语音讯号 |
| Tacotron | - 输入:character 字母,即文本 - 输出:(linear) spectrogram,与最终的 waveform 只差了一个 phase 的资讯,不需要非常强的 decoder,只需要做一个线性转换 |
可见,Tacotron 的输入、输出是最 end-to-end 的 |
Tacotron:是一个真正 end-to-end 的语音合成系统
- Tacotron 实际上就是 Seq2Seq model + Attention
- Tacotron 包含 5 部分:
- Encoder:扮演的角色类似于 Deep Voice 中的 Grapheme-to-phoneme model,输入文字,输出向量序列(将每个 character 变成一个向量)
- Attention:扮演的角色类似于 Deep Voice 中的 Duration Prediction model,预测每个 character 对应的 embedding 的发音时长
- Decoder:扮演的角色类似于 Deep Voice 中的 Audio Synthesis,输出 Mel-spectrogram
- Post-processing:输入 Mel-spectrogram,让网络看过整个输入,再重新输出修正的 Mel/Linear-spectrogram
- Vocoder:输入 Mel/Linear-spectrogram(一种 acoustic features),输出合成的语音讯号

5.3.1 Encoder
Tacotron 的 Encoder 扮演的角色类似于 Deep Voice 中的 Grapheme-to-phoneme model,输入一串文字(characters),输出向量序列(将每个 character 变成一个 embedding 向量)
- Tacotron v1 版本的 Encoder 中用了 CBHG,但其实不是必要的

- Tacotron v1 版本的 Encoder 中就去掉了 CBHG,改用卷积层

5.3.2 Attention
Tacotron 中的 Attention 扮演的角色类似于 Deep Voice 中的 Duration Prediction model,输入是 encoder 的输出,即一串向量序列(是每个 character 对应的 embedding),输出是每个 character 对应的 embedding 在 decoder 那边会产生的声音讯号的时长
- 语音合成和语音识别做 attention 有一个共同的地方:文字和声音有共同的顺序,是单调一致的,也就是说画成图应该类似一条从左上到右下的斜线
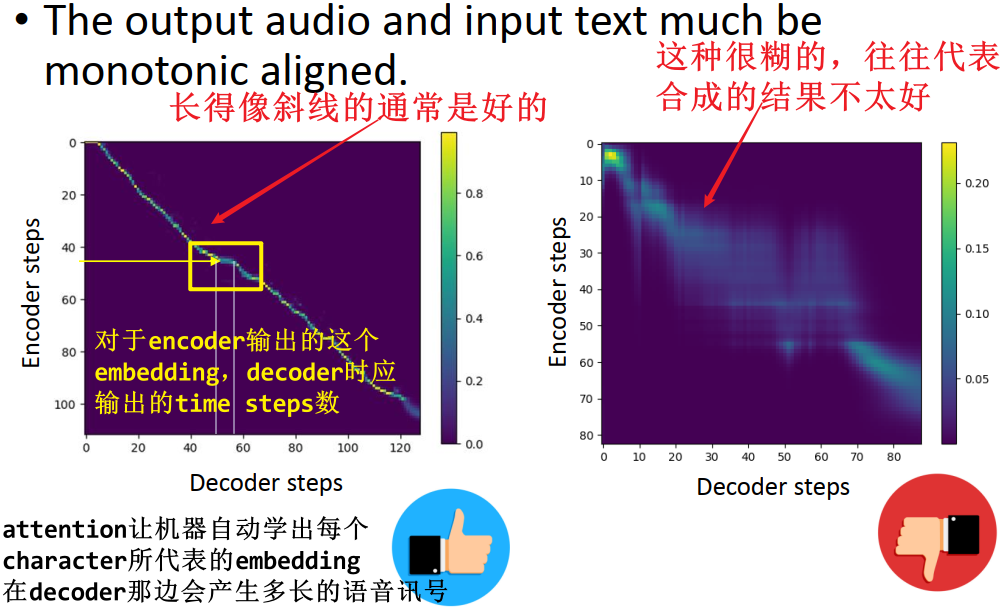
5.3.3 Decoder
Tacotron 中的 Decoder 扮演的角色类似于 Deep Voice 中的 Audio Synthesis,输出 Mel-spectrogram
- 与一般 Decoder 不同的是,这里的 Decoder 一次会产生多个(r 个) vector
- 有利于减少运算量,使得训练更容易
- 0但在 v2 版本中,r = 1
- Decoder 一次产生的多个 vector,可以将其中最后一个 vector 当作下一时刻的输入,也可以将 r 个 vectors 串起来当作下一时刻的输入,可以有不同的做法
- 使用 teacher forcing,即由于上一时刻的输出不能保证其正确性,因此在训练的时候,不把上一时刻的输出作为输入,而是直接将 ground truth 作为输入
- 问题:测试时并没有 ground truth,只能使用上一时刻的输出作为输入,会造成训练和测试的不一致,可能导致对训练数据过拟合
- 解决办法:dropout
- Pre-net 中包含 dropout,就像计划采样(schedule sampling),就可以在训练时模拟测试时 RNN 有可能出错的情况
- Tip:在测试(inference)时,也需要加上 dropout,增加一些随机性,效果才会好。这与以往认为的只在训练时使用 dropout、测试时要去掉的认知是相反的
- 什么时候结束?
- 语音识别时,产生一个“
EOS” token 就代表识别结束,但在语音合成中产生的并不是 token,而是连续的向量 - 因此,语音合成需要额外的 binary classifier 模型来判断要不要结束
- 语音识别时,产生一个“

5.3.4 Post processing
Tacotron 还需要进行后处理,将 Decoder 输出的向量序列(Mel-spectrogram)当作输入,输出修正过的向量序列(Mel/Linear-spectrogram)
- 后处理网络 v1 版本时使用的是 CBHG,到了 v2 版本就变成一堆卷积了
- 需要进行后处理的原因:Decoder 是基于 RNN 的,那么它输出的 acoustic features 向量序列是按照顺序一个个输出的,每次都只能看到前面已产生的向量再产生后面的向量。也许在某个时刻看到后面的输出,想回头修改前面的向量,但并没有机会。因此,加上后处理的网络,相当于给了一个修正的机会,后处理网络就相当于是把整个输入都看过再产生新的输出
因此,Tacotron 在训练时有 2 个训练目标,也就有 2 个 loss:
- loss 1:希望基于 RNN 的 decoder 的输出与真实的 Mel-spectrogram(ground truth)越像越好
- loss 2:希望经过后处理网络修正后的输出与真实的 Mel/Linear-spectrogram(ground truth)越像越好
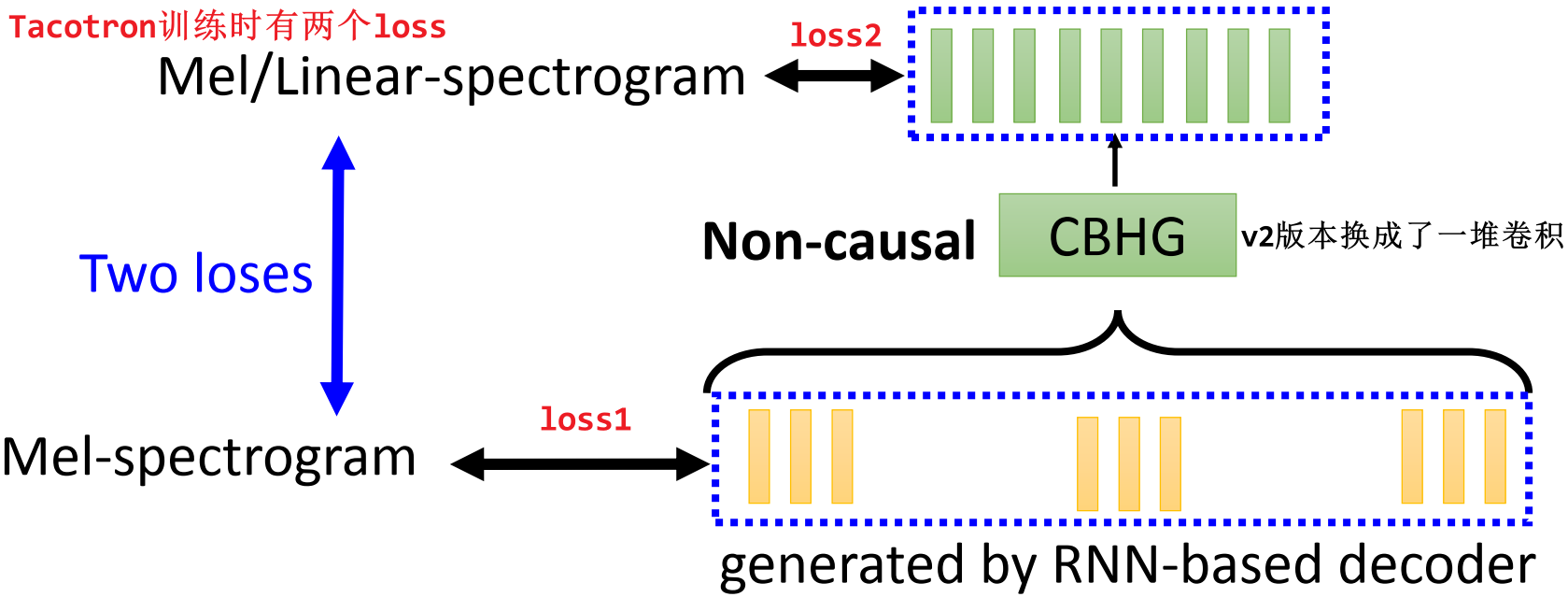
5.3.5 Vocoder
Tacotron 的 Vocoder 输入后处理修正后得到的 Mel/Linear-spectrogram(一种 acoustic features),输出合成的语音讯号
- Vocoder 是独立训练的,不和 Tacotron 的其它部分一起训练
- Tacotron 第二代更换了 vocoder 后,效果变好了

5.4 Tacotron(硬 train 一发)的后时代做的事
实际上Tacotron 并没有解决所有的问题,那么硬 train 一发的后时代做的事情是什么?
5.4.1 发音错误 mispronunciation
Tacotron 会遇到的第一个问题就是:有时候发音会有错误,这是 Tacotron 合成的语音不如 ground truth 的主要原因
- 造成有时发音错误的原因:语音合成若只要合成某个人的声音,那么只需要这个人十多个小时的声音就足够了,但是词汇量并不够。即使是最大的语音数据集中也有词汇量不够的问题,那么要合成训练时没出现过的词汇就可能出现发音错误的问题
- 一个解决办法:不把 character 当作输入,而是使用一个字典将 character(word)转换成音素 phoneme,再使用音素 phoneme 作为 Tacotron 的输入
- 音素 phoneme 和声音是有直接对应关系的,所以不会发生念错词汇的情形
- 问题:oov(out of vocabulary)问题,即肯定有新的词汇是词典里没有的
- 解决:使用 character 和 phoneme 作为混合输入,训练的时候,随机挑选某些词汇(即使词典里有也)不去看词典,直接用 character 作为输入,剩余的用 phoneme 作为输入
- 优点:如果机器对某个词的发音不对,可以将该词及其对应的正确发音加入词典,就可以修正机器的发音

5.4.2 给 Encoder 输入更多信息
- 可以将文法资讯加入到 Tacotron 的输入中
- 就可以知道哪些词汇连起来算一个片语,需要连起来读,相当于告诉机器怎么停顿

- 也可以将 BERT 输出的 embedding 当作 Tacotron 的输入
- BERT 可以把每个词汇抽取它的 representation,有非常丰富的语义资讯
5.4.3 Attention 的改进
5.3.4.1 Guided Attention
在 5.3.2 Attention 一节中提到,我们期待 Encoder 和 Decoder 之间产生的 attention 的关系最好看起来像一条对角线,那么何不把这个期待直接加入到训练过程中,告诉模型希望模型在做 attention 的时候最好看起来像是对角线?
具体做法:训练时对注意力矩阵非对角线的部分加上惩罚
- 原来 Tacotron 训练只是希望输出的声音讯号跟 ground truth 的声音讯号越像越好,Guided Attention 则在原本 Tacotron 训练的 loss 的 terms 上再多加一个 term:对 attention 加了一个 regularization,划了一个禁止进入进入的区域(下图所示的红色区域),如果在禁止进入的区域有 attention 的 weight,loss 就比较大;如果在禁止进入的区域没有 attention 的 weight,loss 值就较小。那么在训练时为了让 loss 越小越好,就会倾向于让 attention 只集中在对角线附近的区域

除了 guided attention,还有一些方法会对 attention 做出更强的限制
- Monotonic Attention:要求 attention 一定要由左向右
- Location-aware attention:Tacotron 的第二版中使用的
- 百度的第三代 Deep Voice 直接在 inference 时把 attention 矩阵禁止进入的区域的 weight 值设为 0,强制 attention 只能在对角线附近区域进行
- More… …

5.4.4 Fast Speech / DurIAN
Fast Speech 用的不是 Seq2Seq model:
- Encoder:输入一串 characters,输出一串 embedding 向量
- Duration:代替了 Attention,来预测每个 character 的发音时长,即对每个character 对应的 embedding 向量输出一个代表重复次数(时长)的值
- Decoder:输入是有重复的 embedding 向量序列,每个 embedding 重复几次是 Duration 的输出决定的,而且重复后的总长度和 Decoder 输出的 acoustic features 序列长度相同。输出 Mel-spectrogram
- 输入输出等长,因此就不要用到 Seq2Seq model
问题:Duratrion 模型产生的是数值,没法微分,那么就没办法 end-to-end 硬 train
解决办法:测试时才使用 Duration 生成重复次数。而在训练时直接使用 ground truth 的重复次数对每个 embedding 进行重复;并且 ground truth 也被用于更新 Durartion 网络的参数。这样就还是 End-to-End 训练
- 如何得到 ground truth(即得到 character 和 acoustic feature sequence 之间的 alignment 关系):先训练一个 Tacotron,根据 Tacotron 的 attention 想办法计算每个 character embedding 分别需要重复几次,才能使得总长和最终的输出一样长

5.4.5 双重学习 Dual Learning:ASR & TTS
如下图所示,语音识别 ASR》) 和 语音合成 TTS 正好是相反的,两者都可以用 Seq2Seq model + Attention 来解
Dual Learning 双重学习:ASR 和 TTS 组成一个循环,一起训练,来互相增进彼此的能力
- Case 1:收集到一堆没有文字的标注的语音讯号,输入给 ASR,输出文字,再输入给 TTS,得到语音讯号,希望 TTS 输出的语音讯号和最初输入给 ASR 的语音讯号越像越好。这样 ASR、TTS 就变成了 auto encoder,ASR 是 encoder,TTS 是 decoder
- Case 1:收集到一堆没有对应语音的文字,输入给 TTS,输出语音,再输入给 ASR,得到文字,希望 ASR 输出的文字和最初输入给 TTS 的文字越像越好。这样 TTS、ASR 就变成了 auto encoder,TTS 是 encoder,ASR 是 decoder

5.5 可控制的 TTS
怎么控制 TTS 合成出我们要的声音?
一段语音讯号中,包含几个不同的方面:
- 说什么:由输入文本控制
- 谁在说:希望语音系统合成的声音像是某个特定的人的声音(voice cloning)
- 但是很难找到目标语者数个小时的高质量的声音来微调/训练你的 Tacotron 等语音合成系统
- 怎么说:希望合成的语音抑扬顿挫,即有一定的语调、重音、韵律等
可控制的 TTS 模型:
- 类似语者转换》),语者转换是输入一段语音讯号提供内容信息,输入另一段语音讯号提供语者特征信息
- 可控制的 TTS 模型:输入一串文本来提供内容信息(即说什么),输入一段参考语音讯号来告诉机器谁在说、怎么说

5.5.1 训练
问题:训练时,参考语音同时就是 ground truth,这会导致 copy 问题
- 因为我们只希望参考语音提供发音相关的特征(即怎么说、谁在说),而内容信息应该由输入的文本控制
- 如果参考语音和 ground truth 是同一条,那么就会导致 copy 的问题,即模型在训练时,会进行错误的学习,使得输出的语音去拷贝参考语音(本来的训练目标是缩小输出与 ground truth 语音的 loss,那么现在就等同于缩小输出与参考语音的 loss),输出一段和参考语音一模一样的语音,而完全忽略了文字内容资讯
- 因此,要阻断 copy,使得对参考语音只抽语者资讯(即怎么说、谁在说),而无视其内容资讯,内容资讯由输入的文字控制

解决办法:
5.5.1.1 Speaker Embedding
使用一个预训练好的特征提取网络(参数固定,不跟 TTS 模型一起训练)来提取参考语音中只和语者风格相关的资讯,得到 speaker embedding,再用 speaker embedding 作为 TTS 模型的一个输入
- 这里 ground truth 依然就是参考语音

5.5.1.2 GST-Tacotron
GST-Tacotron 是 Tacotron 的进阶版,GST = Global Style Tokens
- GST-Tacotron 在 Tacotron 的基础上增加了一个输入,即参考语音,实现可控制的 TTS
- 参考语音经过特征提取网络(Feature Extractor),仅输出一个向量,用这个向量复制出跟 encoder 的输出一样多的向量,两者拼接或者相加,来做 attention
- 特征提取网络(Feature Extractor)的架构做了一个设计,避免让其输出包含参考语音的内容资讯

Feature Extractor 的设计:
- Feature Extractor 中有一个 Encoder,但只能控制产生 attention weight,对 token vector 做线性变换,这样就很难把 content 资讯抽出来,也就尽可能让其输出只包含了语者风格相关的资讯
- Style Tokens:token vector 是另外训练得到的
- 用单一语者的数据进行训练得到,避免包含语者资讯
- 每一种 token 代表一种说话的风格,eg. 某个 token 对应频率高、低,某个 token 对应说话速度… …
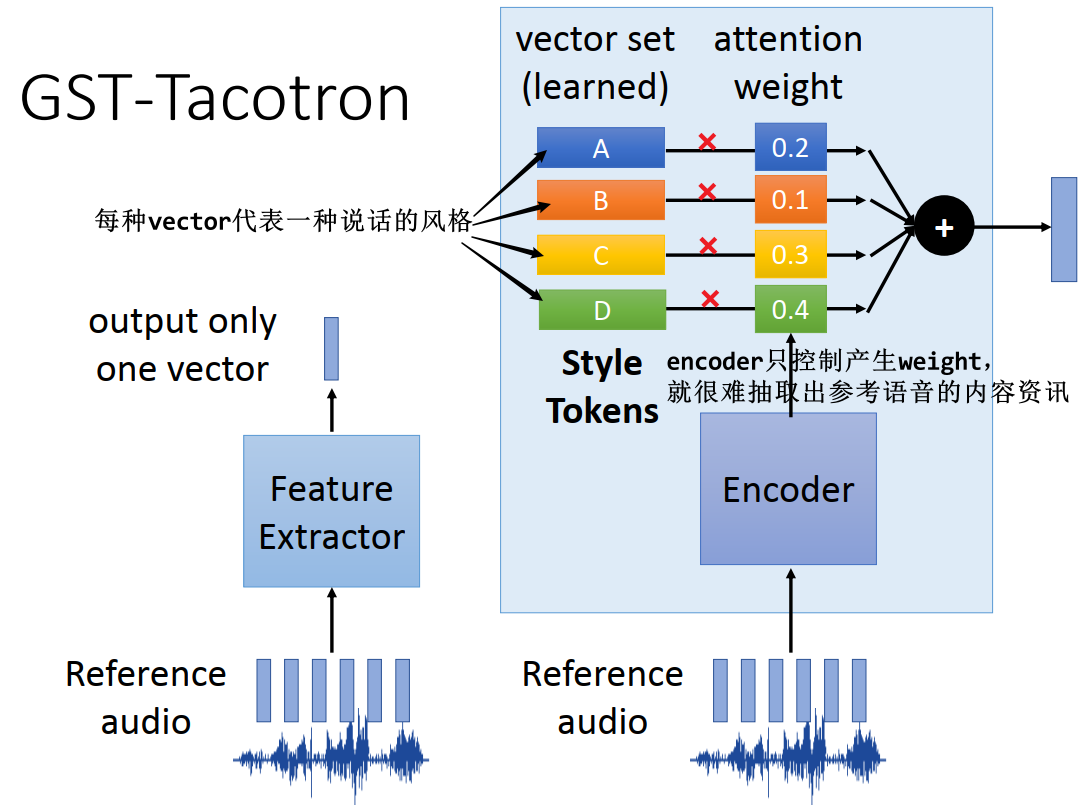
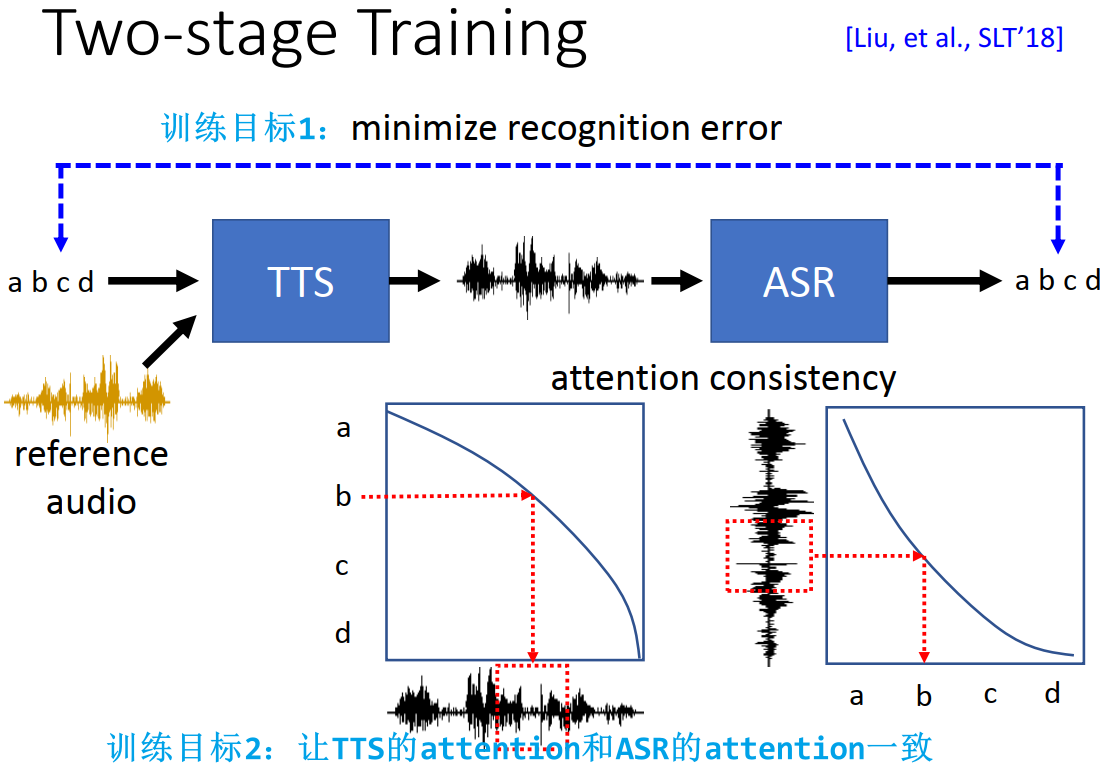
5.5.1.3 2nd Stage training
可以参考语音转换中的 2nd Stage Training
2nd Stage training 在训练时刻意让 referce audio 和 ground truth 的内容不同,就避免了 copy 的问题
新的问题:那如何得到 ground truth?
- 解决办法:引入 GAN 的思想
- 将 TTS 合成的语音再输入到 ASR 中,输出文本,让 ASR 输出的文本和 TTS 输入的文本越像越好
- 两个训练目标:
- 训练目标 1:让 ASR 输出的文本和 TTS 输入的文本越像越好
- 训练目标 2:让 TTS 的 attention 和 ASR 的 attention 一致

若有收获,就点个赞吧
0 人点赞
