视频:Transformer 李宏毅 - YouTube
参考博文:
Transformer(变形金刚):带有 self-attention 的 seq2seq 模型
- 应用:BERT
- 作用:任何原来可以使用 seq2seq 模型的东西,都可以换成 Transformer
- 任何原来使用 RNN 做的东西,都可以用自注意力机制代替

1、RNN
- 输入:向量序列
- 输出:向量序列
- 优点:可以考虑长时间的输入内容(当然不能过长,否则有长程依赖问题)
- 若是单向 RNN:在输出
 时,已把输入
时,已把输入  都看过
都看过 - 若是双向 RNN:在输出每个
 时,都已看过整个输入向量序列
时,都已看过整个输入向量序列
- 若是单向 RNN:在输出
- 缺点:不容易并行化

2、CNN
第 5 章 卷积神经网络
可以考虑使用 CNN 代替 RNN 来实现 seq2seq 模型
- 对于一个 filter:将多个输入向量当作其输入,将这个 filter 扫过整个输入序列,得到输出

- 可以使用多个 filters,产生不同的输出序列,叠加起来就得到输出向量序列
- 即 CNN 可以代替 RNN 实现 seq2seq 模型,使得输入是一个向量序列,输出是另一个向量序列
- 全部的 filters 可以同时计算,即 CNN 可以并行化
- 只使用一层的 CNN 只能考虑非常有限的输入内容,不能像 RNN 一样考虑整个句子
- 但叠加多层的 CNN,高层的卷积层就相当于可以考虑长时间的输入内容

CNN 代替 RNN 实现 seq2seq 的优缺点:
- 优点:全部的 filters 可以同时计算,即 CNN 可以并行化
- 缺点:如果要第一层的 CNN 就考虑长时间的输入资讯,是做不到的
3、Self-Attention
自注意力模型 - 邱锡鹏《神经网络与深度学习》
Attention Is All You Need 论文
Transformer 就是使用 Self Attention 代替 RNN 的 seq2seq 模型
Self-Attention:任何可以使用 RNN 实现的东西都可以用 Self-Attention 代替
- 输入是一个序列,输出是另一个序列,和 RNN 一样
- 每个输出
 都可以基于整个输入序列,即和双向 RNN 具有相同的能力
都可以基于整个输入序列,即和双向 RNN 具有相同的能力 - 所有输出
 可以并行运算
可以并行运算

3.1 自注意力的计算过程
- 对于输入向量序列(矩阵)
 ,先乘上一个权重矩阵 W (即做 word embedding,只有最底层的编码器需要这一步)得到向量序列
,先乘上一个权重矩阵 W (即做 word embedding,只有最底层的编码器需要这一步)得到向量序列 
- 将向量序列
 %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-49%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-3D%22%20x%3D%22782%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(1838%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-31%22%20x%3D%22748%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%222821%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(3267%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-32%22%20x%3D%22748%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%224250%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2E%22%20x%3D%224695%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2E%22%20x%3D%225140%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2E%22%20x%3D%225586%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(6031%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%22748%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=I%3Da%5E1%2Ca%5E2%2C…a%5EN&id=zcASv) 映射到 3 个不同的空间,得到 3个向量序列(矩阵):
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-49%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-3D%22%20x%3D%22782%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(1838%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-31%22%20x%3D%22748%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%222821%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(3267%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-32%22%20x%3D%22748%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2C%22%20x%3D%224250%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2E%22%20x%3D%224695%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2E%22%20x%3D%225140%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2E%22%20x%3D%225586%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(6031%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-61%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%22748%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=I%3Da%5E1%2Ca%5E2%2C…a%5EN&id=zcASv) 映射到 3 个不同的空间,得到 3个向量序列(矩阵):- Query 查询向量矩阵
 ,
, %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-51%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-3D%22%20x%3D%221069%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(2125%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-57%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-71%22%20x%3D%221526%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-49%22%20x%3D%223630%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2208%22%20x%3D%224413%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(5358%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJAMS-52%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(722%2C412)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-44%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.574)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6B%22%20x%3D%221020%22%20y%3D%22-271%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%221351%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%222130%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=Q%3DW%5EqI%5Cin%5Cmathbb%7BR%7D%5E%7BD_k%5Ctimes%20N%7D&id=uTJ52)
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-51%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-3D%22%20x%3D%221069%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(2125%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-57%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-71%22%20x%3D%221526%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-49%22%20x%3D%223630%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2208%22%20x%3D%224413%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(5358%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJAMS-52%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(722%2C412)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-44%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.574)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-6B%22%20x%3D%221020%22%20y%3D%22-271%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%221351%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%222130%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=Q%3DW%5EqI%5Cin%5Cmathbb%7BR%7D%5E%7BD_k%5Ctimes%20N%7D&id=uTJ52)- 用来 match others
- Key 键向量矩阵
 ,
,
- 用来被 match
- 和查询向量矩阵 Q 维度相同,因为下面做 attention 时两个矩阵要相乘
- Value 值向量矩阵
 ,
, %22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-56%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-3D%22%20x%3D%221047%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(2103%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-57%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%221526%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-49%22%20x%3D%223626%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2208%22%20x%3D%224408%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(5354%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJAMS-52%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(722%2C412)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-44%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.574)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%221020%22%20y%3D%22-185%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%221322%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%222101%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=V%3DW%5EvI%5Cin%5Cmathbb%7BR%7D%5E%7BD_v%5Ctimes%20N%7D&id=D666w)
%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-56%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-3D%22%20x%3D%221047%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(2103%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-57%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%221526%22%20y%3D%22583%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-49%22%20x%3D%223626%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-2208%22%20x%3D%224408%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(5354%2C0)%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJAMS-52%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3Cg%20transform%3D%22translate(722%2C412)%22%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-44%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.574)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-76%22%20x%3D%221020%22%20y%3D%22-185%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%221322%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20transform%3D%22scale(0.707)%22%20xlink%3Ahref%3D%22%23E1-MJMATHI-4E%22%20x%3D%222101%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E#card=math&code=V%3DW%5EvI%5Cin%5Cmathbb%7BR%7D%5E%7BD_v%5Ctimes%20N%7D&id=D666w)- 待抽取的信息
- Query 查询向量矩阵

- 对每个查询向量
 ,利用缩放点积模型(scaled Dot-Prodcut)去对每个键向量
,利用缩放点积模型(scaled Dot-Prodcut)去对每个键向量  做 attention,计算得到打分函数(
做 attention,计算得到打分函数( 和 之间的相关性/权重)
和 之间的相关性/权重) ,得到矩阵
,得到矩阵 
- 向量
 维度相同
维度相同  维度越大,
维度越大, 越大,为了平衡,除以
越大,为了平衡,除以 
- 向量
- 将每个
 输入 softmax 求得注意力分布
输入 softmax 求得注意力分布  ,得到矩阵
,得到矩阵 
 代表对于输入句子中的每个单词
代表对于输入句子中的每个单词  与当前单词
与当前单词  之间的相关性评分,分数决定了我们在编码当前位置的单词时,对输入句子中各部分(单词)的关注程度
之间的相关性评分,分数决定了我们在编码当前位置的单词时,对输入句子中各部分(单词)的关注程度

- 使用键值对注意力机制求得第 n 个输出向量
 ,得到输出矩阵
,得到输出矩阵 
- 每个输出向量
 都用了整个输入向量序列(global)的资讯
都用了整个输入向量序列(global)的资讯 - 输入句子中的每个单词的值向量乘以对应的 softmax 分数,相当于保持想要关注的单词的值向量不变(其 softmax 分数大,→1),而忽略不相关的单词(其 softmax 分数小,→0)
- 可以只让特定的注意力分布
 有值,就可以变成只关注部分输入(local),而且不只可以关注相邻的输入,而是可以通过学习关注任意的部分输入,甚至可以是关注最远的输入(天涯若比邻)
有值,就可以变成只关注部分输入(local),而且不只可以关注相邻的输入,而是可以通过学习关注任意的部分输入,甚至可以是关注最远的输入(天涯若比邻) - 所有输出向量
 可以并行计算
可以并行计算
- 每个输出向量

总结:如下图所示,自注意力的计算过程就是一堆矩阵乘法,因此用 GPU 可以加速运算
3.2 多头自注意力 Multi-head Self-attention
多头自注意力模型:不同的头关注的点不一样,例如有的 head 关注的是 local 的资讯,而有的 head 关注的是长时间的(global)的资讯
例:两头的自注意力模型
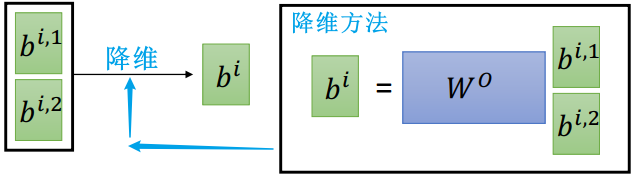
N 个头就输出 N 维的输出向量序列,如果觉得维度太高,可以降维
- eg. 论文中使用了 8 头注意力,那么会对每个输入
 输出 8 个矩阵
输出 8 个矩阵  ,但是自注意力层之后的前馈神经网络期望的输入是一个矩阵而不是 8 个,因此可以将这 8 个矩阵拼接起来,然后乘以一个附加的权值矩阵
,但是自注意力层之后的前馈神经网络期望的输入是一个矩阵而不是 8 个,因此可以将这 8 个矩阵拼接起来,然后乘以一个附加的权值矩阵  ,降维(压缩)成一个矩阵
,降维(压缩)成一个矩阵 
3.3 位置编码 Positional Encoding
3.1 自注意力的计算过程 介绍的自注意力的计算方式有一个缺点:
- 自注意力中没有位置信息,使得输入序列的时间变得不重要,邻居和天涯是一样的(天涯若比邻)。但没有位置信息,导致“A 打了 B”和“B 打了 A”是一样的,这显然不是我们想要的,我们希望能考虑输入序列的顺序
解决方法:位置编码 Positional Encoding
- 原论文是使用了一个手动设置(而不是学习得到)的位置向量(positional vector)
 :
:- 位置向量
 代表每个输入向量的位置资讯
代表每个输入向量的位置资讯  和
和  维度相同,两者相加
维度相同,两者相加- 这可能有点难理解,为什么要将
 和
和  相加而不是拼接?相加不是会导致原来的位置信息混到向量
相加而不是拼接?相加不是会导致原来的位置信息混到向量  中很难被找到吗?直接拼接是不是更好呢?
中很难被找到吗?直接拼接是不是更好呢?
- 位置向量
- 另一种理解(运算一样,只是讲法不同,更容易理解):
- 使用一个 one-hot 向量
 代表第 i 个输入向量的位置资讯,只有第 i 维是 1,其它维都是 0
代表第 i 个输入向量的位置资讯,只有第 i 维是 1,其它维都是 0 - 将输入向量
 和位置向量
和位置向量  拼接在一起
拼接在一起 - 从 3.1 自注意力的计算过程 可知,
 ,那么将 W 拆解成两部分
,那么将 W 拆解成两部分  和
和  ,
, ,所以发现原论文直接将
,所以发现原论文直接将  和
和  相加其实是说得通的
相加其实是说得通的
- 使用一个 one-hot 向量

- 但是有一个匪夷所思的地方:上图的
 当然可以通过学习得到,但原论文中
当然可以通过学习得到,但原论文中  是人工手动设置的
是人工手动设置的- 参考:
 的图:每一行对应一个输入向量的位置编码(每行 512 个值,因为论文中
的图:每一行对应一个输入向量的位置编码(每行 512 个值,因为论文中  向量的大小是 512)
向量的大小是 512)

位置编码更详细的说明参考:
4、Transformer:Seq2seq with Attention
3、Self-Attention 一节讲的是 self-attention 可以取代 RNN,接下来讲的是 self-attention 在 seq2seq 模型中怎么被使用 李宏毅老师的 Sequence-to-sequence Learning 视频讲解 - YouTube

seq2seq 模型分为编码器(encoder)和解码器(decoder),原先两部分都使用 RNN 层,现在这些 RNN 层都可以被自注意力层取代
基于 Transformer 的序列到序列生成过程(参考:Transformer: A Novel Neural Network Architecture for Language Understanding - Google AI Blog):
- 编码器 Encoder:所有输入序列的 word 两两之间做 attention,这些 attention 是并行的,做了 3 次,有 3 个 attention layer
- 解码器 Decoder:不仅会 attend 之前的输入,也会 attend 之前已经输出的部分 words

上图可以看到,Transformer 的工作过程可以分为 6 个步骤:
- Encoder 为输入序列的每个词汇产生初始的 representation(词向量),用空圈表示
- 利用自注意力机制将输入序列中所有词汇的语义资讯各自汇总成每个词汇的 representation,用实圈表示
- Encoder 重复 N 次自注意力机制(即步骤 2),让每个词汇的 representation 彼此修正以完整纳入上下文语义
- Decoder 使用自注意力机制,关注自己之前已生成的元素,将其语义也纳入当前生成元素的 representation
- 自注意力机制之后,Decoder 再使用注意力机制关注 Encoder 的所有输出并将其资讯纳入当前生成元素的 representation
- Decoder 重复 N 次步骤 4、5(自注意力机制和注意力机制) 让当前生成词汇的 representation 完整纳入整体语义
4.1 Transformer 模型网络结构

- 编码器 Encoders
- 叠放了 N 个 Encoder(论文中是 6 个),结构相同,但不共享权重。每个 Encoder 的结构:
- Feed Forward Neural Network 前馈神经网络:接受自注意力层的输出(每个 encoder 的前馈神经网络权重贡献)
- Self-Attention 自注意力层:接受编码器的输入。在编码一个特定单词时,帮助编码器查看输入句子中其他单词。论文中是 8 头自注意力
- 叠放了 N 个 Encoder(论文中是 6 个),结构相同,但不共享权重。每个 Encoder 的结构:
- 解码器 Decoders
- 叠放了 N 个 Decoder(论文中是 6 个),结构相同,但不共享权重。每个 Decoder 自下往上的结构:
- Feed Forward Neural Network 前馈神经网络:
- Encoder-Decoder Attention 编码器-解码器注意力层:帮助解码器关注输入句子的相关部分(类似于 seq2seq 模型中的注意力)
- 最顶层编码器的输出转换为注意力向量 K 和 V 的集合(矩阵),被每个解码器的 编码器-解码器注意力层 使用,使得解码器能关注到输入序列中的适当位置
- 从下面的层(多头自注意力层 + Add & Norm 的输出)创建查询矩阵 Q
- Self-Attention 自注意力层:最底部的 decoder 接受上一时刻 decoders 的输出。只关注已生成的序列(通过在子注意力计算的 softmax 步骤之前屏蔽未来的位置,即设为-inf,实现只允许关注输出序列中较早的(已生成的)位置)
- 叠放了 N 个 Decoder(论文中是 6 个),结构相同,但不共享权重。每个 Decoder 自下往上的结构:
- 以上的各个子层(Self-Attention、Encoder-Decoder Attention、Feed Forward Neural Network)都有一个残差连接(Add:将自注意力层的输入和输出相加),然后是层归一化(Layer Norm)

- 最终的 Linear 和 Softmax 层:
- Linear 层:一个简单的全连接神经网络,将 decoders 的输出向量投影到一个更大的 logits 向量
- 如果输出的词典中包含有 N 个可能的词汇,则 logits 向量的宽度就为 N,每格代表每个单词的分数
- Softmax 层:将 logits 向量中的分数转换为各个单词的概率(概率为正数,且和为 1),得到 log_probs 向量
- 选择最高概率的格子对应的单词,作为当前时刻的输出
- Linear 层:一个简单的全连接神经网络,将 decoders 的输出向量投影到一个更大的 logits 向量

4.2 自注意力 vs 注意力
前面提到,Transformer 就是 Seq2Seq 模型 + 自注意力机制。但其实在 Transformer 之前,就已经使用 Seq2Seq 模型搭配注意力机制了,只不过当时的 Seq2Seq 模型中 Encoder 和 Decoder 使用的都是 RNN。而 Transformer 只是进一步用自注意力代替了 Seq2Seq 模型中 Encoder 和 Decoder 使用的 RNN。
在 3、Self-Attention 一节我们强调了使用自注意力机制代替 RNN,可以实现并行运算。但实际上,在 Seq2Seq 架构中,自注意力机制和注意力机制其实就是一回事:
- 注意力机制(即 Decoders 中的编码器-解码器注意力层)让 Decoder 在生成输出元素的 representation 时关注 Encoder 的输出序列,从中获得上下文资讯
- 自注意力机制(即 Encoders 中的自注意力层)让 Encoder 在生成输入元素的 representation 时关注自己序列中的其他元素,从中获得上下文资讯
- 自注意力机制(即 Encoders 中的自注意力层)让 Decoder 在生成输出元素的 representation 时关注自己序列中的其他元素,从中获得上下文资讯
因此,注意力机制和自注意力机制都是让序列 q 关注序列 k 来将其上下文资讯 v 汇总到序列 q 的 representation 中,只不过自注意力机制中关注的序列 k 就是序列 q 本身
因此,在编码中,自注意力机制和注意力机制实际上使用的是同一个函数
4.3 Attention 可视化
每两个 word 之间都会有一个 attention。attention 的权重越大,线条越粗(Attention Is All You Need 论文)
一个训练英语翻译成法语的 Transformer 的编码器(8个 attention heads 之一)的第五层到第六层的单词“it”的自注意力分布(Transformer: A Novel Neural Network Architecture for Language Understanding - Google AI Blog):
多头自注意力的可视化(Attention Is All You Need 论文):
- 不同的头学会了执行不同的任务,不同的头 attend 的东西不一样

4.4 Transformer 的应用
只要可以使用 seq2seq,就可以使用 Transformer
实例:文本摘要生成(Generating Wikipedia by Summarizing Long Sequences)
之前的 seq2seq 模型,如果要处理  量级的输入和输出
量级的输入和输出  是很不可思议的,很困难,但是使用 Transformer 可以实现
是很不可思议的,很困难,但是使用 Transformer 可以实现
4.5 Transformer 的变形
Universal Transformer(Moving Beyond Translation with the Universal Transformer - Google AI Blog):
- 原本的 Transformer 的每一层都是不一样的
- 而 Universal Transformer 在纵轴(深度)上做 RNN,每一层(横轴)都是一样的 Transformer

Self-Attention GAN(SAGAN)(Self-Attention Generative Adversarial Networks):
自注意力在图像上的应用,让每一个 pixel 都去 attend 其它 pixel,这样在处理影像时可以考虑比较 global 的资讯。SAGAN 就是利用图像远处而非局部的互补特征来生成图像。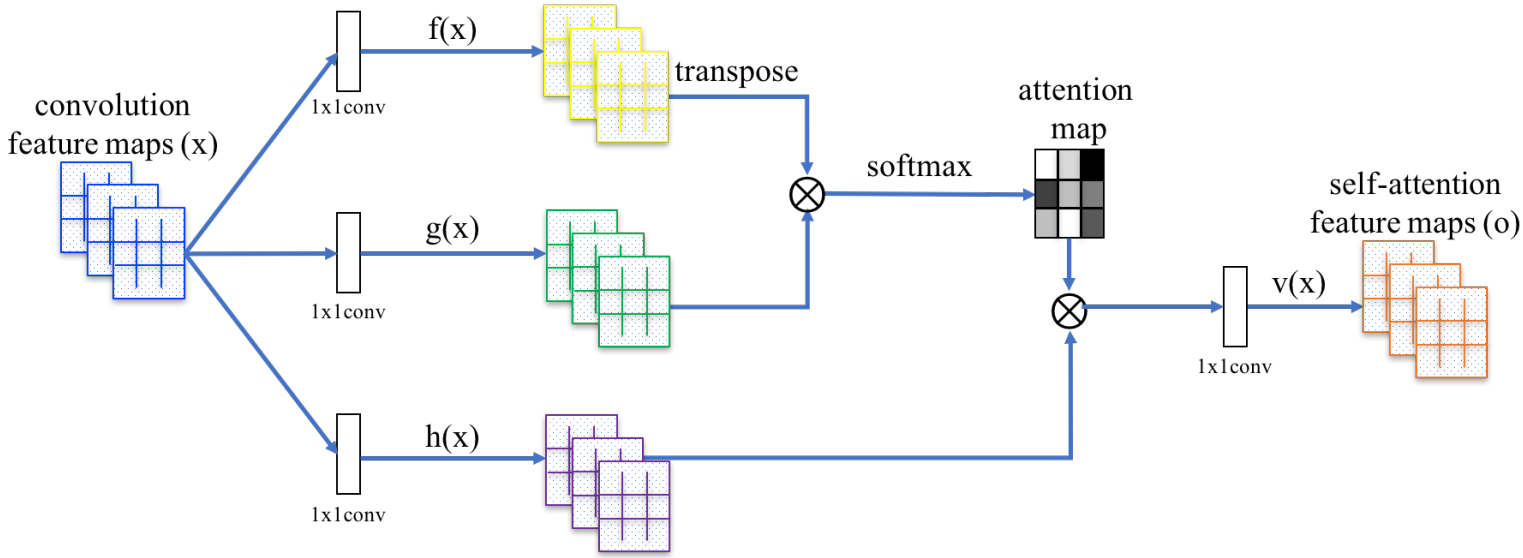

4.6 其它相关文献
- 原始论文:Attention Is All You Need
- Image Transformer
- Training Tips for the Transformer Model
- One Model To Learn Them All
5、Transformer 代码实现
Tensorflow 实现:Tensor2Tensor package
Pytorch 论文复现:The Annotated Transformer
- Github:annotated-transformer,可下载到本地使用 jupyter notebook 允许
- Google Colab 在线运行版:The Annotated “Attention is All You Need”.ipynb
- 中文翻译讲解版:The Annotated Transformer的中文注释版(1)
Pytorch 官方提供的 torch.nn 中的 Transformer API | nn.Transformer | Transformer 模型 | | —- | —- | | nn.TransformerEncoder | N 个编码器的堆叠 | | nn.TransformerDecoder | N 个解码器的堆叠 | | nn.TransformerEncoderLayer | 编码器层,由自注意力和前馈网络组成 | | nn.TransformerDecoderLayer | 解码器层,由自注意力、多头注意力、前馈网络组成 |

若有收获,就点个赞吧
0 人点赞
