3.1 语音转换 VC
3.1.1 什么是语音转化?
语音转换(VC):
- 输入:一段声音讯号
- 输出:另一端声音讯号
- 输入和输出的语音讯号的异同点:
- 相同点(保留的):内容 content(文字)一样
- 不同点:有很多方面
- 语者不一样:语者转换
- 说话风格转化
- 增进一段声音的可理解性:eg. 增进发音有问题的病人说话的可理解性、口音转换
- … …
3.1.2 语音转换的用途
上面提到的输入输出的不同点,就对应了不同的语音转换任务:
- 语者转换:可用于欺骗他人、实现个人 TTS、隐私保护等
- 说话风格转换:说话情感转换、小声说换转成正常声音、歌手发音技巧转换等
- 提高一段声音的可理解性:增强一些发音有问题的病人说话的可理解性、口音转换等
- 数据增强:

3.2 语音转换的实现方法 汇总
3.2.1 语音转换的两个阶段
语音转换分为两部分:
- 语音转换 Voice Conversion:
- 理论上,语音转换的输入和输出语音长度可以是不一样的
- 需要用 Seq2seq model 实现
- 但实际上,为了简化模型,往往假设输入和输出的长度相等,这样就不需要使用 Seq2seq model
- 理论上,语音转换的输入和输出语音长度可以是不一样的
- Vocoder:将语音转换输出的 acoustic features (即声学特征向量序列) 转换为声音讯号
- 这部分其实是通用的,并不是语音转换才用到,VC、TTS、语音分离等都会用到
- 本节课不会涉及这部分内容

3.2.2 语音转换的方法
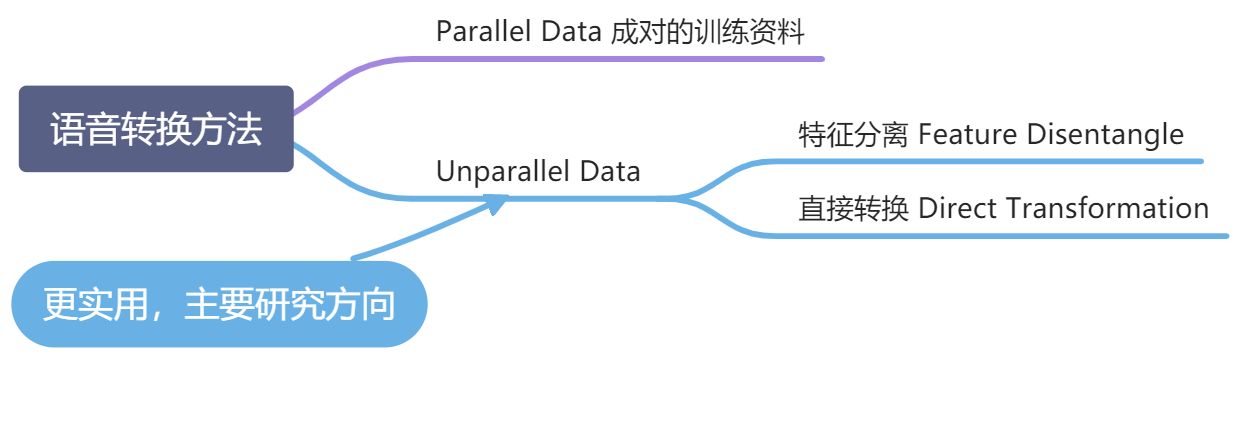
- 成对的训练资料:
- eg. 若要将语者 A 的语音转换为语者 B 的语音,训练资料中包含的都是两个语者对同一句话的语音

- 缺点:缺乏训练数据。很难收集到非常大量的成对训练资料
- 解决办法:
- 用一个预训练好的模型,再用少量训练数据去 fine-tune
- 使用语音合成的数据
- 不成对的训练资料:

- 是 语音的风格迁移,可以从图像风格迁移借鉴技术
- 2 类方法:
- 特征分离 Feature Disentangle:把混在一起的资讯(eg. 文字资讯 & 语者资讯,or 口音、情绪等资讯)分类开来,想要进行什么转换,就把什么资讯解离开
- 下面都以语者转换为例,也就是要把输入的一段语音的文字资讯和语者资讯分离开。那么只要将语者资讯替换掉,就可以实现语者转换
- 直接转换 Direct Transformation:借鉴影像风格转换
- Cycle GAN
- Star GAN
- 特征分离 Feature Disentangle:把混在一起的资讯(eg. 文字资讯 & 语者资讯,or 口音、情绪等资讯)分类开来,想要进行什么转换,就把什么资讯解离开
- 特征分离和直接转换这两种方法并不冲突,可以直接整合在一起使用。比如 Star GAN 中的生成器可以替换成特征分离中 encoder 和 decoder 组成的 auto encoder
3.3 特征分离 Feature Disentangle
特征分离:以语者转换为例,特征分离就是要将一段语音的文字资讯和语者资讯解离开
- 使用 content encoder 提取只跟文字内容有关的资讯
- 使用 speaker encoder 提取只跟语者特征有关的资讯
- 替换语者资讯,就实现了语者转换
- 使用 decoder 读取两个 encoder 输出的文字(内容)资讯和语者资讯,输出合成的语音(记用该语者的特征念出这段话的内容)


3.3.1 Encoder
特征分离分别使用不同的 encoder 来提取内容资讯和语者资讯,这有几种不同的实现方法
3.3.1.1 Speaker Encoder
- 方法一:直接使用 one-hot 向量表示每一位语者
- 直接都进来,不需要学习(不是一个网络)
- 局限:难以考虑新的语者
- 训练资料中有几个语者,就是几维的向量。训练资料中没有的新语者的声音就没办法合成。如果想新增加一个语者,就需要重新训练

- 方法二:使用代表语者特征的向量(Speaker embedding),即使用已经预训练好的 Encoder ,来保证 speaker encoder 输出的是语者特征
- 经典做法:i-vector, d-vector, x-vector

3.3.1.2 Content Encoder
- 方法一:使用预训练的 encoder
- 一种想法是直接把语音识别系统当作 content encoder,以确保抽取出来的是只与内容相关的资讯
- 但不能是一般的语音识别系统,直接输出文字,那么就没法和语者特征向量(speaker embedding)拼接在一起丢到 decoder 做 end-to-end 的训练
- 常见做法:HMM + Deep Learning
- 一种想法是直接把语音识别系统当作 content encoder,以确保抽取出来的是只与内容相关的资讯

- 方法二:加上 GAN,通过对抗训练得到内容资讯
- speaker classifier 用于判别 content encoder 的输出属于哪个语者
- content encoder 试图产生骗过鉴别器的输出,让它无法判断语者
- speaker classifier 和 content encoder 交替对抗训练
- 如果 content encoder 的输出能骗过鉴别器(即无法分出 是哪个语者的声音),则说明这个输出已经不包含任何语 者信息,只保留了内容资讯

- 方法三:将图像风格迁移的思想用于语音转换,设计网络架构
- content encoder 使用的是 CNN,包含一组 filters,每一个 filter 的作用就是抓取声音讯号中的一种 pattern。一个 filter 扫过整个输入语音序列,就得到一行输出序列,一组 filters 扫过就得到一组输出序列。每一行输出序列就代表声音讯号中某种特征是否出现。例如,女生的声音讯号,可能就是高频特征输出比较大,低频特征输出较小。
- 核心思想:使用 instance normalization(IN),来移除语者信息,只保留内容资讯
- instance normalization 对输出向量序列的同一个 dimension 做 normalization,即对每一行输出序列做 normalization,使得每一行都变为均值为 0,方差为 1,也就是不会再有某个 filter 输出的值特别大或特别小,那么就相当于把语者的特征给去掉了

3.3.2 Decoder
对应于上面 Content Encoder 的方法三:将图像风格迁移的思想用于语音转换,设计网络架构
- 使用 adaptive instance normalization(AdaIN)(只影响语者资讯)


3.3.3 问题
上面介绍的 Auto Encoder 的训练方法有一个问题:产生出来的声音未必理想。
- 因为模型在训练时从未考虑语音转换(VC),训练时是用同一个语者的声音输入到 speaker encoder 和 content encoder。但在测试时,因为是语音转换任务,那么这两个 encoder 的输入是不同的语者

3.3.4 解决办法:2nd Stage Training
- 针对上面提到的问题,一个自然的解决办法就是,在训练时把语音转换考虑进来,也就是说,在训练时,将来自不同语者的输入分别丢给 content encoder 和 speaker decoder
但这又产生了一个问题,这样训练语料就没有 ground truth 了,decoder 不知道应该产生怎样的声音讯号,没有训练目标,就没办法训练
解决办法:引入 GAN 的思想,在训练时加入两个额外的标准:
- 鉴别器 Discriminator:用于鉴别声音讯号是真的还是语音合成的
- 语者分类器 Speaker Classifier:用于判断一段声音讯号属于哪个语者
- 那么在训练时,decoder 就有了训练目标,即想办法输出一段声音讯号,使得能够欺骗鉴别器(即让输出听起来像真的,而不是合成的)和语者分类器(即让输出听起来像是这个语者讲的)

改进 Tips:打补丁 patcher。本来 decoder 的输出不太理想,patcher 把一些补丁加入到 decoder 的输出上,期待输入给 discriminator 后鉴别声音是真实的,输入给 speaker classifier 后判定是语者 A 的声音。发现在 2nd stage 不直接训练 decoder,而只去训练另外一个模型,即 patcher,会让训练结果更加稳定、成功
3.4 直接转换:Cycle GAN & Star GAN
点击查看【bilibili】
直接转换:即不需要特征分离,直接将 A 的声音转换成 B 的声音
- 借鉴影像风格转换的方法:Cycle GAN
- 缺点:若有多个语者,则 Cycle GAN 不太实用,需要语者两两之间都做 Cycle GAN
- 进阶:Star GAN
- 更进阶:Blow
3.4.1 Cycle GAN
Cycle GAN 原本用于影像的风格转换,可以将影像换成声音
Cycle GAN 有三个训练目标:
- 训练目标 1:让生成器
 生成的语音能骗过鉴别器
生成的语音能骗过鉴别器  ,即被鉴别为是 Y 的声音(与 Y 的声音越像越好)
,即被鉴别为是 Y 的声音(与 Y 的声音越像越好)- 如果只有训练目标 1,那么可能会导致这个网络无视输入,只让生成器
 生成的语音听起来像 Y 的声音
生成的语音听起来像 Y 的声音 - 解决办法:增加一个生成器
 ,把生成器
,把生成器  生成的语音再转回 X 的语音,希望输入、输出的声音讯号越接近越好,也就是训练目标 2
生成的语音再转回 X 的语音,希望输入、输出的声音讯号越接近越好,也就是训练目标 2
- 如果只有训练目标 1,那么可能会导致这个网络无视输入,只让生成器
- 训练目标 2:希望生成器
 生成的语音与输入的 X 的语音越像越好
生成的语音与输入的 X 的语音越像越好 - 训练目标 3:训练时直接给生成器
 输入 Y 的语音,希望能生成一模一样的声音
输入 Y 的语音,希望能生成一模一样的声音- 是一个 tip,在训练时加上这个目标会更好


3.4.1.1 Cycle GAN 的问题
若有多个语者,Cycle GAN 就不太实用,需要对语者两两之间都做 Cycle GAN
解决办法:Stat GAN
3.4.2 Star GAN
Cycle GAN 和 Star GAN 的训练方式的差别如下图所示:
- 生成器:
- Cycle GAN 中生成器只有一个功能:即将特定两个语者的声音进行转换(要么将 X 的声音转换为 Y 的声音,要么将 Y 的声音转换为 X 的声音)
- Star GAN 中生成器是多才多艺的,它额外接收一个代表语者的向量,可以将输入的声音讯号转换成任意你想要的语者的声音

- 鉴别器:
- Cycle GAN 中鉴别器只会鉴别一段声音讯号是不是特定某个人讲的
- Star GAN 中鉴别器额外接收一个代表语者的向量,可以判定一段声音是不是属于这个语者的


若有收获,就点个赞吧
0 人点赞
