4.1 语音分离 Speech Separation
鸡尾酒会效应:人可以无视嘈杂的环境,专注于你想听的那个人的声音资讯
语音分离 Speech Separation:让机器像人一样,能把它想听的声音资讯从嘈杂的环境中抽取出来
语音分离分为两类:
 本节课专注于语者分离 Speaker Separation
本节课专注于语者分离 Speaker Separation
4.1.1 语者分离 Speaker Separation
语者分离 Speaker Separation:即将一段混合了多个语者(以及环境音)的语音分离成各个语者的声音
- 语者分离的输入和输出长度相同,因此不需要用 Seq2Seq 模型(杀鸡焉用牛刀)

本节课的关注点(设定):
- 假设只包含两个语者(可以轻松拓展到多个语者)
- 假设只有单一麦克风,即只输入一段声音讯号
- 假设是语者独立的 Speaker independent:即训练和测试是完全不同的语者
训练数据:成对的训练数据
- 很容易收集到单一语者的声音讯号,再两两结合,即可得到成对的训练资料

4.1.1.1 评估方法
设模型分离出的的语者 A 的语音为  ,对应的真实的语者 A 的语音(ground truth)为
,对应的真实的语者 A 的语音(ground truth)为  ,则模型的训练目标是让
,则模型的训练目标是让  与
与  越接近越好
越接近越好
几种评估指标:
- SNR (Signal-to-noise ratio):

- SNR 的值越大,说明模型效果越好
- 并不适用于语者分离,存在两个问题:
- ①
 与
与  实际上听起来很像,说明模型效果好,但如果
实际上听起来很像,说明模型效果好,但如果  声音较小,E 就会较大,使得 SNR 的值较小
声音较小,E 就会较大,使得 SNR 的值较小 - ② 如果模型的输出
 质量很差,但直接把它的音量变大,E 就会变小,SNR 的值就会变大,尽管模型能力并没有得到改善
质量很差,但直接把它的音量变大,E 就会变小,SNR 的值就会变大,尽管模型能力并没有得到改善
- ①

- SI-SDR / SI-SNR (Scale invariant signal-to-distortion ratio):

- 是现在文献上常用的评估语者分离好坏的标准
 与
与  越平行,则 SI-SDR 的值越大,说明模型效果越好
越平行,则 SI-SDR 的值越大,说明模型效果越好

- SI-SDR improvement:是文献上常见的一种使用 SI-SDR 的方式
- 计算混合语音与真实的单个语者语音(ground truth)的 SI-SDR,再计算模型分离出来的语音和 ground truth 的 SI-SDR,两者的差值代表了经过语者分离后 SI-SDR 值的提升
- 通常是正的,因为分离后一般肯定 SI-SDR 有提升,即与 ground-truth(单个语者的真实语音)更像

- PSEQ:评估语音质量
- STOI:计算可理解程度
4.1.1.2 排列问题 Permutation Issue
- 为了实现语者分离的训练,训练资料中包含了很多语者,那么对于每对训练资料,在评估模型输出的时候,ground truth 的两个语者的语音如何排列?
- 如果每对训练资料中包含两个语者的语音,那么就有两种摆放 ground truth 的方式,但不知道哪一种是对的。
- 因此,早期的时候,无法使用 deep learning 解决语者独立的语者分离问题,只能解语者不独立的语者分离问题。

4.2 深度聚类 Deep Clustering
深度聚类 Deep Clustering:16年,是最早用深度学习解决语者独立的语者分离问题的模型
- 想法:语音转换 VC》) 是输入一段声音讯号,输出一段很不一样的声音讯号;但语者分离的输入和输出其实很像,输出只是输入减去一些东西,因此不需要一个 general model 来做语者分离
- 深度聚类就是不直接产生新的声音讯号,而是产生 Mask:
- 设计一个 Mask Generation 网络,输入混合的语音讯号 X,输出两个 Mask:M1、M2
- Mask 矩阵的大小和输入相同
- Mask 矩阵的值可以是二元的也可以是连续的
- 两个 Mask 矩阵 M1、M2 分别与 X1、X2点乘(element-wise product),得到两段语者分离的声音讯号 X1、X2
- 设计一个 Mask Generation 网络,输入混合的语音讯号 X,输出两个 Mask:M1、M2

4.2.1 IBM (Idea Binary Mask)
- 训练数据是有 ground truth 的,也就是两个语者单独的语音讯号,将这两个声音讯号分别转换成两个矩阵(蓝矩阵 & 红矩阵)
- 比较这两个矩阵每一格谁的值大,来得到 Mask 矩阵(Mask 矩阵的大小和输入、输出相同)
- 如果某一格蓝矩阵的值大于红矩阵的值,那么蓝色语者的 Mask 矩阵该格就填 1,红色语者的 Mask 矩阵该格就填 0;反之亦然
- 将两个 Mask 矩阵与输入矩阵点乘,分别得到两个输出矩阵,就是两个语者分离后的语音讯号
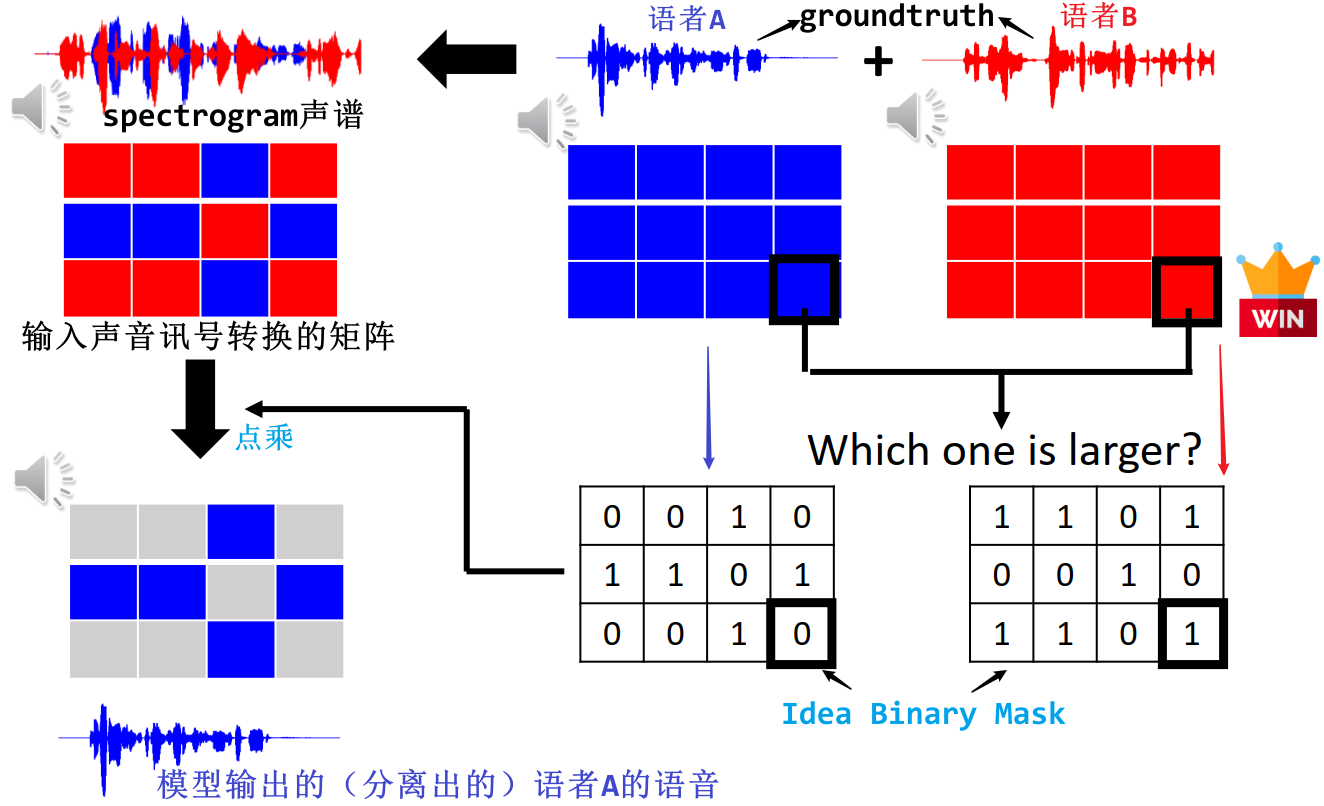
- 训练:上面提到的 Mask 称为 Idea Binary Mask,即理想二元 Mask,这在训练时是能得到的,因为有 ground truth,就可以让模型产生的 Mask 去逼近 ground truth 得到的 Mask,据得到了理想的 Mask
测试/推理:但在测试阶段没有 ground truth,就出现了一个问题:没法得到 Idea Binary Mask
问题:
- ① 上面提到的测试时没法得到 Idea Binary Mask
- ② 仍未解决排列问题(Permutation Issue),还是存在两种排列方式
4.2.2 深度聚类的运作方式
深度聚类的工作流程(框架)如下:
- Embedding Generation:是深度聚类中唯一能训练的网络结构
- 输入一段混合的声音讯号:是一个长为 T,高为 D 的矩阵
- 输出长为 T,高为 D,深为 A 的立方体,即把输入矩阵的每个格子都扩展成一个向量
- K-means Clustering:一般是固定的,没法 train(后来的研究也可以 train)。将向量分成 K 群
- Embedding Generation 的输出相当于 T×D 个向量,输入给 K-means Clustering
- 输出将这 T×D 个向量分为了 K 群,这里 K=2,即两个语者
- 根据分群结果产生 Binary Mask
- 将 Mask 分别与输入矩阵点乘,就分离出了不同语者的声音讯号

4.2.3 深度聚类的训练
真正需要训练的只有 Embedding Generation,其学习目标为:
- ① 对于输入矩阵中代表不同语者的格子,希望它们经过 Embedding Generation 扩张成的向量的距离越大越好
- 这样代表不同语者的向量经过 K-means Clustering 后才会被分到不同的 clusters,最终 Mask 矩阵中这两个格子的值才会不同
- ② 对于输入矩阵中代表相同语者的格子,希望它们经过 Embedding Generation 扩张成的向量的距离越小越好
- 这样代表不同语者的向量经过 K-means Clustering 后才会被分到相同的 clusters,最终 Mask 矩阵中这两个格子的值才会相同

训练效果:实验结果表明训练是有效的。而且神奇的是,训练时做的是两个语者的语者分离,但在测试时,将 K-means Clustering 的 K 值改为 3,就能做 3 个语者的分离了
缺点:不是 End-to-End 的
4.3 置换不变训练 PIT (Permutation Invariant Training)
PIT:真正有办法实现 End-to-End 训练的方法
- 想法:假设已经有一个语者分离的模型,参数为
 。这样我们就知道怎样安排 ground truth 的排列:以两个语者有两种排列情况为例,两种排列都算一下 loss,看看哪个的 loss 比较小,就代表哪个排列更合适
。这样我们就知道怎样安排 ground truth 的排列:以两个语者有两种排列情况为例,两种排列都算一下 loss,看看哪个的 loss 比较小,就代表哪个排列更合适 - 但是,我们需要先知道怎么排列,才能训练出一个语者分离的模型
- 陷入了“鸡生蛋、蛋生鸡”的问题

PIT 的做法(解决上述问题):
- ① 初始,随机安排 ground trurh 的排列,基于此训练语者分离网络,更新模型参数
- ② 用训练好的模型重新决定标签的排列,基于此重新训练语者分离网络,更新模型参数
- ③ 循环迭代第 ② 步,直到收敛
训练效果:前期排列不稳定,但最终会收敛,即模型是 work 的
4.4 TasNet (Time-domain Audio Separation Network)
点击查看【bilibili】
TasNet:一个端到端的语者分离模型,19年提出
- 输入输出:输入和输出直接是声音讯号的 sample(采样),直接是原始的 waveform(声波),没有抽 acoustic feature
- 输入:是一串非常长的数值,也可以仍当作向量序列,即每个向量的维度为 1
- 输出:同输入,不过 K 个语者就输出 K 个序列
- 包含几个模块:
- Encoder:输入 Mixed audio,输出 Feature map 矩阵
- Separator:输入 Feature map 矩阵,输出 2 个 Mask
- Decoder:输入:两个 Mask 和 Feature map 分别做点乘;输出:语者分离的语音
- 训练时需要用到 PIT


4.4.1 Encoder & Decoder
- Encoder:是一个 linear transform,即一个 16×512 的矩阵
- Decoder:是一个 linear transform,即一个 512×16的矩阵
- Encoder 和 Decoder 不需要绑定成互为 inverse,实验表明 inverse 效果反而不好
- Encoder输出的 512 维的向量不需要都为正值

将 Encoder 的权重参数可视化:
4.4.2 Separator
一个简化的 Separator 的示例:
- 输入:encoder 的输出
- 输出:两个 mask
- 实验验证,两个 mask 的同一位置不需要和为 1

实际的 separator 要深得多,CNN 的 d 从 1、2、4、8 一直到 128,再从头开始循环,反复多次(一般重复 3-4 次,次数是一个超参数)
- 之所以使用非常深的 CNN 网络,是因为这样可以看到够长的资讯
- 每次 encoder 的 output 只代表了时长 2ms (即16 sample)的输出,如果使用上面提到的方式重复 3 次,模型就能考虑时长1.53s 的资讯
- 可以使用让 CNN 参数量减少(轻量化)的方法:深度可分卷积(Depthwise Separable Convolution)

之所以用的 CNN,而不是 LSTM,是因为 LSTM 有点敏感,就一定要从句子开头读起,否则就崩掉,不稳定,波动大
4.5 More
- 语者数量未知:实际上一段混合语音中语者数量是不固定的,未知的
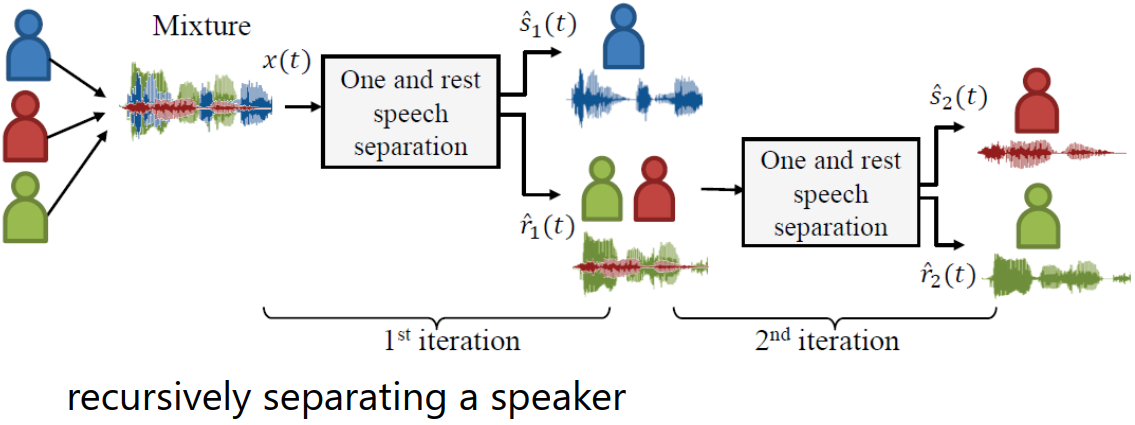
- 参考论文:Recursive speech separation for unknown number of speakers
- 方法:每次只分离一个人的声音讯号(网络自己决定抽哪个人的声音讯号),迭代
- 问题:不知道有几个语者,不知道走到什么时候停下来?
- 答:走到剩余部分只剩下杂讯,没有人的声音就可以停下来
- 多个麦克风:即输入有多条语音讯号的情况
- 参考论文:FASNET: LOW-LATENCY ADAPTIVE BEAMFORMING FOR MULTI-MICROPHONE AUDIO PROCESSING
- 也是直接端到端的硬 train

- 面向任务的优化:针对不同的任务、以及是给机器听还是给人听,可以制定不同的训练目标

- 视觉信息:也有可能通过使用影像资讯来强化语者分离


若有收获,就点个赞吧
0 人点赞
