视频:ELMO, BERT, GPT 李宏毅 - YouTube
点击查看【bilibili】
这里介绍 3 种 Language Models:
 这些 language model 的目的都是为 token(单词、字等) 抽取出一个好的表示(representation),也就是将每个 word token 映射到一个 word embedding 向量
这些 language model 的目的都是为 token(单词、字等) 抽取出一个好的表示(representation),也就是将每个 word token 映射到一个 word embedding 向量
1 单词表示
- 为了让计算机读人类的文字,需要对单词或字进行编码
- 在有 ELMO, BERT, GPT 等模型前,传统的编码方式有:
- one-hot 编码(1-of-N Encoding):无法表达词汇之间的关联性
- Word Class:分类太粗糙
- Word Embedding:相当于一个 soft 的 word class

- 以上这些传统的编码方式,是每个 word type 固定有一个或多个 embedding,但即使是相同的 word type 也可能存在多种不同的含义(是不同的 word tokens)

解决办法:
- Contextualized Word Embedding:每个 word token 有一个 embedding(即使有相同的 word type),且每个 word token 的 embedding 依赖于其上下文

2 ELMO (Embeddings from Language Model)
- 是基于 RNN (LSTM) 的语言模型
- 不需要对数据做标注,只需要搜集一大堆句子(无标签),就可以训练
- 将训练好的 RNN 的隐藏层拿出来,就可以看作对应单词的 Contextualized Word Embedding
- 正向 RNN 的隐藏层就相当于是考虑 上文 的 word embedding
- 逆向 RNN 的隐藏层就相当于是考虑 下文 的 word embedding
- 将这两个 word embedding 拼接起来就是 Contextualized Word Embedding

- 可以叠加多层 LSTM,得到深层网络,每一层都可以对每个 token 产生一个隐表示(latent representation),ELMO 对每一层得到的 word embedding 求加权和,得到最终的 Contextualized Word Embedding
- 每层的 embedding 对应的权重 α 被视为之后要做的任务的模型的参数,训练得到

3 BERT (Bidirectional Encoder Representations from Transformer)
BERT 相当于 Transformer 的 Encoder
- 不需要带标签的语料,用大量无标注的句子即可进行训练
- 输入 token 序列(句子),输出一串向量(即每个 token 对应的向量)
- 下图中输入的 tokens 用的是 词,但实际上处理中文时用 字 更为恰当。因为 tokens 也要表示成 one-hot vector 的形式才能输入给 BERT,而中文词的数量几乎是无穷的,会导致输入的 one-hot 向量维度太大,而中文字的个数是有限的

3.1 预训练 BERT 的两种方法:
过去,一般会根据不同 NLP 任务的性质量身定制一个最合适的模型架构,这无疑是耗时耗力耗计算资源的。于是就有了一个想法:如果有一个能直接处理各式 NLP 任务的通用架构该有多好?
BERT 就将上述想法付诸实践。通过两阶段迁移学习:
- ① 使用 Transfomer Encoder、大量无标注的文本以及两个预训练目标,事先训练好一个可以套用到多个 NLP 任务的 BERT 模型(对自然语言有一定“理解”的通用模型)
- ② 再将该模型拿来做特征提取 or 以及为基础 fine tune 不同的下游任务
值得注意的是,预训练和 fine-tune 这两个步骤使用的 BERT 模型是一模一样的。也就是说,当你学会使用 BERT,就能用同一个架构训练各式 NLP 任务,大大减少自己设计模型架构的成本。
不过 BERT 的预训练成本非常高,非常吃计算资源。但实际上现在已经有开源的预训练好的 BERT,通过 Pytorch or TensorFlow 导入即可使用。
3.1.1 方法一:Masked LM
随机将输入句子的 tokens 以一定的概率(eg. 15%)置换成特殊的 tokens:[MASK],也就是说句子中有 15% 的词汇会被遮盖住,而 BERT 就要猜测这些被盖住的地方是什么词汇。
将挖空的地方 BERT 输出的 word embedding 输入到线性分类器,要求它预测出挖空处的实际词汇。由于线性分类器的能力很弱,想要成功预测,那么就要求 BERT 输出的 word embedding 是一个很好的 representation,因此 BERT 要很深(24层、48层)
将线性分类器和 BERT 一起训练
3.1.2 方法二:Next Sentence Prediction
输入两个句子,中间插入 [SEP] 代表两个句子的交界,第一个句子开头加上 [CLS] 代表在这里输出分类结果(即两个句子是否应该被接在一起),[CLS] 通过 BERT 的输出再经过线性分类器输出分类结果
- 如果网络是 RNN,需要依次读入两个句子后再预测更合适,那么在两个句子之后做预测更合适
- 但 BERT 内部不是 RNN,而是 Transformer,包含 Self-Attention,天涯若比邻,放在哪都一样能看全局,因此放在开头预测就可以
训练语料中有很多句子,且知道两个句子是否是相接的(上下句),就可以将线性分类器和 BERT 一起训练
3.1.3 方法一、二同时使用
谷歌在预训练 BERT 时同时使用方法一(Masked Language Model,克漏字填空)和方法二(Next Sentence Predicition,判断两个句子在原文中是否相接)
3.2 如何使用 BERT
3.2.1 Case1:输入单个句子,输出类别
任务举例:文本情感分析、文本分类
3.2.2 Case2:输入单个句子,输出每个词的类别

3.2.3 Case3:输入两个句子,输出类别
任务举例:自然语言推理
- 给定 前提 和 假设,判断假设是对、错、未知的

3.2.4 Case4:输入两个句子,输出两个整数
任务举例:基于抽取的问答系统(答案一定在输入的文章中出现)
- 输入文本 D 和查询 Q,输出两个整数 s,e,代表文本中第 s~e 个 tokens 为答案


3.3 BERT 拓展
3.3.1 ERNIE 专为中文设计
中文任务全面超越BERT:百度正式发布NLP预训练模型ERNIE
ERNIE: Enhanced Representation through Knowledge Integration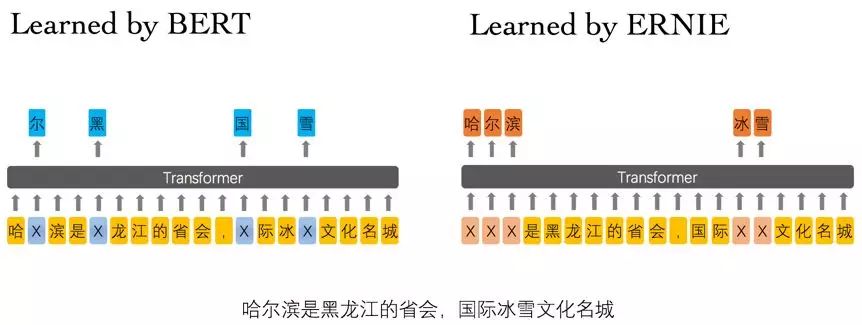
3.3.2 BERT 学习什么?
BERT Rediscovers the Classical NLP Pipeline
WHAT DO YOU LEARN FROM CONTEXT? PROBING FOR SENTENCE STRUCTURE IN CONTEXTUALIZED WORD REPRESENTATIONS
3.3.3 Multilingual BERT
Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT
用各种语言的维基百科去训练,能自动学习到不同语言之间的对应关系。给英文的文章让它去学文章的分类,他能自动学会中文文章的分类
4 GPT (Generative Pre-Training)
Language Models are Unsupervised Multitask Learners
GPT 相当于 Transformer 的 Decoder 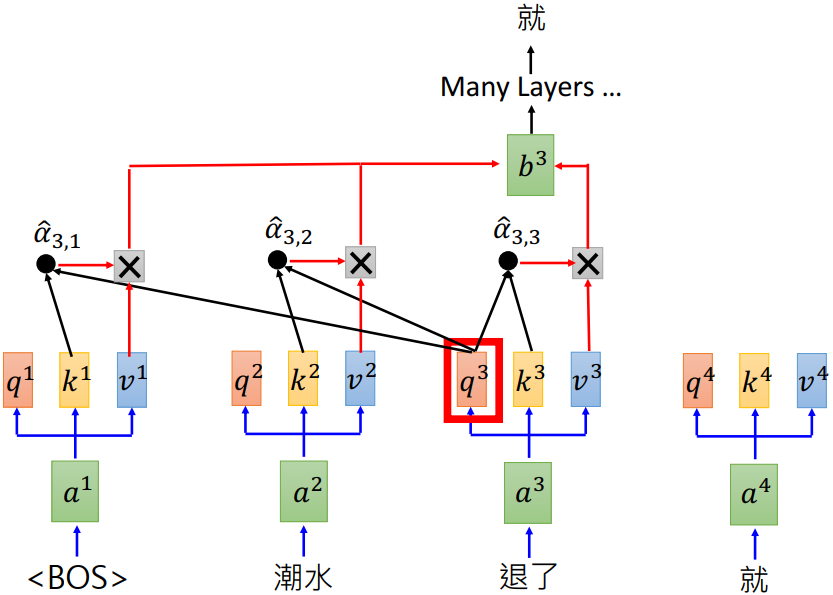
- Zero-shot learning:GPT 可以在完全没有与任务相关的训练资料的情况下自动做到:
- 阅读理解:给定文章 D 和问题 Q,给出答案
- BERT 需要 QA 相关的训练资料,而 GPT 可以不用,直接硬做
- 摘要:表现很差
- 翻译:表现很差
- 阅读理解:给定文章 D 和问题 Q,给出答案
- 网站 Talk to Transformer 就是用 GPT 来自动续写你输入的文字
5 拓展阅读

若有收获,就点个赞吧
0 人点赞
