6.1 语音→类别 相关任务
前面的课分别介绍了:语音→文字(语音识别 ASR》)),语音→语音(语音转换 VC》)、语音分离),文字→语音(语音合成 TTS》)),这节课介绍的是语音→类别任务(语音分类)
语音→类别 相关的任务:
6.1.1 语者识别 Speaker Recognition / Identification
语者识别:即判断一段语音是谁说的
6.1.2 语者验证 Speaker Verification
语者验证:即判断两段语音是否为同一人所说
- 输入:注册语音(Enrollment) & 验证语音(Evaluation)
- 输出:代表两端语音相似度的数值,如果这个数值大于设定的阈值,代表两段语音属于同一个语者;否则代表属于不同语者

应用:银行客服(用于验证客户身份)
语者验证系统的评价指标:EER (Equal Error Rate)
- 即 FN 和 FP 相等时的值
- FN (False Negative) Rate:实际是同一语者但被判断成不同语者
- FP (False Positive) Rate:实际上不同语者但被判断成同一语者
- 不同的 threshold 会导致系统有不同的 performance
- 穷举所有可能的 threshold,绘制不同 threshold 时的 FN-FP 折线图,在绘制一条 FN=FP 的对角线,两条线的交点就是该语者验证系统的 EER 值

6.1.3 语者分段标记 Speaker Diarization
语者分段标记:即判断在一段语音中,谁在何时说话
- 输入:一段语音(eg. 会议记录),其中包含多个语者

- 两个步骤:
- 分段 Segmentation:将属于不同语者的语音分成不同的段,每段属于一个语者
- Clustering:标记每一段语音是哪个语者讲的
- 两种状况:
- Case 1:语者数量已知
- Case 2:语者数量未知
本节课主要关注的是语者验证 Speaker Verification 任务,实际上其它语音分类任务也是大同小异
6.2 Speaker Embedding
前面提到,语者验证是输入两端语音(注册语音 & 验证语音),输出代表两段语音相似度的数值。一般的做法是先将两段语音分别抽出一个 speaker embedding 向量(这个向量代表了语者特征,过滤了内容资讯),再对这两个 speaker embedding 向量做相似度计算
- Speaker Embedding:代表语者特征的向量。已过滤掉关于内容的资讯,只留下语者相关的资讯
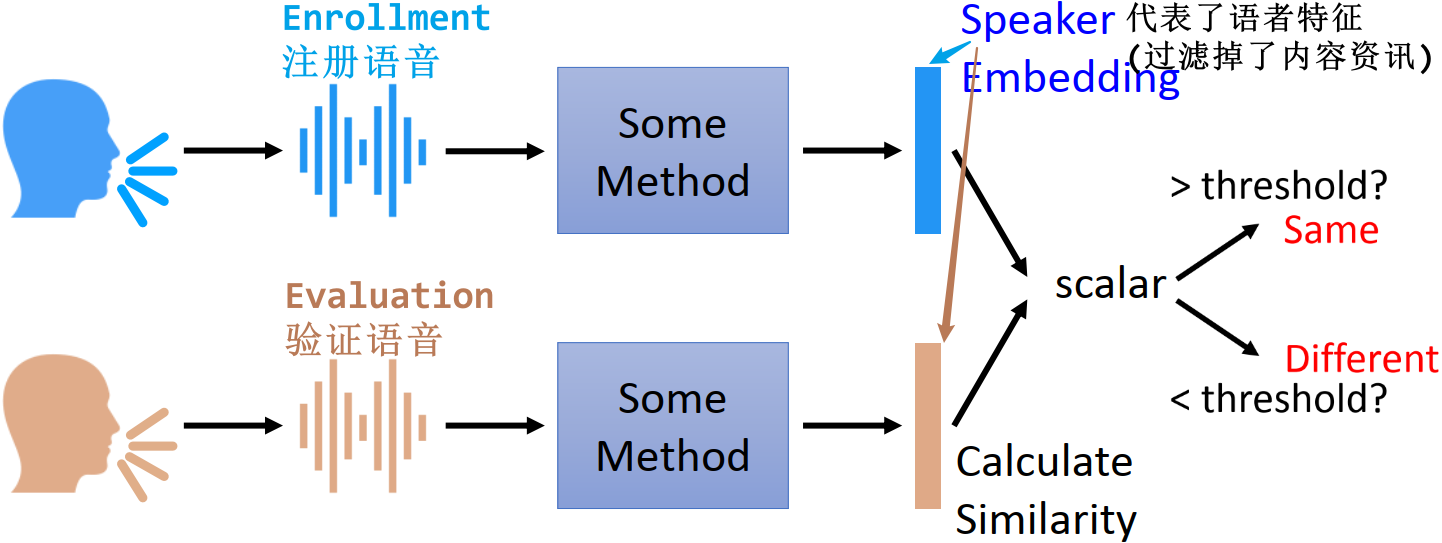

6.2.1 语者验证的框架
分为三个步骤:(以银行客服系统为例)
- stage 1:Development 开发
- 使用语料库,训练出可以产生 speaker embedding 的模型
- 语料库中用于训练的语音的语者在步骤 2、3 中不再出现
- 语料库:
- 谷歌的论文中用的是包含 36 M 条句子、18000 个语者的语料库,但是非公开的
- 公开语料库:
- VoxCeleb:包含 0.15 M 条句子,1251 个语者
- VoxCeleb2:包含 1.12 M 条句子,6112 个语者
- stage 2:Enrollment 注册
- 你打电话给银行客服,客服问你要不要开通语者验证系统,你说要,就要求你念几句话,念的话就是注册语音,输入到训练好的模型中,输出注册语音的 speaker embedding
- 如果有多条注册语音(即说了好几句话),就将这几段话的 speaker embedding 平均起来
- stage 3:Envaluation 验证
- 你下一次打电话给客服,你的声音(验证语音)通过这个模型产生验证语音的 speaker embedding,计算注册语音的 speaker embedding 和验证语音的 speaker embedding 的相似度,如果相似度的值大于设定的阈值,则表明是同一个语者;否则是不同语者
- 计算相似度的一种方法:speaker embedding 做 normalization,然后计算余弦相似度
- 你下一次打电话给客服,你的声音(验证语音)通过这个模型产生验证语音的 speaker embedding,计算注册语音的 speaker embedding 和验证语音的 speaker embedding 的相似度,如果相似度的值大于设定的阈值,则表明是同一个语者;否则是不同语者

其实,这套框架的想法就是 Metric-based meta learning(参考:Meta Learning – Metric-based (1/3) 李宏毅 - YouTube)
6.2.2 i-vector
i-vector 是语音领域最后一个被 deep learning 打败的方法
- 将一段语音讯号(不论多长)都抽取出 400 维的向量,即 speaker embedding,代表这段声音讯号的语者特征
- i:identity

6.2.3 d-vector
d-vector 是最早用 deep learning 抽取 speaker embedding 的模型
- d:deep learning
想法:
- 将声音讯号截一小段丢到 DNN 中(因为没有用 RNN,DNN 只能吃固定长度的句子,因此要截取固定长度的一段)
- DNN 的训练目标是做语者识别。尽管我们最终是要做语者验证,但在训练时,把这个 DNN 当作语者识别模型来训练
- d-vector:将 DNN 模型的最后一层的输出抽出来,就是 d-vector。d-vector 的维度可以自己决定,eg. 512
- 不使用最终的输出作为 d-vector,是因为最后的输出层和语者数目有关,维度大,而且不能自己决定

上面的模型得到的 speaker embedding 向量只看了截取的一小段声音讯号的资讯,但实际上在语者验证中应该是将一整个句子的资讯变成一个 vector,该怎么办呢?
总体框架:
- 将一个句子切成很多很多长度相等的小段,每个小段之间可以有重叠
- 将每个小段的语音分别输入到一个 DNN 中,每个 DNN 是分开训练的(即每小段语音是分开训练的?),可以对每小段语音分别抽一个 vector 出来
- d-vector:将这些 vector 取平均,就是最终的 d-vector,是代表整个句子的语者资讯的向量

结果:只是接近 i-vector 的效果,还略逊一筹
6.2.4 x-vector
x-vector:训练 x-vector 语音识别模型时,直接就是看一整个句子,直接看一整个句子的资讯来预测 speaker 是哪一个
- 与 d-vector 的区别:
- d-vector 中每个 DNN 是分开训练的,每个 DNN 看的是一部分语音,并判断属于哪个语者;而 x-vector 虽然也有多个 DNN,但是将这些 DNN 的输出向量都集合起来,求均值和方差向量,再将均值和方差向量拼接起来,输入到另外的 DNN 中做语者分类,因此相当于在训练时直接看的就是一整个句子的资讯
结果:优于 i-vector
进阶:用 LSTM 取代 DNN 读取这些 vector
6.2.5 其它进阶方法
- 注意力机制:用某个方法产生每个语音片段对应的 vector 的 attention weight,再对所有 vector 求加权和

- NetVLAD:从影像领域借鉴的方法。想办法从一整段声音讯号里产生一个固定长度的向量,里面只包含我们需要关注的部分,不包含杂讯、静音等。有很多种方法,不过做的事都是先训练语音识别模型,训练完后得到 speaker embedding,再拿这个 embedding 做语者验证
6.3 End-to-End 的语者验证模型
前面提到的方法都是先做语者识别模型的训练,以抽取得到 speaker embedding,然后对注册和验证语音的 speaker embedding 计算相似度(先对 speaker embedding 做 normalization,然后对两个向量计算余弦相似度)
End-to-End 模型:将学习 speaker embedding 和计算相似度放在一个模型里一起学
6.3.1 数据集的准备
训练数据集准备的一种方法:
- 对于正样本:随机选取语者 i,选择语者 i 的 K 个句子当作注册语句,选择语者 i 的另外一个句子当作验证语句,将注册语句和验证语句丢到模型中,希望输出的代表相似度的值越大越好
- 对于负样本:随机选取语者 i,选择语者 i 的 K 个句子当作注册语句,再选择另外一个语者 j 的一个句子当作验证语句,将注册语句和验证语句丢到模型中,希望输出的代表相似度的值越小越好

准备训练数据集现在比较常用的另一种方法:GE2E (Generalized end-to-end)
6.3.2 End-to-End 模型
其实 End-to-End 的语者验证模型完全是仿照传统的语者验证模型构造的
- 将 K 条注册语音输入到网络中,得到代表每个语音的 K 个 speaker embedding 向量,将这 K 个向量做平均得到最终的代表注册语音的 speaker embedding 向量
- 将验证的语音输入到网络中,得到代表验证语音的 speaker embedding 向量
- 计算代表注册语音的 speaker embedding 向量 和 代表验证语音的 speaker embedding 向量之间的相似度
- 常见的设计是两个向量做余弦相似度,再做一些小的 shift(乘上一个 weight,加上一个 bias),就得到最终的输出

训练目标:如果注册语音和验证语音来自同一语者,则希望相似度打分越高越好;如果注册语音和验证语音来自不同语者,则希望相似度打分越低越好
6.3.3 Text-dependent v.s. Text-independent
- Text-dependent:注册和验证时都要说固定的句子
- Text-independent:注册和验证时都可以随便说,不指定句子内容
- 对于 Text-independent 的情况,如何让模型能无视文本内容,只抽取出语者特征?
- 解决办法:GAN 的思想(语音转换 VC 中也用到类似技术,Content Encoder 的方法二)
- 加上一个鉴别器,用于判断输入的向量代表的文字内容(类似语音识别)
- 训练时网络的训练目标是想办法骗过这个鉴别器。如果能骗过鉴别器,说明网络能过滤掉内容资讯,使得输出的 speaker embedding 中只包含语者资讯


若有收获,就点个赞吧
0 人点赞
