- 7.1 NLP 任务汇总
- 7.2 前处理任务
- 7.3 摘要 Summarization
- 7.4 机器翻译 Machine Translation
- 7.5 文法纠错 Grammer Error Correction
- 7.6 文本情感分类 Sentiment Classification
- 7.7 立场侦测 Stance Detection
- 7.8 事实侦测 Veracity Prediction
- 7.9 自然语言推理 NLI (Natural Language Inference)
- 7.10 搜索引擎 Search Engine
- 7.11 问答系统 QA (Question Answering)
- 7.12 对话系统 Dialogue
- 7.13 知识图谱 Knowledge Graph
- 7.14 自然语言处理能力评测
点击查看【bilibili】
前面几节介绍了很多和语音相关的任务,接下来介绍和文字有关的任务
7.1 NLP 任务汇总

7.1.1 文字→类别
文字→类别 的 NLP 任务又分为两种类型:
- 输入一段文字,只输出一个类别
- 输入一段文字,对每个 token 都输出一个类别

7.1.2 文字→文字
文字→文字的 NLP 任务通常使用 seq2seq 模型(包含一个 encoder、一个 decoder),有时还需要做 attention
- 有些时候,需要给 attention 加上 copy 机制,使得 decoder 可以从 encoder 的输入中直接 copy 一些词汇输出


7.1.3 输入多个语句
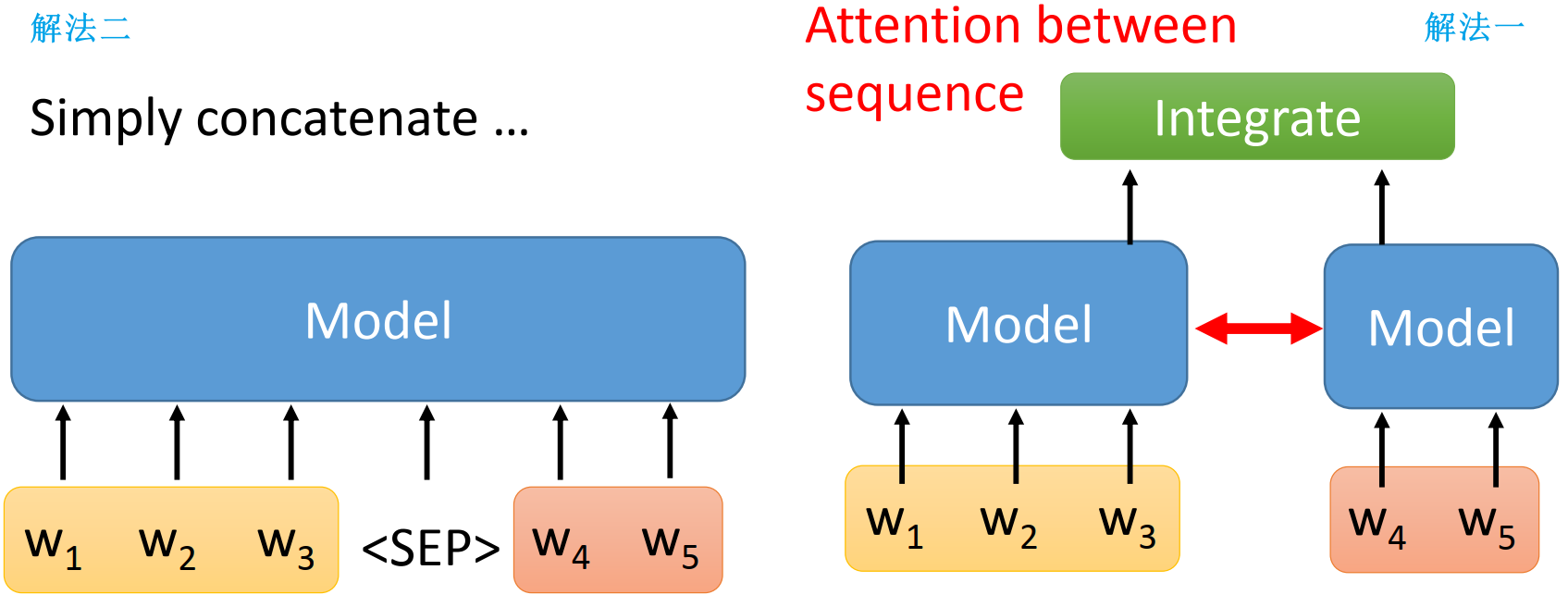
如果输入包含多条语句,如何处理多条输入语句?(对 文字→文字、文字→类别 两类任务都适用)
- 解法一:对每条输入的 sequence ,分别用一个 model 做 encode,再整合
- 有时候在 model 之间会加上 attention,因为有时候需要知道上下文的句子才能 encode 好
- 解法二:直接把多条输入的 sequence 连接起来,连接处加上一个特殊的 token:
<SEP>- 是近年来比较流行的方法
7.1.4 NLP 任务分类汇总
根据输入、输出的不同,NLP 任务分类如下:(横轴是输入形式、纵轴是输出形式)
| 输入一个 sequence | 输入多个 sequences | |
|---|---|---|
| 输出一个类别 | - 文本情感分类 Sentiment Classification - 立场侦测 Stance Detection - 事实侦测 Veracity Prediction - 意图分类 Intent Classification - 对话策略 Dialogue Policy |
- 自然语言推理 NLI. Natural Language Inference - 搜索引擎 Search Engine - 关系抽取 Relation Extraction |
| 每个 token 输出一个类别 | - 词性标注 POS tagging - 分词 Word segmentation - 抽取式摘要 Extractive Summarization - 槽填充 Slotting Filling - 名字实体识别 NER. Name Entity Recognization |
|
| 输出拷贝自输入 | - 抽取式QA(问答系统) Extractive QA |
|
| 输出 General Sequence (一般的语句) |
- 生成式摘要 Abstractive Summarization - 机器翻译 Translation - 语法校正 Grammer Correction - 自然语言生成 NLG. Natural Language Generalization |
- 一般的 QA. General QA - 面向任务的对话系统 Task Oriented Dialogue - 聊天机器人 Chatbot |
| 其它输出情况 | - 句法分析 Parsing - 指代消解 Coreference Resolution |
7.2 前处理任务
7.2.1 词性标注 Part-of-Speech(POS) Tagging
词性标注:用词性(eg. 动词、形容词、名词)注解句子中的每一个词
- 输入:sequence
- 输出:每个 token 的类别(词性)
- 作用:常被用作下游任务的前处理,先对 sequence 做词性标注得到词性序列,再将词性序列和原来的句子一起输入给后续更复杂的任务(eg. 摘要、翻译等),使后续任务做的更好
- 但是现在处理下游任务的模型能力越来越强,eg. BERT 本身就有词性标注的能力,因此先做词性标注作为前处理就显得没那么必要

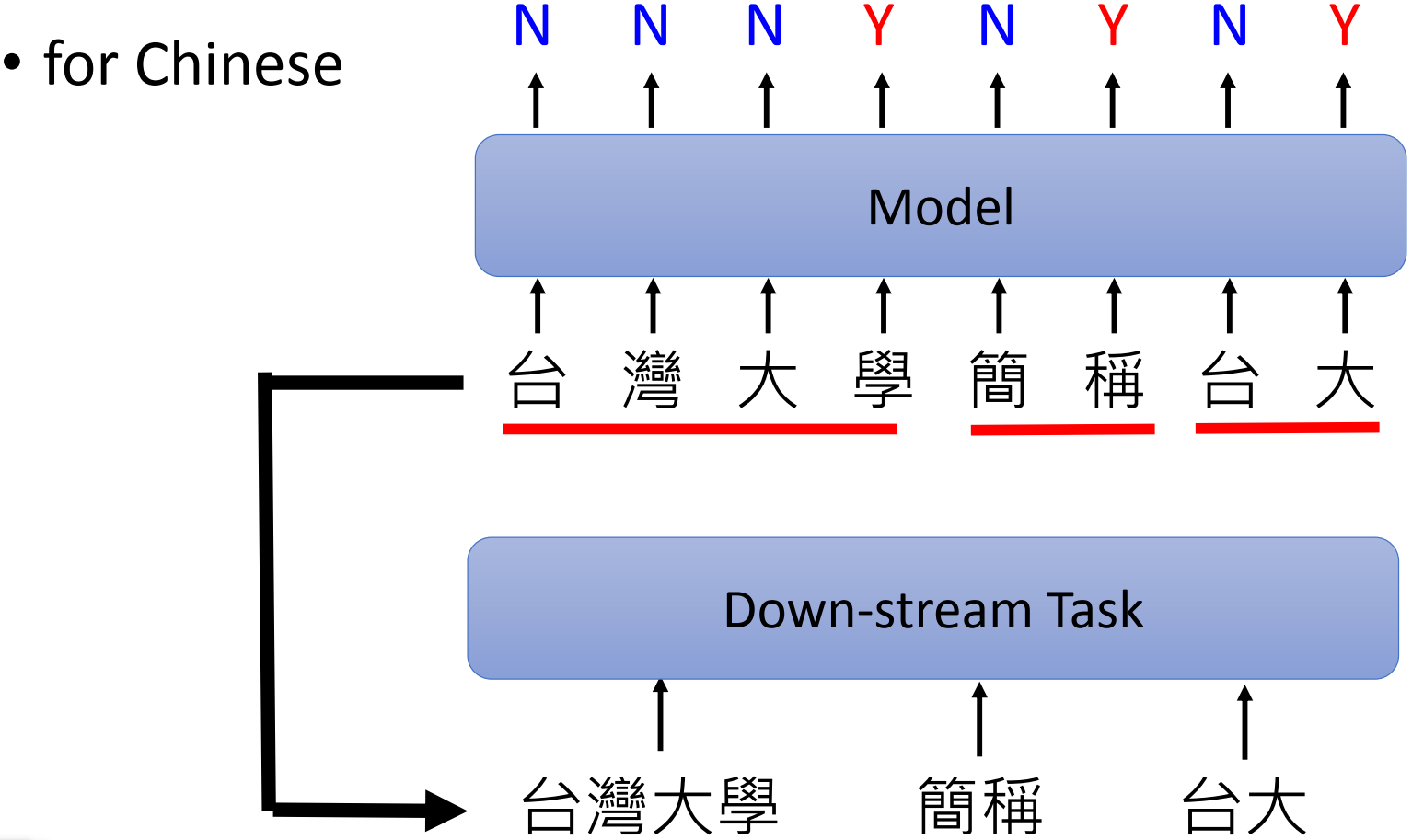
7.2.2 分词 Word Segmentation
分词:也是前处理常使用的,尤其是中文,往往需要先做分词
- 输入:sequence
- 输出:每个 token 的类别(是否是一个词汇的结束边界)
- 作用:常被用作下游任务的前处理,后续任务就可以将词汇而不是字当作处理的单位
- 但像 BERT 这种模型处理中文时就以字作为单位(很可能已经自动学到了分词)
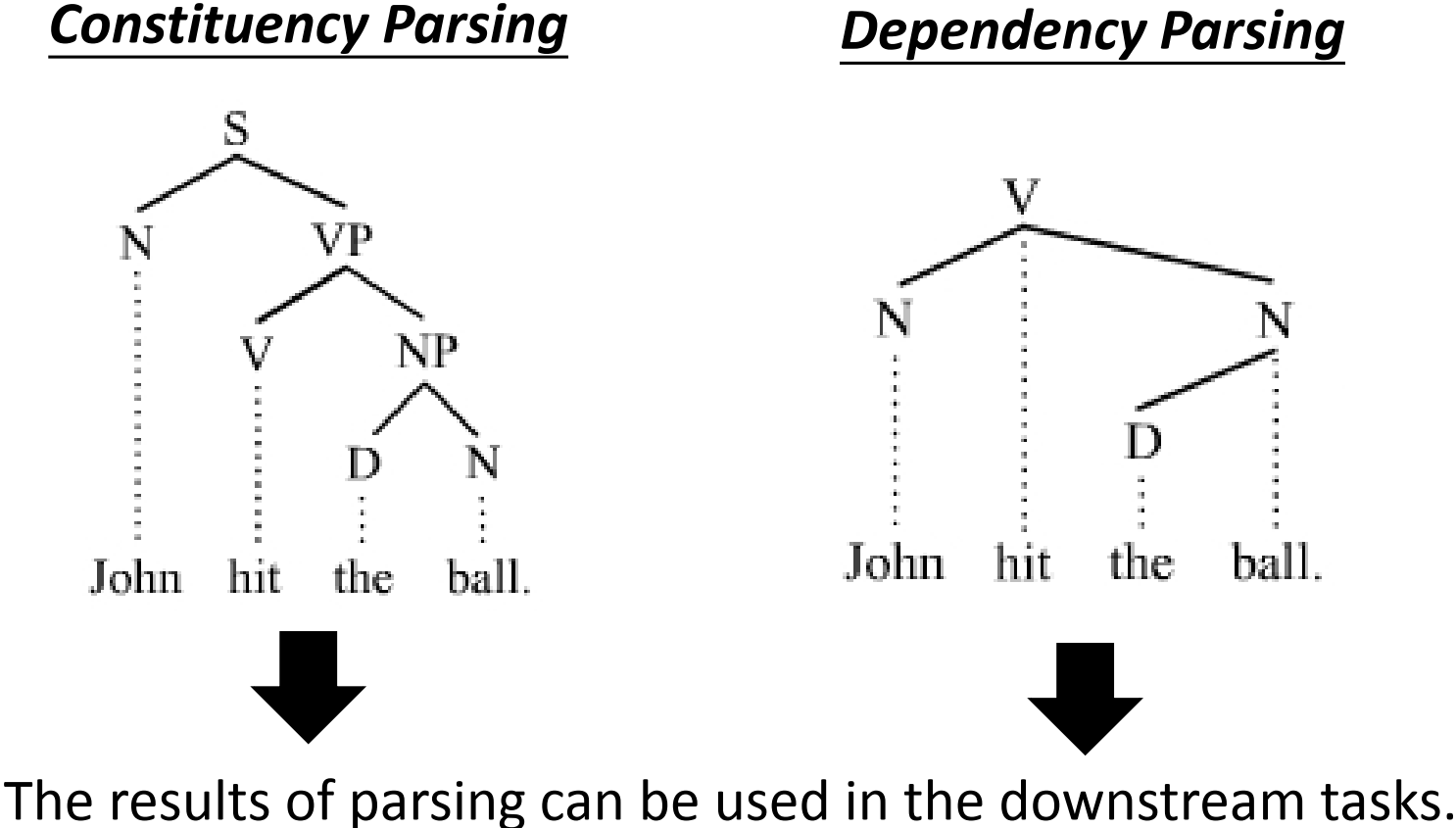
7.2.3 句法分析 Parsing
句法分析:
- 输入:sequence
- 输出:树状结构
7.2.4 指代消解 Coreference Resolution
指代消解:找出一篇文章里哪些词汇指的是同一样实体(Entity),尤其是某个代名词(he、she、it)指的是什么
- 输入:sequence
- 输出:
在线Demo:AllenNLP - Demo
7.3 摘要 Summarization
7.3.1 抽取式摘要 Extractive summarization
抽取式摘要:给机器看一篇文章,让它自动挑选出其认为重要的语句,拼接起来,就是摘要
- 输入:sequence
- 输出:每个 token(句子) 的类别(二分类:选择、不选择)
- 缺点:这种方法生成的摘要中的句子都是文本中的原句,因此很难产生好的摘要

7.3.2 生成式摘要 Abstractive summarization
生成式摘要:不从文章里直接挑句子组成摘要,机器要用自己的话来写摘要
- 输入:sequence
- 输出:sequence
- 使用 seq2seq model
- 模型需要有 copy 机制,能够直接从输入的原文章中 copy 一些词汇放到输出的摘要中(因为摘要中一般包含原文中的词汇)

7.4 机器翻译 Machine Translation
机器翻译:
- 输入:sequence
- 输出:sequence
- 无监督机器翻译是一个重要的研究方向

7.5 文法纠错 Grammer Error Correction
文法纠错:可以直接使用 seq2seq model 硬 train 一发,也需要 copy 的机制将一些没有错的词汇直接从输入 copy 到输出
- 输入:sequence
- 输出:sequence
- 简化版本:输出每个 token 的类别(4种类别:正确、置换、插入、删除)

7.6 文本情感分类 Sentiment Classification
文本情感分类:
- 输入:sequence
- 输出:一个类别(正面、负面)

7.7 立场侦测 Stance Detection
立场侦测:
- 输入:两个 sequences(原博文 + 需判断立场的评论)
- 输出:一个类别(立场:支持、反对、怀疑、评论)

7.8 事实侦测 Veracity Prediction
事实侦测:判断一段文字的真假
- 输入:多个 sequences(需判断真假的博文 + 评论 + 维基百科等其它资料)
- 输出:一个类别(二分类:真、假)

7.9 自然语言推理 NLI (Natural Language Inference)
自然语言推理 NLI:
- 输入:两个 sequences(前提 + 待判断真假的假设)
- 输出:一个类别(假设的推理结果:矛盾、蕴含、中立)

7.10 搜索引擎 Search Engine
搜索引擎:
- 输入:两个 sequences(查询关键字 + 网页文章)
- 输出:一个类别(二分类:相关/不相关,相关的网页排序就靠前)
- 谷歌已经把 BERT 用于搜索引擎,使用 BERT 后搜寻结果变得更好(参见博客:Understanding searches better than ever before)

7.11 问答系统 QA (Question Answering)
QA 问答系统:
- 输入:多个 sequences (问题 + 知识来源)
- 输出:sequence(回答)
- QA 模型要能处理非结构化的文章(网页),因此也称为 阅读理解

7.11.1 抽取式问答系统 Extractive QA
抽取式 QA:正确答案在文章中,是普通 QA 的简化版
- 输入:多个 sequences
- 输出:两个正数 s,e,代表输入的文章中的第 s 到第 e 个 tokens 为答案

7.12 对话系统 Dialogue
7.12.1 Chatting 尬聊
在线聊天机器人:cleverbot
Chatting 聊天机器人:使用 Seq2Seq Model
- 输入:多个 sequences(要把过去的对话语句都丢进去,使得能知道上下文信息)
- 输出:sequence(下一句要说的话)
- 同时为了让回答更丰富,希望模型还能考虑人格、同理心、知识等

7.12.2 面向任务的 Task-oriented
任务导向的对话系统:期望对话是为了知道某些资讯,以帮人完成某件事,而不是尬聊
- 输入:多个 sequences(过去已有的对话)
- 输出:sequence(下一句要说的话)

- 使用 Seq2Seq model,又可以拆成几个更小的模型:
- NLU 自然语言理解:
- 意图分类:sequence(用户输入) → class(意图)
- 槽填充:sequence(用户输入) → 每个 token 的类别(slot)
- State Tracker:several sequences(历史对话) → sequence(state)
- Policy:sequence(state) → 类别(action)
- NLG 自然语言生成:sequence(action) → sequence(回答语句 reply)
- NLU 自然语言理解:

7.12.2.1 NLG 自然语言生成 Natural Language Generation:
NLG 自然语言生成 Natural Language Generation:
- 输入:sequence(一个 action)
- 输出:general sequence(自然语言,即要说的话)
- 流程:
- 先定好机器可以做的有哪些 action(eg. 打招呼、询问入住日等)
- 将历史对话输入到模型中,输出一个 action
- 将这个 action 输入 NLG,输出下一句对话

7.12.2.2 Policy & State Tracker
State Tracker:抽取状态
- 输入:多个 sequences(历史对话)
- 输出:sequence(state:相当于对历史对话记录的总结)
- 使用 Seq2Seq 模型,可以 end-to-end 硬学
Policy:
- 输入:sequence(state,即 State Tracker 抽取出的状态)
- 输出:一个类别(一个 action)
- 分类问题,根据 state 来决定下一步要执行哪个 action
- eg. state 中还不知道入住人数,那么就执行询问订房人数的 action

7.12.2.3 NLU 自然语言理解 Natural Language Understanding
NLU 自然语言理解:将用户输入的 sequence 进行处理再输入到后面的 state tracker 进行后续处理
包含两个模组:
- 意图分类 Intent Classification:判断句子的意图,是提供资讯还是询问问题
- 输入:sequence(历史对话)
- 输出:一个类别(一种意图:eg. 这句话是提供资讯 or 询问问题)
- 槽填充 Slot Filling:
- 输入:sequence(历史对话)
- 输出:每个 token 的类别
- 流程:
- 先定好一些 slots,每一个 slot 代表跟任务有关的一个咨询,eg. 入住日、退房日
- 输入句子,输出每个 token 对应的类别(是哪一种 slot)

7.13 知识图谱 Knowledge Graph
知识图谱:从大量文字中抽取 实体 entity、关系relation
分为两个步骤:(下面的介绍实际上是过度简化了的)
- ① 抽取实体 Extract Entity:
- ② 抽取关系 Extract Relation:

7.13.1 NER 名字实体识别 Name Entity Recognition
名字实体 name entity:人名、机构名、地点等,取决于实际应用关心的点
NER 名字实体识别:抽取实体
- 输入:sequence
- 输出:每个 token 的类别(名字实体)

- 问题:名字一样可能指不同东西(实体),名字不一样可能指同一个东西(实体)
- 解决:Entity Linking(之后的课会讲)
7.13.2 关系抽取 Relation Extraction
关系抽取:
- 输入:多个 sequences(相关的语句、两个实体)
- 输出:类别(两个实体之间的关系)

7.14 自然语言处理能力评测
- 过去是每个任务分开做,各有一个模型,那么就难以系统性地评估机器理解人类语言的能力
- 想法:用同一个模型解多个任务,对比结果
- 几个比赛:
7.14.1 GLUE
有三大类任务:
- sequence → class:
- Corpus of Linguistic Acceptability (CoLA)
- Stanford Sentiment Treebank (SST-2)
- 两个 sequences → class(两个句子的意思是否相同)
- Microsoft Research Paraphrase Corpus (MRPC)
- Quora Question Pairs (QQP)
- Semantic Textual Similarity Benchmark (STS-B)
- NLI 自然语言推理 Natural Language Inference:两个 sequences(前提 + 假设) → class(推理结果)
- Multi-Genre Natural Language Inference (MNLI)
- Question-answering NLI (QNLI)
- Recognizing Textual Entailment (RTE)
- Winograd NLI (WNLI)
GLUE 网址:GLUE
GLUE 还有中文版本:中文语言理解测评基准(CLUE)
7.14.2 Super GLUE
随着模型的进步,上面的 GLUE 的难度就显得不够大了,因此就有了进阶版的 GLUE,包含 8 个任务
网址:SuperGLUE
7.14.3 DecaNLP
网址:DecaNLP
DecaNLP 有十个任务,且任务更难,要求用同一个模型解这 10 个任务
- 可以将所有不同的任务都看作 QA 问题

若有收获,就点个赞吧
0 人点赞
