- 2.1 语音识别的输入输出
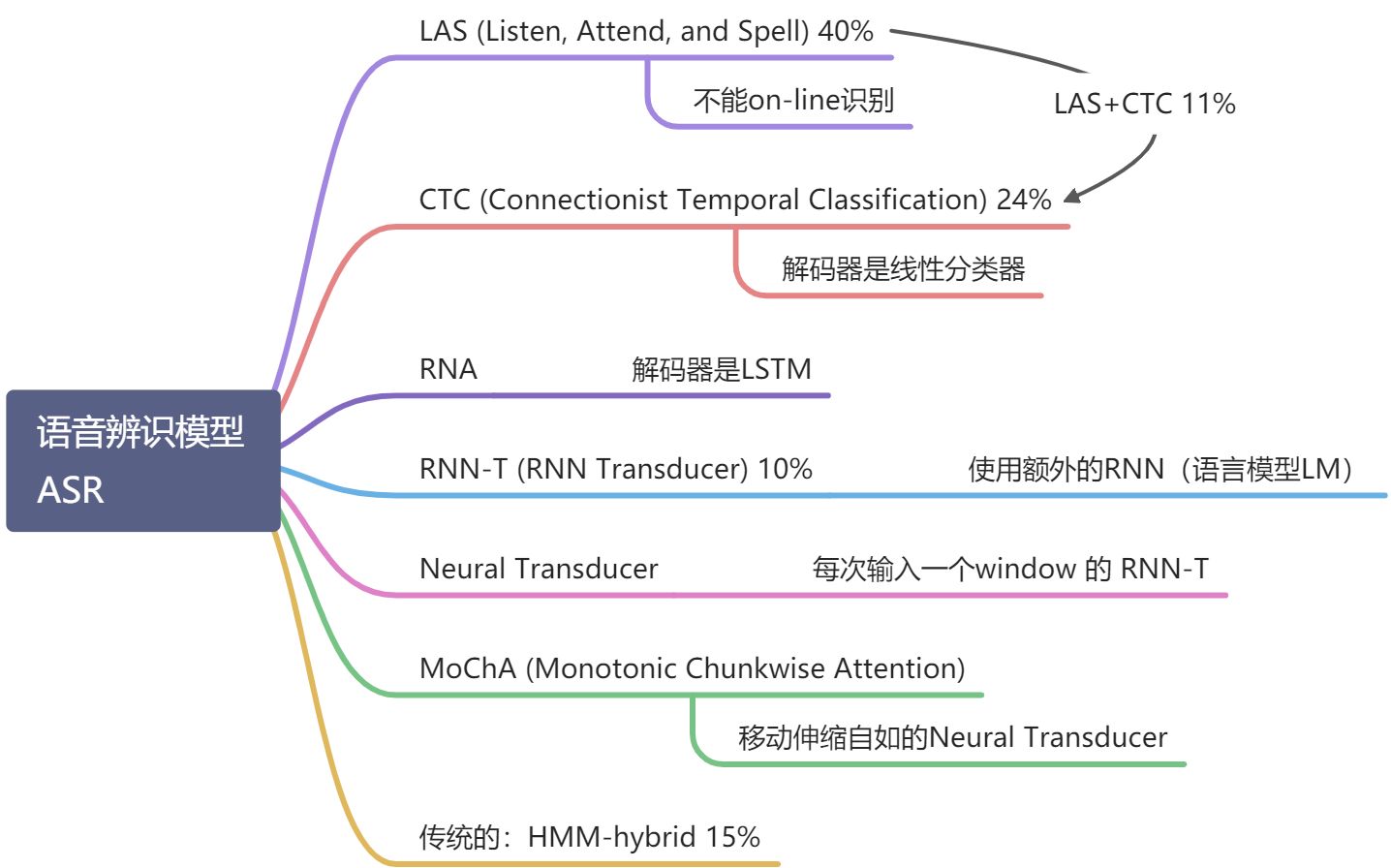
- 2.2 语音辨识模型 汇总
- 2.3 LAS 模型 (Listen, Attend, and Spell)
- 2.4 CTC 模型 (Connectionist Temporal Classification)
- 2.5 RNA
- 2.6 RNN-T 模型 (RNN Transducer)
- 2.7 Neural Transducer 模型
- 2.8 MoChA 模型 (Monotonic Chunkwise Attention)
- 2.9 传统的语音识别系统 HMM(Hidden Markov Model) 隐马尔可夫模型
- 2.10 HMM,CTC,RNN-T 的 4 个问题汇总
- 2.11 Q1:如何穷举所有 alignments?
- 2.12 Q2:如何累加各 alignment 对应的概率(RNN-T 为例)?
- 2.13 Q3:如何训练 (RNN-T 为例)?
- 2.14 Q4:如何测试/解码(以RNN-T为例)?
- 2.15 语言模型 Language Model
2.1 语音识别的输入输出

- 输入:长度为 T 的 d 维语音向量序列
输出:长度为 N 的 tokens 序列,tokens 总数为 V(词表数)
2.1.1 输出 token
不同的 token 形式:(百分比为 19 年论文对不同 token 的使用率)

Phoneme 音位:发音的基本单位
- 优点:语音和 phoneme 是直接对应的(phoneme 可以想象成音标,不过实际上某些音标含多个 phoneme)
- 缺点:需要语言学家将一门语言的发音划分为 phoneme,还需要给出词典(lexicon)对词汇和 phoneme 做映射。费时费力,而且主观性强

- Grapheme:书写的最小单位
- 在英文中就是:英文字母 + 空格 + 标点符号
- 优点:不需要使用词典,容易使用
- 缺点:有一定的风险拼写错误

- Word:词
- 对于一些语言(例如中文),词的数量可能特别大,甚至无法穷举

- Morpheme:传达意思的最小单位
- eg. 英文中的词根词缀
- 如何定义 morpheme?
- linguistic:语言学家给出
- statistic:统计学的方法

- Bytes:
- eg. 输出 UTF-8
- 优点:和语言无关,所有语言都可以输出 UTF-8 格式的编码,然后以字节作为 token,因此 V 大小固定为 256(1字节=8bits,2^8=256种不同的字节编码)

2.1.2 输入 Acoustic Feature
acoustic feature(声学特征)的不同形式:(百分比代表 19 年论文中对不同声学特征形式的使用率)


2.1.3 常用数据集(声学语料库)

2.2 语音辨识模型 汇总
语音辨识模型:(百分比为 19 年 papers 中使用各种模型的占比)
除了传统的 HNN 模型,其余都是 End-to-End 模型


2.3 LAS 模型 (Listen, Attend, and Spell)
点击查看【bilibili】
LAS:该模型就是典型的(传统的标准的)带有 attention 的 seq2seq 模型
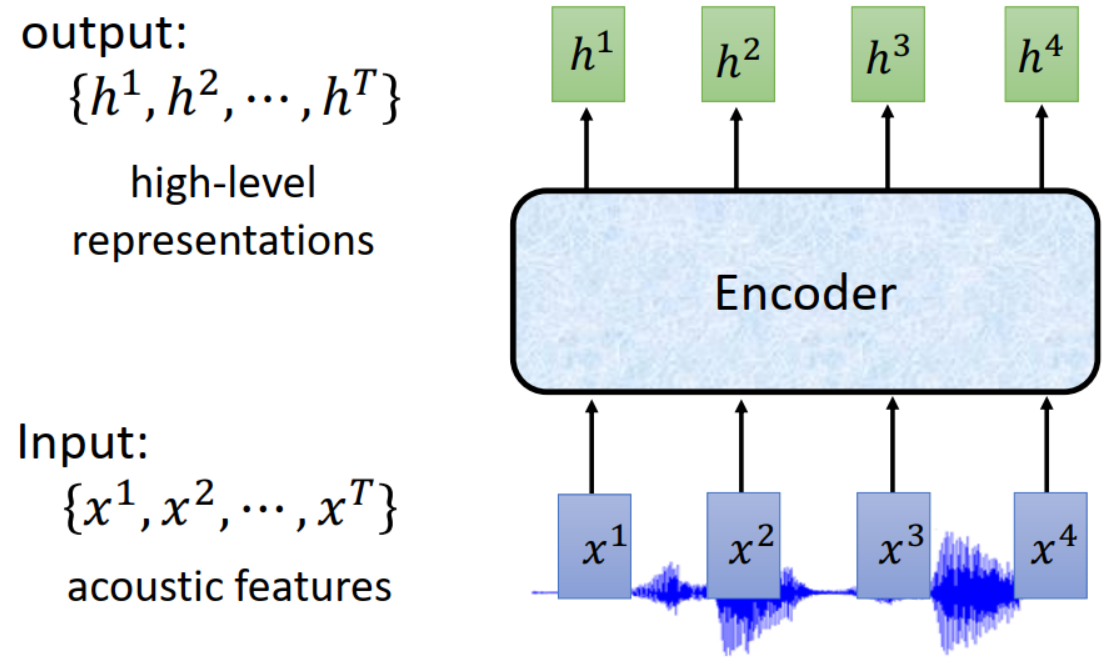
2.3.1 Listen (Encoder 编码器)
功能:
- 提取语音内容信息
- 移除不同讲述者之间的差异,移除噪声
输入:声学特征(acoustic features)

- Encoder 模型:可以是 RNN、CNN、基于自注意力的网络层等
- 输出:高级特征抽象(high-level representation)

下采样
2.1.2 输入 Acoustic Feature 中提到,一段语音信号表示成 acoustic features(声学特征向量),1 s 就有 100 帧,而且帧之间有重复,因此为了节省计算量,先对输入的声学特征向量  进行下采样
进行下采样
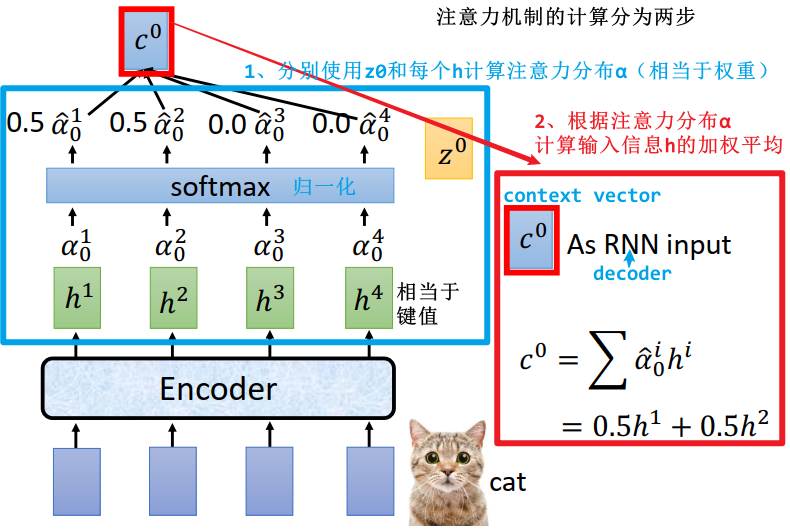
2.3.2 Attend (Attention 注意力)
两种常用的注意力机制:(可以参考 邱锡鹏 《神经网络与深度学习》 8.2 注意力机制)
- Dot-product Attention 点积模型:

- Additive Attention 加性模型:


注意力机制的两步计算过程:
- ① 在所有输入信息(encoder 的输出
 )上计算注意力分布
)上计算注意力分布  (计算方法可以是上面提到的点积模型、加性模型或其他注意力机制),并使用 softmax 对注意力分布进行归一化,得到
(计算方法可以是上面提到的点积模型、加性模型或其他注意力机制),并使用 softmax 对注意力分布进行归一化,得到  ,注意力分布可以看作权重
,注意力分布可以看作权重 - ② 根据注意力分布 α 计算输入信息(encoder 的输出
 )的加权平均,得到
)的加权平均,得到  ,称为 context vector,作为解码器(decoder,RNN)的输入
,称为 context vector,作为解码器(decoder,RNN)的输入
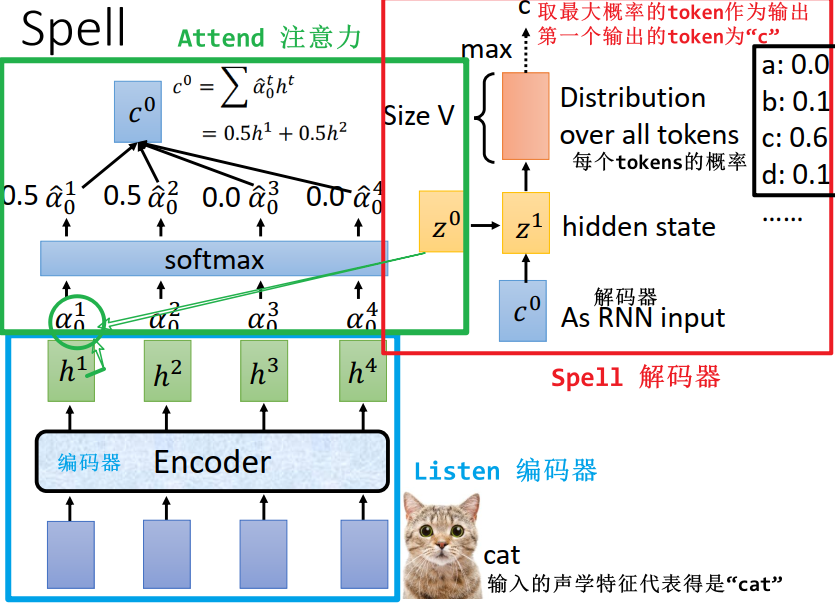
2.3.3 Spell (Decoder 解码器)
- 将
 和 context vector
和 context vector  输入到 RNN,得到隐藏层向量
输入到 RNN,得到隐藏层向量 
- 再经过一次 transform输出 tokens 的概率分布矩阵
- 取概率最大的 token 作为本次的输出,下面的例子输出第一个 token “c”
- 再用
 和编码器的输出
和编码器的输出  做 attention,得到
做 attention,得到  作为解码器的输入,得到输出 “a”
作为解码器的输入,得到输出 “a” - 以此类推,得到解码器的输出“c a t
“

束搜索
- 上面的编码器的图可以看到,上一时刻的输出(eg. “c”)是作为下一时刻解码器的输入,影响下一时刻的输出的(eg. “a”),每次选取当前时刻概率最大的的 token 作为输出,这种贪心解码并不一定能得到整体概率最高的 tokens 序列
- 但要遍历所有可能的输出序列路径也是不现实的
- 解决方法:束搜索,即每次都保留概率最高的 B 条路经(B 是束大小)

2.3.4 训练
Teacher Forcing:解码器求当前时刻的输出是受上一时刻的输出影响的,但上一时刻的输出不能保证其正确性,因此在训练的时候,不考虑上一时刻的输出,而是直接将正确答案(实际应该输出的 token)作为解码器的输入
2.3.5 Attention 的使用
Attention 的使用方式:
- Attention 得到的结果在下一时刻使用:如 2.3.3 Spell (Decoder) 中介绍的,从解码器中拿出隐藏层状态
 作为关键字,与编码器的输出
作为关键字,与编码器的输出  做 attention,得到 context vector
做 attention,得到 context vector  ,作为下一时刻解码器的输入
,作为下一时刻解码器的输入 - Attention 得到的结果在当前时刻使用:从解码器中拿出隐藏层状态
 作为关键字,与编码器的输出
作为关键字,与编码器的输出  做 attention,得到 context vector
做 attention,得到 context vector  ,直接作为当前时刻解码器的输入
,直接作为当前时刻解码器的输入 - 两者结合,Attention 得到的结果(context vector,c)既影响现在的输出,也影响下一刻的输出

Location-aware attention
- attention 最初是为了解决输入输出位置不匹配的问题(eg. 翻译),因此注意力机制关注的区域是乱跳的
- 但是语音识别中 attention 的改变应该就是从左往右的,而不是乱跳的,因此提出了位置感知的注意力(Location-aware attention)
- Location-aware attention:attention 不能乱跳,要考虑前一时刻得到的 attention 的影响
- 例如现在要用
 和
和  计算注意力
计算注意力  ,则将前一个时刻
,则将前一个时刻  的
的  以及相关的前后的一些 α(比如以
以及相关的前后的一些 α(比如以  为中心前后取一个 window 的 α)输入 transform,得到一个向量,也当作 match 函数(即 attention)的输入
为中心前后取一个 window 的 α)输入 transform,得到一个向量,也当作 match 函数(即 attention)的输入
- 例如现在要用

2.3.6 结果
- 结果:
- 随着训练语料和训练时长的增加,LAS 的效果远超传统系统。而且不仅模型优秀(错误率低),模型可以很小(0.4GB,对比传统的7.2GB),这种端到端模型的优势,使得其可以部署在手机上
- 缺点:
- LAS 必须听完整个语音输入,才能输出第一个 token,而没法实现 on-line 识别,即没法一边听,一边识别
2.4 CTC 模型 (Connectionist Temporal Classification)
点击查看【bilibili】
CTC (Connectionist Temporal Classification):解码器是线性分类器的 seq2seq 模型 
- 输入:T 个 acoustic features
- 输出:T 个 tokens
- 有时候语音信号
 可能很小,使得当前时刻暂时无法识别出说的是啥,无法输出对应的 token,就输出
可能很小,使得当前时刻暂时无法识别出说的是啥,无法输出对应的 token,就输出 
- 有时候语音信号
- 后处理:对于输出的 tokens 序列(包含
 )
)- 合并连续出现的重复 tokens(中间有
 则不能合并)
则不能合并) - 移除

- 合并连续出现的重复 tokens(中间有

2.4.1 训练时的问题
假如训练集中一条语音数据包含 4 个 acoustic features,但是其标签(即对应的文字)只有两个字,eg. “好棒”,而 CTC 要求输出的 tokens 序列长度和输入的 acoustic features 的数目是相同的,即也得输出 4 个 tokens,也就是要在“好棒”中插入两个“ ”,那怎么插才能得到正确的答案作为训练的真实标签呢?
”,那怎么插才能得到正确的答案作为训练的真实标签呢?
alignment:上面提到的,在文字中插入“ ”得到的新的 tokens 序列,eg.“好
”得到的新的 tokens 序列,eg.“好
 棒”,就称为 alignment
棒”,就称为 alignment
- 问:应该选择哪一种 alignment 作为训练数据的标签?
- 答:穷举所有的 alignments,都当作正确答案去训练
2.4.2 优缺点
- 优点:
- CTC 可以实现 on-line 识别(LAS 则不能),即一边听一边识别,而不用等听完整条语音再开始输出
- 缺点:
- 要后处理(eg. 加一个 language model)结果才能好,否则结果很惨
- 解码器每次只关注(输入)一个 vector,并且每个输出都是独立决定的。这就产生一个问题,比如三个 acoustic features 向量
 共同代表“c”,而解码器针对
共同代表“c”,而解码器针对  输出了 token “c”,针对
输出了 token “c”,针对  输出“
输出“ ”,那么后面的
”,那么后面的  就不能生成“c”了,否则最后的序列就变成了“cc”,但是由于解码器并不知道前面输出的是什么,就有可能导致这种错误情况出现
就不能生成“c”了,否则最后的序列就变成了“cc”,但是由于解码器并不知道前面输出的是什么,就有可能导致这种错误情况出现
2.5 RNA
RNA (Recurrent Neural Aligner):输入一个 acoustic feature 就输出一个 token 的seq2seq (LAS 也是)
- 将 CTC 模型解码器中的线性分类器更改为 LSTM ,使得解码器每个时刻的输出不再是独立决定的,而是受到前面时刻输出的影响

2.6 RNN-T 模型 (RNN Transducer)
RNN-T:输入一个 acoustic feature 可以输出多个 tokens 的seq2seq
- 与 RNA 相同的问题:
- alignment 问题:eg. 训练样本为“
 ,好棒”,那么要给“好棒”插入 4 个“
,好棒”,那么要给“好棒”插入 4 个“ ”
”- 穷举所有可能的 alignments 用于训练
- alignment 问题:eg. 训练样本为“
- 与 RNA 的区别
- 使用额外的 RNN(称为 语言模型 Language Model):忽略语音,只关注 tokens,但忽略输入

- 只将 tokens 当作输入(即只关注 token 与 token 之间的关系),因此可以先用大量文字转化为 token 去训练 RNN,而文字数据容易获取(文字数据中不含
 )
) - 对训练至关重要:RNN-T 训练时要穷举所有 alignments,这就需要模型内部有一个忽略
 的
的
- 只将 tokens 当作输入(即只关注 token 与 token 之间的关系),因此可以先用大量文字转化为 token 去训练 RNN,而文字数据容易获取(文字数据中不含
- 对于一个输入,解码器可以输出多个 tokens。对于每一个输入,最后输出
 代表输出结束,请求输入下一帧
代表输出结束,请求输入下一帧- T 个 输入就有 T 个
 输出,当然最终(后处理)要移除
输出,当然最终(后处理)要移除 
- T 个 输入就有 T 个
- 使用额外的 RNN(称为 语言模型 Language Model):忽略语音,只关注 tokens,但忽略输入

2.7 Neural Transducer 模型
Neural Transducer:相当于每次输入一个 window 的 RNN-T
- CTC,RNA,RNN-T 都是每次只读一个 h 来进行输出,效率不够高,而 Neural Transducer 一次读一个窗口的输入,然后在这个窗口内做 attention,由 attention 决定选择哪些进入 RNN 输出

- window 大小和使用 attention 对 Neural Transducer 错误率的影响:
- 若不使用 attention,就很容易烂掉

2.8 MoChA 模型 (Monotonic Chunkwise Attention)
MoChA (Monotonic Chunkwise Attention):相当于移动伸缩自如的 Neural Transducer
- 自由决定窗口的大小(移动窗口),而 Neural Transducer 的窗口大小是固定的


2.9 传统的语音识别系统 HMM(Hidden Markov Model) 隐马尔可夫模型
在过去还没有 deep learning 的时候,HMM 被广泛使用(其实现在仍常被使用)
2.9.1 语音识别系统 P(Y|X)→声学模型 P(X|Y) & 语言模型 P(Y)

语音识别系统是在给定输入声学特征向量 X 的情况下,给出概率最大的 tokens 序列 Y
 (贝叶斯公式分解,P(X) 无关可忽略)
(贝叶斯公式分解,P(X) 无关可忽略)- 声学模型 Acoustic Model
 :以前通常采用 HMM 建模
:以前通常采用 HMM 建模 - 语言模型 Language Model
 :
:
2.9.2 HMM: P(X|Y)→P(X|S)
- S:HMM 将 tokens 序列 Y 进一步分解为更小的状态(state)序列 S


- S→X:由状态序列 S 产生声学特征向量 X,需要知道两个概率:
- ① 状态转移概率(Transition Probability):跳转到下一个 state 的概率
- ② 输出概率(Emission Probability):给定一个 state,产生某个样子的 acoustic feature 向量的概率

- P(X|S):
 ,即所有可能的 alignment 的概率相加
,即所有可能的 alignment 的概率相加- alignment:state 序列(短)和声学特征序列 X(长)的匹配,也就是说多个连续的声学特征向量对应一个状态,哪个状态生成哪几个向量,每个有效排列就是一个 alignment


2.9.3 深度学习在 HMM 中的应用
- 方法一:Tandem

- 方法二:DNN-HMM Hybrid

2.10 HMM,CTC,RNN-T 的 4 个问题汇总
点击查看【bilibili】
语音识别的目标就是要求  ,Y 是输出的 tokens 序列,X 是输入的 acoustic features
,Y 是输出的 tokens 序列,X 是输入的 acoustic features
- 上一节提到传统的 HMM 是要先求出
 ,再间接地通过贝叶斯公式求得
,再间接地通过贝叶斯公式求得 
 ,因此存在 alignment 问题
,因此存在 alignment 问题
- 而现今的 End-to-End 模型,都是直接计算

- LAS:
 ,可以直接计算
,可以直接计算 - CTC & RNN-T:
 ,也存在 alignment 问题
,也存在 alignment 问题
- LAS:


HMM,CTC,RNN-T 都有 alignment 问题,这又可与拆解为 4 个问题:
- 如何穷举所有可能的 alignments?
- 如何把所有的 alignments 的概率相加?
- 怎么训练?CTC,RNN-T 用的是梯度下降,目标函数是
 ,如何计算将 alignments 加起来的梯度
,如何计算将 alignments 加起来的梯度  ?
? - 怎么测试(推断 inference 和解码 decoding)?
 ,如何找到最优的 Y?
,如何找到最优的 Y?
2.11 Q1:如何穷举所有 alignments?
HMM、CTC、RNN-T 都有特定的机制,将输出的长为 N 的 tokens 序列与输入的长为 T 的 acoustic features 序列进行匹配,即把 tokens 序列扩展为 alignments(比如一段语音实际上代表的是“cat”,在HMM中为了匹配长度为 T 的输入向量序列,将其扩展为长度为 T 的 alignments,eg. “ccaaat”),作为训练时该输入的标签,使得能够进行训练
如何穷举所有的 alignments?
2.11.1 HMM:重复至长度 T
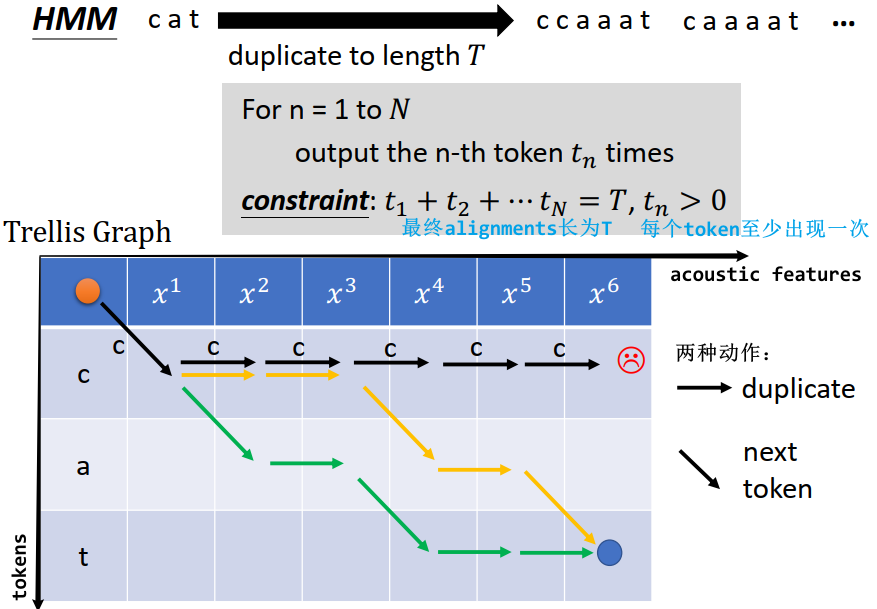
2.11.2 CTC:重复 or 加 Φ 至长度 T

遍历所有 alignments 的伪代码:
output "φ" c0 timesFor n=1 to Noutput the n-th token tn timesoutput "φ" cn times限制:t1 + t2 + ... + tN + c0 + c1 + ... + cN == T, tn > 0, cn ≥ 0

2.11.3 RNN-T:加 T 个 Φ


2.12 Q2:如何累加各 alignment 对应的概率(RNN-T 为例)?
点击查看【bilibili】
2.10 HMM,CTC,RNN-T 的 4 个问题汇总 一节中提到,语音识别的目标是求  ,Y 是输出的 tokens 序列,X 是输入的 acoustic features
,Y 是输出的 tokens 序列,X 是输入的 acoustic features
- 传统的 HMM 是要先求出
 ,再间接地通过贝叶斯公式求得
,再间接地通过贝叶斯公式求得 
- 而现今的 End-to-End 模型,都是直接计算

- CTC & RNN-T:
 ,也存在 alignment 问题
,也存在 alignment 问题
- CTC & RNN-T:

上一节,介绍了如何穷举 HMM、CTC、RNN-T 的 alignments,而实际上我们还需要计算各 alignments 对应的概率之和(如上面的公式所示)
以下,都以 RNN-T 为例,介绍如何计算各 alignment 对应概率的累加和:
对于一个 alignment(一条路径)h = Φ c Φ Φ a Φ t Φ Φ:
计算对应概率 

- 计算一个 alignment(一条路径)对应的概率:

表格中每个格子对应一个固定的概率分布,不受到达这个格子的路径的影响
- 因为RNN-T 中用额外的 RNN 处理 token 与 token 之间的关系,但忽略
 ,所以每个格子代表的概率分布不受路径的影响
,所以每个格子代表的概率分布不受路径的影响  :由 acoustic feature
:由 acoustic feature  作为输入(即已经输出 i-1 个
作为输入(即已经输出 i-1 个  ,或者说已经读取 i 个 acoustic features),已经输出 j 个 tokens
,或者说已经读取 i 个 acoustic features),已经输出 j 个 tokens

计算所有 alignments(所有路径)对应的概率和:
 :表示所有已经读取 i 个acoustic features,并且已经输出 j 个tokens 的 alignments(路径)的概率和
:表示所有已经读取 i 个acoustic features,并且已经输出 j 个tokens 的 alignments(路径)的概率和- 计算方式举例:

- 计算方式举例:
- 用动态规划算法,一直从左上角计算到右下角,就得到了所有 alignments(所有路径)对应的概率累加和

2.13 Q3:如何训练 (RNN-T 为例)?
- 训练的目标是:

- 而

- 对于 alignment h = Φ c Φ Φ a Φ t Φ Φ,

- 对于 alignment h = Φ c Φ Φ a Φ t Φ Φ,
- 如何计算梯度


上面表格中每一个箭头到代表梯度计算中的其中一个元素,比如对于  这个箭头,其贡献的梯度计算为
这个箭头,其贡献的梯度计算为  ,这两项梯度求法如下(分为两部分):
,这两项梯度求法如下(分为两部分):
- 第一部分:计算
 :下图左半部分所示
:下图左半部分所示

- 第二部分:计算
 :由上图右半部分可知,问题最终变为如何求
:由上图右半部分可知,问题最终变为如何求
 :从已读入 i 个 acoustic feature 并输出 j 个tokens 的情况出发,走到结尾,所有 alignments(即所有路径)对应的概率和(和
:从已读入 i 个 acoustic feature 并输出 j 个tokens 的情况出发,走到结尾,所有 alignments(即所有路径)对应的概率和(和  相反)
相反)- 计算举例:

- 计算举例:



2.14 Q4:如何测试/解码(以RNN-T为例)?
- 语音识别的目标是找到
 ,即找到概率最大的 Y 作为辨识结果
,即找到概率最大的 Y 作为辨识结果 - 理想情况:
 ,即比较每一个 Y 的 alignments 的概率和,选取最大概率的 Y 作为识别结果
,即比较每一个 Y 的 alignments 的概率和,选取最大概率的 Y 作为识别结果 - 现实情况:
 ,即比较每一个 Y 的最大的 alignment 概率,选取最大概率的 Y 作为识别结果
,即比较每一个 Y 的最大的 alignment 概率,选取最大概率的 Y 作为识别结果

- 找概率最大的 alignment 的两种方法:

- 贪心法:每一时刻输出概率最大的 token
- 束搜索:
2.15 语言模型 Language Model
点击查看【bilibili】
上文提到的语言模型:语言模型 P(Y)
语言模型  :用来估计 tokens 序列
:用来估计 tokens 序列  的概率
的概率 
2.15.1 为什么要用语言模型
语言模型  是用来估计 tokens 序列的概率:
是用来估计 tokens 序列的概率:
- HMM 模型:
 ,因此要用到语言模型
,因此要用到语言模型 
- LAS 等深度学习的端到端模型:可以直接求 P(Y|X),

- 理论上不再需要语言模型
 了,但实际上直接乘上
了,但实际上直接乘上  通常能提升模型性能(即
通常能提升模型性能(即  )
) - ① 因为语言模型
 只需要使用大量文字即可估测,无监督的数据很容易获得(可以说是有无限大的语料),容易训练的好(比如一个巨大的LM:BERT 用了30亿个以上的词来训练);而
只需要使用大量文字即可估测,无监督的数据很容易获得(可以说是有无限大的语料),容易训练的好(比如一个巨大的LM:BERT 用了30亿个以上的词来训练);而 需要成对的数据(即有标注的语音)用于训练,不容易估测好
需要成对的数据(即有标注的语音)用于训练,不容易估测好 - ② 强大的语言模型(eg. BERT)能自动学到词性标注、分词、句法分析、指代消解等前处理任务,通过特征提取 or fine-tune 就能用于提升下游任务的表现
- ③ 强大的语言模型能减少处理不同 NLP 任务所需的架构工程成本。以往一般会根据不同 NLP 任务的性质,设计一个最合适的模型架构来解这个特定的 NLP 任务,而设计这些模型并测试其 performance 是非常耗时耗力耗计算资源的。而 BERT 等强大的语言模型可以实现使用一个通用架构处理各式 NLP 任务。通过两阶段迁移学习: a) 使用 Transformer Encoder、大量文本以及两个预训练目标,事先训练好一个可以套用到多个 NLP 任务的通用的 BERT 模型; b) 将该模型拿来做特征提取 or fine tune 各式下游(监督式)任务。预训练步骤和 fine-tune 步骤所用的 BERT 模型是一模一样的,因此学会 BERT 就能使用同个架构训练各式 NLP 任务,大大减少自己设计模型架构的成本 (参考:進擊的 BERT:NLP 界的巨人之力與遷移學習)
- 理论上不再需要语言模型
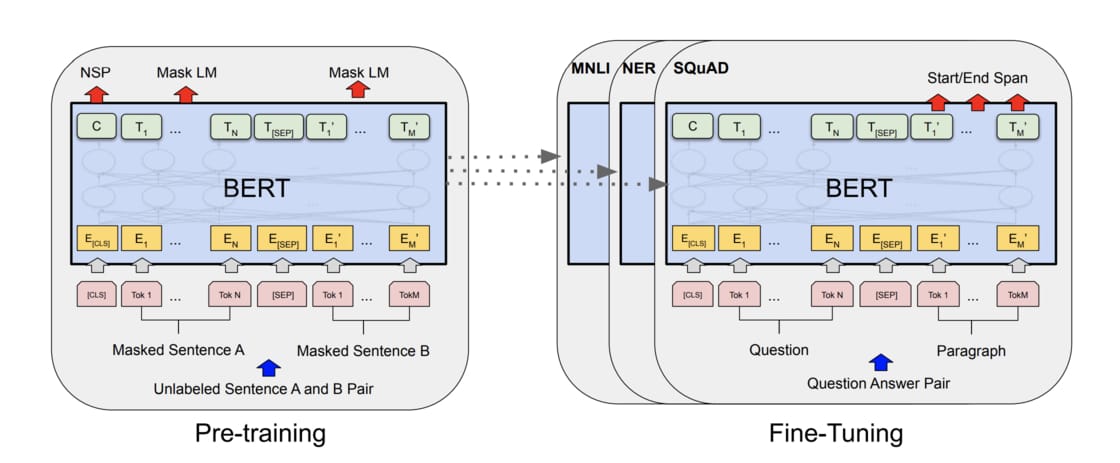
- 实际上,1 深度学习与人类语言处理 DLHLP 介绍 中提到的 6 种人类语言处理任务,只要输出是文字(语音 → 文字,文字 → 文字),往往加上语言模型
 就有用
就有用
2.15.2 语言模型汇总:如何估测一个 token 序列的概率 P(Y)?
即如何使用语言模型? or 有哪些语言模型
2.15.2.1 N-Gram 语言模型/统计语言模型
N-Gram:深度学习之前常用的预测 token 序列概率的传统方法
给定一个 token 序列  ,估测
,估测 
- 最直接的方法是直接令

- 但是 token 序列在语料库中往往出现的次数为 0,但不能认为它的概率为0
- 改进:N-Gram
- N-Gram:将 token 序列的概率拆解为前后条件概率的乘积
- eg. 2-Gram:

- eg. 2-Gram:

N-Gram 的问题:即使将 token sequence 的概率拆解成了多项概率的乘积,由于数据稀疏性,收集的语料库仍远远不够准确计算一个 token sequence(句子)出现的概率,尤其是当 N 的值设置的较大时
- 解决办法:Language Model Smoothing(平滑):给 N-Gram 中值为 0 的概率赋予一个小的非零概率
Continuous LM——一种语言模型的平滑技术 Language Model Smoothing
Continuous LM 是借鉴了推荐系统的思想,利用矩阵分解来估测表格中填 0 位置的实际值
借鉴推荐系统的思想:”dog” 和 “cat” 的词向量
是相似的,而
的概率较大,那么
的概率也应该较大,即使语料库中并没有出现 “dog jumped”
- 将每个词汇都对应一个词向量,横轴的词汇是第一个词汇,记为
 ,纵轴的词汇是第二个词汇,记为
,纵轴的词汇是第二个词汇,记为  ,用来进行训练。词向量
,用来进行训练。词向量  和
和  相当于输入模型的训练数据 X,而对应的表格项
相当于输入模型的训练数据 X,而对应的表格项  就是对应的标签值 Y
就是对应的标签值 Y - 训练的目标是最小化
 和
和  的乘积和
的乘积和  之间的差异
之间的差异 - 训练后的模型去估测表格中每个项的值,代替原值

因此,Continuous LM 可以看作含有一层隐藏层的神经网络模型,当然也就可以扩展到更深层的神经网络,即深度学习
2.15.2.2 NN-based LM 神经网络语言模型
NN-based LM(神经网络语言模型)最早是想取代 N-Gram 语言模型
RNN-based LM
借助于 RNN/LSTM 的特性,相当于可以让 N-Gram 的 N 设置的很大,即可以用很长的前缀预测下一个 token 的概率
更进阶的语言模型:ELMO、BERT、GPT
2.15.3 如何用语言模型提升 LAS
如何用语言模型提升现今基于神经网络的端到端的语音识别模型?下面以 LAS 模型为例
语言模型和 LAS 的结合可以分为三种:
- Shallow Fusion 浅融合:语言模型和 LAS 模型都已训练好,在两个模型的输出端进行结合
- Deep Fusion 深度融合:语言模型和 LAS 模型都已训练好,在两个模型的隐藏层结合(需要另外训练一个网络来输出分布)
- Cold Fusion 冷融合:训练好的语言模型 + 没有训练的 LAS(需要从零开始训练),在两个模型的隐藏层结合(需要另外训练一个网络来输出分布)

Shallow Fusion

Deep Fusion

Cold Fusion


若有收获,就点个赞吧
0 人点赞
