跨平台特性
“一次编写,到处运行”
跨平台特性如何实现的?
通过不同版本和平台的JVM,将字节码文件编译成不同机器代码。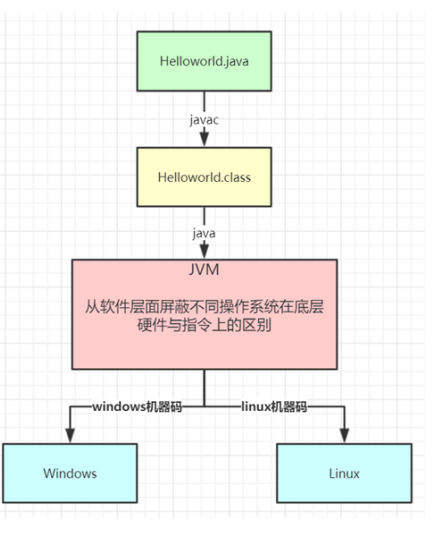
三大组成
类装载子系统 + 运行时数据区(最核心) + 字节码执行引擎
运行时数据区(内存模型)
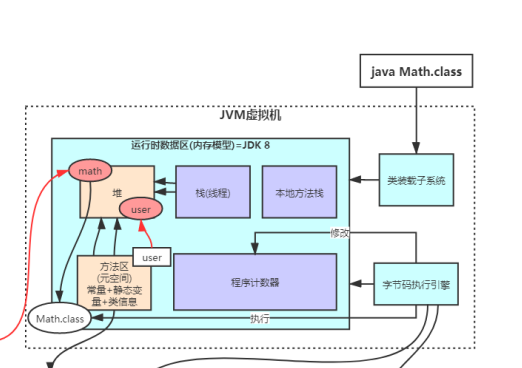
栈(线程)
之所以叫线程栈,是因为会为不同的线程分配不同的空间来存储局部变量。不同线程之间是互不干扰的。
栈帧
即为每个方法分配的一块内存空间。
栈帧内主要放以下数据:
- 局部变量表(存局部变量的);
- 操作数栈(存数值的);
- 动态链接
- 方法出口,存放方法执行完之后,要返回到哪里接着执行的信息;
为什么是栈结构?
因为和程序调用的逻辑很吻合,例如main方法中调用了compute方法,那么首先,
- main入栈,compute入栈,
- compute调用结束,compute出栈,
- main方法调用结束,main出栈。
程序计数器
其实和计数无关,是用来保存当前执行或者即将要执行的下一条指令的地址。
为什么需要程序计数器?
因为JAVA中存在多线程,在A线程执行的过程中,如果B线程抢走了CPU,等回到A线程时,需要知道接下来执行的指令的地址,因此需要用程序计数器保存下来。这里也可以看出来,每一个线程都有自己的程序计数器。
堆
堆主要用来存放new出来的对象。
结构如下: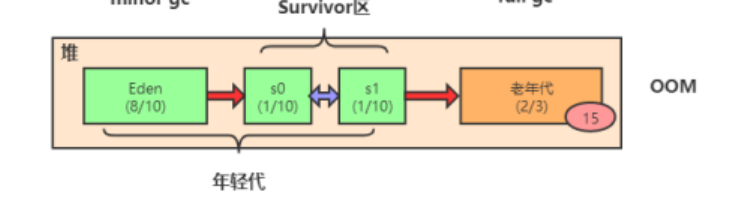
即年轻代 + 老年代。年轻代由Eden区 + Survivor区组成。
对象会不停的放进Eden区,当Eden区满了以后,触发minor gc. minor gc 会尝试回收年轻代中的垃圾。
堆和栈的关系
栈中可能要用到某个对象,该对象是存放在堆中的,栈里只保存该对象的内存地址。
方法区
主要放置常量(final修饰),静态变量(static修饰)以及类信息。
本地方法栈
用来保存本地方法(native修饰)
本地方法栈同样也是每个线程一份
GC的过程
GC主要涉及到的是堆,因为GC是回收垃圾对象,次要涉及方法区。
Minor GC
触发条件: 对象会不停的放进Eden区,当Eden区满了以后,触发minor gc. minor gc 会尝试回收年轻代中的垃圾。
过程:
通过可触达分析算法,即通过GC root往下找,能触达的对象标记为不是垃圾,其他的不能触达的对象将被回收。不是垃圾的对象将会移动到s0或者s1中(来回移动)。此外,每经历一次minor gc, 这些不是垃圾的对象的年龄会加1, 当年龄到达15时,如果还没被回收,就会被移动到老年代。
Full GC
触发条件:老年代满了
过程:和Minor GC差不多,只是回收整个堆以及方法区
Stop the word (STW)
即在执行GC时,会停止用户的所有线程,因此用户会觉得卡顿。那么如果GC次数越多,耗时越长,用户体验越差。
既然如此,为什么要有STW?
反过来想,如果没有STW,用户的线程和GC并行,那么某一些数据不会被标记为垃圾,因为可能正被GC ROOT 引用着,然而当用户线程结束时,这些数据应该被释放掉,但是因为没有被标记为垃圾,所以GC不会回收这部分数据。因此,需要STW来应对这种情况。
内存参数设置
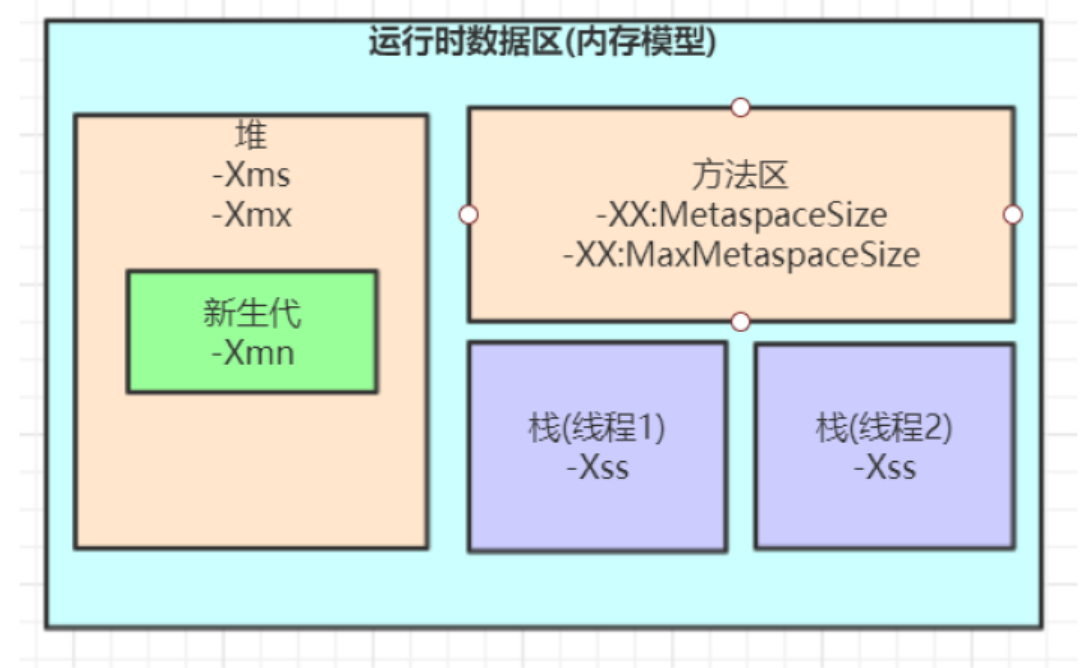
java ‐Xms2048M ‐Xmx2048M ‐Xmn1024M ‐Xss512K ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐jar microservice‐eureka‐server.jar

若有收获,就点个赞吧
0 人点赞
