G1(JDK 9 默认收集器)
G1主要是针对多颗处理器以及大容量内存的机器。
G1在物理概念上已经没有分区的概念,即没有物理意义上的的年轻代和老年代。
G1可以通过设置参数-XX: MaxGCPauseMilis来指定一次GC的最大停顿时间,从而避免长时间STW的发生。例如,设置200ms。
而是转化成了逻辑上的老年代和年轻代
: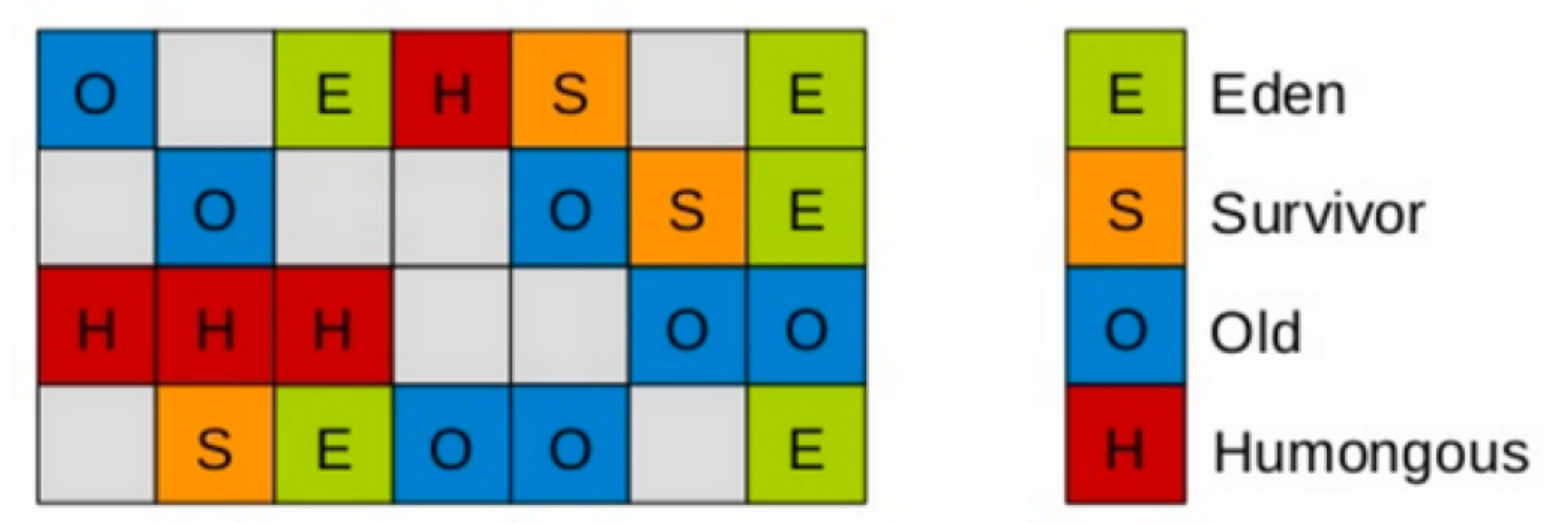
G1将JAVA划分成多个大小相等的区域(region),JVM最多有2048个Region. 每个Region不是固定的,可能会发生变化,即现在是老年代,将来可能会变成年轻代。
此外,还有H代表Humongous来保存大对象。如果一个大对象超过了一个region的50%,那么就会被放入Humongous中。
年轻代默认5%,可以通过“-XX: G1NewSizePercent”设置年轻代的比例,但是最多不能超过60%。 年轻代中的Eden和Survivor仍然遵循8:1:1.
G1的垃圾回收流程
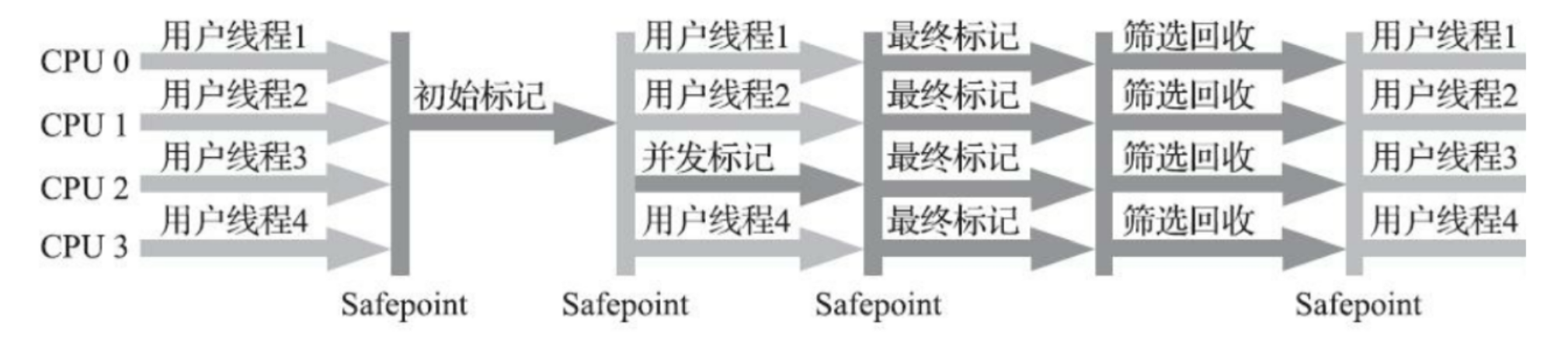
四个步骤:
- 初始标记(STW),标记GC roots能直接引用的对象,很快;
- 并发标记,同CMS;
- 最终标记(STW),同CMS的重新标记;
- 筛选回收(STW):用户可以设置STW停顿时间,JVM会对各个Region的回收价值和成本进行排序,然后根据用户设置的停顿时间来决定要制定回收计划。因此该步骤并不会回收所有需要回收的Region。此外,采用了复制算法,相比于CMS的标记清除算法,不会产生太多的内存碎片。;
为什么筛选回收不做并发?
首先,用户可以控制STW的时间,其次,停顿用户线程可以大大提高回收效率。
如果设置的停顿时间不够对进行垃圾回收怎么办?
G1不一定会回收所有的垃圾,它会根据设置的时间进行估算,例如只够回收1/3的垃圾,那就只回收那1/3的垃圾。另外剩余的2/3等下一次GC来进行回收。
如何做筛选?
G1会维护一个优先列表,例如,如果某个Region花200ms回收10M垃圾,另一个Region花50ms回收20M垃圾,在回收时间有限的条件下,G1肯定会优先选择后面的Region进行回收。
G1垃圾收集分类
Yong GC
- Eden区满了以后,并不一定会触发Young GC;
- G1会判断此次Young GC需要的时间,如果接近设定的回收时间(默认200ms),才会触发Young GC;
- 否则,给年轻代增加空间;
因此,在G1下,年轻代的空间大小是动态变化的。
Mixed GC
- 不是Full GC;
- 老年代的堆占有率达到参数(-XX: InitialtingHeapOccupancyPercent)设定的值触发;
- 回收所有的Young区和部分Old区以及大对象区。
- 采用复制算法,把各个region中存活的对象拷贝到其他Region中去;
- 如果在拷贝的过程中,发现没有足够的空Region能够承载拷贝对象,触发一次Full GC。
Full GC
- 停止系统程序,单线程进行标记、清理和压缩整理,
- 从而空闲出来一批Region来供下一次MixedGC使用,
- 非常耗时。
G1的一些特有的参数
-XX: InitiatingHeapOccupancyPercent
老年代占用空间达到整堆内存的阈值(默认45%),则触发Mixed GC。
举个例子:
有100格子,如果其中45个都变成了老年代,则触发Mixed GC。
-XX: G1MixedGCThresholdPercent
Region中存活对象小于这个值时,才会回收该Region(默认85%);
-XX: G1MixedGCCountTarget
在一次回收过程中指定做几次筛选,默认为8次。即回收一会,暂停一会,反复八次。
G1适用场景
- 8GB以上的堆内存(建议值);
- 50%以上的堆被存活对象占用;
- 对象分配和晋升的速度变化非常大;
- 垃圾回收时间特别长,超过1秒;
- 停顿时间500ms以内。
每秒几十万并发系统如何优化JVM
对于Kafka这种支持高并发的系统,每秒可能需要处理几十万的消息,因此会使用大内存机器,例如64G。
此时,如果仍然采用CMS,那么Young GC可能也需要花费较长时间。因为内存大,需要回收的对象多,消耗的时间就长。
因此,对于这种情况就需要使用G1收集器,设置停顿时间为50ms,每50ms就回收3~4G的内存,卡顿50ms对用户来说基本上没有感知,从而改善用户体验。
ZGC
这个收集器现在并没有多少人用。

若有收获,就点个赞吧
0 人点赞
