缓存穿透
概念
去查询一个根本不存在的数据,这个数据既不在缓存中,也不在数据库中,这就会导致每次查询都会穿透缓存,直接去查数据库。当这种查询非常多的时候,就会导致大面积缓存穿透,增大数据库的压力。
解决方案
缓存空对象
原理:
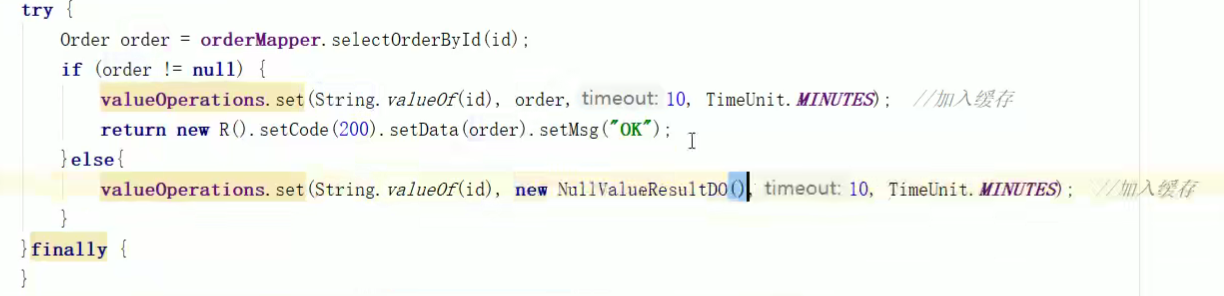
不管数据库里存不存在这条数据,我们都把其加入到缓存:
- 如果存在,就把那个对象加入缓存
- 如果不存在,就把空对象加入缓存。
那么下次该查询再过来的时候,缓存里就有该对象了,就能防止其去查询数据库。
优点:
- 代码简单
缺点:
- 效果不好
- 只能解决1个key多次访问的问题,不能解决多个key都为空的问题(仍然会在第一次去查询数据库)
- 会导致redis中有大量的空数据,占用了redis的空间
布隆过滤器(互联网公司多用这个)
应用:
- 创建布隆过滤器对象,先将其大概理解成一个特殊的List

最后一个参数为误判概率,不能定义成0。
- 通过put方法将key放入

- 判断key是否在布隆过滤器中
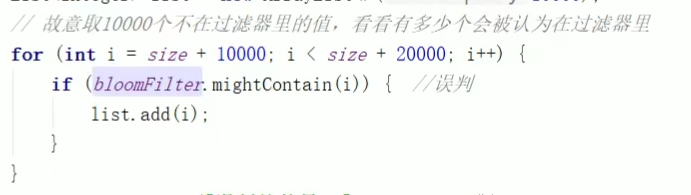
注意事项:
- 布隆过滤器只有Put和判断是否可能存在(mightContain)的方法;
- 判断是否存在的方法,有可能会误判,即将不存在判断为存在。
原理
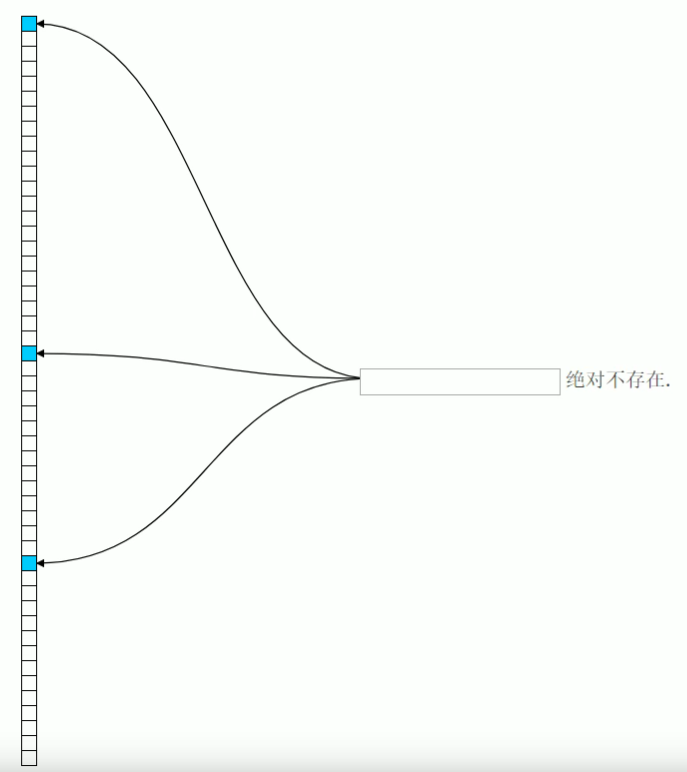
- 底层依赖于一个bit数组,每一位要么是0,要么是1
- 通过put方法设置值时,会有多个hash算法对key进行hash,现在假设是3个hash算法;
- hash后得到一个数值,对数组长度进行取余,得到下标,将对应下标的bit改为1;
- 三个不同的hash函数,得到三个不同的下标, 均改为1。
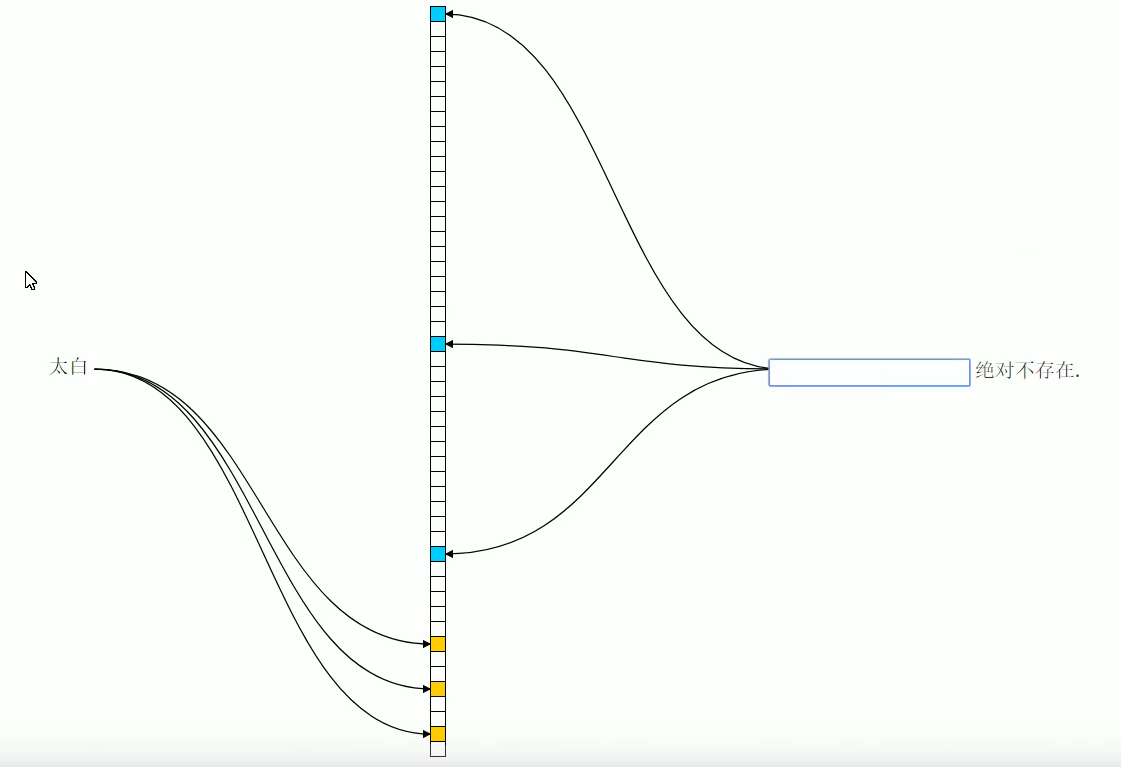
- 当调用mightContains函数时,同样进行hash和取余的操作,拿到对应的下标,判断其位置上是否为1;
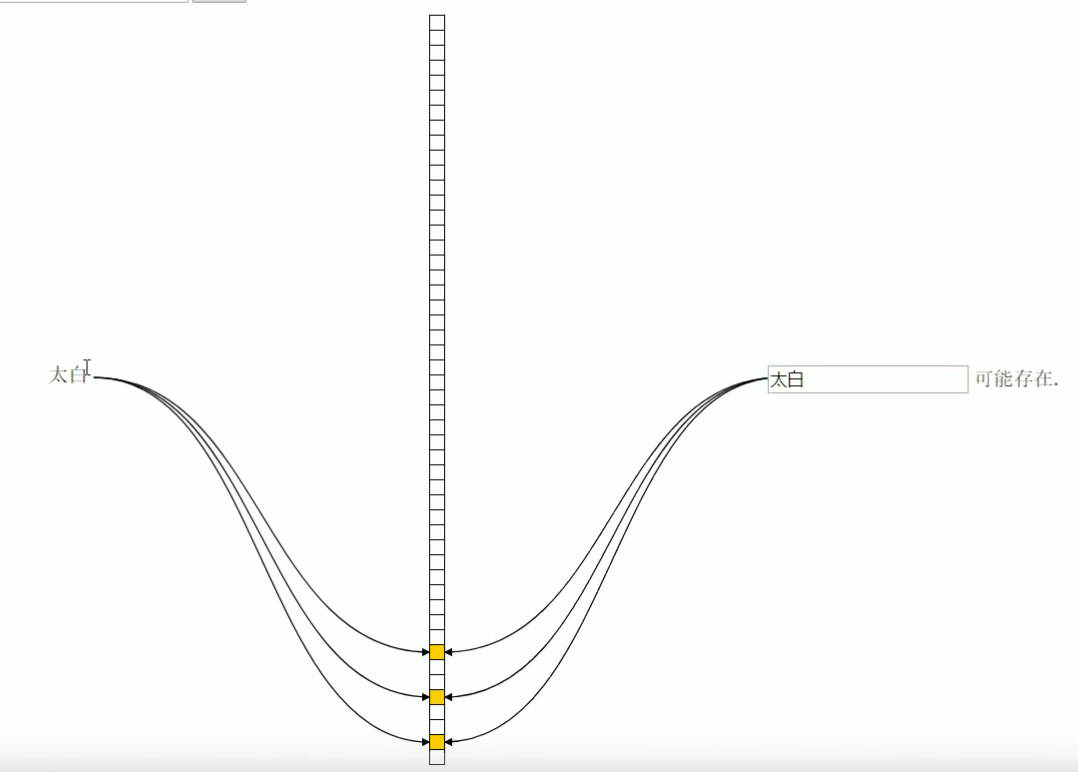
之所以出现误判,是因为当我们添加的值很多的时候,很多位置都被设置为了1,那么查询一个不存在的值,也有可能发现对应的索引位置是1,导致误判。如下图,111并不存在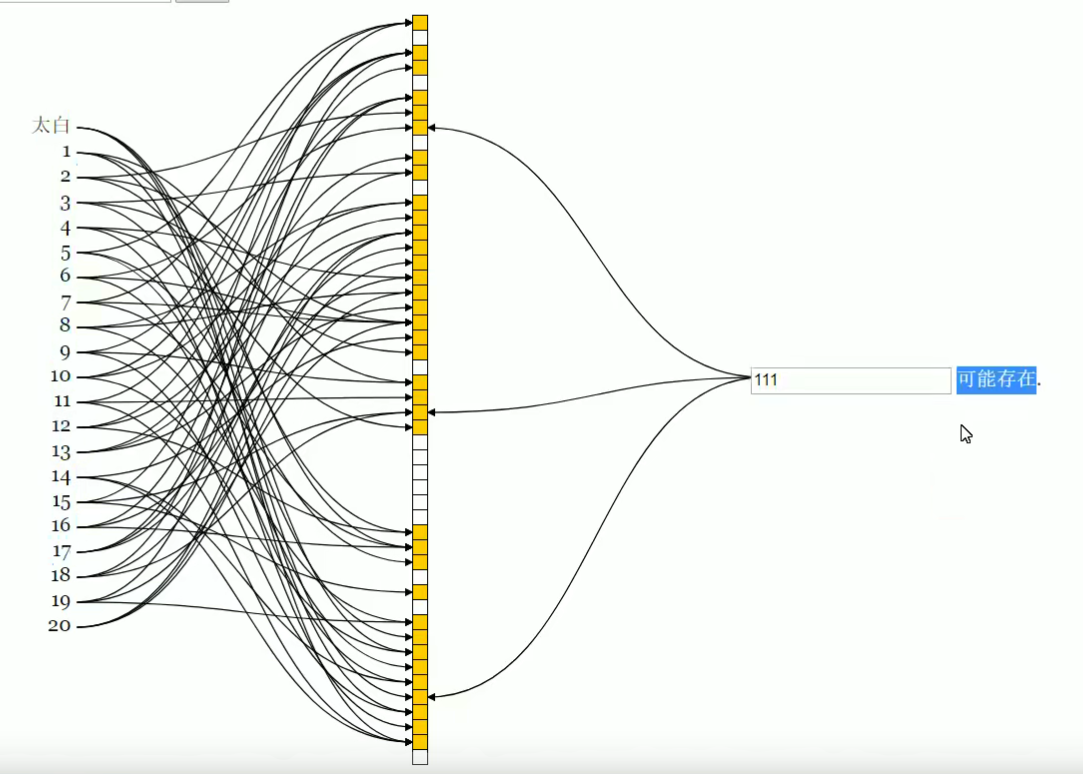
误判率和哈希函数的数量以及数组长度都有关系。
为什么我们要自己手写布隆过滤器
因为谷歌的布隆过滤器框架用的是JVM内存,一旦发生停电之类的问题,数据完全丢失;
但是我们自己手写的时候用的是redis内存,redis自带持久化,例如RDB或者AOF,不会将所有数据丢失,最多丢失一部分。
实际场景运用
- 首先,将Mysql中的所有订单Id添加到布隆过滤器中,例如1 ~ 100000;
- 当查询过来的时候,先去布隆过滤器中查找
- 如果不存在该id,则直接返回不存在;
- 如果存在该id,说明数据库中存在该数据,接着往下走;
- 接着往下走,如果redis缓存中有,即直接返回;
- 如果没有,就去读数据库读取,并写入缓存中。
优点:
- 效果好
缺点:
- 代码复杂
- 维护成本变高,每次在数据库中添加一个新的数据,就需要同步更新布隆过滤器中的数组;
- 当删除了数据库中的很多数据时,因为布隆过滤器没有删除的操作,所以要考虑重新生成布隆过滤器的list,因此我们可以考虑设置定时任务,每过一段时间重新生成布隆过滤器的list。
缓存击穿
概念
主要指的是热点数据的访问,缓存中没有该数据,某个热点数据的访问就全访问到了数据库,导致数据库压力非常大,就击穿了某个点。
数据库有该数据,但是缓存中没有该数据。
- 例如某个数据从来没有被访问过,也就不会添加到缓存中。(不会导致缓存击穿)
- 数据刚好失效,例如刚好到过期时间了。该热点数据就会导致缓存击穿。
解决方式
采用分布式锁。
- 在访问数据库前上锁;
- 加上一次查询缓存的代码;
- 查询数据库,并添加到缓存;
- 解锁。
线程分析:
- 线程1首先拿到锁,其他线程等待
- 线程1访问缓存,缓存中没有,查询数据库;
- 数据库中有,写入缓存并返回该对象。
- 解锁
- 线程2拿到锁;
- 线程2查询缓存;
- 拿到被缓存1写入的缓存对象;
- 直接返回,不走数据库;
- 后续线程逻辑和线程2一样。
这样就只会访问一次数据库。
缓存雪崩
概念
大部分缓存数据同时失效的问题,例如:
- 对于100W条数据同时设置相同的过期时间,那么在某个时间点,对这些数据的访问全部会落到数据库上。
- Redis挂了。
解决办法
对于redis挂了这个问题,需要搭建Redis高可用集群,一个挂了我还有好多个备份呢!
对于相同过期时间的问题,错开数据过期时间。
如果已经出现了雪崩
那么就需要降级熔断

若有收获,就点个赞吧
0 人点赞
