为什么有哨兵模式了,还要用Redis Cluster集群?
哨兵模式有一些缺陷,例如:
- Master宕机后,切换新的Master需要花一定的时间,导致这段时间无法提供访问;
- 哨兵的配置略微复杂,性能和高可用性表现一般;
- 哨兵模式下,只有一个主节点对外提供服务,没法支持很高的并发;
- 单个主节点的时候,内存也不宜设置的过大,否则会导致持久化文件过大,影响数据恢复和主从同步的效率。
因此,小型互联网公司使用哨兵模式还凑合,但是大型互联网公司需要采取Redis Cluster集群。
Redis Cluster集群结构
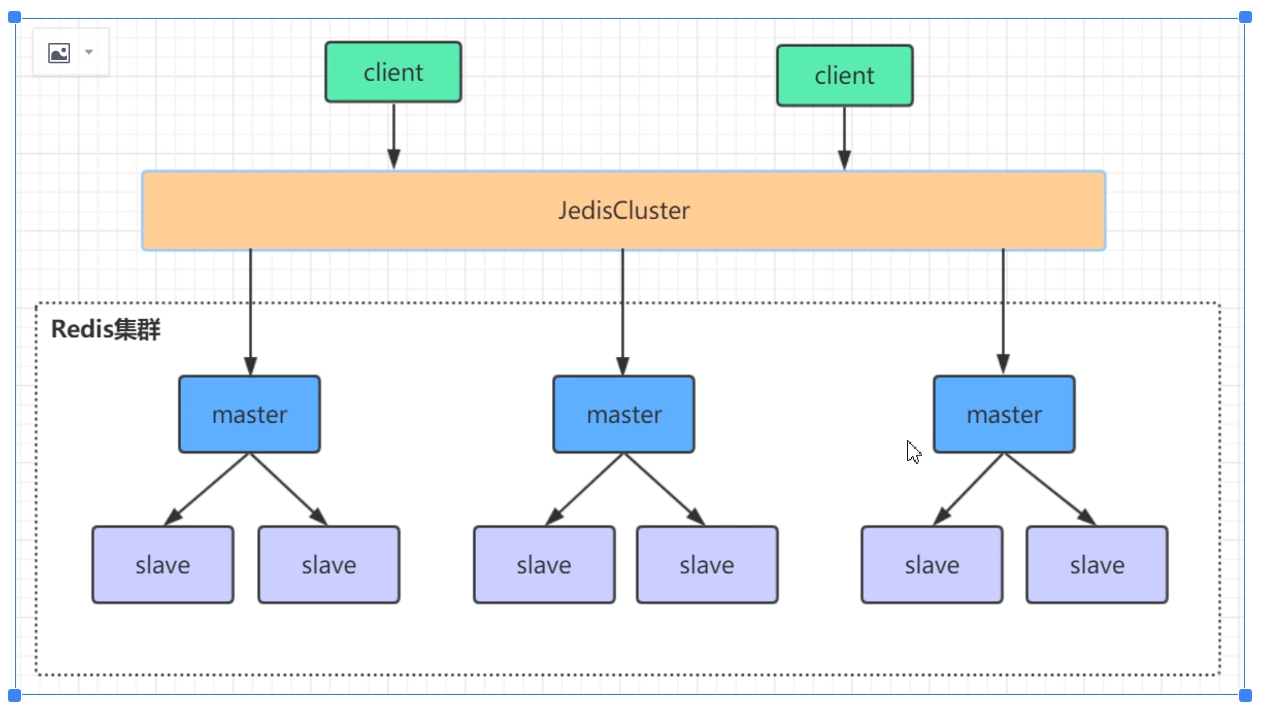
- 数据分片存储,每一个小集群里存的数据是不重复的;
- 要求至少三个主结点。
Redis Cluster集群配置
- 修改配置文件
```bash
port 8001
dir /usr/local/redis-cluster/8001
cluster-enabled yes
cluster-config-file nodes-8001.conf
cluster-node-timeout 5000
注释bind
127.0.0.1
protected-mode no appendonly yes
如果需要设置密码
requirepass 123456 masterauth 123456
其他实例也做相应的修改。2. 启动redis-server:```bashredis-server redis-8001.conf
如果发现redis-server没有启动成功,那么就去看日志文件,例如我这里看到如下问题:
说明没有这个文件夹,那么手动创建就好了。
创建好文件夹后,重新启动,发现启动成功了。
- 对三台虚拟机都进行配置,每台虚拟机起两个实例。
- 通过命令来形成集群
redis-cli -a 123456 --cluster create --cluster-replicas 1 192.168.31.27:8001 192.168.31.27:8002 192.168.31.147:8001 192.168.31.147:8002 192.168.31.118:8001 192.168.31.118:8002
- -a后面跟密码
- —cluster-replicas后面的1表示1个从节点
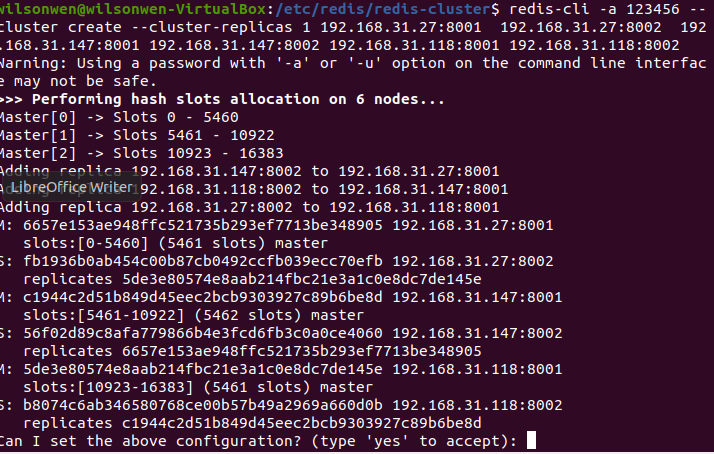
输入yes表示接受。
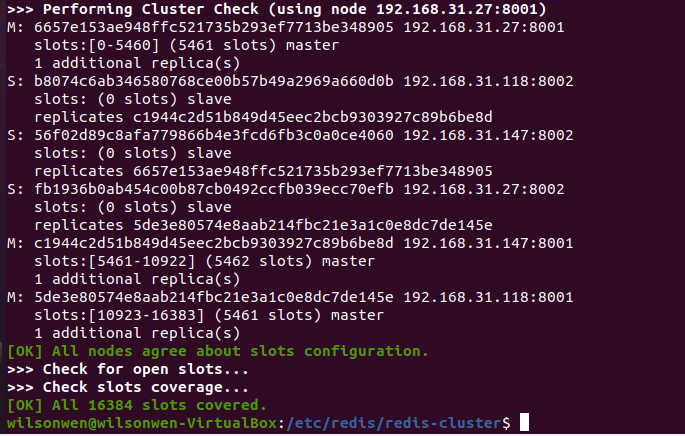
可以看到,redis cluster共有16384个slot,每个实例保存不同的slot: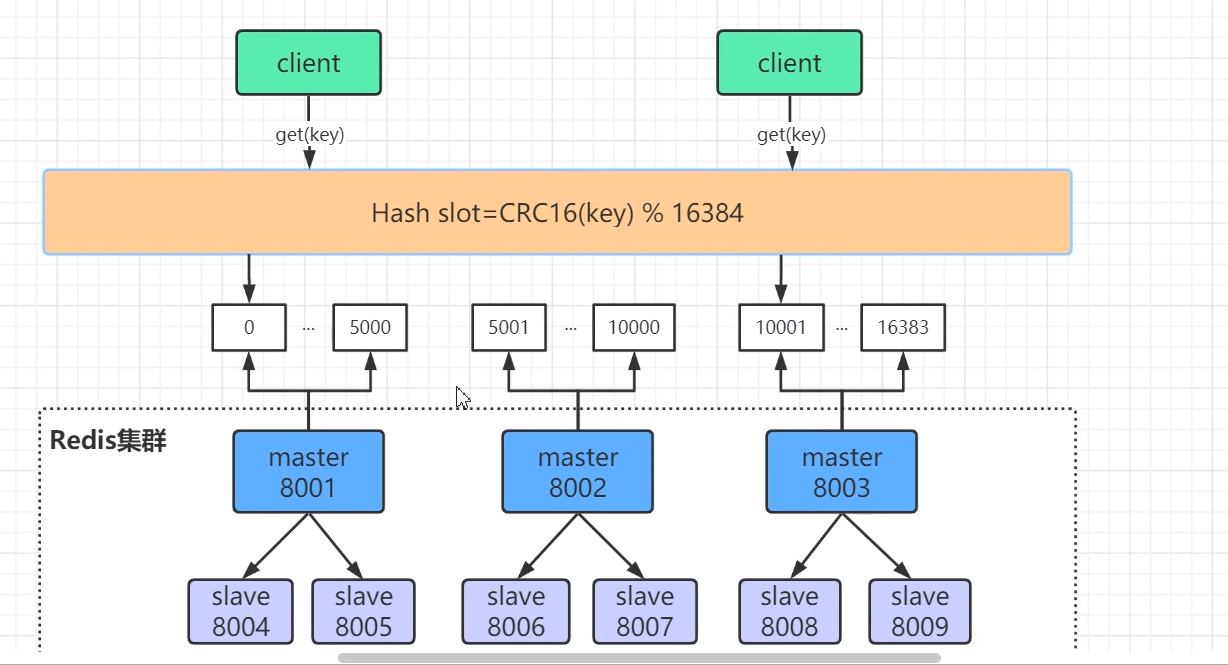
进入redis集群,一定要带上-c参数
redis-cli -p 8001 -a 123456 -c设置,观察是否可以设置成功:
192.168.31.147:8001> set lang-cluster 123 -> Redirected to slot [13250] located at 192.168.31.118:8001 OK成功。
分配算法的原理
关键是根据key获取到对应的slot: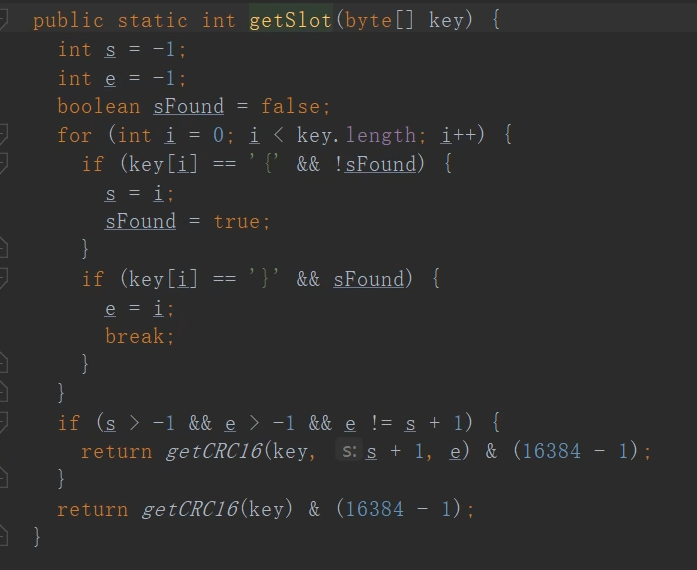
最后一行,就是对key做哈希,然后对16384取模,得到对应的槽位slot。
Cluster的选举
- Master挂了;
- Slave发现Master挂了;
- 将自己记录的集群currentEpoch加1, 并且广播FAILOVER_AUTH_REQUEST信息;
- 其他节点收到该信息,只有其他集群的Master会响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ACK;
- Slave收集返回的FAILOVER_AUTH_ACK,当超过半数Master以后,变成新的Master;
- 如果多个Slave票数一样,重新选举。
为了防止多个slave同时发起请求,采取了延迟公式:
DELAY = 500ms + random(0 ~ 500) + SLAVE_RANK * 1000ms;
集群脑裂
指的是,由于网络波动等问题,Master可能和Slave断开连接了,但是并没有宕机。此时Slave会发起选举选出新的Master,导致一个集群同时出现了多个Master对外提供数据的写服务,导致数据不一致。
在网络恢复后,之前断开连接的Master要重新回到集群,回来后它变成Slave,在进行主从同步时,这个Master之前写入的数据会被丢失。
解决方式:
min-slaves-to-write 1
该配置指的是,至少要有1个slave写成功了,才算真正的写成功。
这样配置牺牲了集群的一定的可用性,所以需要根据具体场景进行权衡。
集群批量操作
当进行批量操作,例如:
mset key1 value1 key2 value2
如果计算出来的两个key落在不同的slot上,Redis会让它失败,因为这种操作Redis需要保证原子性。
如果就是希望用批量操作,那么在key前面加上{xxx},{}里的值用来做redis做哈希计算,保证落在同一个slot上即可,
mset {user1}:key1 value1 {user1}:key2 value2
添加新的集群
- 将实例加入到集群中
第一个IP为新节点的IP和Port,第二个为集群内任意节点的iP和port。redis-cli -a 123456 --cluster add-node 192.168.31.27:8003 192.168.31.27:8001
加入成功后还不能对该结点进行读写操作,因为此时没有slot分配给它。
- 进行数据的重新分片。
回答一些问题以后,将数据和槽位迁移到新机器上。redis-cli -a 123456 --cluster reshard 192.168.31.27:8001

若有收获,就点个赞吧
0 人点赞
