索引的本质
帮助Mysql高效获取数据的排好序的数据结构。
如果没有索引,查询时需要逐行查询,效率低。
索引数据结构
- 二叉搜索树;
- 红黑树
- Hash表;
- B-Tree;
为什么不用二叉搜索树?
因为很容易非常不平衡,例如如果根据ID形成二叉树,分别为1,2,3,4,5,6,最后得到的二叉树为: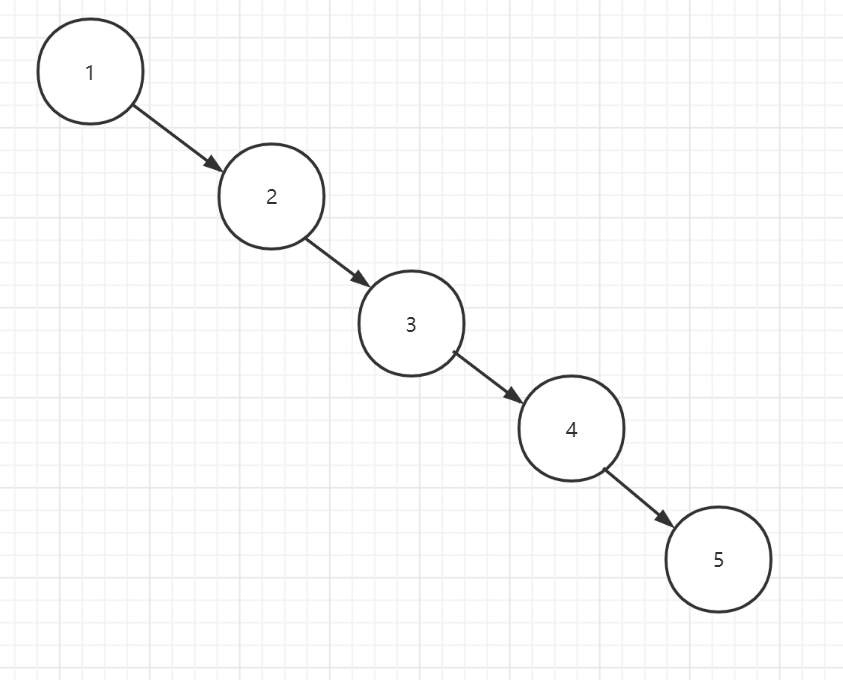
那么效率不高。
为什么不用红黑树?
红黑树是一棵不严格的二叉树,查找,插入,删除的性能比较稳定。但是对于很多数据来说,树的高度会很高,导致查询效率变低。
为什么不用Hash索引?
事实上,Hash索引相当快,甚至比B+树还快,但是Hash索引最大的缺点是,不支持范围查询。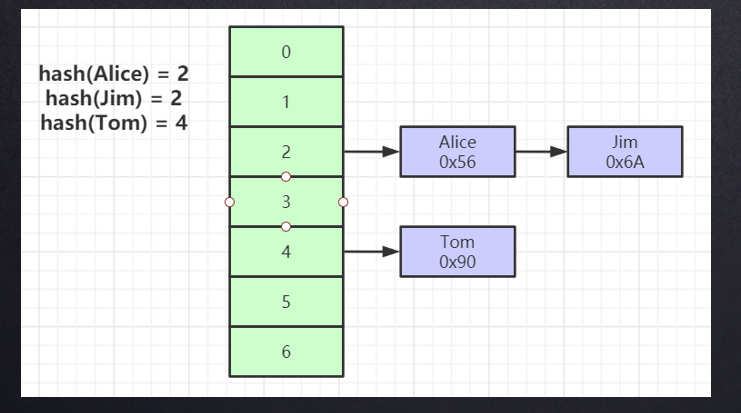
B+树
B+树为Mysql底层真正使用的数据结构,相当于优化后的B树。B+树就解决了红黑树高度太高的问题,它的树的高度小于等于3。
B+树和B树
B树:
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列。
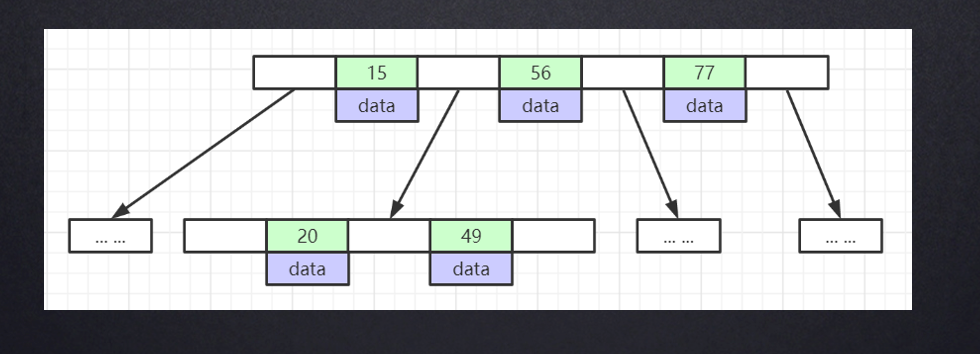 B+树
B+树
- 非叶子节点不存储data,只存储索引,因此可以存放更多的索引;
- 叶子节点包含所有索引字段;
- 叶子节点用指针连接,提高区间访问的性能。
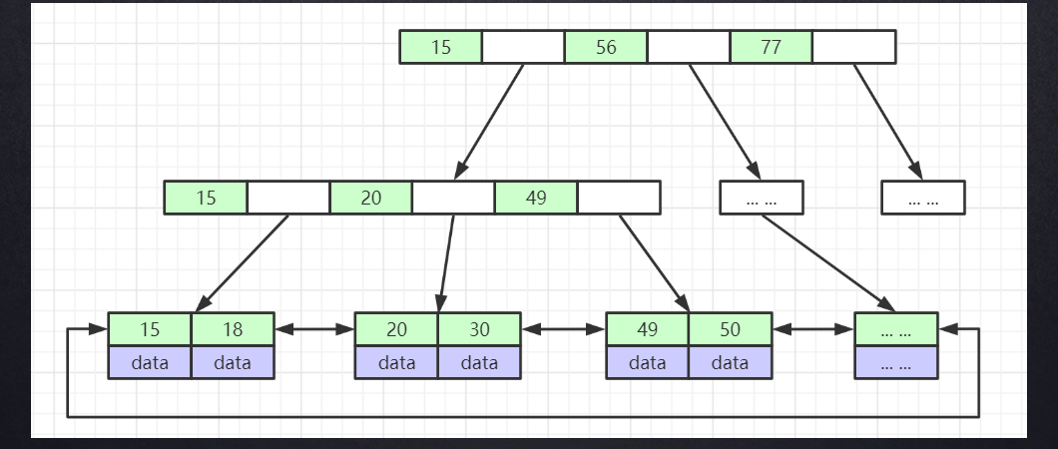
那么为什么最后选择了B+树?
因为,只在叶子节点存储data,那么非叶子节点就可以存储更多的索引,索引一般都很小(相对于data来说),那么对于同样的数据量,B+树的深度会比B树小得多。
在Mysql中,默认一块索引的大小为16Kb,那么三层可以存放将近几千万的数据量。
此外,B+树的叶子节点之间用指针连接了,那么对于范围查找,比如 20 < x < 50,效率更高。
存储引擎
现在常用的为InnoDB, 以前还有MyISAM
InnoDB和MyISAM的区别
MyISAM将最终数据和索引分开存储,即B+树的叶子节点不直接保存数据,而是保存数据的地址,这被称为非聚集索引。因此有三个文件,一个保存表的结构信息,一个保存索引,一个保存数据。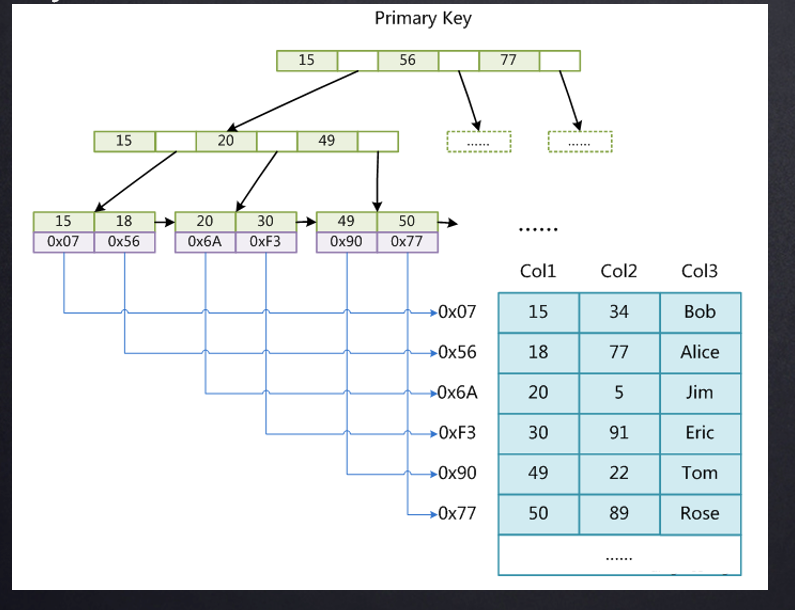
InnoDB则在叶子节点中保存了所有数据, 这被称为聚集索引。因此只有两个文件,一个文件保存表的结构信息,一个文件保存索引以及数据。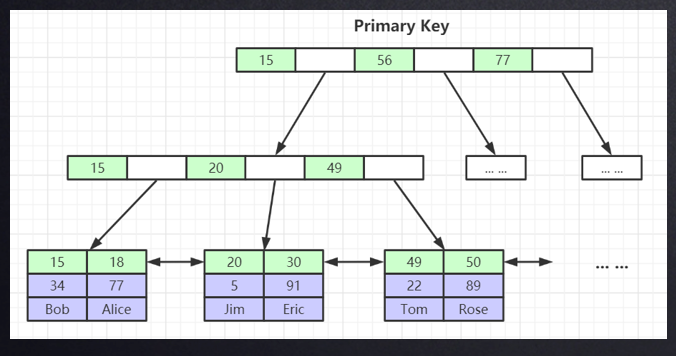
为什么建议InnoDB必须建主键,且推荐使用整形的自增主键?
主键:因为InnoDB需要维护一个B+树,如果不设置主键,InnoDB需要自己帮你找一个列设置为主键,如果没找到,还需要新增一个专门的列作为主键。
整型:整数更好比较大小,效率更高。且整型数所占的空间较小,相对于UUID来说。
自增:
如果采用自增,不会导致叶子节点分裂以及B+树的重新平衡,那么B树的生成效率要高。
例如,如果叶子节点只能两个一组,插入6,7,8那么就会自然得到: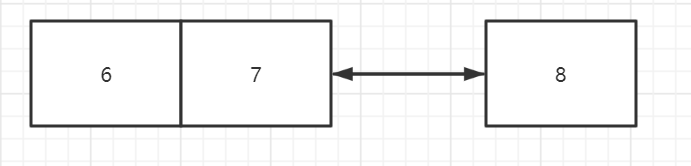
而如果插入6, 8, 7,就会先得到: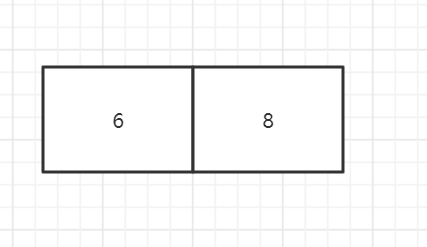
然后将6和8拆开,将6和7合并,并让8单独一组: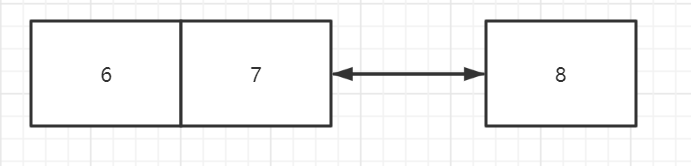
显然,非递增的代价变高。
主键索引和二级索引
主键索引又是聚簇索引,如果没有设置主键,聚簇索引就是另一个值。其叶子节点里包含了所有的数据信息,因此体积比较大。
二级索引的叶子节点中,仅仅包含索引的键和主键,体积比主键索引要小。
为什么需要二级索引,而不都采取聚簇索引的形式保存所有数据?
二级索引的存在保证了查找速度也比较快,之所以不采取聚簇索引,最重要的原因是节省空间。想象一下如果都采取聚簇索引,那么有5个二级索引就需要5倍的数据体积。
其次,为了一致性。如果都采取聚簇索引,那么如果某个数据发生更新,那么必须要更新所有的聚簇索引的叶子节点,效率低。
二级索引如何工作?
如果能通过二级索引直接查到所有需要的信息,例如,返回值仅包含二级索引的值和主键的值,那么就直接通过二级索引找到以后返回。
如果不能通过二级索引直接查到所有需要的信息,则需要通过回表,即先通过二级索引拿到主键,然后拿主键去主键索引中去查找。
联合索引
即多个字段,共同组成一个索引。
实际项目中,不建议建太多的单值索引,而是尽量通过少量的联合索引来搞定查询。
语法:
KEY `idx_name_age_position` (`name`, `age`, `position`) USING BTREE;
其底层仍然是B+树,机构如下: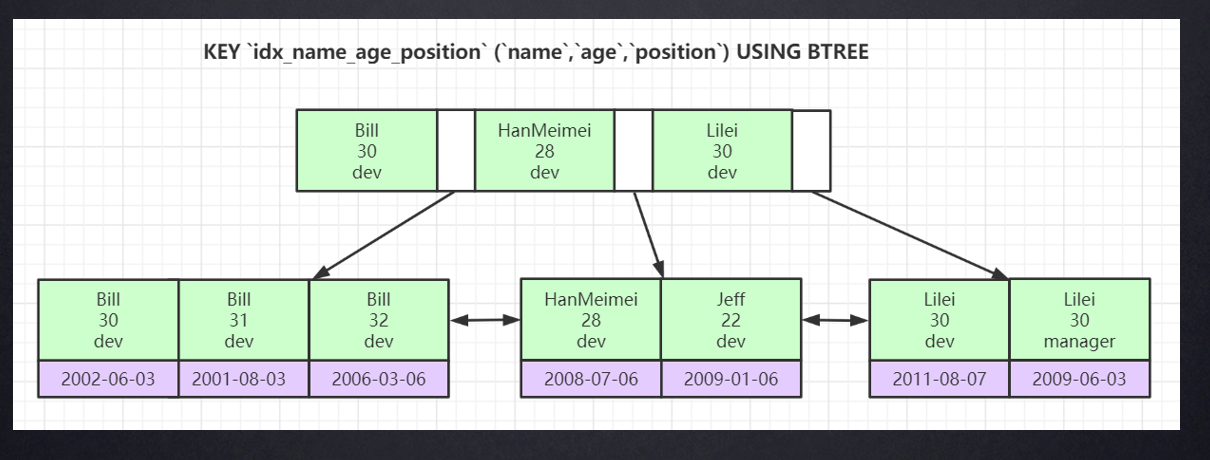
其排序遵循索引最左前缀原理,即首先按name排序,如果name相同,按age排序,最后按position排序。
当查询时,必须要先用name, 再用age, 再用position才能使用联合索引,不能跳过。例如:
// 下面这条会使用索引select * from employees where name = 'Bill' and age = 31;// 下面这两条都不会使用索引。select * from employees where age = 31 and position = 'dev';select * from employees where position = 'manager';
原因很简单,即索引最左前缀原理,首先是按照name排序的,如果跳过了name,只看age, age都是无序的,此时都不能满足成为索引的条件’排好序的数据结构’ , 自然就无法通过索引来优化查询效率了。

若有收获,就点个赞吧
0 人点赞
